快速上手NumPy
NumPy is the fundamental package for scientific computing in Python.
NumPy是一个开源的Python科学计算库。
初识NumPy
对于相同的数值计算任务,使用NumPy比直接使用Python要简洁、高效的多。
NumPy使用ndarray来处理多维数组。
NumPy provides an N-dimensional array type, the ndarray, which describes a collection of “items” of the same type. The items can be indexed using for example N integers.
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的items的集合。
比如下面的学生成绩:
| 语文 | 数学 | 英语 | 物理 | 化学 |
|---|---|---|---|---|
| 92 | 99 | 91 | 85 | 90 |
| 95 | 85 | 88 | 81 | 88 |
| 85 | 81 | 80 | 78 | 86 |
用ndarray进行存储:
import numpy as np score = np.array(
[[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]]) score
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
ndarray与list对比
用数据说话。所以,这里先通过几行代码来比较ndarray与Python原生的list的执行效率。
import random
import time
import numpy as np list = [random.random() for i in range(10000000)] array = np.array(list) # 使用%time魔法方法, 可查看当前行的代码运行一次所花费的时间
%time sum_array = np.sum(array) %time sum_list = sum(list)
CPU times: user 4.59 ms, sys: 3 µs, total: 4.59 ms
Wall time: 4.6 ms
CPU times: user 37.2 ms, sys: 155 µs, total: 37.4 ms
Wall time: 37.2 ms
可以看到ndarray的计算速度要快很多。机器学习通常有大量的数据运算,如果没有一个高效的运算方案,很难流行起来。
NumPy对ndarray的操作和运算进行了专门的设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,NumPy的优势就越明显。
那么自然要问了,ndarray为什么这么快?
- 在内存分配上,
ndarray相邻元素的地址是连续的,而python原生list是通过二次寻址方式找到下一个元素的具体位置。如下图所示:
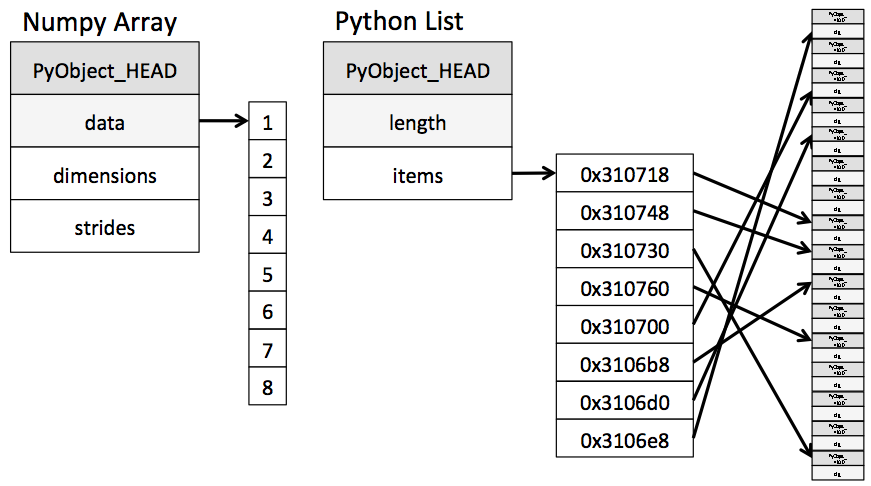
其中图片来自:
https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
一个ndarray占用内存中一个连续块,并且元素的类型都是相同的。所以一旦确定了ndarray的元素类型以及元素个数,它的内存占用就确定了。而原生list则不同,它的每个元素在list中其实是一个地址引用,这个地址指向存储实际元素数据的内存空间,也就是说指向的内存不一定是连续的。
- numpy底层使用
C语言编写,内部解除了GIL(全局解释器锁)限制。
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
- numpy支持并行运算,系统有多个核时,条件允许的话numpy会自动发挥多核优势。
数组常见属性
一维数组
a1 = np.array([1, 2, 3])
a1
array([1, 2, 3])
# 数组维度
a1.ndim
1
# 数组形状
a1.shape
(3,)
# 数组元素个数
a1.size
3
# 数组元素的类型
a1.dtype
dtype('int64')
# 一个数组元素的长度(字节数)
a1.itemsize
8
ndarray的元素类型如下表所示:
| 类型 | 描述 | 简写 |
|---|---|---|
| bool | 用一个字节存储的布尔类型(True或False) | 'b' |
| int8 | 一个字节大小,-128 至 127 | 'i' |
| int16 | 整数,-32768 至 32767 | 'i2' |
| int32 | 整数,-2^31 至 2^31 -1 | 'i4' |
| int64 | 整数,-2^63 至 2^63 - 1 | 'i8' |
| uint8 | 无符号整数,0 至 255 | 'u' |
