论文翻译:2020_Acoustic Echo Cancellation by Combining Adaptive Digital Filter and Recurrent Neural Network
论文地址:https://arxiv.53yu.com/abs/2005.09237
自适应数字滤波与循环神经网络相结合的回声消除技术
摘要
回声消除(AEC)在语音交互中起关键作用。由于明确的数学原理和适应条件的智能特性,具有不同实现类型的自适应滤波器始终用于AEC,从而提供了可观的性能。但是,结果中会存在某种残留回波,包括估计和实际之间不匹配引起的线性残留以及主要由音频设备上的非线性分量引起的非线性残留。可以通过精细的结构和方法减少线性残留,但非线性残留难以抑制。尽管已经提出了一些非线性处理方法,但是它们复杂且抑制效率低,并且会给语音音频带来损害。本文提出了一种将自适应滤波器与神经网络相结合的融合方案。通过自适应滤波可以大幅度减少回声,从而几乎没有残留回声。尽管它比语音音频小得多,但它也能被人耳察觉,从而影响通信。通过精心设计和训练神经网络,以抑制此类残留回波。并与主流方法进行实验比较,验证了所提出的组合方案的有效性和优越性。
关键字:声学回声消除,AEC,残差回波,自适应滤波器,神经网络,RNN, GRU
1 引言
如果声音被扬声器本身[1]听到,就会产生回声。这种现象在通信、娱乐、人机交互以及其他领域都非常普遍。它可能在某些场景中有用,比如娱乐活动。但是,在大多数情况下,特别是在语音交互和通信中,它是干扰,应该从重要的语音音频[2]中消除。
由于回波源是一个参考信号,因此通常采用自适应滤波器进行声学回声消除(AEC)。目前已有许多自适应算法,如最小均方(LMS)[3],归一化LMS(NLMS)[4],块LMS(BLMS)[5]等。每一种都有自己的优点和特殊的应用。为了获得可观的性能,需要数百甚至数千个过滤器长度。由于采用快速傅里叶变换(FFT)有效地实现BLMS算法大大降低了计算量,因此基于LMS算法的频域块自适应滤波器(FDBAF)被认为是最适合的[6]算法。此外,为了适应FFT中较大的分组延迟和量化误差,提出了一种更加灵活的频域自适应滤波器结构,称为多延迟分组频域(MDF)自适应滤波器[7]。
此外,为获得更具鲁棒性的回声消除,同时还提出了根据双讲和回波路径变化等条件调整学习速率的方法。简单地说,在AEC中使用自适应滤波器的算法有很多,具有较好的性能。
不幸的是,自适应滤波后会有一些残留回波。虽然在大多数情况下,它的振幅比语音音频小得多,但它也可以被人的耳朵感知到,会使交流变得烦恼。这些残差包括由估计与现实不匹配引起的线性残差和主要由音频设备中的非线性分量引起的非线性残差。线性残差可以通过精细的结构和方法进行还原,如[8][9-12],而非线性残差则难以抑制。虽然,一些非线性处理(NLP)方法已经提出,但算法处理是复杂的,并且可能无法有效地进行抑制[13,14]。而且,这些NLP方法会对语音音频[15]造成损害。此外,一些其他的方法,如非线性滤波[16]和建模估计[17]也用于非线性回声消除。
