大数据分布式存储之Cassandra
分布式存储需要考虑的问题
元数据管理
元数据是指数据本身的标识,通过元数据能很快的找到数据存储的位置,比如在分布式文件系统中,元数据是指文件的路径名+文件名;元数据管理包括集中式元数据管理架构和分布式元数据管理架构;集中式是指将元数据存储到一个节点上,实现简单,但具有单点故障和性能瓶颈的问题;分布式元数据架构是将元数据存储到多个节点上,虽然解决了集中式元数据管理架构的问题,但却引入了数据一致性的问题,如多节点之间的数据如何保持一致;
弹性伸缩
弹性伸缩需要考虑如下两种情况:
- 某一节点宕机或磁盘坏掉的情况下如何保障系统还能正常运行并且数据不丢失;
- 数据和计算资源的负载均衡:当前数据库集群已经无法容纳更多的数据时,如何通过加入新的数据节点分摊数据;或当前的数据库集群算力已经达到顶峰时,如何通过加入新的节点分摊算力;如何保证计算和数据均匀分布,避免某一节点成为热点或瓶颈;
性能与成本
高效而合理的存储结构应在保障数据库性能的情况下,最大程度降低系统能耗和构建/管理成本;如如何保障数据库查询不会扫描整个数据库集群?如何在算力、存储不足的情况下能不加人为干预的动态加入新的节点?
CAP理论
作为分布式存储系统的奠基石,CAP理论提出了在分布式系统架构过程中必须考虑的三个因素:
- C(一致性Consistency):对写入的数据,分布式系统中的所有的备份节点是否都能得到最新的数据副本;
- A(可用性Availability):对每个读取/写入请求,都能得到相应的结果;
- P(分区容错Partition tolerance):分布式集群中任何节点的宕机都不会影响整个系统的继续运作;
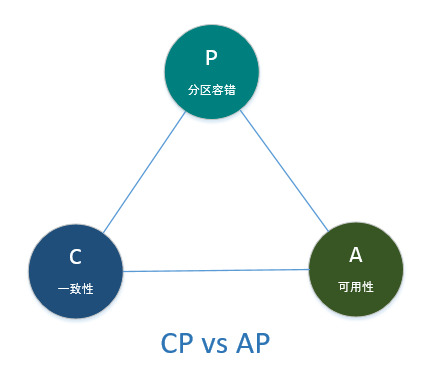
在分布式存储系统中,一致性、分区容错、可用性三者很难完全达到,只能满足其中之二,但分区容错又是必须满足的,因此CAP最终演变为了CP和AP的对决。
Cassandra
特点
去中心化
相对于传统的集中式元数据管理架构和Master/Slave的分布式数据库架构,Cassandra采用了P2P(Peer-to-peer对等网络)协议,通过Gossip协议来维护和同步节点信息;
每隔一秒,数据节点就会从集群中随机选择一个节点,并初始化与它的一个Gossip会话,并发送一个GossipDigestSynMessage;这个节点收到消息时,会返回一个GossipDigestAckMessage;发送者收到ACK消息时,会再次发送一个GossipDigestAck2Message并结束此轮Gossip会话;
Cassandra采用累积型故障探测(对历史数据进行累计与分析)方法判断某个节点是否下线;每个节点的存活与死亡都存在一个可信度,可信度是一个随时间变化连续的值,当可信度达到low threshold时,会被判断为逻辑死亡,其他节点不会将读写操作发送至该节点,当可信度达到moderate thresold的时候时,则被判断为物理死亡;
对等网络中分布式一致性问题:

Cassandra使用Paxos共识算法确保在分布式对等节点里达成一致结果,而不需要一个主节点协调。
