MapReduce08 数据清洗(ETL)和压缩
数据清洗(ETL)
ETL(Extract抽取-Transform转换-Load加载)用来描述数据从来源端经过抽取、转换、加载至目的端的过程。一般用于数据仓库,但其对象并不限于数据仓库
在运行核心业务MapReduce程序之前,往往需要对数据进行清洗,清理掉不符合用户要求的数据,清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
ETL清洗案例
需求
去除日志中字段(通过空格切割)个数小于等于11的日志
输入数据D:\hadoop\hadoop_data\inputlog
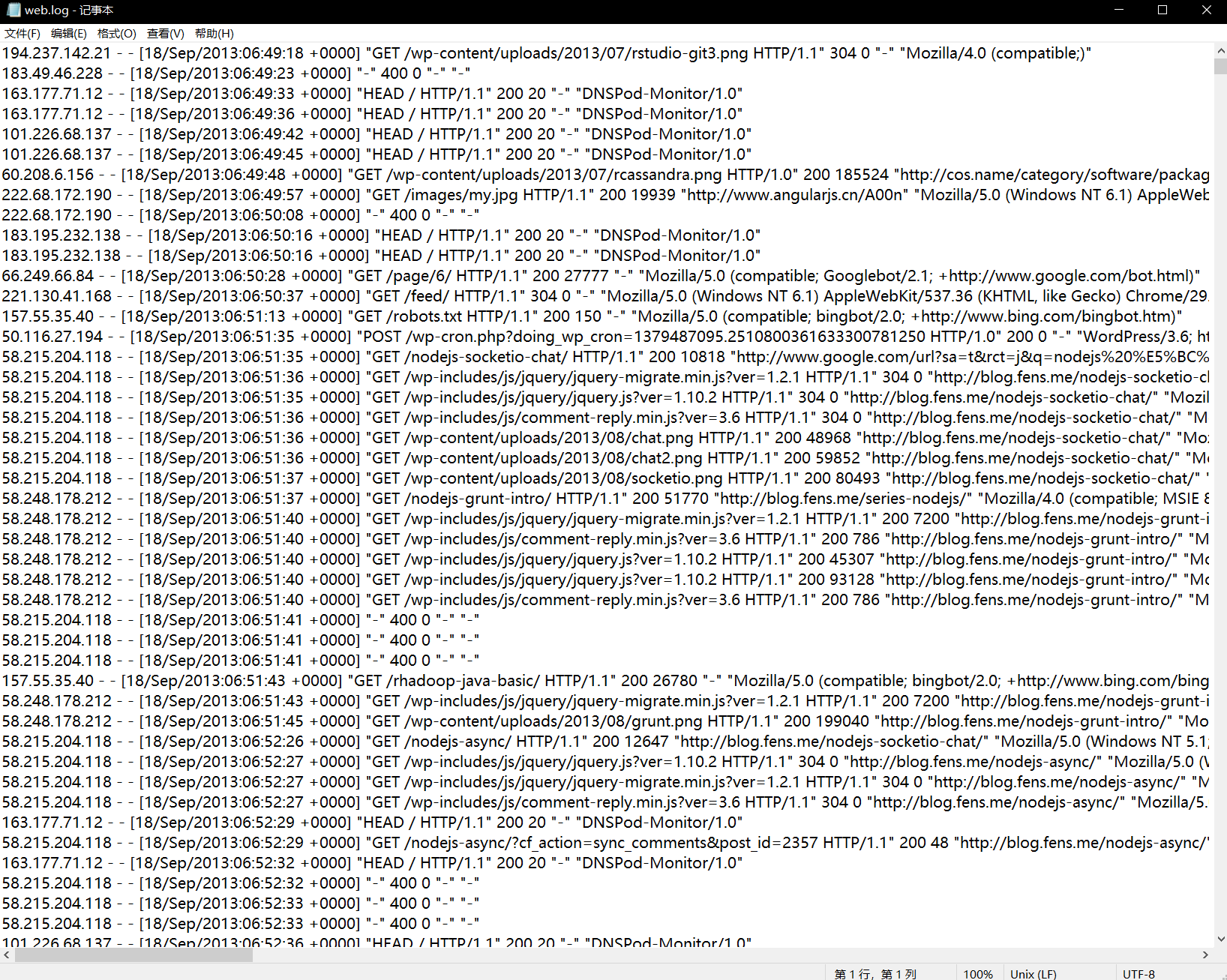
期望输出数据:每行字段长度都大于11
需求分析
需要在Map阶段对输入的数据根据规则进行过滤清洗。
实现代码
编写WebLogMapper类
package com.ranan.mapreduce.etl;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author ranan* @create 2021-09-03 10:39*/class WebLogMapper extends Mapper<LongWritable, Text,Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1.获取一行String line = value.toString();//2.ETL 符合条件就写出到上下文,不符合条件就直接判断下一行boolean result = parseLog(line,context);if (!result){return;}//3.写出context.write(value,NullWritable.get());}private boolean parseLog(String line, Context context) {String[] fields = line.split(" ");if(fields.length >11){return true;}return false;}}
编写WebLogDriver类
package com.ranan.mapreduce.etl;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author ranan* @create 2021-09-03 10:47*/public class WebLogDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Job job = Job.getInstance(new Configuration());job.setJarByClass(WebLogDriver.class);job.setMapperClass(WebLogMapper.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);job.setNumReduceTasks(0);//通过命令行控制,方便上次打包到集群运行FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}}