| uint16 | 无符号整数,0 至 65535 | 'u2' |
| uint32 | 无符号整数,0 至 2^32 - 1 | 'u4' |
| uint64 | 无符号整数,0 至 2^64 - 1 | 'u8' |
| float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | 'f2' |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | 'f4' |
| float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | 'f8' |
| complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | 'c8' |
| complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | 'c16' |
| object_ | python对象 | 'O' |
| string_ | 字符串 | 'S' |
| unicode_ | unicode类型 | 'U' |
创建数组的时候可指定元素类型。若不指定,整数默认int64,小数默认float64。
np.array([1, 2, 3.0]).dtype
dtype('float64')
np.array([True, True, False]).itemsize
1
np.array(['Python', 'Java', 'Golang'], dtype=np.string_).dtype
dtype('S6')
二维数组
a2 = np.array([
[1, 2, 3],
[1, 2, 3]
])
a2
array([[1, 2, 3],
[1, 2, 3]])
# 数组维度
a2.ndim
2
# 数组形状
a2.shape
(2, 3)
# 数组元素个数
a2.size
6
# 数组元素类型
a2.dtype
dtype('int64')
# 一个数组元素的长度(字节数)
a2.itemsize
8
三维数组
a3 = np.array([
[[1, 2, 3], [1, 2, 3]],
[[1, 2, 3], [1, 2, 3]],
[[1, 2, 3], [1, 2, 3]],
[[1, 2, 3], [1, 2, 3]]
])
a3
array([[[1, 2, 3],
[1, 2, 3]], [[1, 2, 3],
[1, 2, 3]], [[1, 2, 3],
[1, 2, 3]], [[1, 2, 3],
[1, 2, 3]]])
# 数组维度
a3.ndim
3
# 数组形状
a3.shape
(4, 2, 3)
# 数组元素个数
a3.size
24
# 数组元素类型
a3.dtype
dtype('int64')
# 一个数组元素的长度(字节数)
a3.itemsize
8
生成数组的方式
从现有数组生成
score
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
# 相当于深拷贝
arr1 = np.array(score)
arr1
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
# 相当于浅拷贝, 并没有copy完整的array对象
arr2 = np.asarray(score)
arr2
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
score[0, 0] = 100
score
array([[100, 99, 91, 85, 90],
[ 95, 85, 88, 81, 88],
[ 85, 81, 80, 78, 86]])
arr1
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
arr2
array([[100, 99, 91, 85, 90],
[ 95, 85, 88, 81, 88],
[ 85, 81, 80, 78, 86]])
从上面的结果可以看出:传入ndarray时,np.array()会copy完整的ndarray,而np.asarray()不会。
注意:传入的参数是ndarray,并非Python原生的list。这两种情况不能混淆。下面看下传入list是啥结果。
nums = [1, 2, 3]
nums
[1, 2, 3]
array1 = np.array(nums)
array1
array([1, 2, 3])
array2 = np.asarray(nums)
array2
array([1, 2, 3])
现在修改list中的元素:
nums[0] = 10
nums
[10, 2, 3]
array1
array([1, 2, 3])
array2
array([1, 2, 3])
生成0和1的数组
- 生成元素全为0的数组
np.zeros([3, 2], dtype=np.int64)
array([[0, 0],
[0, 0],
[0, 0]])
