python爬取疫情数据存入MySQL数据库
import requests
from bs4 import BeautifulSoup
import json
import time
from pymysql import * def mes():
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0' #请求地址
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36 SLBrowser/6.0.1.6181'}#创建头部信息
resp = requests.get(url,headers = headers) #发送网络请求
content=resp.content.decode('utf-8')
soup = BeautifulSoup(content, 'html.parser')
listA = soup.find_all(name='script',attrs={"id":"getAreaStat"})
account =str(listA)
mes = account.replace('[<script id="getAreaStat">try { window.getAreaStat = ', '')
mes=mes.replace('}catch(e){}</script>]','')
#mes=account[52:-21]
messages_json = json.loads(mes)
print(messages_json)
times=time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print(times)
provinceList=[]
cityList=[]
lenth=total()
con=len(messages_json)+lenth#算出数据库已有的条数+今天省份的条数,才是城市的开始id
for item in messages_json:
lenth+=1
provinceName=item['provinceName']
confirmedCount=item['confirmedCount']
suspectedCount=item['suspectedCount']
curedCount=item['curedCount']
deadCount=item['deadCount']
cities=item['cities']
provinceList.append((lenth,times,provinceName,None,confirmedCount,suspectedCount,curedCount,deadCount))
for i in cities:
con+=1
provinceName = item['provinceName']
cityName=i['cityName']
confirmedCount = i['confirmedCount']
suspectedCount = item['suspectedCount']
curedCount = i['curedCount']
deadCount = i['deadCount']
cityList.append((con,times,provinceName,cityName,confirmedCount,suspectedCount,curedCount,deadCount))
insert(provinceList,cityList) def insert(provinceList, cityList):
provinceTuple=tuple(provinceList)
cityTuple=tuple(cityList)
cursor = db.cursor()
sql = "insert into info_new values (%s,%s,%s,%s,%s,%s,%s,%s) "
try:
cursor.executemany(sql,provinceTuple)
print("插入成功")
db.commit()
except Exception as e:
print(e)
db.rollback()
try:
cursor.executemany(sql,cityTuple)
print("插入成功")
db.commit()
except Exception as e:
print(e)
db.rollback()
cursor.close()
def total():
sql= "select * from info_new"
cursor = db.cursor()
try:
cursor.execute(sql)
results = cursor.fetchall()
lenth = len(results)
db.commit()
return lenth
except:
print('执行失败,进入回调1')
db.rollback() # 连接数据库的方法
def connectDB():
try:
db = connect(host='localhost', port=3306, user='root', password='password', db='virus',charset='utf8')
print("数据库连接成功")
return db
except Exception as e:
print(e)
return NULL
if __name__ == '__main__':
db=connectDB()
mes()
数据库结构:

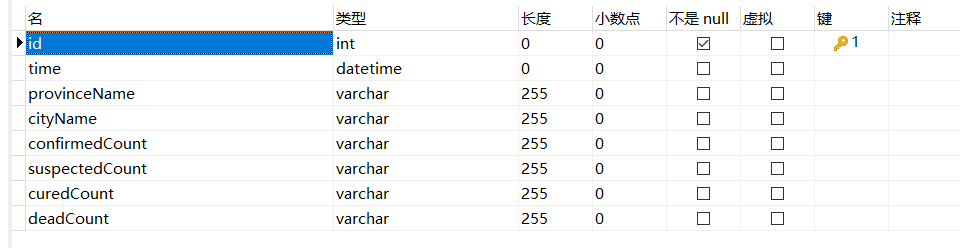
python爬取疫情数据存入MySQL数据库的更多相关文章
- python爬取疫情数据详解
首先逐步分析每行代码的意思: 这是要引入的东西: from os import path import requests from bs4 import BeautifulSoup import js ...
- 利用Python爬取疫情数据并使用可视化工具展示
import requests, json from pyecharts.charts import Map, Page, Pie, Bar from pyecharts import options ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- 使用selenium再次爬取疫情数据(链接数据库)
爬取网页地址: 丁香医生 数据库连接代码: def db_connect(): try: db=pymysql.connect('localhost','root','zzm666','payiqin ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
随机推荐
- spring学习06(AOP)
9.AOP 什么是AOP AOP(Aspect Oriented Programming)意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软 ...
- 零基础学Java之Java学习笔记(一):Java概述
什么是Java? Java是一门面向对象编程语言,可以编写桌面应用程序.Web应用程序.分布式系统和嵌入式系统应用程序. Java特点有哪些? 1.Java语言吸收了C++语言的各种优点,具有功能强大 ...
- STM32—SysTick系统定时器
SysTick是STM32中的系统定时器,利用SysTick可以实现精确的延时. SysTick-系统定时器 属于 CM3 内核中的一个外设,内嵌在 NVIC 中.系统定时器是一个 24bit 的向下 ...
- 【TS】学习总结
[TS]学习总结 01-TypeScript编译环境 TypeScript全局安装 npm install typescript -g tsc --version //查看版本,安装成功 TypeSc ...
- Vmware15的安装以及Ubunt的在虚拟机上的安装
一.vmware15安装 1.百度网盘地址 链接:https://pan.baidu.com/s/1Lgez57n50QEW97HNdYZCfQ 提取码:9wvy 2.下载到本地后 3.双击安装程序 ...
- flutter查看安全码SHA1
最近flutter技术调研高德地图插件时,要用到安全码,可以打开cmd,键入一下命令查看.(注意路径用户名yourusernamehere改为自己的) keytool -list -v -keysto ...
- 【C#】Enum,Int,String的互相转换 枚举转换
Enum为枚举提供基类,其基础类型可以是除 Char 外的任何整型.如果没有显式声明基础类型,则使用 Int32.编程语言通常提供语法来声明由一组已命名的常数和它们的值组成的枚举. 注意:枚举类型的基 ...
- 不同的 count 用法
不同的 count 用法效率:在 select count(?) from t 这样的查询语句里面, count(*).count(主键 id).count(字段) 和 count(1) 等不同用法的 ...
- Git pull and push
转自:https://blog.csdn.net/qq_41306423/article/details/101701991 关于 git pull 和 git pull origin develop ...
- mysql最强
MYSQL 与mysql第一次亲密接触 数据库相关概念 一.数据库的好处 二.数据库的常见概念 ★ 三.数据库存储数据的特点 四.常见的数据库管理系统 MYSQL的介绍 一.MySQL的背景 二.My ...