在Paxos算法中,每个节点都可以担任协调者的角色,向其他副本节点提议一个新值,每个副本节点会检查该提议,如果这个提议是它看到的最新的提议,它会承诺不接受与之前任何提议关联的提议,每个副本节点都会返回它接收到的最新的提议,如果这个提议被大多数副本接受,协调者就会提交这个提议。
可调复制一致性级别
Cassandra可通过可调节的一致性级别满足CP和AP的需要;
写复制一致性级别(不完全列表)
| 一致性级别 | 含义 |
| ANY | 弱一致性,写数据时,只要确保这个值能写入到一个节点即保证写入成功 |
| QUORUM | 确保至少大多数副本(副本因子/2+1) |
| ALL | 强一致性,要求要写入到所有副本,如果有一个副本没有响应,则操作失败 |
如果写复制一致性级别没有设置为ALL的时候,必然会导致一些副本节点保存的数据不是最新数据,因此要使用修复功能完成节点间的数据同步:读修复和逆熵修复;
读修复是指Cassandra从多个副本读取出数据,并检测到某些副本包含过期的数据,如果有最新值的节点数量不够,就需要进行读修复来更新那些过期的副本;
逆熵修复是一种在节点上手动的修复方式,通过判断两个副本之间Merkle树是否相等来确定两个副本的数据是否一致,如果不一致,则进行修复。
读一致性级别(不完全列表)
| 一致性级别 | 含义 |
| ONE,TWO,THREE | 立即返回响应查询的第一个节点包含的记录,创建一个后台线程对这个记录与其他副本上相同的记录做比较,如果过期则进行读修复 |
| QUORUM | 查询所有节点,一旦大多数节点(副本因子/2+1)做出响应,则向客户端返回最新时间戳的值,必要时进行读修复 |
| ALL | 查询所有节点,等待所有节点做出响应,向客户端返回具有最新时间戳的值,必要时进行读修复 |
易操作的数据接口
Cassandra作为NoSQL技术的代表性数据库,提供了类似于SQL语言的CQL查询语言,比如创建一个user表:
CREATE TABLE user(first_name text, last_name text, PRIMARY KEY(first_name));
当需要向user表中插入一条记录时,可以使用下面的脚本:
INSERT INTO user(first_name, last_name) VALUES('Bill', 'Nguyen');
当要进行数据查询时,可以使用:
SELECT COUNT(*) FROM user;
数据分布
在早期的Cassandra版本中,将这个集群中的节点连接为一个环,并为环中的每个物理节点分配一个数据区间或范围,由一个令牌来表示,通过这个令牌来确定数据在环中的位置:
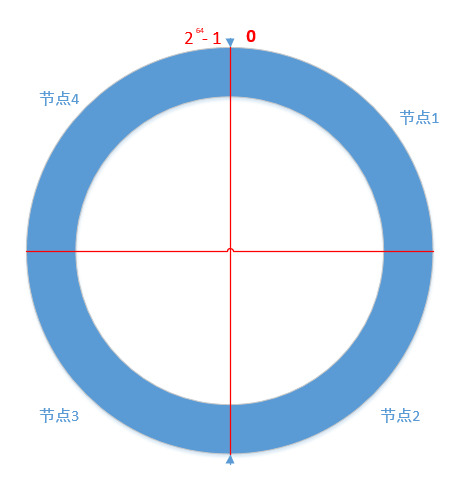
当插入数据时,会通过一个Hash函数计算得到要插入数据的Hash值,通过这个Hash值得到这个数据在环中所处的位置或区间,并确定拥有这个数据的节点;但采用这种方式会存在一个问题,即增加或替换节点会有非常大的开销,再平衡数据分布时会移动大量的数据;
因此在Cassandra后期的版本中引入了虚拟节点,即不再为物理节点分配一个令牌,而将令牌区间分解为多个小区间(每个小区间对应一个虚拟节点),这样每个物理节点就会被分配多个虚拟节点;在增加或替换节点时只需要迁移相应的虚拟节点即可。
高性能的写操作
写日志优先