通过对残差回波频谱与语音音频频谱的比较,可以认为残差是一种噪声。此外,远端参考信号也可以为残差抑制提供一些关系。在此基础上,提出了一种将自适应滤波器与神经网络相结合的组合方案。受回声干扰的语音音频首先由具有自适应学习速率的MDF滤波器处理,以消除主回声信号。此后,精心设计并训练了具有明显结构的神经网络,以抑制残余回声。在回声回波损耗增强(ERLE),对数谱距离(LSD),响应时间(RT),模型大小等方面,将该方法与其他主流方法进行了比较。
2 算法结构
2.1 组合方案
自适应滤波器与神经网络相结合的集成方案如图1所示。自适应滤波器用于消除多径或房间脉冲响应(RIR)[18]引入的线性回波。实践证明,该算法具有相当好的性能和较低的复杂度。通过及时调整有限脉冲滤波器(FIR)的加权系数来估计RIR,从而得到回波信号的估计副本。但由于设备上装有非线性元件,例如线性度较差的扬声器,会引入非线性回声。它不能被FIR结构的自适应滤波所消除,从而产生残差回波。如图2所示,与语音音频相比,自适应滤波后的残差回波幅度减小到小尺度。它能够被认为是一种特殊类型的噪音。同时,该噪声可能与远端参考信号有一定的关系。因此,基于这些观察结果,我们将设计一个神经网络,并对其进行专门的训练,以抑制此类残留回声,如图1所示。
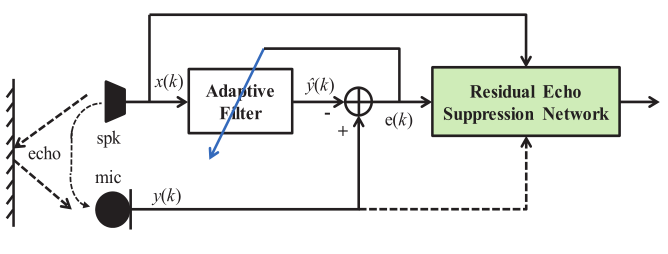
图1 组合方案结构
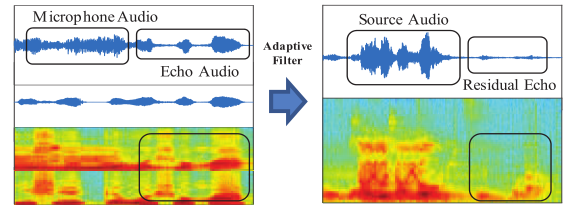
图2 自适应滤波后的残余回声
2.2 自适应滤波器
由于多延迟块频域自适应滤波器具有存储容量小、FFT大小较小、可根据使用的硬件选择不同的配置等诸多优点,因此被用于线性回声消除的组合方案中。此外,正如Speex的开源软件[19,20]所使用的那样,自适应滤波器中的学习率是根据双讲和回波路径变化等条件控制变化的。在这种情况下,线性回波可以自适应地大大消除。
长度为N的复数NLMS滤波器定义为:
\]
适应步骤为:
\]
其中\(x(n)\)是远端信号,\(d(n)\)是接收到的麦克风信号,\(\hat{y}(n)\)是自适应滤波器估计的回声,\(e(n)\)是相应的估计误差,\(w_{k}(n)\)是在时间n处的滤波器权重,\(\hat{w}_{k}(n)\)是估计的权重,\(\mu\)是学习率。
为了在双向通话的情况下获得快速响应,以防止双向通话开始时滤波器发生分歧,将学习率更新为[8]
\]
其中\(\hat{Y}(k, l)\)和\(E(k, l)\)是\(\hat{y}(n)\)和\(e(n)\)的频域对应部分,\(k\)是频率索引,\(l\)是帧索引,\(\hat{\eta}(l)\)是代表滤波器失调的估计泄漏系数。它等于估计的回波功率\(P_{Y}(k, l)\)与输出功率\(P_{E}(k, l)\)之间的线性回归系数:
\]
其中,将\(R_{E Y}(k, l)\)和\(R_{Y Y}(k, l)\)的相关性递归平均为:
&R_{E Y}(k, l)=(1-\beta(l)) R_{E Y}(k, l)+\beta(l) P_{Y}(k) P_{E}(k) \\
