Kafka 消息存储机制
Kafka 消息以 Partition 作为存储单元,那么在 Partition 内消息是以什么样的格式存储的呢,如何处理 Partition 中的消息,又有哪些安全策略来保证消息不会丢失呢,这一篇我们一起看看这些问题。
Partition 文件存储方式
每个 Topic 的消息被一个或者多个 Partition 进行管理,Partition 是一个有序的,不变的消息队列,消息总是被追加到尾部。一个 Partition 不能被切分成多个散落在多个 broker 上或者多个磁盘上。
它作为消息管理名义上最大的管家内里其实是由很多的 Segment 文件组成。如果一个 Partition 是一个单个非常长的文件的话,那么这个查找操作会非常慢并且容易出错。为解决这个问题,Partition 又被划分成多个 Segment 来组织数据。Segment 并不是终极存储,在它的下面还有两个组成部分:
- 索引文件:以 .index 后缀结尾,存储当前数据文件的索引;
- 数据文件:以 .log 后缀结尾,存储当前索引文件名对应的数据文件。
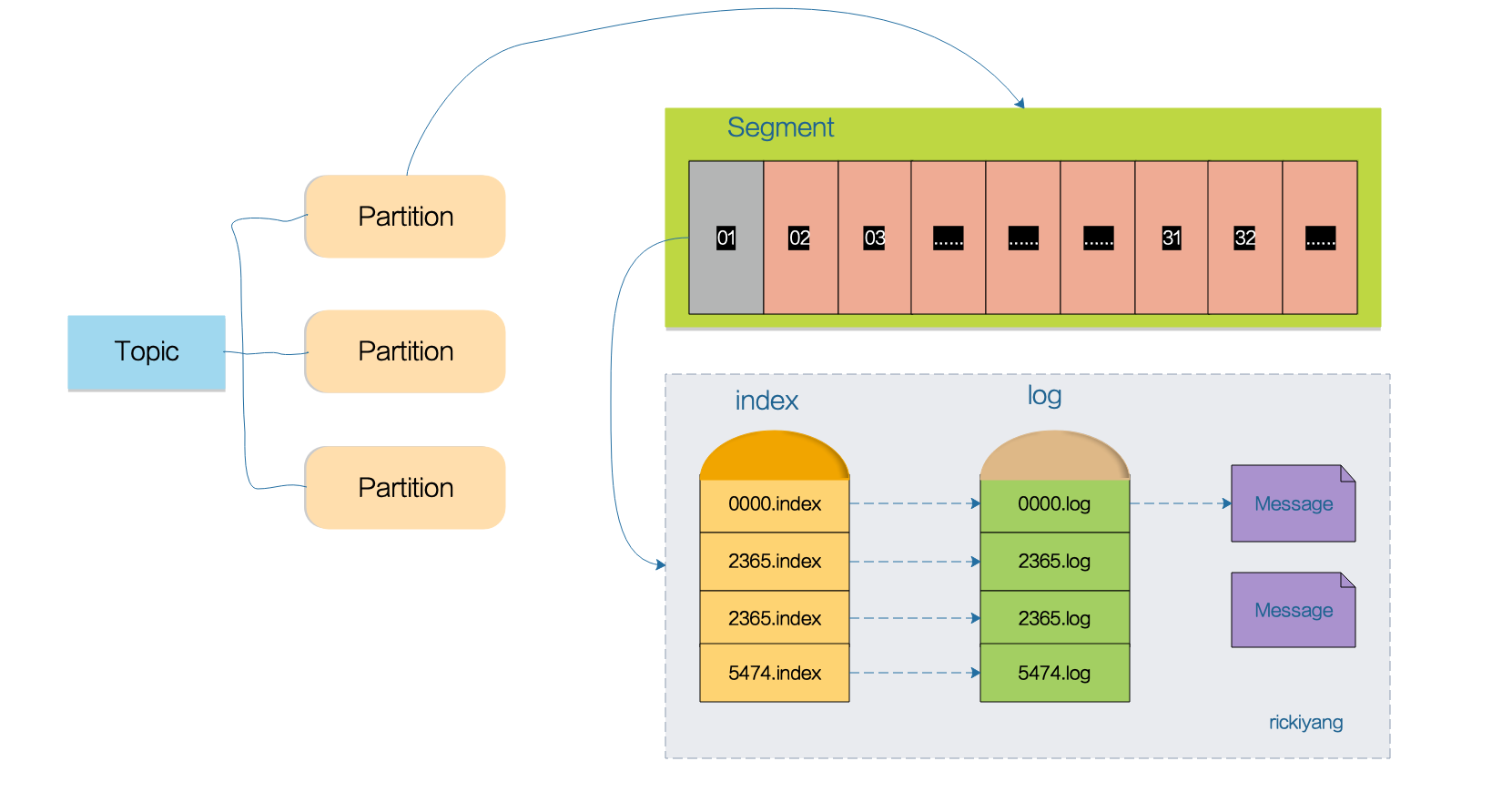
Segment 文件的命名规则是: 某个 Partition 全局的第一个 Segment 从 0 开始,后续每个 Segment 文件名以当前 Partition 的最大 offset(消息偏移量)为基准,文件名长度为 64 位 long 类型,19 位数字字符长度,不足部分用 0 填充。
如何通过 offset 找到 某一条消息呢?
- 首先会根据 offset 值去查找 Segment 中的 index 文件,因为 index 文件是以上个文件的最大 offset 偏移命名的所以可以通过二分法快速定位到索引文件。
- 找到索引文件后,索引文件中保存的是 offset 和对应的消息行在 log 日志中的存储行号,因为 Kafka 采用稀疏矩阵的方式来存储索引信息,并不是每一条索引都存储,所以这里只是查到文件中符合当前 offset 范围的索引。
- 拿到 当前查到的范围索引对应的行号之后再去对应的 log 文件中从 当前 Position 位置开始查找 offset 对应的消息,直到找到该 offset 为止。
每一条消息的组成内容有如下字段:
offset: 4964(逻辑偏移量)
position: 75088(物理偏移量)
CreateTime: 1545203239308(创建时间)
isvalid: true(是否有效)
keysize: -1(键大小)
valuesize: 9(值大小)
magic: 2
compresscodec: NONE(压缩编码)
producerId: -1
producerEpoch: -1(epoch号)
sequence: -1(序号)
isTransactional: false(是否事务)
headerKeys: []
payload: message_0(消息的具体内容)
