模块random+os+sys+json+subprocess
模块random+os+sys+json+subprocess
1. random 模块 (产生一个随机值)
import random
1 # 随机小数
2 print(random.random()) # 随机产生一个0-1之间的小数
3 print(random.uniform(1, 6)) # 随机产生一个1-6之间的小数
4 # 随机整数
5 print(random.randint(1, 6)) # 随机产生一个1-6之间的整数 掷骰子
6 # 随机抽取
7 print(random.choice(['特等奖', '一等奖', '二等奖', '谢谢惠顾', '惊喜大奖之如花抱回家'])) # 随机抽取一个
8 print(random.sample(['安徽省', '江苏省', '山东省', '海南省', '广东省', '台湾省'], 3)) # 随机抽取指定样本量
9 # 随机打乱
10 l = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A']
11 random.shuffle(l)需要掌握,以后用到,生成随机订单号等 # 随机打乱容器类型中的诸多元素#
12 print(l) # ['A', 10, 'K', 3, 2, 'Q', 9, 6, 'J', 5, 8, 7, 4]
2. os模块 (与操作系统打交道)
import os
2.1 创建和删除文件夹
最重要指令:os.path.dirname(__file__)
***** 获取当前文件所在的路径(可以嵌套 则为上一层路径)
BASE_DIR = os.path.dirname(__file__)
print(BASE_DIR) # D:/Program Files/pythonProject21
__file__表示当前文件路径,,,os.path.dirname 表示上一层文件路径
# 创建文件夹
# 1.创建单级目录(文件夹)
os.mkdir('XXX老师精品课程集')
os.mkdir(r'xxx视频合集\r老师视频作品') # 报错
# 2.创建多级目录(文件夹)
os.makedirs(r'xxx视频合集\r老师视频作品\2021选集') # 3.删除空目录(文件夹) 如果不是空的直接报错(没啥用)
os.rmdir(r'xxx视频合集')
os.removedirs(r'xxx视频合集')
# 删除一个文件
os.remove('a.txt')
# 修改文件名称
os.rename('老文件名','新文件名')
2.2 获取路径下全部文件
# 5.路径拼接(******) 能够自动识别不同操作系统分隔符问题
movie_dir = os.path.join(BASE_DIR, '老师教学视频')
# 获取当前文件夹路径下所有文件
print(os.listdir()) 重要!!!掌握 # 查看当前文件夹路径下所有文件
print(os.listdir('D:/')) # 查看当前文件夹路径下所有文件
# ['$RECYCLE.BIN', 'python全栈开发', 'BaiduNetdisk', '安装包 合集', '幽游白书-魔强统一战10.11.17', '网易有道词典']

练习:把路径下每个文件打印出来,让用户自己选择看哪一个
1 while True:
2 for i, j in enumerate(data_movie_list):
3 print(i + 1, j)
4 choice = input('请选择你想要看的文件编号>>>:').strip()
