单细胞分析实录(19): 基于CellPhoneDB的细胞通讯分析及可视化 (下篇)
在上一篇帖子中,我介绍了CellPhoneDB的原理、实际操作,以及一些值得注意的地方。这一篇继续细胞通讯分析的可视化。
公众号后台回复20210723获取本次演示的测试数据,以及主要的可视化代码。
所有的数据和结果文件均已打包,下载后直接就能跑下面的代码画图。
下面的代码可以绘制对称热图
(如果你不清楚为啥热图要沿着对角线对称,可以看一下之前的推文)
library(tidyverse)library(RColorBrewer)library(scales)pvalues=read.table("./test/pvalues.txt",header = T,sep = "\t",stringsAsFactors = F)pvalues=pvalues[,12:dim(pvalues)[2]]statdf=as.data.frame(colSums(pvalues < 0.05))colnames(statdf)=c("number")statdf$indexb=str_replace(rownames(statdf),"^.*\\.","")statdf$indexa=str_replace(rownames(statdf),"\\..*$","")statdf$total_number=0for (i in 1:dim(statdf)[1]) {tmp_indexb=statdf[i,"indexb"]tmp_indexa=statdf[i,"indexa"]if (tmp_indexa == tmp_indexb) {statdf[i,"total_number"] = statdf[i,"number"]} else {statdf[i,"total_number"] = statdf[statdf$indexb==tmp_indexb & statdf$indexa==tmp_indexa,"number"]+statdf[statdf$indexa==tmp_indexb & statdf$indexb==tmp_indexa,"number"]}}rankname=sort(unique(statdf$indexa))statdf$indexa=factor(statdf$indexa,levels = rankname)statdf$indexb=factor(statdf$indexb,levels = rankname)statdf%>%ggplot(aes(x=indexa,y=indexb,fill=total_number))+geom_tile(color="white")+scale_fill_gradientn(colours = c("#4393C3","#ffdbba","#B2182B"),limits=c(0,20))+scale_x_discrete("cluster 1")+scale_y_discrete("cluster 2")+theme_minimal()+theme(axis.text.x.bottom = element_text(hjust = 1, vjust = NULL, angle = 45),panel.grid = element_blank())ggsave(filename = "interaction.num.2.pdf",device = "pdf",width = 12,height = 10,units = c("cm"))
