基于Apache Hudi 的CDC数据入湖
作者:李少锋
文章目录:
一、CDC背景介绍
二、CDC数据入湖
三、Hudi核心设计
四、Hudi未来规划
1. CDC背景介绍
首先我们介绍什么是CDC?CDC的全称是Change data Capture,即变更数据捕获,它是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。它的应用比较广,可以做一些数据同步、数据分发和数据采集,还可以做ETL,今天主要分享的也是把DB数据通过CDC的方式ETL到数据湖。

对于CDC,业界主要有两种类型:
- 基于查询,客户端会通过SQL方式查询源库表变更数据,然后对外发送。
- 基于日志,这也是业界广泛使用的一种方式,一般是通过binlog方式,变更的记录会写入binlog,解析binlog后会写入消息系统,或直接基于Flink CDC进行处理。
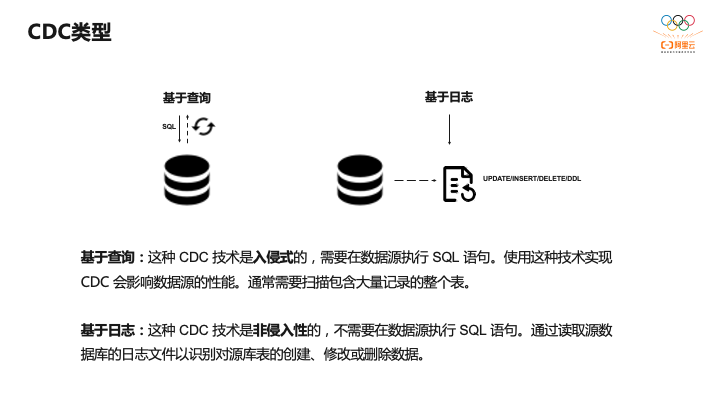
它们两者是有区别的,基于查询比较简单,是入侵性的,而基于日志是非侵入性,对数据源没有影响,但binlog的解析比较复杂一些。

基于查询和基于日志,分别有四种实现技术,有基于时间戳、基于触发器和快照,还有基于日志的,这是实现CDC的技术,下面是几种方式的对比。
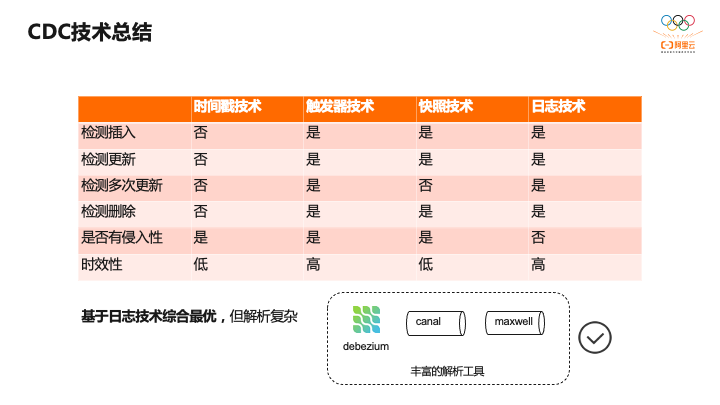
通过这个表格对比可以发现基于日志的综合最优,但解析比较复杂,但业界有很多开源的binlog的解析器,比较通用和流行的有Debezium、Canal,以及Maxwell。基于这些binlog解析器就可以构建ETL管道。
下面来看下业界比较流行的一种CDC入仓架构。
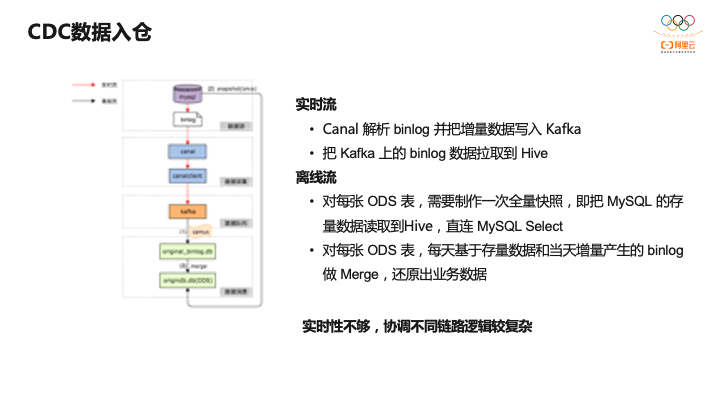
整个数据入仓是分实时流是离线流,实时流解析binlog,通过Canal解析binlog,然后写入Kafka,然后每个小时会把Kafka数据同步到Hive中;另外就是离线流,离线流需要对同步到Hive的贴源层的表进行拉取一次全量,如果只有前面的实时流是数据是不全的,必须通过离线流的SQL Select把全量导入一次数据,对每张ODS表会把存量数据和增量数据做一个Merge。这里可以看到对于ODS层的实时性不够,存在小时、天级别的延迟。而对ODS层这个延时可以通过引入Apache Hudi做到分钟级。
2. CDC数据入湖方法
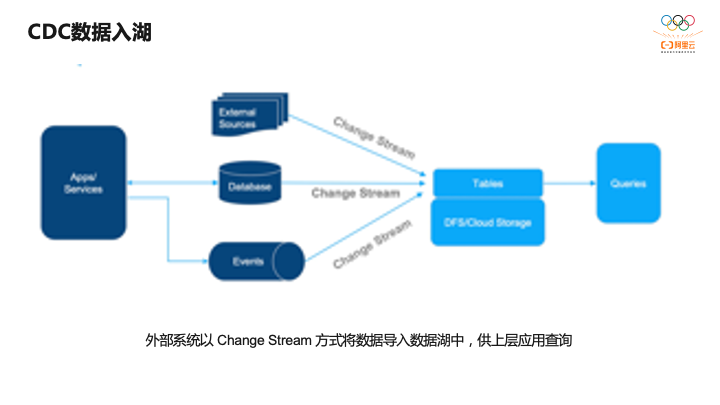
基于CDC数据的入湖,这个架构非常简单。上游各种各样的数据源,比如DB的变更数据、事件流,以及各种外部数据源,都可以通过变更流的方式写入表中,再进行外部的查询分析,整个架构非常简单。