5 if choice.isdigit():
6 choice = int(choice)
7 if choice in range(len(data_movie_list) + 1):
8 # 获取编号对应的文件名称
9 file_name = data_movie_list[choice - 1]
10 # 拼接文件的完整路径(******)
11 file_path = os.path.join(movie_dir, file_name) # 专门用于路径拼接 并且能够自动识别当前操作系统的路径分隔符
12 # 利用文件操作读写文件
13 with open(file_path, 'r', encoding='utf8') as f:
14 print(f.read())
2.3 路径修改及判断
# getcwd 单用没啥用,主要与chdir结合使用
# 9.获取当前工作路径
print(os.getcwd()) # get current work dir
# D:\Program Files\pythonProject21 # 10.切换路径
os.chdir('D:/') # change dir
print(os.getcwd()) # 切换后,就可以查看切换后的当前路径
# 接下来所有操作就可以基于切换后的路径进行了
with open(r'a.txt','wb') as f:
pass
2.4 判断路径 & 获取文件大小
# 11.判断当前路径是否存在
print(os.path.exists('a.txt')) # False
print(os.path.exists('01 练习随机数.py')) # True
print(os.path.exists('02 抽取幸运观众.py')) # True # 12.判断当前路径是否是文件
print(os.path.isfile('01 练习随机数.py')) # True (文件)
print(os.path.isfile('XXX老师精品课程集')) # False (文件夹) # 13.判断当前路径是否是文件夹
print(os.path.isdir('01 练习随机数.py')) # False (文件)
print(os.path.isdir('XXX老师精品课程集')) # True (文件夹) # 14.获取文件大小(字节数)
print(os.path.getsize(r'01 练习随机数.py')) # 1258 bit 字节
3. sys模块 (主要与python解释器打交道)
import sys
print(sys.path) # 查看当前的所有文件路径
print(sys.version) # version版本 查看当前版本(没啥用)
print(sys.platform) # 平台(没啥用)
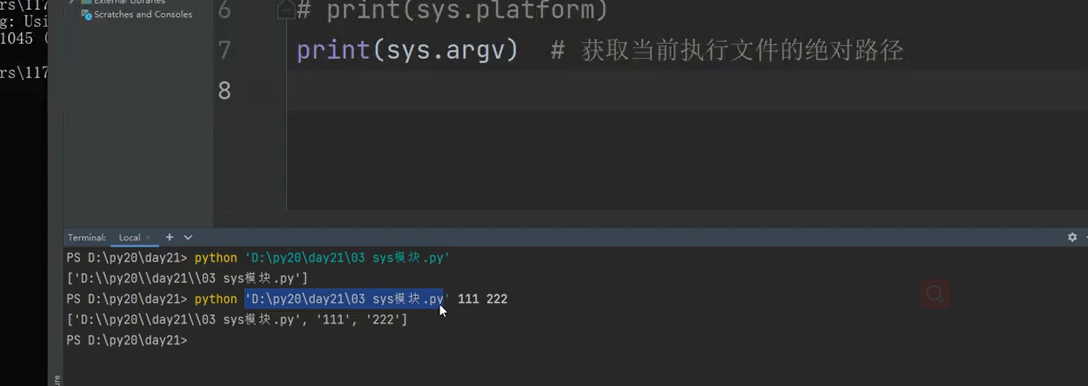
print(sys.argv) # (必须掌握)获取当前执行文件的绝对路径
重要!!!重要!!!重要!!!重要!!!
try:
username = sys.argv[1]
password = sys.argv[2]
if username == 'jason' and password == '123':
print('正常执行文件内容')
else:
print('用户名或密码错误')
except Exception:
print('请输入用户名和密码')
print('目前只能让你体验一下(游客模式)')
4.序列化模块 ( json格式数据:跨语言传输 )--->>> 最常用模块!!!