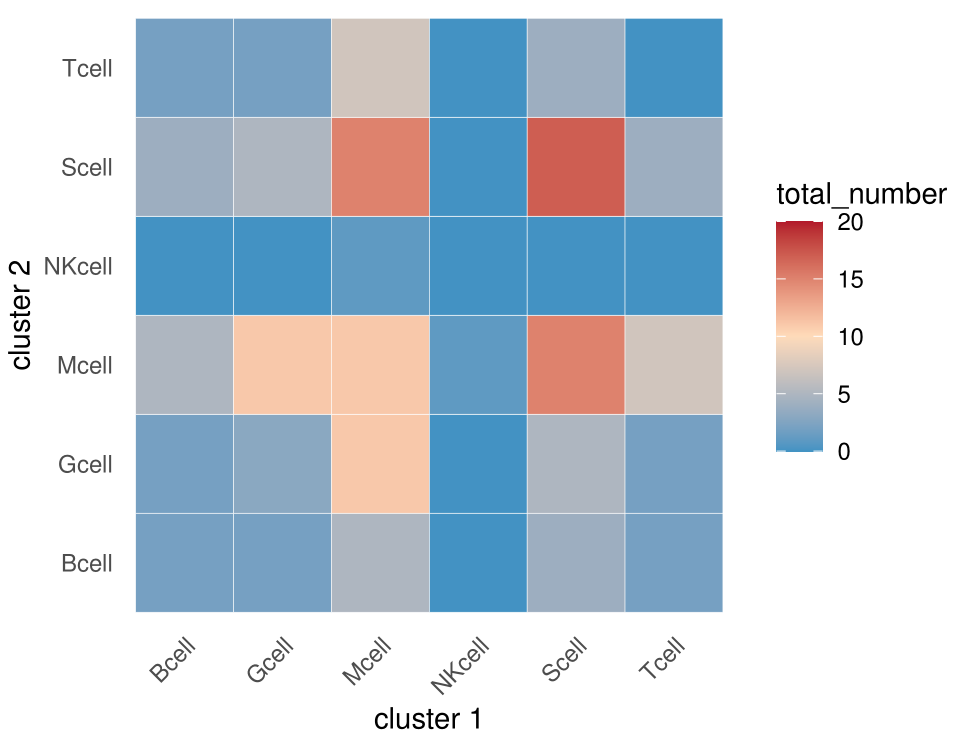
还可以用网络图表示互作关系的数量
代码如下
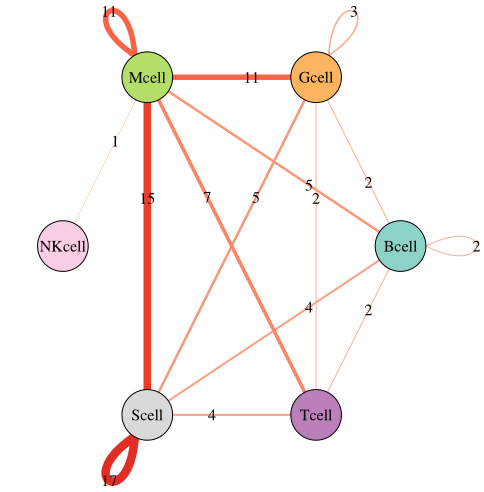
library(tidyverse)library(RColorBrewer)library(scales)library(igraph)pvalues=read.table("./test/pvalues.txt",header = T,sep = "\t",stringsAsFactors = F)pvalues=pvalues[,12:dim(pvalues)[2]]statdf=as.data.frame(colSums(pvalues < 0.05))colnames(statdf)=c("number")statdf$indexb=str_replace(rownames(statdf),"^.*\\.","")statdf$indexa=str_replace(rownames(statdf),"\\..*$","")rankname=sort(unique(statdf$indexa))A=c()B=c()C=c()remaining=ranknamefor (i in rankname[-6]) {remaining=setdiff(remaining,i)for (j in remaining) {count=statdf[statdf$indexa == i & statdf$indexb == j,"number"]+statdf[statdf$indexb == i & statdf$indexa == j,"number"]A=append(A,i)B=append(B,j)C=append(C,count)}}statdf2=data.frame(indexa=A,indexb=B,number=C)statdf2=statdf2 %>% rbind(statdf[statdf$indexa==statdf$indexb,c("indexa","indexb","number")])statdf2=statdf2[statdf2$number > 0,] #过滤掉值为0的观测#设置节点和连线的颜色color1=c("#8DD3C7", "#FDB462", "#B3DE69", "#FCCDE5", "#D9D9D9", "#BC80BD")names(color1)=ranknamecolor2=colorRampPalette(brewer.pal(9, "Reds")[3:7])(20) #将颜色分成多少份,取决于互作关系数目的最大值names(color2)=1:20 #每一份颜色用对应的数字命名#做网络图##下面的四行代码相对固定net <- graph_from_data_frame(statdf2[,c("indexa","indexb","number")])edge.start <- igraph::ends(net, es=igraph::E(net), names=FALSE)group <- cluster_optimal(net)coords <- layout_in_circle(net, order = order(membership(group)))E(net)$width <- E(net)$number / 2 #将数值映射到连线的宽度,有时还需要微调,这里除以2就是这个目的E(net)$color <- color2[as.character(ifelse(E(net)$number > 20,20,E(net)$number))] #用前面设置好的颜色赋给连线,颜色深浅对应数值大小E(net)$label = E(net)$number #连线的标注E(net)$label.color <- "black" #连线标注的颜色V(net)$label.color <- "black" #节点标注的颜色V(net)$color <- color1[names(V(net))] #节点的填充颜色,前面已经设置了;V(net)返回节点信息#调整节点位置的线条角度##如果没有这两行代码,节点位置的圆圈是向右的loop.angle<-ifelse(coords[igraph::V(net),1]>0,-atan(coords[igraph::V(net),2]/coords[igraph::V(net),1]),pi-atan(coords[igraph::V(net),2]/coords[igraph::V(net),1]))igraph::E(net)$loop.angle[which(edge.start[,2]==edge.start[,1])] <- loop.angle[edge.start[which(edge.start[,2]==edge.start[,1]),1]]#pdf("interaction.num.3.pdf",width = 6,height = 6)plot(net,edge.arrow.size = 0, #连线不带箭头edge.curved = 0, #连线不弯曲vertex.frame.color = "black", #节点外框颜色layout = coords,vertex.label.cex = 1, #节点标注字体大小vertex.size = 30) #节点大小#dev.off()
气泡图——具体的互作关系
以上几种图,只是用来展示数量,具体的两种细胞之间的互作关系可以用如下的代码展示:
source("CCC.bubble.R")CCC(pfile="./test/pvalues.txt",mfile="./test/means.txt",#neg_log10_th= -log10(0.05),#means_exp_log2_th=1,#neg_log10_th2=3,#means_exp_log2_th2=c(-4,6),#notused.cell=c("Bcell","Gcell"),#used.cell=c("Mcell"),#cell.pair=c("Mcell.Scell","Mcell.NKcell","Mcell.Tcell","Scell.Mcell","NKcell.Mcell","Tcell.Mcell"),#这里是自定义的顺序,若是可选细胞对的子集,则只展示子集,若有交集则只展示交集;空值情况下,会根据可选细胞对自动排序#gene.pair=c("MIF_TNFRSF14","FN1_aVb1 complex","EGFR_MIF")#作用同上)ggsave(filename = "interaction.detail.1.pdf",device = "pdf",width =20,height = 12,units = "cm")
参数解释:
neg_log10_th和means_exp_log2_th两个参数用来筛选显著的互作关系;neg_log10_th2和means_exp_log2_th2两个参数用来限定最终气泡图的数值范围;notused.cell不包含的细胞类型;used.cell必须包含的细胞类型;cell.pair必须包含的细胞pair,以及它们的顺序;gene.pair必须包含的基因pair,以及它们的顺序。
后面四个参数在细化气泡图的时候,很有用。
我们先不加额外的参数,查看全部的互作关系
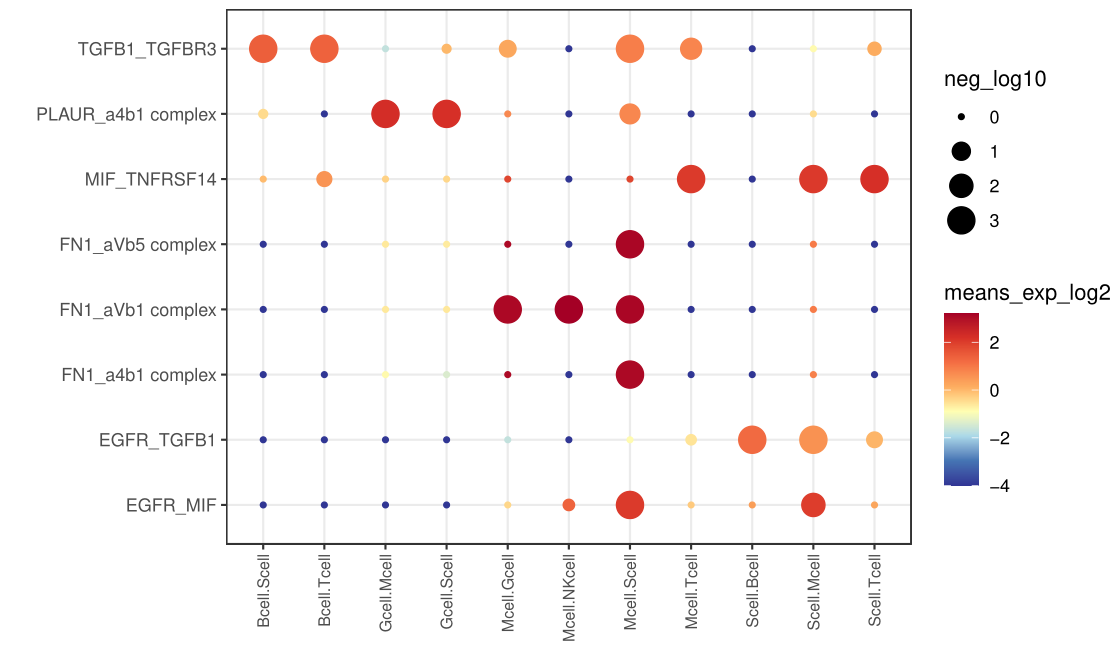
随后再细化,指定需要展示的细胞类型和gene pair,如下:
CCC(pfile="./test/pvalues.txt",mfile="./test/means.txt",cell.pair=c("Mcell.Scell","Mcell.NKcell","Mcell.Tcell","Scell.Mcell","NKcell.Mcell","Tcell.Mcell"),#这里是自定义的顺序,若是可选细胞对的子集,则只展示子集,若有交集则只展示交集;空值情况下,会根据可选细胞对自动排序gene.pair=c("MIF_TNFRSF14","FN1_aVb1 complex","EGFR_MIF")#作用同上)ggsave(filename = "interaction.detail.2.pdf",device = "pdf",width =16,height = 10,units = "cm")

最后那个CCC( )函数是小编写的,小编觉得还挺好用的。并不复杂,也才120行。如果你也想用,欢迎转发上一篇推文,截图后发给公众号后台,留下邮箱,小编就会发给你哦。别怪小编套路呀,写这两篇帖子花了不少时间呢
因水平有限,有错误的地方,欢迎批评指正!
单细胞分析实录(19): 基于CellPhoneDB的细胞通讯分析及可视化 (下篇)的更多相关文章
- 单细胞分析实录(18): 基于CellPhoneDB的细胞通讯分析及可视化 (上篇)
细胞通讯分析可以给我们一些细胞类群之间相互调控/交流的信息,这种细胞之间的调控主要是通过受配体结合,传递信号来实现的.不同的分化.疾病过程,可能存在特异的细胞通讯关系,因此阐明这些通讯关系至关重要. ...
- 【代码更新】单细胞分析实录(20): 将多个样本的CNV定位到染色体臂,并画热图
之前写过三篇和CNV相关的帖子,如果你做肿瘤单细胞转录组,大概率看过: 单细胞分析实录(11): inferCNV的基本用法 单细胞分析实录(12): 如何推断肿瘤细胞 单细胞分析实录(13): in ...
- 单细胞分析实录(8): 展示marker基因的4种图形(一)
今天的内容讲讲单细胞文章中经常出现的展示细胞marker的图:tsne/umap图.热图.堆叠小提琴图.气泡图,每个图我都会用两种方法绘制. 使用的数据来自文献:Single-cell transcr ...
- 【代码更新】单细胞分析实录(21): 非负矩阵分解(NMF)的R代码实现,只需两步,啥图都有
1. 起因 之前的代码(单细胞分析实录(17): 非负矩阵分解(NMF)代码演示)没有涉及到python语法,只有4个python命令行,就跟Linux下面的ls grep一样的.然鹅,有几个小伙伴不 ...
- 【GWAS文献】基于GWAS与群体进化分析挖掘大豆相关基因
Resequencing 302 wild and cultivated accessions identifies genes related to domestication and improv ...