架构虽然简单,但还是面临很多挑战。以Apache Hudi数据湖为例,数据湖是通过文件存储各种各样的数据, 对于CDC的数据处理需要对湖里某部分文件进行可靠地、事务性变更,这样可以保证下游查询不会看到部分结果,另外对CDC数据需要高效的做更新、删除操作,这就需要快速定位到更改的文件,另外是对于每小批量的数据写入,希望能够自动处理小文件,避免繁杂的小文件处理,还有面向查询的布局优化,可以通过一些技术手段如Clustering改造文件布局,对外提供更好的查询性能。

而Apache Hudi是怎么应对这些挑战的呢?首先支持事务性写入,包括读写之间的MVCC机制保证写不影响读,也可以控制事务及并发保证,对于并发写采用OCC乐观锁机制,对更新删除,内置一些索引及自定义保证更新、删除比较高效。另外是面向查询优化,Hudi内部会自动做小文件的管理,文件会自动长到用户指定的文件大小,如128M,这对Hudi来说也是比较核心的特性。另外Hudi提供了Clustering来优化文件布局的功能。

下图是典型CDC入湖的链路。上面的链路是大部分公司采取的链路,前面CDC的数据先通过CDC工具导入Kafka或者Pulsar,再通过Flink或者是Spark流式消费写到Hudi里。第二个架构是通过Flink CDC直联到MySQL上游数据源,直接写到下游Hudi表。
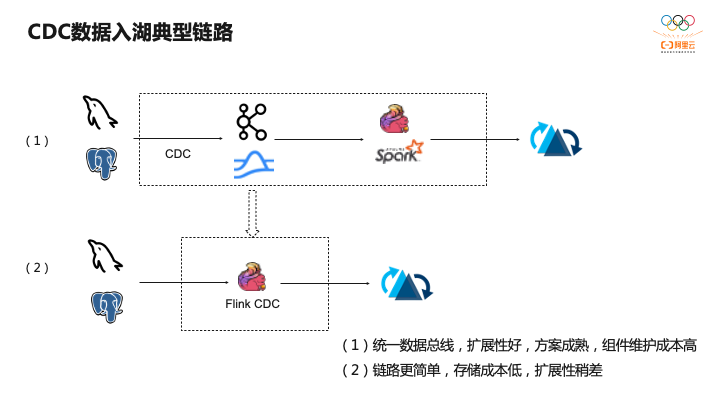
其实,这两条链路各有优缺点。第一个链路统一数据总线,扩展性和容错性都很好。对于第二条链路,扩展性和容错性会稍微差点,但由于组件较少,维护成本相应较低。
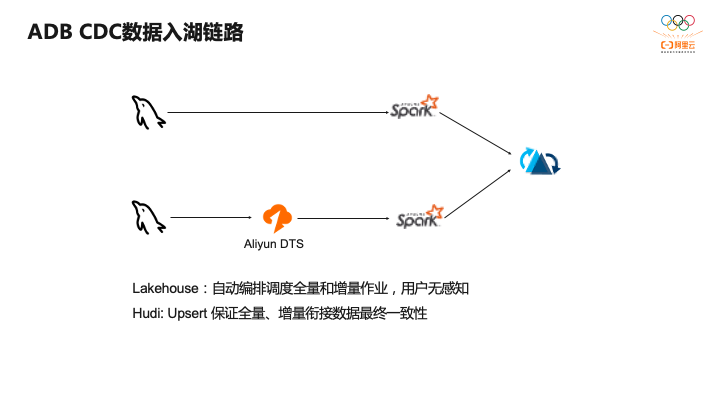
这是阿里云数据库OLAP团队的CDC入湖链路,因为我们我们做Spark的团队,所以我们采用的Spark Streaming链路入湖。整个入湖链路也分为两个部分:首先有一个全量同步作业,会通过Spark做一次全量数据拉取,这里如果有从库可以直连从库做一次全量同步,避免对主库的影响,然后写到Hudi。然后会启动一个增量作业,增量作业通过Spark消费阿里云DTS里的binlog数据来将binlog准实时同步至Hudi表。全量和增量作业的编排借助了Lakehouse的作业自动编排能力,协调全量和增量作业,而对于全量和增量衔接时利用Hudi的Upsert语义保证全增量数据的最终的一致性,不会出现数据偏多和偏少的问题。
在Lakehouse的CDC入湖链路中,我们团队也做了一些优化。
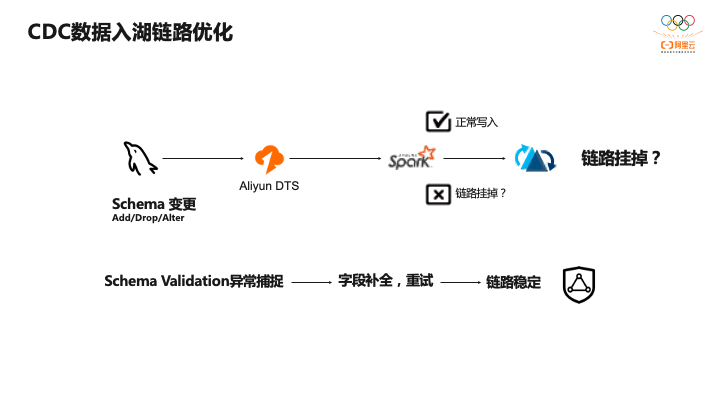
第一个是原库的Schema变更处理,我们对接的客户某些列的增加、删除或者修改某些列的场景。在Spark写Hudi之前会做Schema的检验,看这个Schema是不是合法,如果合法就可以正常写入,如果不合法的话,则会写入失败,而删除字段会导致Schema校验不合法,导致作业失败,这样稳定性是没有保证的。因此我们会捕捉Schema Validation的异常,如果发现是减少了字段,我们会把之前的字段做自动补全,然后做重试,保证链路是稳定的。