Cassandra进行写操作时,会优先写入提交日志,提交日志是支持Cassandra持久性目标的一种失败恢复机制;
基于内存写的数据结构
在提交日志成功之后,值会被写入到一个内存的数据结构中,这个内存结构称之为memtable,每个表都会有一个或多个独立的memtable;
当存储在memtable中的记录数量达到一个阈值的时候,memtable中的内容会被刷到磁盘里一个名为SSTable的文件中,然后再创建一个新的memtable;刷盘是非阻塞操作,与数据写入可以同时进行;在memtable刷入成功之后会删除掉对应的日志;
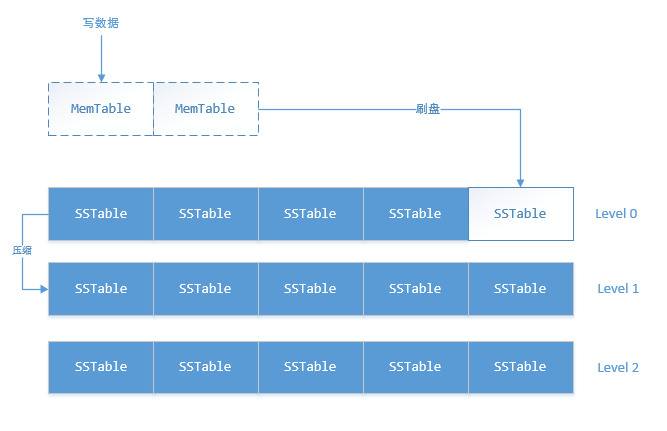
数据合并
Cassandra对数据的写操作都是以追加的方式顺序进行,并不需要任何读或者查找操作,这就会导致同一条数据的操作分布到多个SSTable中;同时SSTable是不可变的;
Cassandra的删除操作并不是立即删除,只是在值上放置一个墓碑,墓碑相当于删除标志,等到可以运行合并的时候,才真正删除Cassandra中的老数据;
合并触发的条件:每个层级下面会有多个SSTable,当某个层级的SSTable文件数量达到Threshold之后,会将该层级的SSTable与上一层级的SSTable文件合并,并写入到新的SSTable中;合并过程中,键会归并、列会组合、墓碑将会被删除。
增强式的读操作
由于对数据的更新都是顺序,势必会导致对同一条记录多次更新的数据会落入到多个SSTable或MemTable中。
为提高查询的速度,Cassandra使用BloomFilter检测记录是否存在于SSTable中,由于BloomFilter存在误报的现象(不存在的记录判断为存在),可通过增加过滤器内存大小减少误报率。
大数据分布式存储之Cassandra的更多相关文章
- 分布式大数据高并发的web开发框架
一.引言 通常我们认为静态网页html的网站速度是最快的,但是自从有了动态网页之后,很多交互数据都从数据库查询而来,数据也是经常变化的,除了一些新闻资讯类的网站,使用html静态化来提高访问速度是不太 ...
- 大数据:Hadoop(简介)
一.简介 定义:开源的,做分布式存储与分布式计算的平台: 功能:搭建大型数据仓库,对PB级数据进行存储.处理.分析.统计等业务:(如日志分析.数据挖掘) Hadoop工作模块 Common:提供框架和 ...
- 大数据学习笔记之初识Hadoop
1.Hadoop概述 1.1 Hadoop名字的由来 Hadoop项目作者的孩子给一个棕黄色的大象样子的填充玩具的命名 Hadoop的官网:http://hadoop.apache.org . 1.2 ...
- 阿里巴巴飞天大数据架构体系与Hadoop生态系统
很多人问阿里的飞天大数据平台.云梯2.MaxCompute.实时计算到底是什么,和自建Hadoop平台有什么区别. 先说Hadoop 什么是Hadoop? Hadoop是一个开源.高可靠.可扩展的分布 ...
- Hadoop是一种开源的适合大数据的分布式存储和处理的平台
"Hadoop能做什么?" ,概括如下: 1)搜索引擎:这也正是Doug Cutting设计Hadoop的初衷,为了针对大规模的网页快速建立索引: 2)大数据存储:利用Hadoop ...
