Homework_3 (完整版)
划水♂️!好耶!
果然还是逃不过作业,初三刚过就要营业
审题
爬虫+算法:划水中的员工
员工 A 此刻内心一酸,大年初一加班惨绝人寰,情不自禁打开 B 站,跟着网友一起划水看番。
但是由于技术故障原因番没了,员工 A 心态差点爆炸,刚好有个 Up 主疯狂掉粉几十万引起了他的注意,掉得他内心莫名舒坦,但是他想起自己还要工作不能实时查看粉丝数,于是他准备把这个工作交给下属。
他交代下属:将某个 Up 主的粉丝数用爬虫的方法抓取下来,并且每小时重新爬取一次,可视化出来。
当然,除此之外,他还想知道多个 Up 主之间粉丝的重合度,请选三个 Up 主,爬取其粉丝,用合理的算法给出大致正确的重合度,给出算法时间复杂度,估计算法所用的空间内存。
要做什么:
任务一:
- 爬! 一个up主的粉丝数
- 设定每个小时爬一次
- 记录每次粉丝数画图
任务二:
- 爬三个Up主粉丝数据
- 相互对比算出重合度
- 给出算法时间复杂度
- 估计空间内存(什么登西)
任务一
1、获取up主粉丝数
据网上可靠消息up主粉丝数就藏在
https://api.bilibili.com/x/relation/stat?vmid= + 一串神奇数字(uid) + &jsonp=jsonp
的里面
为了挖掘宝藏需要安装一波requests
安装requests
pip install requests
代码
import requests as req
import time
def fans(uid):
uid = str(uid)
url = "https://api.bilibili.com/x/relation/stat?vmid=" + uid + "&jsonp=jsonp"
resp = req.get(url)
info = eval(resp.text)
num = str(info['data']['follower'])
print("the number of followers is " + num)
if __name__ == "__main__":
uid = input("Enter the uid:")
uid = int(uid)
fans(uid)
获取并打印粉丝数(结合下面环节应该是把粉丝数导入列表)
2、设定每小时爬一次
schedule
python中有一个轻量级的定时任务调度的库:schedule。他可以完成每分钟,每小时,每天,周几,特定日期的定时任务。因此十分方便我们执行一些轻量级的定时任务。
安装schedule
pip install schedule -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import schedule
fans()
schedule.every(10).second.do(fans)
while True:
schedule.fans_pending() # run_pending:运行所有可以运行的任务
输出:
The number of followers is 12614183
The number of followers is 12614188
The number of followers is 12614195
The number of followers is 12614199
......
罗老师涨粉好快!
但是毫无卵用!!
这个schedule好像只能重复无参函数,还停不下来,应该适用于那种实时抓实时输出的程序
换条路!
sleep()
通过time.sleep(t)可以使程序暂停t秒时间,结合for循环控制循环次数,用datetime获取时间,用fans()获取粉丝数作为画图数据
uid = input("请输入up主的uid:")
interval = input("请输入获取粉丝数的时间间隔(单位:秒):")
interval = int(interval)
count = input("请输入获取次数:")
count = int(count)
t = []
number = []
for i in range(0,count):
t.append(datetime.datetime.now().strftime('%H:%M:%S'))
number.append(fans(uid))
time.sleep(interval)
print(t)
print(number)
正常运行,针不戳
接下来是画图时间
画图
plt.plot(t,number)
plt.show()

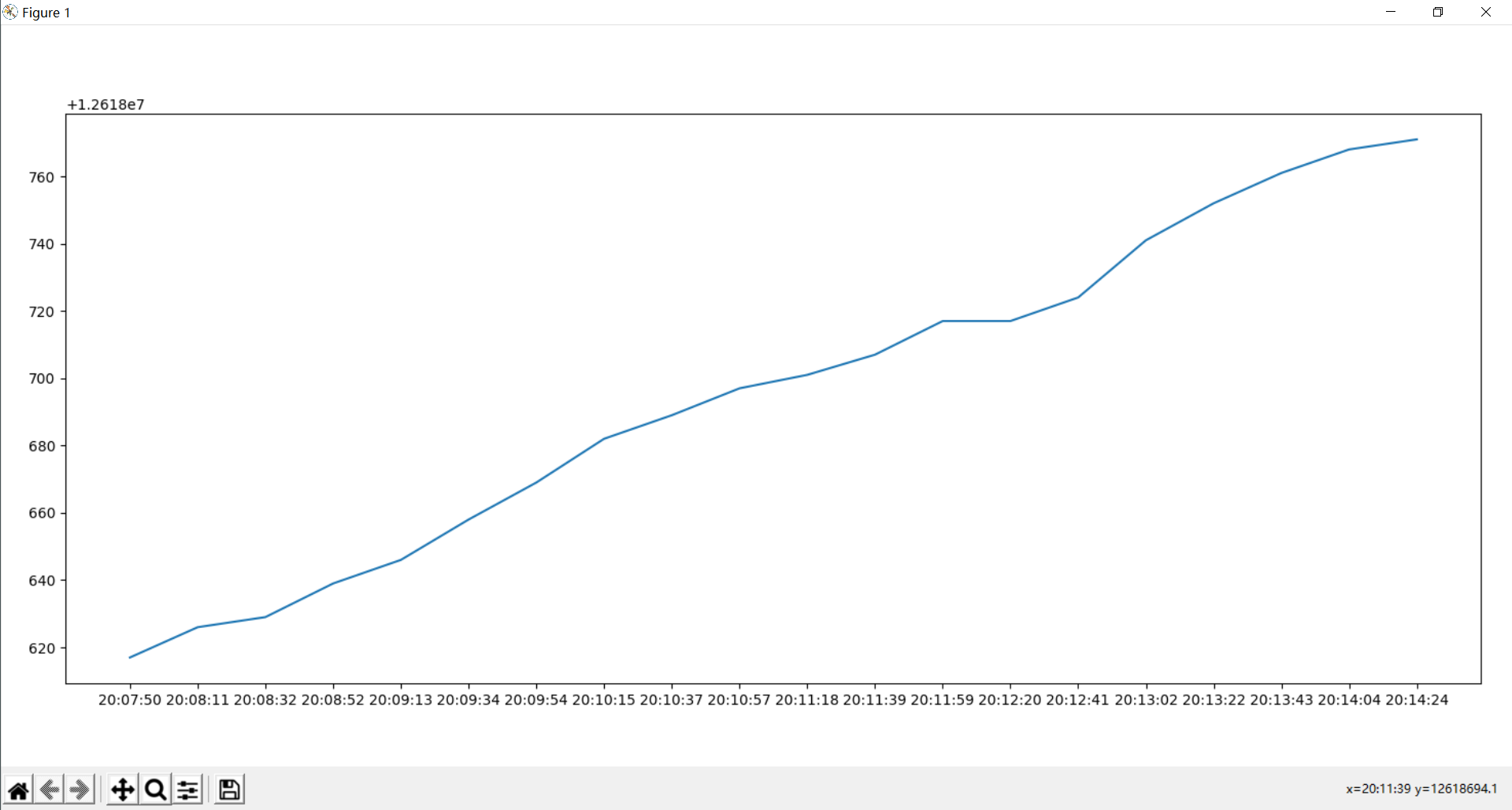
为节约时间设置每二十秒获取一次,一个小时的话设置3600秒即可
好耶!!任务一完成!!
任务二
1、爬三部电影评论数据
爬用户名的函数部分
import urllib.request
import re
comment = 'C:\\Users\\13666\\Desktop\\Pythonwork\\test.txt'
T='<span content=".*?" class=".*?">.*?</span>'
def get_name(id):
url_1 = f"https://movie.douban.com/subject/{id}/reviews?start="
name_list = []
for i in range(10):