打包到集群运行
压缩
概念
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
压缩原则
1.运算密集型的Job,少用压缩
2.IO密集型的Job,多用压缩
MR支持的压缩编码
压缩算法对比
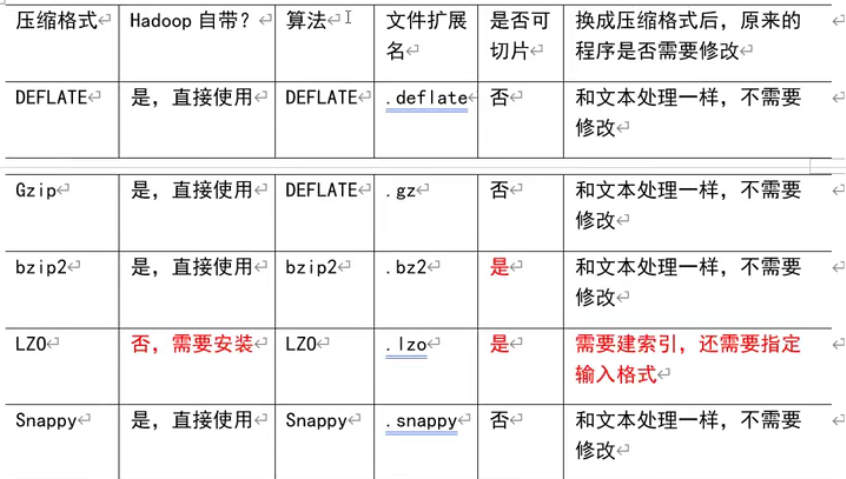
压缩性能比较
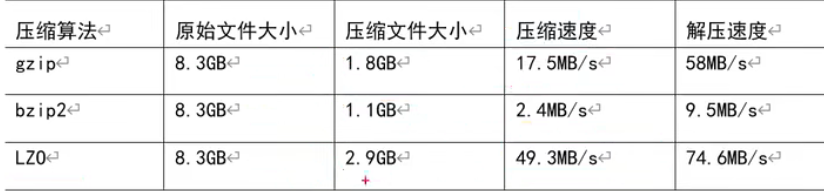
压缩方式选择
压缩方式选择器时需要考虑:压缩/解压缩速度、压缩后的大小、压缩后是否可以支持切片。
| 类型 | 优点 | 缺点 |
|---|---|---|
| Gzip | 压缩率比较高 | 不支持切片;压缩/解压速度一般 |
| Bzip2 | 压缩率高;支持切片 | 压缩/解压速度慢 |
| Lzo | 压缩/解压速度比较块;支持切片 | 压缩率一般;支持切片需要额外创建索引 |
| Snappy | 压缩/解压速度块 | 不支持切片;压缩率一般 |
压缩位置选择
压缩可以再MapReduce作用的任意阶段启用。

压缩参数配置
1.为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器。
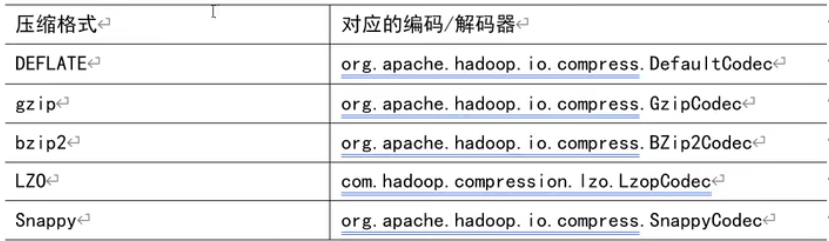
2.要在Hadoop中启用压缩,可以配置如下参数
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs(在core-site.xml中配置) | 无,这个需要在命令行输入hadoopchecknative查看 | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress(在mapred-site.xml中配置) | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
hadoop checknative 查看默认支持的压缩方式
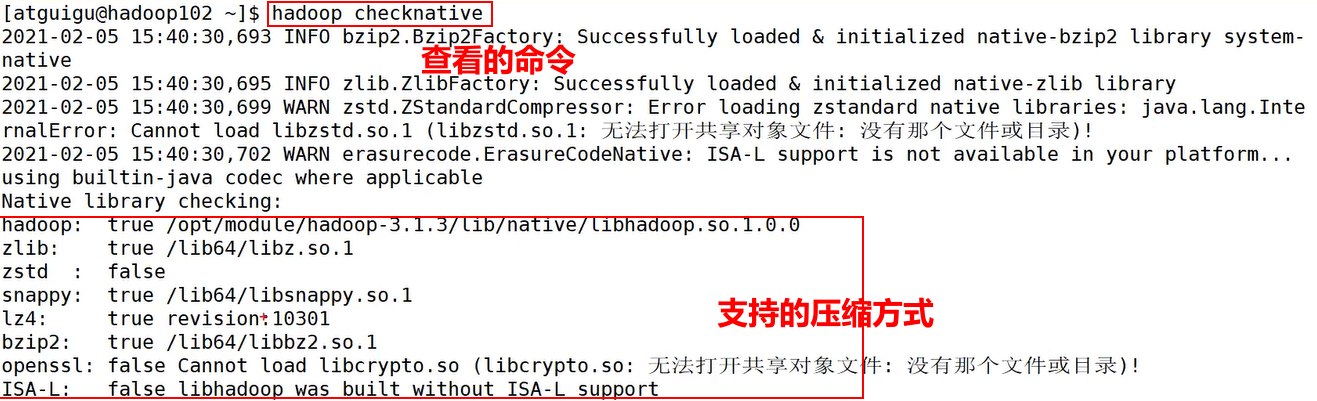
注意:snappy和hadoop的版本需要配对才能适用。
压缩案例实操
Map输出端采用压缩
即使MapReduce的输入输出文件都是未压缩的文件,仍然可以对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。
Driver类
这里用WordCount案例,其余部分保持不变,只修改Driver类。
Map输出压缩文件,Reduce端解压,最终输出的文件格式不变。