# Return an array of zeros with the same shape and type as a given array.
np.zeros_like(score)
array([[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]])
- 生成元素全为1的数组
np.ones([3, 2], dtype=np.int64)
array([[1, 1],
[1, 1],
[1, 1]])
# Return an array of ones with the same shape and type as a given array.
np.ones_like(score)
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]])
生成固定范围的数组
- 创建等差数组(指定步长, 即等差数列中的公差)
# Return evenly spaced values within a given interval.
np.arange(10, 50, 5)
array([10, 15, 20, 25, 30, 35, 40, 45])
- 创建等差数组(指定元素个数)
np.linspace(2.0, 3.0, num=5)
array([2. , 2.25, 2.5 , 2.75, 3. ])
# If endpoint True, 3.0 is the last sample. Otherwise, 3.0 is not included.
np.linspace(2.0, 3.0, num=5, endpoint=False)
array([2. , 2.2, 2.4, 2.6, 2.8])
- 创建等比数列
np.logspace(2, 5, num=4, dtype=np.int64)
array([ 100, 1000, 10000, 100000])
np.logspace(2, 5, num=4, base=3, dtype=np.int64)
array([ 9, 27, 81, 243])
默认base=10.0,第一个例子中生成num=4个元素的等比数列,起始值是10^2,终止值是10^5,所以等比数列为[100, 1000, 10000, 100000]
同理,第二个例子中也是生成num=4个元素的等比数列,不过base=3,起始值是3^2,终止值是3^5,所以等比数列为[9, 27, 81, 243]
生成随机数组
实际生产中的数据大多可能是随机数值,而这些随机数据往往又符合某些规律。下面会涉及到概率论的一点点知识,无需畏惧,其实初高中数学就或多或少接触过。
均匀分布
# 生成均匀分布的随机数
x1 = np.random.uniform(0, 10, 100000)
x1
array([5.76720988, 5.32880068, 7.58561359, ..., 7.59316418, 8.30197616,
4.38992042])
所谓均匀分布,指的是相同间隔内的分布概率是等可能的。直方图可用于较直观地估计一个连续变量的概率分布。 下面简要回顾一下画直方图的步骤,也能加深对使用场景的理解。
(1) 收集数据(数据一般应大于50个)
(2) 确定数据的极差(用数据的最大值减去最小值)
(3) 确定组距。先确定直方图的组数,然后以此组数去除极差,可得直方图每组的宽度,即组距
(4) 确定各组的界限值。为避免出现数据值与组界限值重合而造成频数据计算困难,组的界限值单位应取最小测量单位的1/2
(5) 编制频数分布表。把多个组上下界限值分别填入频数分布表内,并把数据表中的各个数据列入相应的组,统计各组频数据
(6) 按数据值比例画出横坐标
(7) 按频数值比例画纵坐标。以观测值数目或百分数表示
(8) 画直方图。按纵坐标画出每个长方形的高度,它代表取落在此长方形中的数据数。
下面用matplotlib帮助我们画图。
import matplotlib.pyplot as plt # 创建画布
plt.figure(figsize=(10, 5), dpi=100) # 画直方图, x代表要使用的数据,bins表示要划分区间数
plt.hist(x=x1, bins=20) # 设置坐标轴刻度
plt.xticks(np.arange(0, 10.5, 0.5))
plt.yticks(np.arange(0, 6000, 500)) # 添加网格显示
plt.grid(True, linestyle='--', alpha=0.8) # 显示图像
plt.show()

从上图可以直观的看到,100000个[0, 10)范围内的样本数据,落在区间[0,0.5)、[0.5,1.0)、...、[9.0,9.5)、[9.5,10.0)内频数都近乎5000,符合均匀分布规律。
正态分布
正态分布也是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,参数μ是随机变量的期望(即均值),决定了其位置; 参数σ是随机变量的标准差,决定了其分布的幅度。
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为N(μ,σ^2)。当μ = 0,σ = 1时的正态分布是标准正态分布。
类似上面的均匀分布,我们通过生成样本数据,画图观察正态分布状况。
已知某地区成年男性身高近似服从正态分布。下面生成均值为170,标准差为5的100000个符合正态分布规律的样本数据。
x2 = np.random.normal(170, 5, 100000)
x2