为什么要设计 Partition 和 Segment 的存储机制
Partition 是对外名义上的数据存储,用户理解数据都是顺序存储到 Partition 中。那么实际在 Partition 内又多了一套不对用户可见的 Segment 机制是为什么呢?原因有两个:
- 一个就是上面提到的如果使用单个 Partition 来管理数据,顺序往 Partition 中累加写势必会造成单个 Partition 文件过大,查找和维护数据就变得非常困难。
- 另一个原因是 Kafka 消息记录不是一直堆堆堆,默认是有日志清除策略的。要么是日志超过设定的保存时间触发清理逻辑,要么就是 Topic 日志文件超过阈值触发清除逻辑,如果是一个大文件删除是要锁文件的这时候写操作就不能进行。因此设置分段存储对于清除策略来说也会变得更加简单,只需删除较早的日志块即可。
Partition 高可用机制
提起高可用我们大概猜到要做副本机制,多弄几个备份肯定好。Kafka 也不例外提供了副本的概念(Replica),通过副本机制来实现冗余备份。每个 Partition 可以设置多个副本,在副本集合中会存在一个 leader 的概念,所有的读写请求都是由 leader 来进行处理。剩余副本都做为 follower,follower 会从 leader 同步消息日志 。
常用的节点选举算法有 Raft 、Paxos、 Bully 等,根据业务的特点 Kafka 并没有完全套用这些算法,首先有如下概念:
- AR:分区中的所有副本统称为 AR (Assigned Replicas)。
- ISR:in-sync replics,ISR 中存在的副本都是与 Leader 同步的副本,即 AR 中的副本不一定全部都在 ISR 中。ISR 中肯定包含当前 leader 副本。
- OSR:Outof-sync Replicas,既然 ISR 不包含未与 leader 副本同步的副本,那么这些同步有延迟的副本放在哪里呢?Kafka 提供了 OSR 的概念,同步有问题的副本以及新加入到 follower 的副本都会放在 OSR 中。AR = ISR + OSR。
- Hight Watermark:副本水位值,表示分区中最新一条已提交(Committed)的消息的 Offset。
- LEO:Log End Offset,Leader 中最新消息的 Offset。
- Committed Message:已提交消息,已经被所有 ISR 同步的消息。
- Lagging Message:没有到达所有 ISR 同步的消息。
每个 Partition 都有唯一一个预写日志(write-ahead log),Producer 写入的消息会先存入这里。每一条消息都有唯一一个偏移量 offset,如果这条消息带有 key, 就会根据 key hash 值进行路由到对应的 Partition,如果没有指定 key 则根据随机算法路由到一个 Partition。
Partition leader 选举