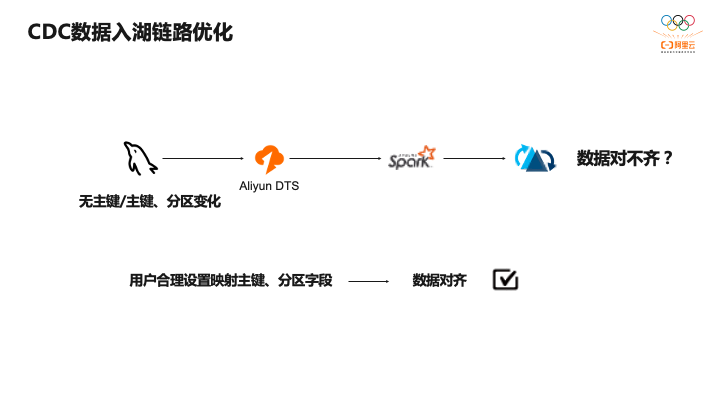
第二个有些客户表没有主键或者主键不合理,比如采用更新时间字段作为主键,或者设置会变化的分区字段,这时候就会导致写入Hudi的数据和源库表数据对不上。因此我们做了一些产品层面的优化,允许用户合理设置主键和分区映射,保证同步到Hudi里和源库是数据完全对齐的。
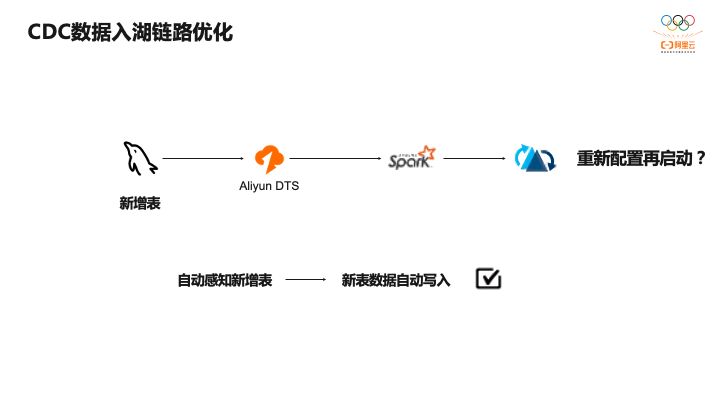
还有一个常见需求是用户在上游库中增加一个表,如果使用表级别同步的话,新增表在整个链路是无法感知的,也就无法同步到Hudi中,而在Lakehouse中,我们可以对整库进行同步,因此在库中新增表时,会自动感知新增表,将新增表数据自动同步到Hudi,做到原库增加表自动感知的能力。
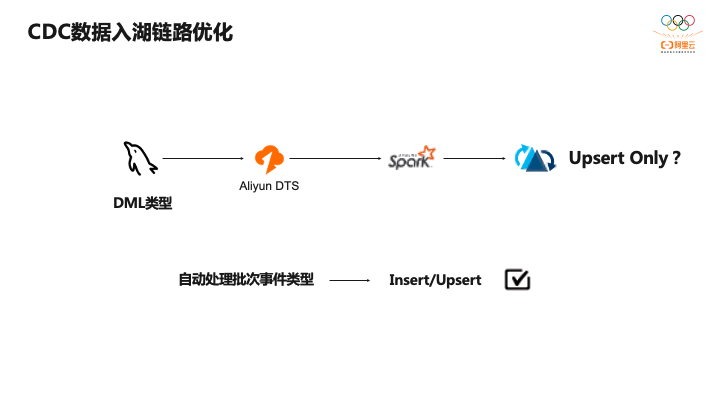
还有一个是对CDC写入时候性能优化,比如拉取的一批数据中包含Insert、Update、Delete等事件,是否一直使用Hudi的Upsert方式写入呢?这样控制比较简单,并且Upsert有数据去重能力,但它带来的问题是找索引的效率低,而对于Insert方式而言,不需要找索引,效率比较高。因此对于每一批次数据会判断是否都是Insert事件,如果都是Insert事件就直接Insert方式写入,避免查找文件是否更新的开销,数据显示大概可以提升30%~50%的性能。当然这里也需要考虑到DTS异常,重新消费数据时,恢复期间不能直接使用Insert方式,否则可能会存在数据重复,对于这个问题我们引入了表级别的Watermark,保证即使在DTS异常情况下也不会出现数据重复问题。
3. Hudi核心设计
接着介绍下Hudi 的定位,根据社区最新的愿景,Hudi的定义是流式数据湖平台,它支持海量数据更新,内置表格式以及支持事务的储存,一系列列表服务包括Clean、Archive、Compaction、Clustering等,以及开箱即用的数据服务,以及本身自带的运维工具和指标监控,提供很好的运维能力。
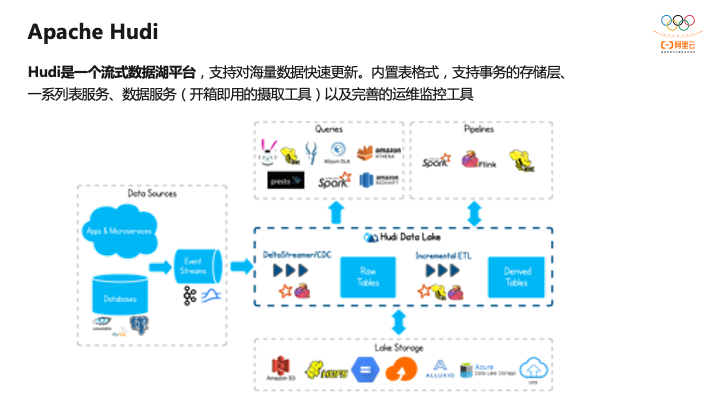
这是Hudi官网的图,可以看到Hudi在整个生态里是做湖存储,底层可以对接HDFS以及各种云厂商的对象存储,只要兼容Hadoop协议接。上游是入湖的变化事件流,对上可以支持各种各样的数据引擎,比如presto、Spark以及云上产品;另外可以利用Hudi的增量拉取能力借助Spark、Hive、Flink构建派生表。