- GoldenGate实时投递数据到大数据平台(2)- Cassandra
简介 GoldenGate是一款可以实时投递数据到大数据平台的软件,针对apache cassandra,经过简单配置,即可实现从关系型数据将增量数据实时投递到Cassandra,以下介绍配置过程. ...
- spark + cassandra +postgres +codis 大数据方案
1.环境: 1.1.cassandra 集群: 用于日志数据存储 1.2.spark集群: 用户后期的实时计算及批处理 1.3.codis 集群: 用于缓存一些基本数据如IP归属地,IP经纬度等,当日 ...
- 低调、奢华、有内涵的敏捷式大数据方案:Flume+Cassandra+Presto+SpagoBI
基于FacebookPresto+Cassandra的敏捷式大数据 文件夹 1 1.1 1.1.1 1.1.2 1.2 1.2.1 1.2.2 2 2.1 2.2 2.3 2.4 2.5 2.6 3 ...
- 关于大数据时代传统商业存储的思考: 中心存储 VS 分布式存储
尊重原创,转载请注明出处:http://anzhan.me ; http://blog.csdn.net/anzhsoft 今天和我们部门的老大1*1, 大家面对面沟通了一下到新的项目组的想法.而且也 ...
随机推荐
- Redis - 1 - linux中使用docker-compose安装Redis - 更新完毕
0.前言 有我联系方式的那些半吊子的人私信问我:安装Redis有没有更简单的方式,网上那些文章和视频,没找到满意的方法,所以我搞篇博客出来说明一下我的安装方式吧 1.准备工作 保证自己的linux中已 ...
- 紧张 + 刺激,源自一次 OOM 历险
作者 | 蚂蝗 背景 Erda 是集 DevOps.微服务治理.多云管理以及快数据管理等多功能的开源一站式企业数字化平台.其中,在 DevOps 模块中,不仅有 CI/CD.项目协同等功能,同时还 ...
- day06 HTTP协议
day06 HTTP协议 HTTP协议 什么是http? HTTP 全称:Hyper Text Transfer Protocol 中文名:超文本传输协议 是一种按照URL指示,将超文本文档从一台主机 ...
- 应用springMVC时如果配置URL映射时如下配置
应用springMVC时如果配置URL映射时如下配置 [html] view plaincopy<servlet> <servlet-name>appServlet</s ...
- js实现递归菜单无限层
/*动态加载菜单*/ function dynamicMenu(data){ if (userID != "admin"){ //1.清空所有菜单 $("#menuLis ...
- 如何在linux 上配置NTP 时间同步?
故障现象: 有些应用场景,对时间同步的要求严格,需要用到NTP同步,如何在linux上配置NTP时间同步? 解决方案: 在linux 上配置NTP 时间同步,具休操作步骤,整理如下: 1.安装软件包( ...
- 为什么Redis集群有16384个槽
一.前言 我在<那些年用过的Redis集群架构(含面试解析)>一文里提到过,现在redis集群架构,redis cluster用的会比较多. 如下图所示 对于客户端请求的key,根据公式H ...
- 01-gevent完成多任务
gevent完成多任务 一.原理 gevent实现多任务并不是依靠多进程或是线程,执行的时候只有一个线程,在遇到堵塞的时候去寻找可以执行的代码.本质上是一种协程. 二.代码实现 import geve ...
- [BUUCTF]PWN14——not_the_same_3dsctf_2016
[BUUCTF]PWN14--not_the_same_3dsctf_2016 题目网址:https://buuoj.cn/challenges#not_the_same_3dsctf_2016 步骤 ...
- 字节面试:SYN 包在什么场景下会被丢弃?
大家好,我是小林. 之前有个读者在秋招面试的时候,被问了这么一个问题:SYN 报文什么时候情况下会被丢弃? 好家伙,现在面试都问那么细节了吗? 不过话说回来,这个问题跟工作上也是有关系的,因为我就在工 ...