C语言小知识(基于Linux)——个人笔记,不定时更新
一、switch case语法,在case中定义变量时,需要在case的有效范围内使用花括号包起来,否则会编译报错;
switch (name){
case "zhangSan":{
int age = 13;
break;
}
case "liSi":{
int age = 14;
break;
}
default:{
break;
}
}
二、规定结构体以n字节对齐
在C语言结构体中,字节对齐方式默认为最大类型字节对齐;比如:
struct Class{
char age;
int id;
}class;
这个结构体有两个成员,分别为1字节的age与4字节的id(32位编译时);实际占用了5个字节的空间,但是此时sizeof(class) == 8;因为最大的成员 id 占了4个字节,所以会以4字节对齐;age就会补充3个字节的保留位来字节对齐。
但是在数据流的处理中,为节约资源,一般每个字节甚至每个bit都需物尽其用;所以上述结构只需要5字节有效空间;
此时就可以使用#pragma pack(n)来进行n字节对齐;
#pragma pack(1)
struct Class{
char age;
int id;
}class;
#pragma pack()
现在sizeof(class)就会等于5了;age只占1字节;在结构体之后加上#pragma pack()是为了限制1字节对齐的范围;#pragma pack()之后的数据结构又会以默认最大成员类型来进行字节对齐;
三、结构中按bit定义变量
可以在定义变量时,变量名之后,分号;之前 加上 : n 来规定此变量占用的位数;
#pragma pack(1)
struct ZhangSan{
unsigned char gender_flag : 1;
unsigned char age : 7;
unsigned short height : 6;
unsigned short weight : 6;
unsigned short id : 4;
}zhangSan;
#pragma pack()
此时gender_flag 成员与age 成员就共用一个字节的空间,height 与 weight 与 id 共用两个字节的空间;sizeof(zhangSan) == 3;
四、数据大小端
1.位序
有如下结构:
struct ZhangSan{
unsigned char gender_flag : 1;
unsigned char age : 7;
}zhangSan;
其中 gender_flag 与 age 共用了一个字节(8bit)的空间,一个占1bit,一个占7bit;但是bit占的位置却是与平台相关的;就有可能出现如下两种排列情况:
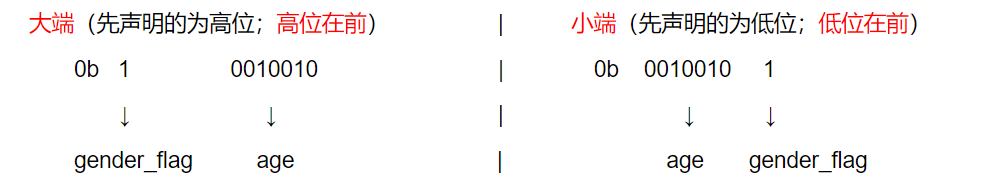
为了解决这种差异化,一般规定传输时的位序都为大端;即在基本类型里声明多个位域时,每个位域看做一个整体,先声明的排在前面,后声明的排在后面;在声明结构体时就可以依据本机的位序来声明位域,从而在接收数据流时能顺利的取出每一个位域。
Linux系统中一般可以通过判断是否定义了宏 __LITTLE_ENDIAN_BITFIELD 与 __BIG_ENDIAN_BITFIELD 来区分当前的位序定义;
若这两个宏同时都没有定义,还可以添加 对字节序的判断来得出本机的位序定义,如下:
#if !defined(__LITTLE_ENDIAN_BITFIELD) && !defined(__BIG_ENDIAN_BITFIELD)
#if (__BYTE_ORDER__==__ORDER_LITTLE_ENDIAN__)
#define __LITTLE_ENDIAN_BITFIELD
#elif (__BYTE_ORDER__==__ORDER_BIG_ENDIAN__)
#define __BIG_ENDIAN_BITFIELD
#endif
#endif
struct ZhangSan{
#if defined(__LITTLE_ENDIAN_BITFIELD)
unsigned char gender_flag : 1;
unsigned char age : 7;
#elif defined(__BIG_ENDIAN_BITFIELD)