整个Hudi体系结构是非常完备的,其定位为增量的处理栈。典型的流式是面向行,对数据逐行处理,处理非常高效。
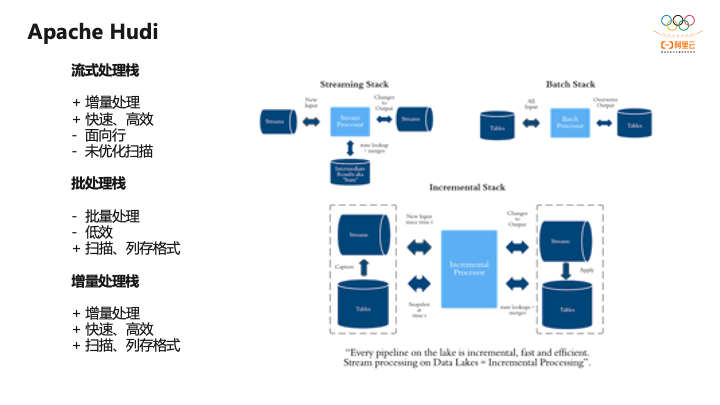
但面向行的数据里没有办法做大规模分析做扫描优化,而批处理可能需要每天全量处理一次,效率相对比较低。而Hudi引入增量处理的概念,处理的数据都是某一时间点之后的,和流处理相似,又比批处理高效很多,并且本身是面向数据湖中的列存数据,扫描优化非常高效。
而回顾Hudi的发展历史。2015年社区主席发表了一篇增量处理的文章,16年在Uber开始投入生产,为所有数据库关键业务提供了支撑;2017年,在Uber支撑了100PB的数据湖,2018年随着云计算普及,吸引了国内外的使用者;19年Uber把它捐赠到Apache进行孵化;2020年一年左右的时间就成为了顶级项目,采用率增长了超过10倍;2021年Uber最新资料显示Hudi支持了500PB数据湖,同时对Hudi做了很多增强,像Spark SQL DML和Flink的集成。最近字节跳动推荐部门分享的基于Hudi的数据湖实践单表超过了400PB,总存储超过了1EB,日增PB级别。

经过几年的发展,国内外采用Hudi的公司非常多,比如公有云的华为云、阿里云、腾讯云以及AWS,都集成了Hudi,阿里云也基于Hudi构建Lakehouse。字节跳动的整个数仓体系往湖上迁移也是基于Hudi构建的,后面也会有相应的文章分享他们基于Flink+Hudi的数据湖的日增PB数据量的实践。同时像百度、快手头部互联网大厂都有在使用。同时我们了解银行、金融行业也有工商银行、农业银行、百度金融、百信银行也有落地。游戏领域包括了三七互娱、米哈游、4399,可以看到Hudi在各行各业都有比较广泛的应用。

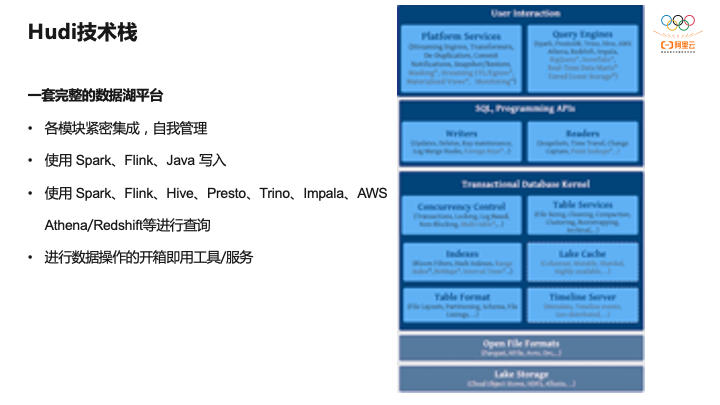
Hudi的定位是一套完整的数据湖平台,最上层面向用户可以写各种各样的SQL,Hudi作为平台提供的各种能力,下面一层是基于SQL以及编程的API,再下一层是Hudi的内核,包括索引、并发控制、表服务,后面社区要构建的基于Lake Cache构建缓存,文件格式是使用的开放Parquet、ORC、HFile存储格式,整个数据湖可以构建在各种云上。
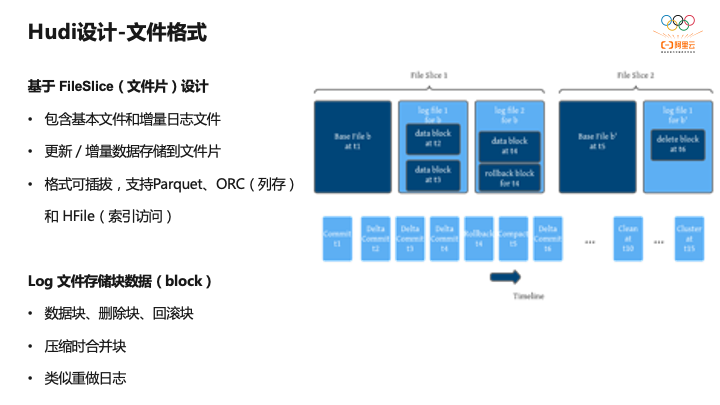
后面接着介绍Hudi的关键设计,这对我们了解Hudi非常有帮助。首先是文件格式,它最底层是基于Fileslice的设计,翻译过来就是文件片,文件片包含基本文件和增量日志文件。基本文件就是一个Parquet或者是ORC文件,增量文件是log文件,对于log文件的写入Hudi里编码了一些block,一批Update可以编码成一个数据块,写到文件里。而基础文件是可插拔,可以基于Parquet,最新的9.0版本已经支持了ORC。还有基于HFile,HFile可用作元数据表。