&R_{Y Y}(k, l)=(1-\beta(l)) R_{Y Y}(k, l)+\beta(l)\left(P_{Y}(k)\right)^{2} \\
&\beta(l)=\beta_{0} \min \left(\frac{\hat{\sigma}_{Y}^{2}(l)}{\hat{\sigma}_{e}^{2}(l)}, 1\right)
\end{aligned} (5)
\]
其中\(\beta_{0}\)是泄漏估计的基本学习速率,\(\hat{\sigma}_{\hat{Y}}^{2}(l)\)和\(\hat{\sigma}_{e}^{2}(l)\)是估计的回波和输出信号的总功率。当不存在回声时,可变平均参数\(\beta(l)\)阻止对估计值进行调整。
然而,由于器件中存在非线性分量,自适应滤波器的输出端会产生非线性残差回波。此外,如果估计的RIR与实际的RIR不匹配,还会引入一些线性残差回波。如图2所示,这些都会导致相当大的残余回波。随着器件非线性的增加和RIR估计误差的增加,这种残余回波将变得更加严重。
2.3 神经网络
2.3.1 网络结构
受[21]的启发,精心设计了基于RNN的残差回声抑制网络结构,如图3所示。在这里,RNN的每个模块都由门控循环单元(GRU)实现,用于数据存储和网络计算。这种结构主要是指传统回声消除的功能架构,包括双讲检测、回波估计和回声消除三个功能模块。双讲检测实时检测远端和近端信号,只有检测到远端信号时才会进行回声抑制。此时,对自适应滤波后的信号进行残差回波估计。回声消除,估计子带的增益,迅速改变每个频带的电平,以衰减回波,但允许信号通过。利用子带增益进行计算的原因是它使模型非常简单,只需要很少的带宽计算。此外,也没有所谓的音乐噪音伪影。
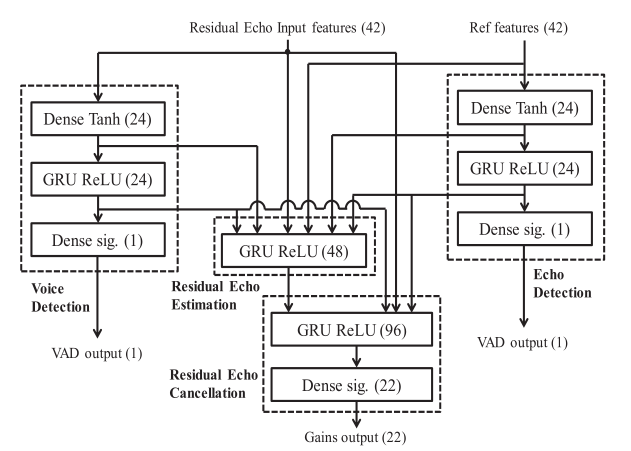
图3 残差回声抑制网络结构
1 特征提取
为了减少神经元的数量从而减少模型的大小,没有直接使用样本或频。相反,采用【带树皮尺度的频带(the frequency band with bark scale is employed),,???】,与人类的感知相匹配。在这种情况下,总共使用了22个频率子带,即树皮频率倒谱系数(BFCC)。此外,前六个BFCC特征的一阶和二阶差分,前六个音高的离散余弦变换(DCT)提取相关系数和动态特征,即基音周期和频谱非平稳性指标[21]。这些结果总共得到42个特征,作为残差回声抑制神经网络的输入数据。
2 双讲检测
自适应滤波后,只保留语音信号和残余回波。由于自适应滤波后的残差回波幅值较小,可以很容易地检测出语音的声音活动。同时,参考信号的远端语音活动由于其纯度高,也易于检测。在这种情况下,每个信道可以独立实现两个语音活动检测(VADs),降低了DTD的难度。
3 残余回声消除
作为循环神经网络(RNN)的一种实现,门控递归单元(GRU)模块利用参考信号的输入特征、自适应滤波的输出信号和DTD结果来估计残差回波。由于RNN模型的记忆功能,相对于其他模型,RNN模型可以更好地估计残差回波。