url = url_1 + str(i*20) # 确定要爬取的入口链接
# 模拟成浏览器并爬取对应的网页 谷歌浏览器
headers = {'User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'}
opener = urllib.request.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read().decode('utf8')
time_pattern = re.compile('<span content=".*?" class=".*?">(.*?)</span>', re.S)
time = re.findall(time_pattern, data)
id_pattern= re.compile('<h2><a href="https://movie.douban.com/review/(.*?)/', re.S)
id= re.findall(id_pattern, data)
for j in range(len(id)):
html = 'https://movie.douban.com/j/review/' + str(id[j]) + '/full'
data = opener.open(html).read().decode('utf8')
html = data
content_pattern = re.compile('data-original(.*?)main-author', re.S)
content = re.findall(content_pattern, html)
text_pattern = re.compile('[\u4e00-\u9fa5|,、“”‘’:!~@#¥【】*()——+。;?]+', re.S)
text = re.findall(text_pattern, content[0])
text = ''.join(text)
name_pattern = re.compile('data-author=.*?"(.*?)"', re.S)
name = re.findall(name_pattern, html)
name_list.append(name[0].strip('\\'))
return name_list
获取部分很大一部分是copy的qwq
然后自己改了一波可以使用任意电影
url那一部分一开始是这样的:
url = "https://movie.douban.com/subject/30331149/reviews?start="+str(i*20) # 确定要爬取的入口链接
只能使用确定的网址
然后我为了可以指定任意电影就改成了
url = "https://movie.douban.com/subject/" + id + "/reviews?start="+str(i*20) # 确定要爬取的入口链接
好像挺完美的样子
然后玩命报错giao
假装下面全是红色
Traceback (most recent call last):
File "C:\Users\13666\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 571, in _readall_chunked
value.append(self._safe_read(chunk_left))
File "C:\Users\13666\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 610, in _safe_read
raise IncompleteRead(data, amt-len(data))
http.client.IncompleteRead: IncompleteRead(55421 bytes read, 9874 more expected)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/13666/PycharmProjects/豆瓣评论区/main.py", line 40, in <module>
first_list = get_name(first)
File "C:/Users/13666/PycharmProjects/豆瓣评论区/main.py", line 14, in get_name
data = opener.open(url).read().decode('utf8')
File "C:\Users\13666\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 461, in read
return self._readall_chunked()
File "C:\Users\13666\AppData\Local\Programs\Python\Python38-32\lib\http\client.py", line 575, in _readall_chunked
raise IncompleteRead(b''.join(value))
http.client.IncompleteRead: IncompleteRead(9514 bytes read)
后来修改成网址前半段在函数开头就确定然后后来再拼接的方式就可以了(见上面的函数)
怎会如此?????
