机器学习——正则化方法Dropout
1 前言
- 2012年,Dropout的想法被首次提出,受人类繁衍后代时男女各一半基因进行组合产生下一代的启发,论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》 提出了Dropout,它的出现彻底改变了深度学习进度,之后深度学习方向(反馈模型)开始展现优势,传统的机器学习慢慢消声。
- 深度学习架构现在变得越来越深,dropout 作为一个防过拟合的手段,使用也越来越普遍。
2 Dropout具体实现
- Dropout的思路:在一次循环中先随机选择神经层中的一些单元并将其临时隐藏,然后再进行该次循环中神经网络的训练和优化过程,在下一次循环中,又将隐藏另外一些神经元,如此直至训练结束。这样每次都会有一种新的组合,假设某一层有 $N$ 个神经元,就有 $2^N$ 个组合,最后子网络的输出均值就是最终的结果。但如果同时训练这些子网络代价太大,而且测试时又要组合多个网络的输出结果,不可行。
- 在训练时,每个神经单元以概率 $p$ 被保留(dropout丢弃率为$1-p$);在测试阶段,每个神经单元都是存在的,权重参数 $w$ 要乘以 $p$,变成 $ pw$ 。测试时需要乘上 $p$ 的原因:考虑第一隐藏层的一个神经元在 dropout 之前的输出是 $x$,那么 dropout 之后的期望值是 $E=px+(1−p)0 $,在测试时该神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整$x→px$. 其中 $p$ 是 Bernoulli 分布 $(0-1分布)$ 中值为 $1$ 的概率。

3 Dropout具体工作流程
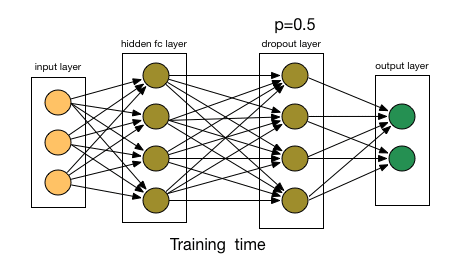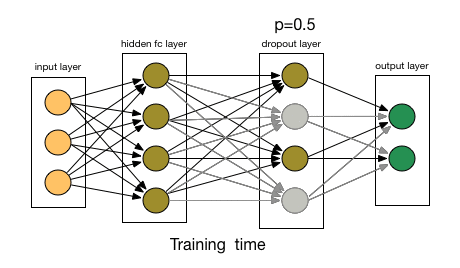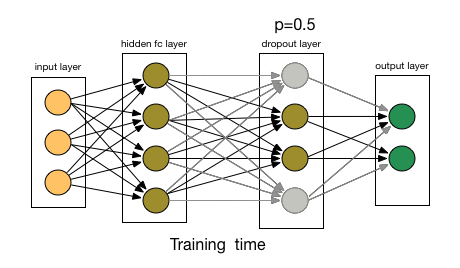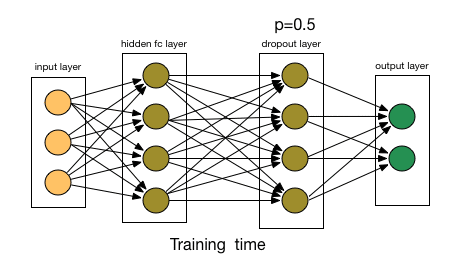
- 为了了解Dropout,假设我们的神经网络结构类似于以下所示:(这里图只有Hidden layer,Output layer)
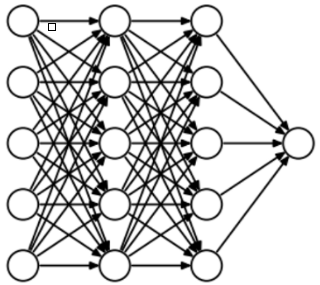
- 输入是 $x$ 输出是 $y$,正常的流程是:我们首先把 $x$ 通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
- (1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变。
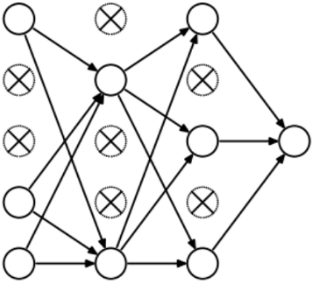
- (2)然后把输入 $x$ 通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数$(w,b)$。
- (3)然后继续重复这一过程:因此,每个迭代都有一组不同的节点,这会导致一组不同的输出。 也可以将其视为机器学习中的集成技术。
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小 $(ρ=0.5)$ 的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数 $(w,b)$ (没有被删除的那一部分参数得到更新,删除的神经元参数,保持被删除前的结果)。
- Dropout也比正常的神经网络模型表现更好。选择应该删除多少个节点的这种可能性是丢失函数的超参数。 如上图所示,Dropout既可以应用于隐藏层,也可以应用于输入层。
机器学习——正则化方法Dropout的更多相关文章
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- [机器学习]正则化方法 -- Regularization
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到. L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合( ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout(转)
ps:转的.当时主要是看到一个问题是L1 L2之间有何区别,当时对l1与l2的概念有些忘了,就百度了一下.看完这篇文章,看到那个对W减小,网络结构变得不那么复杂的解释之后,满脑子的6666------ ...
