brk 和 sbrk 区别
转自:https://www.cnblogs.com/chengxuyuancc/p/3566710.html
brk和sbrk的定义,在man手册中定义了这两个函数:
1 #include <unistd.h>
2 int brk(void *addr);
3 void *sbrk(intptr_t increment);
手册上说brk和sbrk会改变program break的位置,program break被定义为程序data segment的结束位置。感觉这句话不是很好理解,从下面程序地址空间的分布来看,data segment后面还有bss segment,显然和手册说的不太一样。一种可能的解释就是手册中的data segment和下图中的data segment不是一个意思,手册中的data segment应该包含了下图中的data segment、bss segment和heap,所以program break指的就是下图中heap的结束地址。
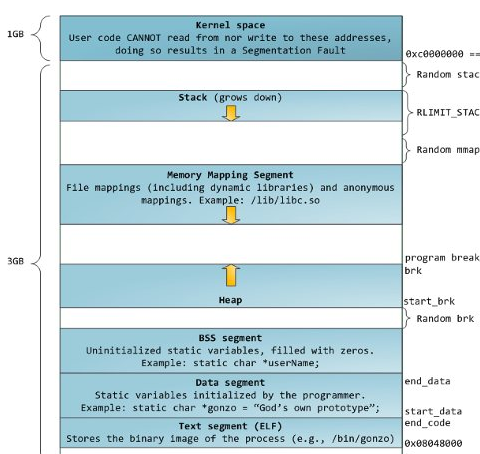
有了前面program break的概念后,我们来看下brk和sbrk的作用。brk通过传递的addr来重新设置program break,成功则返回0,否则返回-1。而sbrk用来增加heap,增加的大小通过参数increment决定,返回增加大小前的heap的program break,如果increment为0则返回program break。
从上面的图可以看出heap的起始地址并不是bss segment的结束地址,而是随机分配的,下面我们用一个程序来验证下:

1 #include <stdio.h>
2 #include <unistd.h>
3
4 int bss_end;
5
6 int main(void)
7 {
8 void *tret;
9
10 printf("bss end: %p\n", (char *)(&bss_end) + 4);
11 tret = sbrk(0);
12 if (tret != (void *)-1)
13 printf ("heap start: %p\n", tret);
14 return 0;
15 }
运行的结果为:
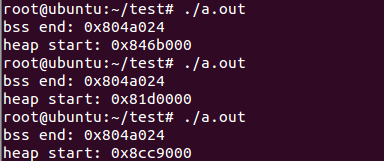
从上面运行结果可以知道bss和heap是不相邻的,并且同一个程序bss的结束地址是固定的,而heap的起始地址在每次运行的时候都会改变。你可能会说sbkr(0)返回的是heap的结束地址,怎么上面确把它当做起始地址呢?由于程序开始运行时heap的大小是为0,所以起始地址和结束地址是一样的,不信我们可以用下面的程序验证下。
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int bss_end;
6
7 int main(void)
8 {
9 void *tret;
10 char *pmem;
11
12 printf("bss end: %p\n", (char *)(&bss_end) + 4);
13 tret = sbrk(0);
14 if (tret != (void *)-1)
15 printf ("heap1 start: %p\n", tret);
16
17 if (brk((char *)tret - 1) == -1)
18 printf("brk error\n");
19
20 tret = sbrk(0);
21 if (tret != (void *)-1)
22 printf ("heap2 start: %p\n", tret);
23
24 pmem = (char *)malloc(32);
25 if (pmem == NULL) {
26 perror("malloc");
27 exit (EXIT_FAILURE);
28 }
29 printf ("pmem:%p\n", pmem);
30
31 tret = sbrk(0);
32 if (tret != (void *)-1)
33 printf ("heap1 end: %p\n", tret);
34
35 if (brk((char *)tret - 10) == -1)
36 printf("brk error\n");
37
38 tret = sbrk(0);
39 if (tret != (void *)-1)
40 printf ("heap2 end: %p\n", tret);
41 return 0;
42 }
运行结果为:
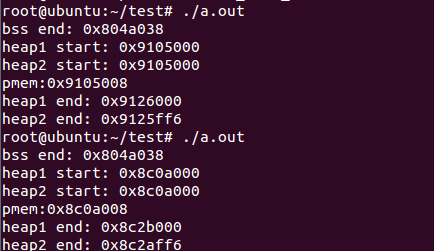
程序开始的时候打印出来heap的结束地址,并用这个地址减1来重新设置heap的结束地址,结果两次的结束地址居然是一样的,那说明这个结束地址就是heap的起始地址,再减小这个起始地址是不允许的,不过brk也不会报错。然后调用malloc获取内存,并打印出该内存的起始地址pmem,可以发现pmem与heap的起始地址相差8个字节,为什么会有8个字节没有?这8个字节应该是用来管理heap空间的(不深究)。最后再次获得heap的结束地址,并用这个地址减10来重新设置heap的结束地址,这下地址设置成功了。
堆的管理
上面的函数我们其实很少使用,大部分我们使用的是malloc和free函数来分配和释放内存。这样能够提高程序的性能,不是每次分配内存都调用brk或sbrk,而是重用前面空闲的内存空间。brk和sbrk分配的堆空间类似于缓冲池,每次malloc从缓冲池获得内存,如果缓冲池不够了,再调用brk或sbrk扩充缓冲池,直到达到缓冲池大小的上限,free则将应用程序使用的内存空间归还给缓冲池。
如果缓冲池需要扩充时,一次扩充多少呢?先运行下面的程序看看:
1 #include <stdio.h>
2 #include <unistd.h>
3 #include <stdlib.h>
4
5 int main(void)
6 {
7 void *tret;
8 char *pmem;
9
10 tret = sbrk(0);
11 if (tret != (void *)-1)
12 printf ("heap start: %p\n", tret);
13
14 pmem = (char *)malloc(64); //分配内存
15 if (pmem == NULL) {
16 perror("malloc");
17 exit (EXIT_FAILURE);
18 }
19 printf ("pmem:%p\n", pmem);
20 tret = sbrk(0);
21 if (tret != (void *)-1)
22 printf ("heap size on each load: %p\n", (char *)tret - pmem);
23 free(pmem)
24 return 0;
25 }
运行结果如下:

从结果可以看出调用malloc(64)后缓冲池大小从0变成了0x20ff8,将上面的malloc(64)改成malloc(1)结果也是一样,只要malloc分配的内存数量不超过0x20ff8,缓冲池都是默认扩充0x20ff8大小。值得注意的是如果malloc一次分配的内存超过了0x20ff8,malloc不再从堆中分配空间,而是使用mmap()这个系统调用从映射区寻找可用的内存空间。
参考
http://blog.csdn.net/sgbfblog/article/details/7772153
brk 和 sbrk 区别的更多相关文章
- Linux中brk()系统调用,sbrk(),mmap(),malloc(),calloc()的异同【转】
转自:http://blog.csdn.net/kobbee9/article/details/7397010 brk和sbrk主要的工作是实现虚拟内存到内存的映射.在GNUC中,内存分配是这样的: ...