4 残余回声抑制
通过计算子带增益,采用由全连接层连接的GRU模块进行回波抑制。如果近端即自适应滤波输出的VAD为零,则接近零;如果远端参考信号的VAD为零,则接近1。否则,估计一个小数表示语音与残余回声叠加的比率。
由于仅通过网络计算频带增益,不能直接应用于每个频率。因此,为了获得频率增益,需要在频带之间进行线性插值,如图4所示,并可以公式化表示为:
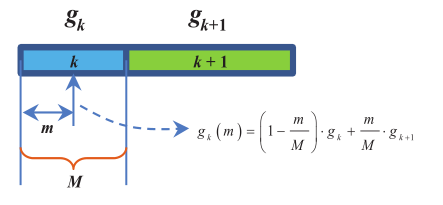
图4 线性插值示意图
\]
其中\(g_{k}(m)\)是第k个频带的第m个频率的增益,\(g_{k}\)和\(g_{k+1}\)是第\(k\)个频带和第\(k+1\)个频带的频带增益,\(M\)表示第\(k\)个频带的频带长度。
2.3.2 双讲检测训练
训练数据可以手工注释,也可以模拟。手动标注数据是通过监听远端或近端是否有音频以及在哪里有音频来获取的。其中记录了源播放的音频和设备本身播放的音频。但是,这种方法很耗时。因此,我们使用仿真数据进行训练。如图5所示,总结如下:
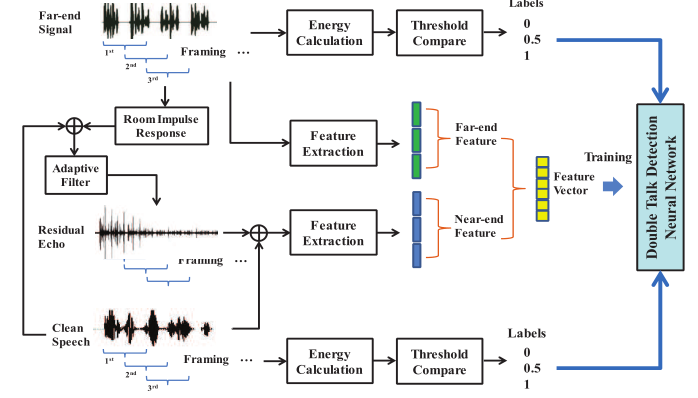
图5 双讲检测训练流程图
1 远端数据准备。远端数据是用于回声消除的参考信号,是设备自身扬声器播放之前在参考信道中传输的音频文件。该参考信号被加框加窗,然后用于能量计算。将此能量值与两个阈值进行比较,如果大于较高的阈值,则用“1”标记,如果小于较低的阈值,则用“0”标记,否则,用“0.5”标记。该标签是逐帧计算的,表示音频存在的概率,并结合特征向量进行计算。
2 近端数据准备。这里的近端数据是自适应滤波后的信号,消除了巨大的回波,特别是线性回波。而回波信号则通过参考信号与RIRs的卷积得到。该回波信号与干净的语音音频文件混合,以模拟麦克风接收信号。然后对这个麦克风信号进行自适应滤波处理。然后,用残差回波混合得到干净的语音,代表训练的近端数据。通过直接计算能量并与阈值进行比较,可以很容易地得到表示是否有干净话语的标签。值得注意的是,由于残差回波的幅值相对干净语音的幅值较小,也可以通过自适应滤波后直接计算信号能量得到标签。同样,计算每一帧对应的特征向量。
3 训练过程。由于通过比较帧能量和阈值可以直接获得两个信道的标签,因此可以使用VADs单独实现语音检测。通过特征向量及其标签,可以很容易地训练出每个信道的VAD模块。
2.3.3 残余回声抑制训练
残差回波抑制网络的目的是计算频带增益,其训练过程如图6所示。
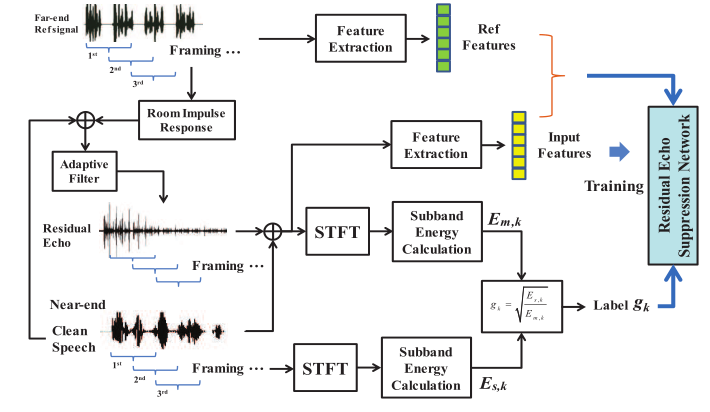
图6 频带增益训练流程图
除带增益标签外,远端和近端数据以上述相同的方式准备。可以通过计算以\(E_{s, k}\)表示的干净语音的频带能量和以\(E_{m, k}\)表示的自适应滤波后的残留信号的频带能量,然后将它们逐段划分以获得标签,即\(g_{k}=\sqrt{\frac{E_{B, k}}{E_{m, k}}}\),来获得这些值。同时,这两个通道的特征向量与前述相同。
3 性能评估