//本机Hadoop版本支持的压缩格式有BZip2Codec、DefaultCodecpackage com.atguigu.mapreduce.compress;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.compress.BZip2Codec;import org.apache.hadoop.io.compress.CompressionCodec;import org.apache.hadoop.io.compress.GzipCodec;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException,ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();//开启map端输出压缩conf.setBoolean("mapreduce.map.output.compress", true);//设置map端输出压缩方式conf.setClass("mapreduce.map.output.compress.codec",BZip2Codec.class,CompressionCodec.class);Job job = Job.getInstance(conf);job.setJarByClass(WordCountDriver.class);job.setMapperClass(WoradCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}}
Reduce输出端采用压缩
Driver类
//设置reduce端输出压缩开启FileOutputFormat.setCompressOutput(job, true);//设置压缩的方式FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);//FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//FileOutputFormat.setOutputCompressorClass(job,DefaultCodec.class);
MapReduce08 数据清洗(ETL)和压缩的更多相关文章
- 【电商日志项目之四】数据清洗-ETL
环境 hadoop-2.6.5 首先要知道为什么要做数据清洗?通过各个渠道收集到的数据并不能直接用于下一步的分析,所以需要对这些数据进行缺失值清洗.格式内容清洗.逻辑错误清洗.非需求数据清洗.关联性验 ...
- 建模前的数据清洗/ETL(python)
1. 读取数据 data= open('e:/java_ws/scalademo/data/sample_naive_bayes_data.txt' , 'r') 2. 把数据随机分割为trainin ...
- 日志数据如何同步到MaxCompute
摘要:日常工作中,企业需要将通过ECS.容器.移动端.开源软件.网站服务.JS等接入的实时日志数据进行应用开发.包括对日志实时查询与分析.采集与消费.数据清洗与流计算.数据仓库对接等场景.本次分享主要 ...