unsigned char age : 7;
unsigned char gender_flag : 1;
#endif
}zhangSan;
加了如上修饰之后,即可保证接收到的大端数据流中的位域都能成功的映射到本机所定义的位域;
2.字节序
在数据流跨平台的传递中,经常会遇到大小端不对齐的情况;比如一个int数据在大端机器中的存储方式是高位在前,低位在后,
比如0x33224411在内存中的存放方式就是先存0x33,再存0x22,以此类推。如下:
buf[0] = 0x33;
buf[1] = 0x22;
buf[2] = 0x44;
buf[3] = 0x11;
而小端平台就刚好相反,是低位在前,高位在后;同样的数据0x33224411在小端中的存放方式就是先存0x11,再存0x44,以此类推。如下:
buf[0] = 0x11;
buf[1] = 0x44;
buf[2] = 0x22;
buf[3] = 0x33;
为了使数据统一,所以一般规定了在网络中传输的数据都以大端模式传递,收到数据之后再把数据从大端模式转为本机的模式即可正常使用;
在linux系统的#include <endian.h>中提供了一系类字节序转换的函数:
#include <endian.h>
// 将主机字节序转换为大端字节序
uint16_t htobe16(uint16_t host_16bits);
uint32_t htobe32(uint32_t host_32bits);
uint64_t htobe64(uint64_t host_64bits);
// 将主机字节序转换为小端字节序
uint16_t htole16(uint16_t host_16bits);
uint32_t htole32(uint32_t host_32bits);
uint64_t htole64(uint64_t host_64bits);
// 将大端字节序转换为主机字节序
uint16_t be16toh(uint16_t big_endian_16bits);
uint32_t be32toh(uint32_t big_endian_32bits);
uint64_t be64toh(uint64_t big_endian_64bits);
// 将小端字节序转换为主机字节序
uint16_t le16toh(uint16_t little_endian_16bits);
uint32_t le32toh(uint32_t little_endian_32bits);
uint64_t le64toh(uint64_t little_endian_64bits);
C语言小知识(基于Linux)——个人笔记,不定时更新的更多相关文章
- Go 语言开发的基于 Linux 虚拟服务器的负载平衡平台 Seesaw
负载均衡系统 Seesaw Seesaw是由我们网络可靠性工程师用 Go 语言开发的基于 Linux 虚拟服务器的负载平衡平台,就像所有好的项目一样,这个项目也是为了解决实际问题而产生的. Seesa ...
- Go语言核心36讲(Go语言基础知识一)--学习笔记
01 | 工作区和GOPATH 从 Go 1.5 版本的自举(即用 Go 语言编写程序来实现 Go 语言自身),到 Go 1.7 版本的极速 GC(也称垃圾回收器),再到 2018 年 2 月发布的 ...
- Go语言核心36讲(Go语言基础知识四)--学习笔记
04 | 程序实体的那些事儿(上) 还记得吗?Go 语言中的程序实体包括变量.常量.函数.结构体和接口. Go 语言是静态类型的编程语言,所以我们在声明变量或常量的时候,都需要指定它们的类型,或者给予 ...
- Go语言核心36讲(Go语言基础知识六)--学习笔记
06 | 程序实体的那些事儿 (下) 在上一篇文章,我们一直都在围绕着可重名变量,也就是不同代码块中的重名变量,进行了讨论.还记得吗? 最后我强调,如果可重名变量的类型不同,那么就需要引起我们的特别关 ...
- Go语言核心36讲(Go语言基础知识二)--学习笔记
02 | 命令源码文件 我们已经知道,环境变量 GOPATH 指向的是一个或多个工作区,每个工作区中都会有以代码包为基本组织形式的源码文件. 这里的源码文件又分为三种,即:命令源码文件.库源码文件和测 ...