Log文件里保存了一系列各种各样的数据块,它是有点类似于数据库的重做日志,每个数据版本都可以通过重做日志找到。对于基础文件和Log文件通过压缩做合并形成新的基础文件。Hudi提供了同步和异步的两种方式,这为用户提供了很灵活的选择,比如做可以选择同步Compaction,如果对延迟不敏感,而不需要额外异步起一个作业做Compaction,或者有些用户希望保证写入链路的延迟,可以异步做Compaction而不影响主链路。
Hudi基于File Slice上有个File Group的概念,File Group会包含有不同的File Slice,也File Slice构成了不同的版本,Hudi提供了机制来保留元数据个数,保证元数据大小可控。
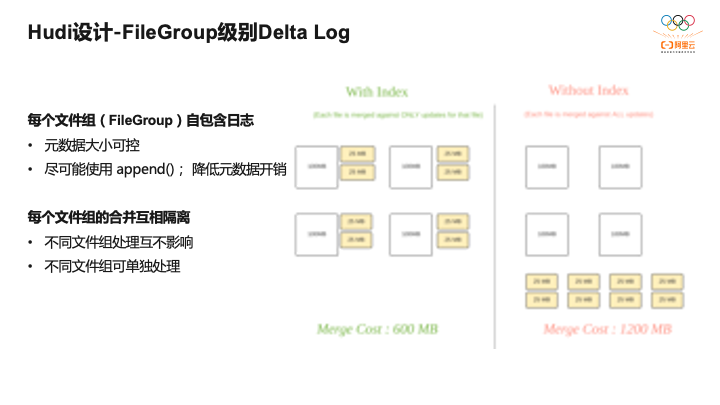
对于数据更新写入,尽量使用append,比如之前写了一个Log文件,在更新时,会继续尝试往Log文件写入,对于HDFS这种支持append语义的存储非常友好,而很多云上对象存储不支持append语义,即数据写进去之后不可更改,只能新写Log文件。对于每个文件组也就是不同FileGroup之间是互相隔离的,可以针对不同的文件组做不同的逻辑,用户可以自定义算法实现,非常灵活。
基于Hudi FileGroup的设计可以带来不少收益。比如基础文件是100M,后面对基础文件进行了更新50M数据,就是4个FileGroup,做Compaction合并开销是600M,50M只需要和100M合,4个150M开销就是600M,这是有FileGroup设计。还是有4个100M的文件,也是做了更新,每一次合,比如25M要和400M合并,开销是1200M,可以看到采用FileGroup的设计,合并开销减少一半。
还有表格式。表格式的内容是文件在Hudi内是怎么存的。首先定义了表的根路径,然后写一些分区,和Hive的文件分区组织是一样的。还有对表的Schema定义,表的Schema变更,有一种方式是元数据记录在文件里,也有的是借助外部KV存储元数据,两者各有优缺点。
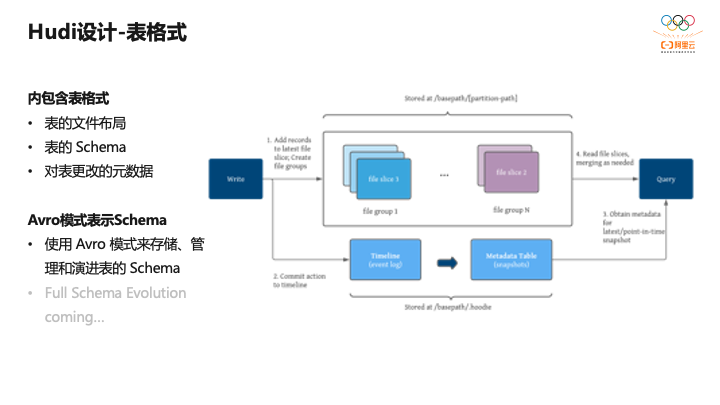
Hudi基于Avro格式表示Schema,因此对Schema的Evolution能力完全等同于Avro Schema的Evolution能力,即可以增加字段以及向上兼容的变更,如int变成long是兼容的,但long变成int是不兼容的。
当前现在社区已经有方案支持Full Schema Evolution,即可以增加一个字段,删去一个字段,重命名,也就是变更一个字段。
还有一个是Hudi的索引设计。每一条数据写入Hudi时,都会维护数据主键到一个文件组ID的映射,这样在做更新、删除时可以更快的定位到变更的文件。