import json
暂且可以简单的理解为:
序列化就是将其他数据类型转换成字符串过程 json.dumps()
反序列化就是将字符串转换成其他数据类型 json.loads()
d = {'username': 'jason', 'pwd': 123}
# 1.将python其他数据转换成json格式字符串(序列化)
res = json.dumps(d)
print(res,type(res)) # {"username": "jason", "pwd": 123}
# 2.将json格式字符串转成当前语言对应的某个数据类型(反序列化)
res1 = json.loads(res)
print(res1,type(res1)) # {'username': 'jason', 'pwd': 123} <class 'dict'>
bytes_data = b'{"username": "jason", "pwd": 123}'
bytes_str = bytes_data.decode('utf8')
bytes_dict = json.loads(bytes_str)
print(bytes_dict,type(bytes_dict))
原始方法 读写文件
d = {'username': 'jason', 'pwd': 123}
# 将字典d写入文件
with open(r'a.txt','w',encoding='utf8') as f:
f.write(str(d))
# 将字典d取出来
with open(r'a.txt','r',encoding='utf8') as f:
data = f.read()
print(dict(data))
用 json 方法 读写文件 ( dumps , loads )
d = {'username': 'jason', 'pwd': 123}
# 将字典d写入文件
with open(r'a.txt','w',encoding='utf8') as f:
res = json.dumps(d) # 序列化成json格式字符串
f.write(res)
# 将字典d取出来
with open(r'a.txt','r',encoding='utf8') as f:
data = f.read()
res1 = json.loads(data)
print(res1,type(res1))
升级写法 ( dump , load )
d1 = {'username': 'tony', 'pwd': 123,'hobby':[11,22,33]}
with open(r'a.txt', 'w', encoding='utf8') as f:
json.dump(d1, f)
with open(r'a.txt','r',encoding='utf8') as f:
res = json.load(f)
print(res,type(res)) # {'username': 'tony', 'pwd': 123, 'hobby': [11, 22, 33]} <class 'dict'>
d1 = {'username': 'tony好帅哦 我好喜欢', 'pwd': 123,'hobby':[11,22,33]}
print(json.dumps(d1,ensure_ascii=False)) # {"username": "tony好帅哦 我好喜欢", "pwd": 123, "hobby": [11, 22, 33]}
并不是所有的数据类型都支持序列化, json.JSONEncoder 查看支持的数据类型。
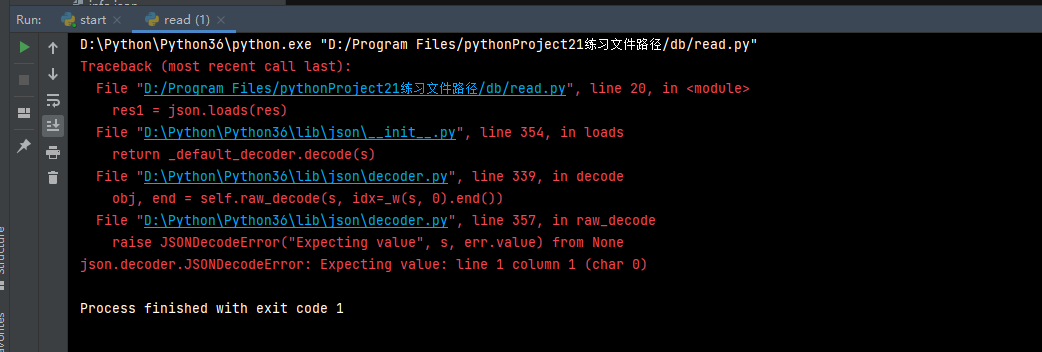
★★★json生成的文件不能为空,不能是空的,不能是空的!!! 空的运行会报警!
下图就是报警信息提示!
5. subprocess模块
import subprocess
1.可以基于网络连接上一台计算机(socket模块)
2.让连接上的计算机执行我们需要执行的命令
3.将命令的结果返回
res = subprocess.Popen('tasklist',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print('stdout',res.stdout.read().decode('gbk')) # 获取正确命令执行之后的结果
print('stderr',res.stderr.read().decode('gbk')) # 获取错误命令执行之后的结果
模块random+os+sys+json+subprocess的更多相关文章
- Python全栈--7模块--random os sys time datetime hashlib pickle json requests xml
模块分为三种: 自定义模块 内置模块 开源模块 一.安装第三方模块 # python 安装第三方模块 # 加入环境变量 : 右键计算机---属性---高级设置---环境变量---path--分号+py ...
- Day 17 time,datetime,random,os,sys,json,pickle
time模块 1.作用:打印时间,需要时间的地方,暂停程序的功能 时间戳形式 time.time() # 1560129555.4663873(python中从1970年开始计算过去了多少秒) 格式化 ...
- 常用模块random/os/sys/time/datatime/hashlib/pymysql等
一.标准模块 1.python自带的,import random,json,os,sys,datetime,hashlib等 ①.正常按照命令:打开cmd,执行:pip install rangdom ...