- Hawk 2. 软件界面介绍
2. 软件界面介绍 1. 基本组件 Hawk采用类似Visual Studio和Eclipse的Dock风格,所有的组件都可以悬停和切换.包括以下核心组件: 左上角区域:主要工作区,任务管理. 下方: ...
- Hawk 1.1 快速入门(链家二手房)
链家的同学请原谅我,但你们的网站做的真是不错. 1. 设计网页采集器 我们以爬取链家二手房为例,介绍网页采集器的使用.首先双击图标,加载采集器: 在最上方的地址栏中,输入要采集的目标网址,本次是htt ...
- 【重磅开源】Hawk-数据抓取工具:简明教程
Hawk-数据抓取工具:简明教程 标签(空格分隔): Hawk Hawk: Advanced Crawler& ETL tool written in C#/WPF 1.软件介绍 HAWK是一 ...
- 【开源】Hawk-数据抓取工具:简明教程
1.软件介绍 HAWK是一种数据采集和清洗工具,依据GPL协议开源,能够灵活,有效地采集来自网页,数据库,文件, 并通过可视化地拖拽, 快速地进行生成,过滤,转换等操作.其功能最适合的领域,是爬虫和数 ...
- Hawk-数据抓取工具
Hawk-数据抓取工具:简明教程 Hawk: Advanced Crawler& ETL tool written in C#/WPF 1.软件介绍 HAWK是一种数据采集和清洗工具,依据 ...
- 【转】Spark实现行列转换pivot和unpivot
背景 做过数据清洗ETL工作的都知道,行列转换是一个常见的数据整理需求.在不同的编程语言中有不同的实现方法,比如SQL中使用case+group,或者Power BI的M语言中用拖放组件实现.今天正好 ...
随机推荐
- 修改记事本PE结构弹计算器Shellcode
目录 修改记事本PE结构弹计算器Shellcode 0x00 前言 0x01 添加新节 修改节数量 节表位置 添加新节表信息 0x02 添加弹计算器Shellcode 修改代码 0x03 修改入口点 ...
- vue-router 4 你真的熟练吗?
虽然 vue-router 4 大多数 API 保持不变,但是在 vue3 中以插件形式存在,所以在使用时有一定的变化.接下来就学习学习它是如何使用的. 一.安装并创建实例 安装最新版本的 vue-r ...
- this.$set用法
this.$set()的主要功能是解决改变数据时未驱动视图的改变的问题,也就是实际数据被改变了,但我们看到的页面并没有变化,这里主要讲this.$set()的用法,如果你遇到类似问题可以尝试下,vue ...
- ucharts tooltip弹窗自定义换行
这个东西吧,也许是因为菜,看了3小时,下面给出解决方案 1. 找到源码下面的这个文件 2. 增加绿色方框中的代码 3.组件调用的时候有一个opts属性 :opts="{ extra: { t ...
- uni-app 提示 v-for 暂不支持循环数据
这个问题由于目前博主只在APP端遇到过,解决办法是把v-for key值全部取循环的索引,如果解决了你的问题请给博主点个赞 <block v-for="(item,index) in ...
- yum设置取消代理
unset http_proxy unset https_proxy 暂时取消代理,若永久取消代理,需要修改/etc/yum.conf 去掉 proxy=http://proxyhost:8080
- 【JAVA】笔记(5)--- final;抽象方法;抽象类;接口;解析继承,关联,与实现;
final: 1.理解:凡是final修饰的东西都具有了不变的特性: 2.修饰对象: 1)final+类--->类无法被继承: 2)final+方法--->方法无法被覆盖: 3)final ...
- 在dotnet6发布之际,FastNat内网穿透,给开发人员送的硬货福利
一.FastNat可为您解决的问题 1.没有公网服务器,但是想发布共享本地的站点或网络程序到公网上,以供他人访问: 此项功能大大方面开发人员进行远程调试,微信小程序等开发工作进行. 2.需要远程到在其 ...
- 我罗斯方块第二次作业(Block类)
负责任务 完善Block类的相关函数及变量: 对Block类的函数功能进行调试: github项目地址. 开发日记 2020.5.11 今天和朋友们讨论了如何分工的工作,我负责的部分是Block类的完 ...
- FZU ICPC 2020 寒假训练 4 —— 模拟(二)
P1056 排座椅 题目描述 上课的时候总会有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情.不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下来之后,只有有限的 D 对同 ...