模型的训练。
模型结构可以显示为3。总共构造了10个小时的语音和5个小时的回声数据,通过使用增益和滤波器的各种组合,可以得到20个小时的训练时间。在训练过程中,应学习三个目标函数,即语音信号的VAD,参考信号的VAD和抑制的频带增益。如图7所示,训练损失和验证损失都逐渐下降到接近零,这表明已经训练了可观的模型。
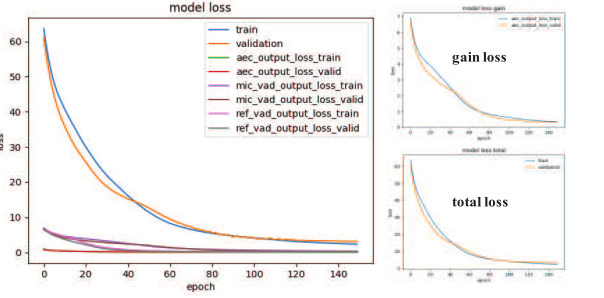
图7 训练过程中的损失
实验验证。
(a)频段增益。由一串唤醒词组成的音频语音受其自身播放的文本到语音(TTS)音频的干扰。关于VAD和频带增益的计算结果如图8所示。可以发现,如果在出现唤醒词的动量处检测到参考信号,则频带增益将接近零。由于残留回波的能量聚集在低频段,因此低频段用于抑制的频段增益将低于高频段。
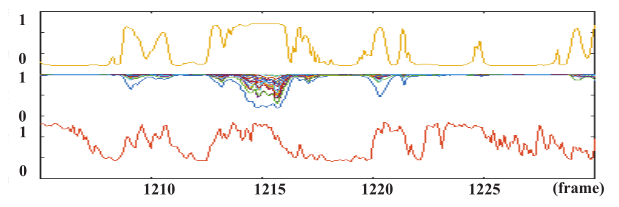
图8 神经网络计算的频带增益
(b)波形观察。为了评估性能,从流行的开源代码中提取方法进行比较。从图9可以看出,与Speex和WebRTC相比,所提出的RNN算法之后的残留回声可以被大大抑制。这些在仅残留回声存在的语音间隙处更为明显。还可以发现,在WbeRTC AEC之后,高频带的频谱被切断,这可以通过算法中的非线性处理(NLP)引入。
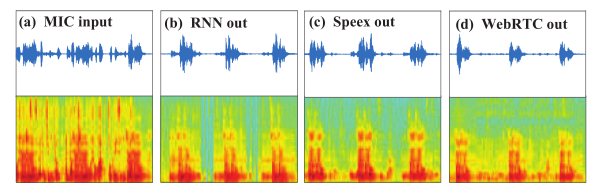
图9 波形比较
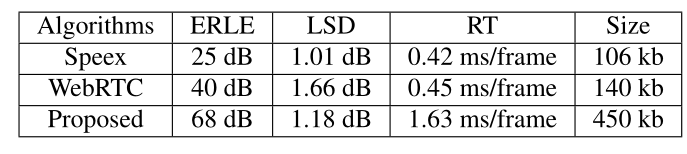
(c)性能比较。表1评估并列出了代表回声抑制性能的ERLE值和代表由AEC引起的语音频谱损失的LSD并列在表1中。由于AEC模块主要在设备上实现,因此在设备上获得的响应时间(RT)代表处理速度的平台相同,代表算法复杂度的模型大小也应考虑在内。可以看出,所提出的方案可以获得较高的ERLE,同时具有相当大的频谱损耗和处理时间。尽管所提出方案的模块尺寸较大,但是由于参考信号是纯净语音,因此可以定制该通道的VAD模型结构。同时,模型结构中用于回波估计的VAD的中间结果可能会被裁剪。这些都可以减小模型的尺寸。
表1 实验对比
4 总结
提出了一种自适应滤波器与神经网络相结合的声学回声消除方案。自适应滤波后的回波可以大范围地消除,特别是线性回波,只留下一点残余回波。残差信号的频谱与语音信号的频谱有很大的不同,可以看作是一种特殊类型的噪声。因此,利用神经网络将残差抑制到相当高的水平。实验表明,该方案在具有相当的频谱损伤和响应时间的情况下,可以获得更高的回波抑制性能。
5 参考文献
[1] E. Ha¨nsler, G. Schmidt, “Topics in acoustic echo and noise control: selected methods for the cancellation of acoustical echoes, the reduction of background noise, and speech processing,” Springer Berlin Heidelberg, 2006.