右边的图里有个订单表,可以根据日期写到不同的分区里。下面就是用户表,就不需要做分区,因为它的数据量没有那么大,变更没那么频繁,可以使用非分区的表。
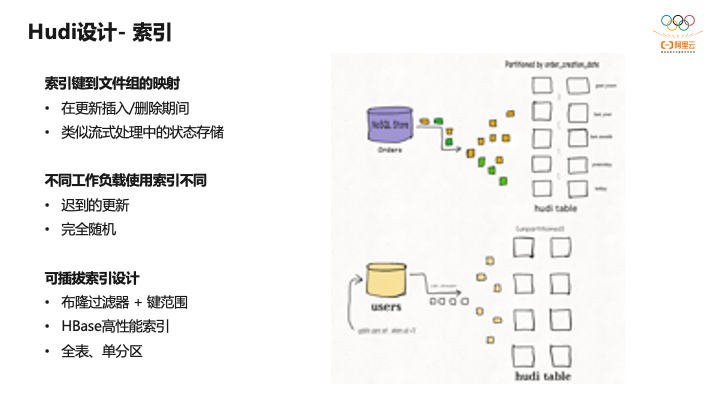
对于分区表及变更频繁的表,在使用Flink写入时,利用Flink State构建的全局索引效率比较高。整个索引是可插拔的,包括Bloomfilter、 HBase高性能索引。在字节场景中, Bloomfilter过滤器完全不能满足日增PB的索引查找,因此他们使用HBase高性能索引,因此用户可根据自己的业务形态灵活选择不同索引的实现。在有不同类型索引情况下可以以较低代价支持迟到的更新、随机更新的场景。
另外一个设计是并发控制。并发控制是在0.8之后才引入的。Hudi提供乐观锁机制来处理并发写问题,在提交的时候检查两个变更是否冲突,如果冲突就会写入失败。对于表服务如Compaction或者是Clustering内部没有锁,Hudi内部有一套协调机制来避免锁竞争问题。比如做Compaction,可以先在timeline上先打一个点,后面完全可以和写入链路解耦,异步做Compaction。
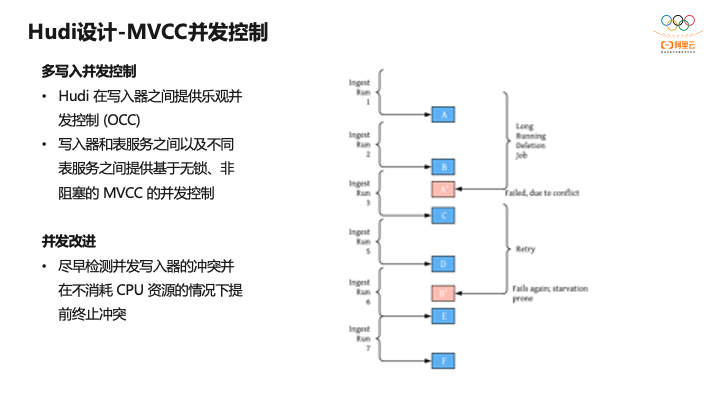
例如左边是数据摄取链路,数据每半个小时摄取一次,右边是异步删除作业,也会变更表,并且很有可能和写入修改冲突,会导致这个链路一直失败,平台无故的消耗CPU资源,现在社区针对这种情况也有改进方案,希望尽早检测并发写入的冲突,提前终止,减少资源浪费。
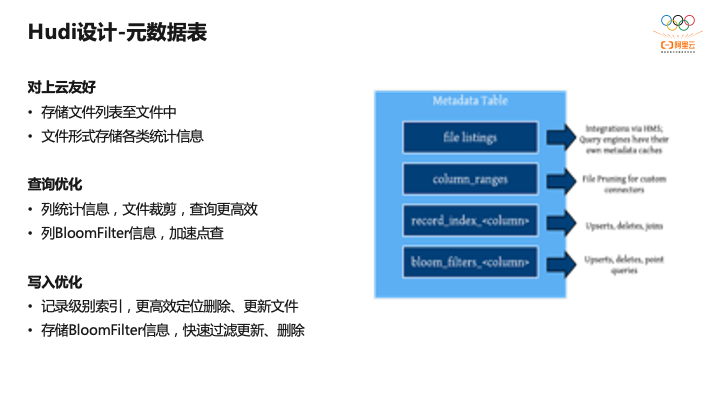
另外一个设计是元数据表。因为Hudi最开始是基于HDFS构建和设计,没有太多考虑云上存储场景,导致在云上FileList非常慢。因此在0.8版本,社区引入了Metadata Table,Metadata Table本身也是一张Hudi表,它构建成一张Hudi,可以复用Hudi表等各种表服务。Metadata Table表文件里会存分区下有的所有文件名以及文件大小,每一列的统计信息做查询优化,以及现在社区正在做的,基于Meta Table表构建全局索引,每条记录对应每个文件ID都记录在Meta table,减少处理Upsert时查询待更新文件的开销,也是上云必备。
4. Hudi未来规划
对未来的规划,如基于Pulsar、Hudi构建Lakehouse,这是StreamNative CEO提出的Proposal,想基于Hudi去构建Pulsar分层的存储。在Hudi社区,我们也做了一些工作,想把Hudi内置的工具包DeltaStreamar内置Pulsar Source,现在已经有PR了,希望两个社区联系可以更紧密。Pular分层存储内核部分StreamNative有同学正在做。