- 理解brk和sbrk
brk和sbrk的定义 在man手册中定义了这两个函数: #include <unistd.h> int brk(void *addr); void *sbrk(intptr_t incr ...
- Unix系统编程()brk,sbrk
在堆上分配内存 进程可以通过增加堆的大小来分配内存,所谓堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减.通常将堆的当前内存边界称为"program ...
- brk(), sbrk() 用法详解
brk() , sbrk() 的声明如下: #include <unistd.h> int brk(void *addr); void *sbrk(intptr_t increment); ...
- brk(), sbrk() 用法详解【转】
转自:http://blog.csdn.net/sgbfblog/article/details/7772153 贴上原文地址,好不容易找到了:brk(), sbrk() -- 改变数据段长度 brk ...
- 系统调用与内存管理(sbrk、brk、mmap、munmap)(转)
一.系统调用(System Call):在Linux中,4G内存可分为两部分——内核空间1G(3~4G)与用户空间3G(0~3G),我们通常写的C代码都是在对用户空间即0~3G的内存进行操作.而且,用 ...
- Linux内存分配小结--malloc、brk、mmap【转】
转自:https://blog.csdn.net/gfgdsg/article/details/42709943 http://blog.163.com/xychenbaihu@yeah/blog/s ...
- brk和mmap(转)
进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap: 1.brk是将数据段的(.data)的最高地址指针_edata往高地址推 2.mmap是虚拟地址空间找一个空闲的虚拟内存 如果mal ...
- C/C++ Learning
目录 1. C/C++中的关键字2. C/C++中的标识符3. 编译选项MD(d).MT(d)编译选项的区别4. C++类模板.函数模板5. C++修饰符6. 调用约定7. 错误处理8. 环境表 9. ...
随机推荐
- LNMP架构上线动态网站
第一步,一键安装所需程序 yum install -y nginx php php-mysql php-fpm mariadb-server 第二步,修改Nginx配置文件/etc/nginx/ngi ...
- java中的|=符号
今天看mybaits源码的时候,发现了这个特殊的符号用法,|=. for (ParameterMapping pm : boundSql.getParameterMappings()) { Strin ...
- Bug Hunt UVA - 1596
In this problem, we consider a simple programming language that has only declarations of onedimens ...
- 构建基于表单配置的 Jenkins 测试项目(接口、UI、APP、Jmeter)
1. 第一个 hello world 项目 2. 构建自动触发的项目(接口测试) 1)新建测试项目(执行测试脚本) 2)新建 Maven 打包项目 3)手动执行构建 4)修改 Web 工程代码并 pu ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(九)——一步一步教你如何撸Dapr之OAuth2授权
Oauth2授权,熟悉微信开发的同学对这个东西应该不陌生吧.当我们的应用系统需要集成第三方授权时一般都会做oauth集成,今天就来看看在Dapr的语境下我们如何仅通过配置无需修改应用程序的方式让第三方 ...
- sublime常用快键键
---------------最常用的1.新建文件-输入"html:xt"后 按"Ctrl+E键"或 "tab键" ,可快速生成xhtml ...
- Android Dex文件格式解析
Dex文件是Android虚拟机下的可执行文件,包含了应用程序所用到所有操作指令和运行时数据.在程序编译过程中,java源文件先被编译成class文件,然后通过dx工具将多个class文件整合为一个d ...
- 支付宝手机端网页支付 PHP(基于官方提供的demo)
1.支付宝开放平台添加应用并且签约快捷手机wap支付(应用添加不做详细说明) 2.下载demo,文档中心SDK&Demo, 3.个人中心秘钥管理,查看商户appID,商户私钥,支付宝公钥,商户 ...
- 浅谈自动特征构造工具Featuretools
简介 特征工程在机器学习中具有重要意义,但是通过手动创造特征是一个缓慢且艰巨的过程.Python的特征工程库featuretools可以帮助我们简化这一过程.Featuretools是执行自动化特征工 ...
- 大数据开发-Flink-数据流DataStream和DataSet
Flink主要用来处理数据流,所以从抽象上来看就是对数据流的处理,正如前面大数据开发-Flink-体系结构 && 运行架构提到写Flink程序实际上就是在写DataSource.Tra ...