一个 Topic 的某个 Partition 如果有多副本机制存在,正常情况下只能有一个 副本是对外提供读写服务的,其余副本从它这里同步数据。那么这个对外提供服务的 leader 是如何选举出来的呢?这个问题要分为两种情况,一种是 Kafka 首次启动的选举,另一种是启动后遇到故障或者增删副本之后的选举。
首次启动的选举
当 broker 启动后所有的 broker 都会去 zk 注册,这时候第一个在 zk 注册成功的 broker 会成为 leader,其余的都是 follower,这个 broker leader 后续去执行 Partition leader 的选举。
首先会从 zk 中读取 Topic 每个分区的 ISR;
然后调用配置的分区选择算法来选择分区 leader,这些算法有不同的使用场景,broker 启动,znode 发生变化,新产生节点,发生 rebalance 的时候等等。通过算法选定一个分区作为 leader就确定了首次启动选举。
后续变化选举
比如分区发生重分配的时候也会执行 leader 的选举操作。这种情况会从重分配的 AR 列表中找到第一个存活的副本,且这个副本在目前的 ISR 列表中。
如果某个节点被优雅地关闭(也就是执行 ControlledShutdown )时,位于这个节点上的 leader 副本都会下线,所以与此对应的分区需要执行 leader 的选举。这里的具体操作为:从 AR 列表中找到第一个存活的副本,且这个副本在目前的 ISR 列表中,与此同时还要确保这个副本不处于正在被关闭的节点上。
Partition 副本同步机制
一旦 Partition 的 leader 确定后续的写消息都会向这个副本请求操作,其余副本都会同步它的数据。上面我们提到过几个概念:AR 、ISR、 OSR,在副本同步的过程中会应用到这几个队列。
首先 ISR 队列肯定包含当前的 leader 副本,也可能只有 leader 副本。什么情况下其余副本能够进入到 ISR 队列呢?
Kafka 提供了一个参数设置:rerplica.lag.time.max.ms=10000,这个参数表示 leader 副本能够落后 flower 副本的最长时间间隔,当前默认值是 10 秒。就是说如果 leader 发现 flower 超过 10 秒没有向它发起 fetch 请求,那么 leader 就认为这个 flower 出了问题。如果 fetch 正常 leader 就认为该 Follower 副本与 Leader 是同步的,即使此时 Follower 副本中保存的消息明显少于 Leader 副本中的消息。
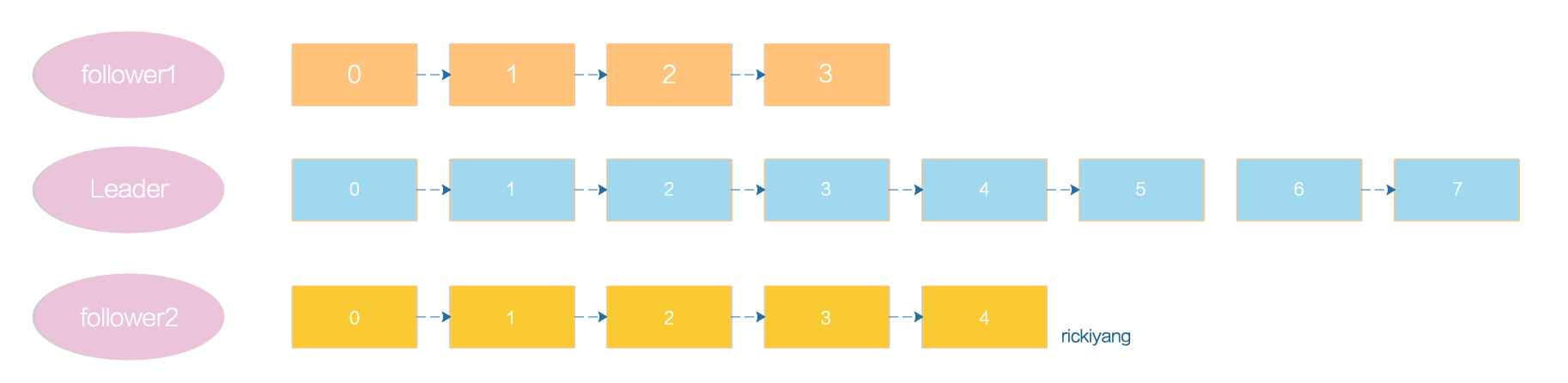
例如上图中的两个 follower 明显慢于 leader,但是如果落后的时间在10 秒内,那么这三个副本都会在 ISR 中存在,否则,落后的副本会被剔除并加入到 OSR。
当然如果后面 follower 逐渐追上了 leader 的进度,那么该 follower 还是会被加入到 ISR,所以 ISR 并不是一个固定不变的集合,它是会动态调整的。