- Go语言核心36讲(Go语言基础知识三)--学习笔记
03 | 库源码文件 在我的定义中,库源码文件是不能被直接运行的源码文件,它仅用于存放程序实体,这些程序实体可以被其他代码使用(只要遵从 Go 语言规范的话). 这里的"其他代码" ...
- Go语言核心36讲(Go语言基础知识五)--学习笔记
05 | 程序实体的那些事儿(中) 在前文中,我解释过代码块的含义.Go 语言的代码块是一层套一层的,就像大圆套小圆. 一个代码块可以有若干个子代码块:但对于每个代码块,最多只会有一个直接包含它的代码 ...
- 小知识-为什么Linux不需要磁盘碎片整理
转载至:http://beikeit.com/post-495.html 简单译文: 这段linux官方资料主要介绍了外部碎片(external fragmentation).内部碎片(inter ...
- 语言小知识-Java ArrayList类 深度解析
· 问题 1:ArrayList 的 size 和 capacity 怎么理解? 如果把 ArrayList 看作一个杯子的话,capacity 就是杯子的容积,也就是代表杯子能装多少东西,而 siz ...
随机推荐
- WPF 数据绑定实例一
前言: 数据绑定的基本步骤: (1)先声明一个类及其属性 (2)初始化类赋值 (3)在C#代码中把控件DataContext=对象: (4)在界面设计里,控件给要绑定的属性{Binding 绑定类的属 ...
- 翻译:《实用的Python编程》02_06_List_comprehension
目录 | 上一节 (2.5 collections模块) | 下一节 (2.7 对象模型) 2.6 列表推导式 一个常见的任务是处理列表中的项(译注:元素).本节介绍列表推导式,完成此任务的强大工具. ...
- WPF -- DataTemplate与ControlTemplate结合使用
如深入浅出WPF中的描述,DataTemplate为数据的外衣,ControlTemplate为控件的外衣.ControlTemplate控制控件的样式,DataTemplate控制数据显示的样式,D ...
- kali 下的邮件发送工具 swaks
kali 下的邮件发送工具 swaks Swaks 是一个功能强大,灵活,可编写脚本,面向事务的 SMTP 测试工具,目前 Swaks 托管在私有 svn 存储库中. 官方项目 http://jetm ...
- 学习java的第二天
Java第二天 标识符 标识符开头只能以字母和_开头 严格区分大小写 不能以关键词命名 变量 变量是什么:就是可以变化的量 Java是一种强类型语言,定义变量必须声明后才能使用 Java变量是程序中最 ...
- 区分函数防抖&函数节流
1. 概念区分 函数防抖:触发事件后,在n秒内函数只能执行一次,如果触发事件后在n秒内又触发了事件,则会重新计算函数延执行时间. 简单说: 频繁触发, 但只在特定的时间内才执行一次代码,如果特定时间内 ...
- Pytorch1.7报错 Output 0 of UnbindBackward is a view and is being modified inplace
utils里内容改成 if scale_each is True: for idx, _ in enumerate([jj for jj in tensor]): t = tensor[idx] # ...
- Python爬虫学习二------爬虫基本原理
爬虫是什么?爬虫其实就是获取网页的内容经过解析来获得有用数据并将数据存储到数据库中的程序. 基本步骤: 1.获取网页的内容,通过构造请求给服务器端,让服务器端认为是真正的浏览器在请求,于是返回响应.p ...
- Everything is Serverless,从开源框架对比说起
摘要:Everything is Serverless. 在众多云计算解决方案中,Serverless 逐渐崭露头角,受到了很多关注并且发展迅猛,今天就关于serverless 开源框架细说二三. 什 ...
- 鸿蒙第三方组件——SwipeCaptcha滑动拼图验证组件
目录:1.组件效果展示2.Sample解析3.<鸿蒙第三方组件>系列文章合集 前言 基于安卓平台的滑动拼图验证组件SwipeCaptcha( https://github.com/mcxt ...