[2] J. Benesty, T. Ga¨nsler, “Advances in network and acoustic echo cancellation,” Advances in network and acoustic echo cancellation, Springer, 2001.
[3] E. Ferrara, “Fast implementations of LMS adaptive filters,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 28, no. 4, pp. 474–475 1980.
[4] R. Tyagi, R. Singh and R. Tiwari, “The performance study of NLMS algorithm for acoustic echo cancellation,” in International Conference on Information, Communication, Instrumentation and Control, ICICIC, 2017, pp. 1–5, Indore.
[5] G. A. Clark, S. K. Mitra, and S. R. Parker, “Block implementation of adaptive digital filters,” IEEE Trans. Acoust., Speech, Signal Processing, vol. ASSP–29, pp. 744–752, June 1981.
[6] Pez Borrallo JosM., M. G. Otero, “On the implementation of a partitioned block frequency domain adaptive filter (PBFDAF) for long acoustic echo cancellation,” Signal Processing, vol. 27, no. 3,pp. 301–315, 1992.
[7] J. S. Soo, K. K. Pang, “Multidelay block frequency domain adaptive filter,” IEEE Transactions on Acoustics,Speech and Signal Processing, vol. 38, no. 2, pp. 373–376, 1990.
[8] J. Valin, “On adjusting the learning rate in frequency domain echo cancellation with double-talk,“ IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 3, pp. 1030–1034,2007.
[9] Z. Yuan and X. Songtao, “Application of new LMS adaptive filtering algorithm with variable step size in adaptive echo cancellation,” in IEEE International Conference on Communication Technology, ICCT, 2017, pp. 1715–1719.
[10] J. Benesty, H. Rey, L. R. Vega and S. Tressens, “A nonparametric VSS NLMS algorithm,” IEEE Signal Processing Letters, vol. 13, no. 10, pp. 581–584, 2006.
[11] C. Paleologu, S. Ciochina and J. Benesty, “Double-talk robust VSS-NLMS algorithm for under-modeling acoustic echo cancellation,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2008, pp. 245–248.
[12] Mohammad Asif Iqbal and S. L. Grant, “Novel variable step size nlms algorithms for echo cancellation,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2008, pp. 241–244.
[13] O. Tanrikulu and K. Dogancay, “A new non-linear processor (NLP) for background continuity in echo control,” in IEEE International Conference on Acoustics, Speech, and Signal Processing,ICASSP, 2003, pp. V–588.
[14] M. Doroslovacki, “Optimal non-linear processor control for residual-echo suppression,” in IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP, 2003, pp. V–608.
[15] B. Panda, A. Kar and M. Chandra, “Non-linear adaptive echo supression algorithms: A technical survey,” in International Conference on Communication and Signal Processing,ICCSP, 2014,pp. 076–080.
[16] M. Z. Ikram, “Non-linear acoustic echo cancellation using cascaded Kalman filtering,” in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2014,pp. 1320–1324.
[17] M. I. Mossi, C. Yemdji, N. Evans, and etc., “Robust and lowcost cascaded non-linear acoustic echo cancellation, in IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2011, pp. 89–92.
[18] J. Mourjopoulos, “On the variation and invertibility of room impulse response functions,” Journal of Sound & Vibration, vol. 102, no. 2, pp. 217–228, 1985.
[19] J. M. Valin, “Speex: A free codec for free speech,” Speex A Free Codec for Free Speech, 2016.
[20] P. Srivastava, K. Babu and T. Osv, “Performance evaluation of Speex audio codec for wireless communication networks,” in International Conference on Wireless and Optical Communications Networks, WOCN, 2011, pp. 1–5.
[21] Valin, Jean-Marc, “A hybrid DSP/deep learning approach to realtime full-band speech enhancement,” in IEEE International Workshop on Multimedia Signal Processing, MMSP, 2018, pp. 1–5
论文翻译:2020_Acoustic Echo Cancellation by Combining Adaptive Digital Filter and Recurrent Neural Network的更多相关文章
- 论文翻译:2020_Acoustic Echo Cancellation Challenge Datasets And Testingframework
论文地址:ICASSP 2021声学回声消除挑战:数据集和测试框架 代码地址:https://github.com/microsoft/DNS-Challenge 主页:https://aec-cha ...