2、相互对比算出重合度
我是将三个列表的重合元素重新组成一个列表,计算列表长度,然后计算重合度
first= input("输入第一部电影的id:")
second = input("输入第二部电影的id:")
third = input("输入第三部电影的id:")
first_list = []
second_list = []
third_list = []
first_list = get_name(first)
second_list = get_name(second)
third_list = get_name(third)
same_12 = [val for val in first_list if val in second_list]
same_123 = [val for val in same_12 if val in third_list]
rate = len(same_123)/(3*len(first_list)-2*len(same_123))
print("三部电影评论用户重合人数为:" + str(len(same_123)))
print("三部电影评论用户重合率为:" + str(rate*100) + "%")
3、给出算法时间复杂度
后面反复调用三次函数算是一个for了,加上函数本身包含俩for,时间复杂度应该是T(n)=O(n^3)
吧
4、贴一下运行结果
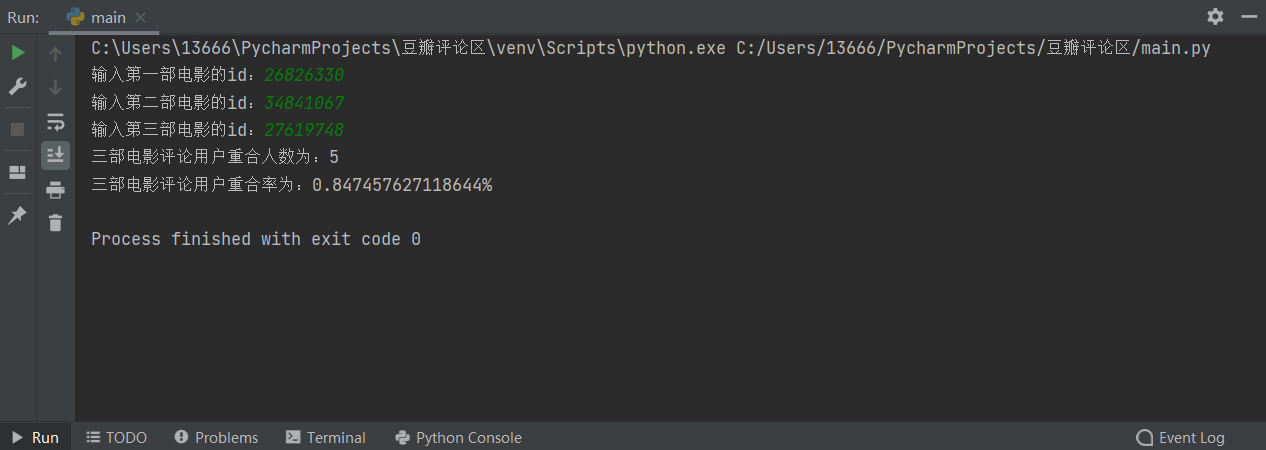
居然有五个人看了唐探三、李焕英和刺杀小说家并写了影评,不容易不容易,瑞思拜
总结
延续上一次作业的优良传统不靠大佬救靠csdn
任务一大部分是自己完成的
任务二爬粉丝名字有点超出能力范围了 函数部分代码抄的有点猛,比较遗憾,自己整出来还是比较有成就感
第三次作业就这样结束啦,一个寒假还是收获了蛮多的,每次作业都有交自己小骄傲一下,越学习越能感受到自己的渺小和代码世界的广阔,还是要继续努力。
Homework_3 (完整版)的更多相关文章
- 如何安全的将VMware vCenter Server使用的SQL Server Express数据库平滑升级到完整版
背景: 由于建设初期使用的vSphere vCenter for Windows版,其中安装自动化过程中会使用SQL Server Express的免费版数据库进行基础环境构建.而此时随着业务量的增加 ...