最近几天已经发布了0.9.0重要的优化和改进。首先集成了Spark SQL,极大降低了数据分析人员使用Hudi的门槛。
Flink集成Hudi的方案早在Hudi的0.7.0版本就有了,经过几个版本的迭代,Flink集成Hudi已经非常成熟了,在字节跳动等大公司已经在生产使用。Blink团队做的一个CDC的Format集成,直接把Update、Deltete事件直接存到Hudi。还有就是做存量数据的一次性迁移,增量了批量导入能力,减少了序列化和反序列化的开销。
另外现在有一些用户会觉得Hudi存一些元数据字段,比如_hoodie_commit_time等元信息,这些信息都是从数据信息里提取的,有部分存储开销,现在支持虚拟键,元数据字段不会再存数据了,它带来的限制就是不能使用增量ETL,无法获取Hudi某一个时间点之后的变更数据。
另外很多小伙伴也在希望Hudi支持ORC格式,Hudi最新版本支持了ORC格式,同时这部分格式的是可插拔的,后续可以很灵活接入更多的格式。还做了Metadata Table的写入和查询优化,通过Spark SQL查询的时候,避免Filelist,直接通过Metadata Table获取整个文件列表信息。
从更远来看社区未来的规划包括对于Spark集成升级到Data SourceV2,现在Hudi基于V1,无法用到V2的性能优化。还有Catalog集成,可以通过Catalog管理表,可以创建、删除、更新,表格元数据的管理通过Spark Catalog集成。
Flink模块Blink团队有专职同学负责,后续会把流式数据里的Watremark推到Hudi表里。
另外是与Kafka Connect Sink的集成,后续直接通过Java客户把Kafka的数据写到Hudi,而不用拉起一个Spark/Flink集群作业。

在内核侧的优化,包括了基于Metadata Table全局记录级别索引。还有字节跳动小伙伴做的写入支持Bucket,这样的好处就是做数据更新的时候,可以通过主键找到对应Bucket,只要把对应Bucket的parquet文件的Bloomfilter读取出来就可以了,减少了查找更新时候的开销。
还有更智能地Clustering策略,在我们内部也做了这部分工作,更智能的Clustering可以基于之前的负载情况,动态的开启Clustering优化,另外还包括基于Metadata Table构建二级索引,以及Full Schema Evolution和跨表事务。
现在Hudi社区发展得比较快,代码重构量非常大,但都是为了更好的社区发展,从0.7.0到0.9.0版本Flink集成Hudi模块基本上完全重构了,如果有兴趣的同学可以参与到社区,共同建设更好的数据湖平台。
基于Apache Hudi 的CDC数据入湖的更多相关文章