leader 和 follower 之间的数据同步过程大概如下:
初始状态下 leader 和 follower 的 HW 和 LEO 都是 0,follower 会不断地向 leader 发送请求 fetch 数据。但是因为没有数据,这个请求会被 leader 强制拖住,直到到达我们配置的 replica.fetch.wait.max.ms 时间之后才会被释放。同时如果在这段时间内有数据产生则直接返回数据。
Producer 提交 commit 确认机制
Producer 向某个 Topic 推过来一条消息,当前 Topic 的 leader Partition 进行相应,那么如果其余 follower 没有同步成功消息会怎么样呢?这个问题 Kafka 交给用户来决定。
producer 提供了如下配置:
request.required.asks=0
- 0:全异步,无需 leader 确认成功立刻返回,发送即成功。
- 1:leader 接收到消息之后才发送 ack,无需 ISR 列表其他 follower 确认。
- -1:leader 和 ISR 列表中其他 follower 都确认接收之后才返回 ack,基本不会丢失消息(除非你的 ISR 里面只有 leader 一个副本)。
可以看到以上确认机制配置逐级严格,生产环境综合考虑一般选择配置 = 1,如果你的业务对数据完整性要求比较高且可以接收数据处理速度稍慢那么选择 = 2。
offset 保存
某个消费组消费 partition 需要保存 offset 记录当前消费位置,0.10 之前的版本是把 offset 保存到 zk 中,但是 zk 的写性能不是很好,Kafka 采用的方案是 consumer 每分钟上报一次,这样就造成了重复消费的可能。
0.10 版本之后 Kafka 就 offset 的保存从 zk 剥离,保存到一个名为 consumer_offsets 的 Topic 中。消息的 key 由 [groupid、topic、partition] 组成,value 是偏移量 offset。Topic 配置的清理策略是compact。总是保留最新的 key,其余删掉。一般情况下,每个 key 的 offset 都是缓存在内存中,查询的时候不用遍历 Partition,如果没有缓存第一次就会遍历 Partition 建立缓存然后查询返回。

Kafka 消息存储机制的更多相关文章
- Kafka消息存储原理
kafka消息存储机制 (一)关键术语 复习一下几个基本概念,详见上面的基础知识文章. Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker能够组成一个Kafka ...
- Kafka 消息存储及检索(作者:杜亦舒)
Kafka 消息存储及检索 原创 2016-02-29 杜亦舒 性能与架构 Kafka是一个分布式的消息队列系统,消息存储在集群服务器的硬盘Kafka中可以创建多个消息队列,称为topic,消息的生产 ...