- 7.18 collection time random os sys 序列化 subprocess 等模块
collection模块 namedtuple 具名元组(重要) 应用场景1 # 具名元组 # 想表示坐标点x为1 y为2 z为5的坐标 from collections import namedtu ...
- python之常见模块(time,datetime,random,os,sys,json,pickle)
目录 time 为什么要有time模块,time模块有什么用?(自己总结) 1. 记录某一项操作的时间 2. 让某一块代码逻辑延迟执行 时间的形式 时间戳形式 格式化时间 结构化时间 时间转化 总结: ...
- python 常用模块之random,os,sys 模块
python 常用模块random,os,sys 模块 python全栈开发OS模块,Random模块,sys模块 OS模块 os模块是与操作系统交互的一个接口,常见的函数以及用法见一下代码: #OS ...
- day19:常用模块(collections,time,random,os,sys)
1,正则复习,re.S,这个在用的最多,re.M多行模式,这个主要改变^和$的行为,每一行都是新串开头,每个回车都是结尾.re.L 在Windows和linux里面对一些特殊字符有不一样的识别,re. ...
- python笔记-1(import导入、time/datetime/random/os/sys模块)
python笔记-6(import导入.time/datetime/random/os/sys模块) 一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其 ...
- 常用模块(random,os,json,pickle,shelve)
常用模块(random,os,json,pickle,shelve) random import random print(random.random()) # 0-1之间的小数 print(rand ...
随机推荐
- django 项目中使用markdown编辑器
第一步: 修改models.py文件下要显示字段的类型为TextField 第二步:运行命令: python manage.py makemigrations 和 python manage.py ...
- mysql自动安装脚本
#!/bin/bashif [ -d /software ] ;then cd /softwareelse mkdir /software && cd /softwarefi #is ...
- 禁止yum update 自动更新系统内核
使用yum update更新系统软件时,禁止升级内核,可以防止产生因不兼容导致的未知错误. 设置前请先备份原设置文件yum.conf cp /etc/yum.conf /etc/yum.conf ...
- win10 防火墙配置 允许局域网其他设备访问本地工程
1.进入防护墙并找到高级设置 2.选择属性 3.将入站连接设为允许,有三个别忘了,[域配置文件,专用配置文件,公用配置文件]
- tomcat启动卡在了 At least one JAR was scanned for TLDs yet contained no TLDs 的根本原因与解决办法
1.前言 有时候服务器开启时启动不了,卡在了 org.apache.jasper.servlet.TldScanner.scanJars At least one JAR was scanned fo ...
- Leetcode算法系列(链表)之删除链表倒数第N个节点
Leetcode算法系列(链表)之删除链表倒数第N个节点 难度:中等给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点.示例:给定一个链表: 1->2->3->4-&g ...
- html手机调试
长话短说 npm install anywhere -g 安装好后,cmd 命令 进入你要调试html页面的目录,运行 anywhere AnyWhere 静态文件服务器 软件简介 AnyWhere是 ...
- 面试官: Flink双流JOIN了解吗? 简单说说其实现原理
摘要:今天和大家聊聊Flink双流Join问题.这是一个高频面试点,也是工作中常遇到的一种真实场景. 本文分享自华为云社区<万字直通面试:Flink双流JOIN>,作者:大数据兵工厂 . ...
- Flowable实战(八)BPMN2.0 任务
任务是流程中最重要的组成部分.Flowable提供了多种任务类型,以满足实际需求. 常用任务类型有: 用户任务 Java Service任务 脚本任务 业务规则任务 执行监听器 任务监听器 多 ...
- Ubuntu 14.04更换内核
1:查看当前安装的内核 dpkg -l|grep linux-image 2:查看可以更新的内核版本: sudo apt-cache search linux-image 3:安装新内核 sudo a ...