- 论文翻译:2020_ACOUSTIC ECHO CANCELLATION WITH THE DUAL-SIGNAL TRANSFORMATION LSTM NETWORK
论文地址:https://ieeexplore.ieee.org/abstract/document/9413510 基于双信号变换LSTM网络的回声消除 摘要 本文将双信号变换LSTM网络(DTLN ...
- 论文翻译:2021_ICASSP 2021 ACOUSTIC ECHO CANCELLATION CHALLENGE: INTEGRATED ADAPTIVE ECHO CANCELLATION WITH TIME ALIGNMENT AND DEEP LEARNING-BASED RESIDUAL ECHO PLUS NOISE SUPPRESSION
论文地址:https://ieeexplore.ieee.org/abstract/document/9414462 ICASSP 2021声学回声消除挑战:结合时间对准的自适应回声消除和基于深度学习 ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2021_A New Real-Time Noise Suppression Algorithm for Far-Field Speech Communication Based on Recurrent Neural Network
论文地址:一种新的基于循环神经网络的远场语音通信实时噪声抑制算法 引用格式:Chen B, Zhou Y, Ma Y, et al. A New Real-Time Noise Suppression ...
- 论文翻译:2020_Acoustic Echo Cancellation Based on Recurrent Neural Network
论文地址:https://ieeexplore.ieee.org/abstract/document/9306224 基于RNN的回声消除 摘要 本文提出了一种基于深度学习的语音分离技术的回声消除方法 ...
- 论文翻译:2020_Nonlinear Residual Echo Suppression using a Recurrent Neural Network
论文地址:https://indico2.conference4me.psnc.pl/event/35/contributions/3367/attachments/779/817/Thu-1-10- ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
- Paper | Adaptive Computation Time for Recurrent Neural Networks
目录 1. 网络资源 2. 简介 3. 自适应运算时间 3.1 有限运算时间 3.2 误差梯度 1. 网络资源 这篇文章的写作太随意了,读起来不是很好懂(掺杂了过多的技术细节).因此有作者介绍会更好. ...
随机推荐
- Android 图片框架
1.图片框架:Picasso.Glide.Fresco 2.介绍: picasso:和Square的网络库能发挥最大作用,因为Picasso可以选择将网络请求的缓存部分交给了okhttp实现 Glid ...
- Use of explicit keyword in C++
Predict the output of following C++ program. 1 #include <iostream> 2 3 using namespace std; 4 ...
- Linux基础命令---htdigest建立和更新apache服务器摘要
htdigest htdigest指令用来建立和更新apache服务器用于摘要认证的存放用户认证信息的文件. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS. 1.语法 ...
- weak和拷贝
weak/拷贝 1. weak 只要没有strong指针指向对象,该对象就会被销毁 2. 拷贝 NSString和block用copy copy语法的作用 产生一个副本 修改了副本(源对象)并不会影响 ...
- 【编程思想】【设计模式】【创建模式creational】原形模式Prototype
Python版 https://github.com/faif/python-patterns/blob/master/creational/prototype.py #!/usr/bin/env p ...
- Map集合的认识和理解
java.util.Map(k,v)集合* Map的特点:* 1.Map集合是一个双列集合,一个元素包含两个值(一个是key,一个是Value)* 2.Map集合中的元素,key和value的类型可以 ...
- 三维引擎导入obj模型不可见总结
最近有客户试用我们的三维平台,在导入模型的时候,会出现模型全黑和不可见的情况.上一篇文章说了全黑的情况.此文说下不可见的情况. 经过测试,发现可能有如下两种情况. 导入的模型不在镜头视野内 导入的模型 ...
- MySQL查询数据库表空间大小
一.查询所有数据库占用空间大小 SELECT TABLE_SCHEMA, CONCAT( TRUNCATE(SUM(data_length) / 1024 / 1024, 2), ' MB' ) AS ...
- Python利用ctypes实现C库函数调用
0X00 ctypes 是强大的,使用它我们就能够调 用动态链接库中函数,同时创建各种复杂的 C 数据类型和底层操作函数.使得python也具备了底层内存操作的能力,再配合python本身强大的表达能 ...
- LuoguB2133 我家的门牌号 题解
Update \(\texttt{2021.11.27}\) 修复了代码中的 \(10000\) 写成 \(n\) 的错误. Content 一个家庭住在一个胡同里面,门牌号从 \(1\) 开始编号. ...