- Android版的菜谱客户端应用源码完整版
Android版的菜谱客户端应用源码完整版,这个文章是从安卓教程网转载过来的,不是本人的原创,希望能够帮到大家的学习吧. <ignore_js_op> 152936qc7jdnv6vo0c ...
- sed实例精解--例说sed完整版
原文地址:sed实例精解--例说sed完整版 作者:xiaozhenggang 最近在学习shell,怕学了后面忘了前面的就把学习和实验的过程记录下来了.这里是关于sed的,前面有三四篇分开的,现在都 ...
- flexbox-CSS3弹性盒模型flexbox完整版教程
原文链接:http://caibaojian.com/flexbox-guide.html flexbox-CSS3弹性盒模型flexbox完整版教程 A-A+ 前端博客•2014-05-08•前端开 ...
- 转贴 IT外企那点儿事完整版
转贴 IT外企那点儿事完整版 第一章:外企也就那么回儿事(http://www.cnblogs.com/forfuture1978/archive/2010/04/30/1725341.html) 1 ...
- C#.Net 上传图片,限制图片大小,检查类型完整版
C#.Net 上传图片,限制图片大小,检查类型完整版 源代码: 处理图片类,如检查图片大小,按宽度比例缩小图片 public class CImageLibrary{ public enum Va ...
- office2016 软件全集 官方下载免费完整版(含破解文件)不含垃圾软件 win10完美激活
office2016官方下载免费完整版是新一代办公软件,office2016官方下载免费完整版已经分享到下面,office2016官方下载免费完整版包括了Word.Excel.PowerPoint.O ...
- 老王Python培训视频教程(价值500元)【基础进阶项目篇 – 完整版】
老王Python培训视频教程(价值500元)[基础进阶项目篇 – 完整版] 教学大纲python基础篇1-25课时1.虚拟机安装ubuntu开发环境,第一个程序:hello python! (配置开发 ...
- thinkPHP3.2.3完整版 在sae上面的部署
第一步: thinkPHP3.2.3完整版,目录结构如下 第二步:在新浪sae上面创建一个新应用 第三步:用svn down,下来会有两个文件:index.php.config.ya ...
随机推荐
- 【LeetCode】954. Array of Doubled Pairs 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】507. Perfect Number 解题报告(Python & Java & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【剑指Offer】04. 二维数组中的查找 解题报告(Java & Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 解题方法 日期 题目地址:https://leetcode-cn.com/ ...
- 【剑指Offer】字符串的排列 解题报告(Python)
[剑指Offer]字符串的排列 解题报告(Python) 标签(空格分隔): LeetCode 题目地址:https://www.nowcoder.com/ta/coding-interviews 题 ...
- 『学了就忘』vim编辑器基础 — 96、末行模式中的相关命令
目录 1.在文档中显示行号 2.是否显示文档内容相关颜色 3.是否将查找的字符串高亮显示 4.是否显示右下角的状态栏 5.是否在左下角显示如"--INSERT--"之类的状态栏 6 ...
- Java 将Excel转为OFD
OFD是一种开放版式文档(Open Fixed-layout Document )的英文缩写,是我国国家版式文档格式标准.本文,通过Java后端程序代码展示如何将Excel转为OFD格式.方法步骤如下 ...
- N-Empress
全排列 基本思想:递归.散列 代码实现 #include<cstdio> const int maxn = 11; int n, P[maxn], hashTable[11] = {fal ...
- 使用 Eclipse 创建一个静态的登录页面
要求: 使用 Eclipse 创建一个静态的登录页面 实现步骤: 在 Eclipse 中,点击"File",显示菜单,选择"New" "Other&q ...
- Java面向对象笔记 • 【第3章 继承与多态】
全部章节 >>>> 本章目录 3.1 包 3.1.1 自定义包 3.1.2 包的导入 3.1.3 包的访问权限 3.1.4 实践练习 3.2 继承 3.2.1 继承概述 3 ...
- Android开发案例 设置背景图片轮播
点击按钮实现图片轮播效果 实践案例: xml <?xml version="1.0" encoding="utf-8"?> <LinearLa ...