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC ...
随机推荐
- SpringBoot 属性配置文件数据注入配置和yml与properties区别
前言 我们知道SpringBoot 通过配置类来解放一堆的xml文件配置,通属性配置文件,来进行,系统全局属性配置,这样极大的简化了我们开发过程,java web 也可以甜甜的从此 快速配置 Spri ...
- WEB漏洞——SQL
由于我的博客是学到渗透的时候才做的,没有关于WEB漏洞的笔记,现在发现WEB层面的漏洞有些不太熟悉了,边写一下笔记边复习一下,就从sql注入开始吧 话不多说先上大佬写的表[ctfhub]SQL注入 - ...
- PyCharm——滚动鼠标调整字体大小
- Django分页组件——Paginator
from django.core.paginator import Paginator #导入Paginator objects = ['john','paul','george','ringo',' ...
- 使用Mosquitto实现MQTT客服端C语言
上一篇文章已经将mosquitto移植到了arm平台上,现在将使用mosquitto完成mqtt客服端的demo,了解过mqtt协议的小伙伴都知道,mqtt主要分为代理服务器.发布者.订阅者三部分 ...
- 快速模式第一包: quick_outI1()
文章目录 1. 序言 2. quick_outI1()流程图 3. quick_outI1()源码分析 4. quick_outI1_continue()源码分析 5. quick_outI1_tai ...
- Nacos注册中心之概要设计
本文已收录 https://github.com/lkxiaolou/lkxiaolou 欢迎star. 前言 在之前的文章中分析了Nacos配置中心,配置中心的核心是配置的创建.读取.推送. 注册中 ...
- angularjs 文件上传
github连接地址:https://github.com/danialfarid/ng-file-upload 核心代码: html: <div class="form-group& ...
- 洛谷P1309——瑞士轮(归并排序)
https://www.luogu.org/problem/show?pid=1309#sub 题目背景 在双人对决的竞技性比赛,如乒乓球.羽毛球.国际象棋中,最常见的赛制是淘汰赛和循环赛.前者的特点 ...
- [Navicat15 试用期过期解决办法]
Navicat15 试用期过期解决办法 第一步:关闭Navicat 第二步: 打开注册表编辑器,win + R, 输入regedit 第三步: 在最上方搜索框输入HKEY_CURRENT_USER\S ...