- 高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化
高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化 作为一名Linux系统管理员,最主要的工作是优化系统配置,使应用在系统上以最优的状态运行.但硬件问题.软件问题.网络环境等 ...
- 基于Keil C的覆盖分析,总结出编程中可能出现的几种不可预知的BUG
基于Keil C的覆盖分析,总结出编程中可能出现的几种不可预知的BUG,供各位网友参考 1.编译时出现递归警告,我看到很多网友都采用再入属性解决,对于再入函数,Keil C不对它进行覆盖分析,采用模拟 ...
- 基于Petri网的工作流分析和移植
基于Petri网的工作流分析和移植 一.前言 在实际应用场景,包括PEC的订单流程从下订单到订单派送一直到订单完成都是按照一系列预先规定好的工作流策略进行的. 通常情况下如果是采用面向过程的编程方法, ...
- UNIX网络编程——分析一帧基于UDP的TFTP协议帧
下图是UDP的段格式: 相比TCP段格式,UDP要简单得多,也没啥好说的,需要注意的是UDP数据长度指payload加上首部的长度. 下面分析一帧基于UDP的TFTP协议帧: 以太网首部 0000: ...
随机推荐
- 重新整理 .net core 实践篇—————文件系统[二十二]
前言 简单介绍一下文件系统. 正文 文件系统,主要是下面3个接口组成: IFileProvider IFileInfo IDirectoryContents 那么他们的实现是: physicalFil ...
- 徒手用 Go 写个 Redis 服务器(Godis)
作者:HDT3213 今天给大家带来的开源项目是 Godis:一个用 Go 语言实现的 Redis 服务器.支持: 5 种数据结构(string.list.hash.set.sortedset) 自动 ...
- noip2013 总结
转圈游戏 题目 n 个小伙伴(编号从 0 到 n-1)围坐一圈玩游戏.按照顺时针方向给 n 个位置编号,从0 到 n-1.最初,第 0 号小伙伴在第 0 号位置,第 1 号小伙伴在第 1 号位置,-- ...
- 微软官方 Win 11 “体检工具”太烂了?开发者自己做了一个
1.Win 10 免费升级到 Win 11 最近微软官方终于宣布了 Windows 11,不仅带来了全新的 UI,而且还有很多新功能:比如支持 Android 应用. 虽然微软官方已说明 Win 10 ...
- Java安全之Weblogic内存马
Java安全之Weblogic内存马 0x00 前言 发现网上大部分大部分weblogic工具都是基于RMI绑定实例回显,但这种方式有个弊端,在Weblogic JNDI树里面能将打入的RMI后门查看 ...
- Unity_DOTween
DOTween官网 DG.Tweening.Ease枚举详解 2019.12.12补充: 问题:当前dotween动画没播放完,便再次播放有冲突的操作,如连续多次播放.正播.倒播,导致显示不正常或报错 ...
- 常见DDoS攻击
导航: 这里将一个案例事项按照流程进行了整合,这样观察起来比较清晰.部分资料来自于Cloudflare 1.DDoS介绍 2.常用DDoS攻击 3.DDoS防护方式以及产品 4.Cloudflare ...
- explicit 关键字 禁止隐式转换
explicit可以抑制内置类型隐式转换,所以在类的构造函数中,使用explicit关键字,防止不必要的隐式转换
- 22、oracle子查询
22.1.什么是子查询: 1.子查询就是在一条sql语句中嵌入select语句: 2.子查询可区分为关联子查询和非关联子查询,他们和主查询之间的执行顺序和关系是不同的: 22.2.关联子查询: 1.说 ...
- CRM系统个性化定制的对企业的优势作用
伴随着科学技术的不断发展,企业信息化建设也在持续地开展.企业管理模式已经开始由传统模式向信息化转变,并且越来越多的企业开始使用互联网软件来进行辅助管理,这一趋势也让CRM客户管理系统得到快速的发展.市 ...