- kafka消息存储与partition副本原理
消息的存储原理: 消息的文件存储机制: 前面我们知道了一个 topic 的多个 partition 在物理磁盘上的保存路径,那么我们再来分析日志的存储方式.通过 ll /tmp/kafka-logs/ ...
- kafka存储机制
kafka存储机制 @(博客文章)[storm|大数据] kafka存储机制 一关键术语 二topic中partition存储分布 三 partiton中文件存储方式 四 partiton中segme ...
- Kafka存储机制(转)
转自:https://www.cnblogs.com/jun1019/p/6256514.html Kafka存储机制 同一个topic下有多个不同的partition,每个partition为一个目 ...
- 菜鸟学习Fabric源码学习 — kafka共识机制
Fabric 1.4源码分析 kafka共识机制 本文档主要介绍kafka共识机制流程.在查看文档之前可以先阅览raft共识流程以及orderer服务启动流程. 1. kafka 简介 Kafka是最 ...
- 数据源管理 | Kafka集群环境搭建,消息存储机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.Kafka集群环境 1.环境版本 版本:kafka2.11,zookeeper3.4 注意:这里zookeeper3.4也是基于集群模式部 ...
- [Kafka] - Kafka内核理解:消息存储机制
一个Topic分为多个Partition来进行数据管理,一个Partition中的数据是有序.不可变的,使用偏移量(offset)唯一标识一条数据,是一个long类型的数据 Partition接收到p ...
- Kafka 存储机制和副本
1.概述 Kafka 快速稳定的发展,得到越来越多开发者和使用者的青睐.它的流行得益于它底层的设计和操作简单,存储系统高效,以及充分利用磁盘顺序读写等特性,和其实时在线的业务场景.对于Kafka来说, ...
随机推荐
- Google 灭霸 彩蛋
Google 灭霸 彩蛋 在Google中搜索"灭霸",然后在右侧点击的"无限手套",页面的一些搜索项就会随机性像沙子一样的消失(后面统称沙化效果),特别的炫酷 ...
- react-app 编写测试
jest Enzyme 文档 为什么要写测试 单元测试(unit testing)指的是以软件的单元(unit)为单位,对软件进行测试.单元可以是一个函数,也可以是一个模块或组件.它的基本特征就是,只 ...
- Flutter: OrientationBuilder 根据方向更新UI
文档 api class _HomePageState extends State<HomePage> { @override Widget build(BuildContext cont ...
- (数据科学学习手札108)Python+Dash快速web应用开发——静态部件篇(上)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- Numpy初体验
目录 Numpy 一.简介 1.安装 2.特殊的导包 二.ndarray-多维数组对象 1.创建ndarray数组 1.1 array 1.2 arange 1.3 linspace 1.4 zero ...
- Go的结构体
目录 结构体 一.什么是结构体? 二.结构体的声明 三.创建结构体 1.创建有名结构体 2.结构体初始化 2.1 按位置传参 2.2 按关键字传 3.创建匿名结构体 四.结构体的类型 五.结构体的默认 ...
- 低功耗蓝牙 ATT/GATT/Service/Characteristic 规格解读
什么是蓝牙service和characteristic?如何理解蓝牙profile? ATT和GATT两者如何区分?什么是attribute? attribute和characteristic的区别是 ...
- HDOJ-1074(动态规划+状态压缩)
Doing Homework HDOJ-1074 1.本题主要用的是状态压缩的方法,将每种状态用二进制压缩表示 2.状态转移方程:dp[i|(1<<j)]=min(dp[i|(1<& ...
- 用java输出"Hello,World!"
Hello,World! 一般步骤 随便新建一个文件夹,存放代码 新建一个java文件 新建.txt文档 文件后缀名改为.java Hello.java [注意]系统可能没有显示后缀名,我们需要手动打 ...
- Java 面向对象 03
面向对象·三级 代码块的概述和分类 * A:代码块概述 * 在Java中,使用 { } 括起来的代码被称为代码块. * B:代码块分类 * 根据其位置和声明的不同,可以分为局部代码块, ...