- 正则化方法L1 L2
转载:http://blog.csdn.net/u012162613/article/details/44261657(请移步原文) 正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者ov ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 模型正则化,dropout
正则化 在模型中加入正则项,防止训练过拟合,使测试集效果提升 Dropout 每次在网络中正向传播时,在每一层随机将一些神经元置零(相当于激活函数置零),一般在全连接层使用,在卷积层一般随机将整个通道 ...
- OpenCV3 Java 机器学习使用方法汇总
原文链接:OpenCV3 Java 机器学习使用方法汇总 前言 按道理来说,C++版本的OpenCV训练的版本XML文件,在java中可以无缝使用.但要注意OpenCV本身的版本问题.从2.4 到3 ...
- [转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam https://blog.csdn.net/u010089444/article/details/76 ...
随机推荐
- (转)Python爬虫--通用框架
转自https://blog.csdn.net/m0_37903789/article/details/74935906 前言: 相信不少写过Python爬虫的小伙伴,都应该有和笔者一样的经历吧只要确 ...
- SQL 练习39
查询各学生的年龄,只按年份来算 SELECT *,year(GETDATE())-YEAR(Sage)年龄 from Student
- SQL 练习4
查询不存在" 01 "课程但存在" 02 "课程的情况 SELECT * from sc WHERE cid = '02' AND sid not in (SE ...
- explorer.exe
explorer.exe是Windows程序管理器或者文件资源管理器, 它用于管理Windows图形壳,包括桌面和文件管理,删除该程序会导致Windows图形界面无法使用. 终止: taskkill ...
- ASP.NET Core教程:ASP.NET Core使用AutoMapper
一.前言 在实际的项目开发过程中,我们使用各种ORM框架可以使我们快捷的获取到数据,并且可以将获取到的数据绑定到对应的List<T>中,然后页面或者接口直接显示List<T>中 ...
- COM笔记-包容与聚合
COM不支持实现继承的原因在于这种继承方式将使得一个对象的实现同另外一个对象的实现紧紧地关联起来.在这种情况下,当基类的实现被修改后,派生类将无法正常运行而必须被修改.这就是为什么一些用C++编写大型 ...
- linux & windows下的动态库制作
动态链接库不是linux独有的特性,在windows下面也存在这样的特性.一般来说,windows下面的动态连接库是以*.dll作为结尾的,而linux下面的动态连接库是以*.so结尾的.和静态链接 ...
- mzy git学习,git协同开发忽略文档配置以及一些杂点(九)
回忆一个电脑多账户问题 之前也说了,如果使用ssh登陆的话,一个电脑就只能登陆一个账号了,不像通过凭据可以切换(但是其实也可以每次去生成新的公钥和私钥,只要你不嫌麻烦) 再次补充: ssh-keyge ...
- Consul 入门-初识
背景 现状:单体架构逐渐被微服务架构所替代,原本两个功能模被拆分成了两个服务.原本两个模块块间的通信只需要函数调用就能够实现,现在却做不到了,因为它们不在同一个进程中,甚至两个服务都可能部署到不同的机 ...
- playwright-python 元素定位、frame处理(一)
浏览器.Browser contexts.frame Playwright 可以同时启动多个浏览器(chromium.Firefox.webkit),每个浏览器可以启动多个page(在Playwrig ...