array([177.45732513, 171.49250483, 159.53980655, ..., 156.38843943,
172.38350177, 164.87975538])
同样使用matplotlib帮助我们画图。
import matplotlib.pyplot as plt # 创建画布
plt.figure(figsize=(10, 5), dpi=100) # 画直方图
plt.hist(x=x2, bins=100) # 添加网格显示
plt.grid(True, linestyle='--', alpha=0.8) # 显示图像
plt.show()

从图中我们可以看出,大多人身高都集中在170左右。讲到这里,不知道你有没有回想起高中数学讲过的3σ原则:
P(μ-σ < X ≤ μ+σ) = 68.3%
P(μ-2σ < X ≤μ+2σ) = 95.4%
P(μ-3σ < X ≤μ+3σ) = 99.7%
即:
- 数值分布在(μ-σ, μ+σ)中的概率为68.3%
- 数值分布在(μ-2σ, μ+2σ)中的概率为95.4%
- 数值分布在(μ-3σ, μ+3σ)中的概率为99.7%
可以认为,取值几乎全部集中在(μ-3σ, μ+3σ)区间,超出这个范围的可能性仅到0.3%
其实,生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。
基本操作与运算
数组的索引与切片
数组的索引与切片类似Python中的list。下面演示一下即可。
score
array([[100, 99, 91, 85, 90],
[ 95, 85, 88, 81, 88],
[ 85, 81, 80, 78, 86]])
score[0]
array([100, 99, 91, 85, 90])
score[0, 1]
99
score[0, 2:4]
array([91, 85])
score[0, :-2]
array([100, 99, 91])
score[:-1, :-3]
array([[100, 99],
[ 95, 85]])
score[:-1, :-3] = 100
score[:-1, :-3]
array([[100, 100],
[100, 100]])
操作数据非常方便。
修改数组形状
还记得数组的形状是什么吗?
score.shape
(3, 5)
(3, 5)表示这是3行5列的二维数组。
如果现在想得到一个5行3列的二维数组呢?
# Returns an array containing the same data with a new shape
score.reshape([5, 3])
array([[100, 100, 91],
[ 85, 90, 100],
[100, 88, 81],
[ 88, 85, 81],
[ 80, 78, 86]])
score本身的形状有变化吗,看看此时的score啥样?
score
array([[100, 100, 91, 85, 90],
[100, 100, 88, 81, 88],
[ 85, 81, 80, 78, 86]])
如果想就地修改score的形状,应该使用resize():
# Change shape and size of array in-place
score.resize([5, 3]) score
array([[100, 100, 91],
[ 85, 90, 100],
[100, 88, 81],
[ 88, 85, 81],
[ 80, 78, 86]])
如果想转置数组呢(即数组的行、列进行互换)?
score.T
array([[100, 85, 100, 88, 80],
[100, 90, 88, 85, 78],
[ 91, 100, 81, 81, 86]])
主意:调用数组的转置后,score本身并没有改变,如下:
score
array([[100, 100, 91],
[ 85, 90, 100],
[100, 88, 81],
[ 88, 85, 81],
[ 80, 78, 86]])
数组去重
# Find the unique elements of an array
# Returns the sorted unique elements of an array
np.unique(score)
array([ 78, 80, 81, 85, 86, 88, 90, 91, 100])
修改数组元素类型
score.dtype
dtype('int64')
# Copy of the array, cast to a specified type.
score.astype(np.float64)
array([[100., 100., 91.],
[ 85., 90., 100.],
[100., 88., 81.],
[ 88., 85., 81.],
[ 80., 78., 86.]])
逻辑运算
如果想操作符合某些条件的数据,应该怎么做?
# 成绩是否及格(60分及以上为及格)
score >= 60
array([[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True],
[ True, True, True]])
# 成绩是否优秀(90分及以上为优秀)
score >= 90
array([[ True, True, True],
[False, True, True],
[ True, False, False],
[False, False, False],
[False, False, False]])
给满足条件的数据赋值。
# 给及格的同学都加上5分
score[score >= 60] += 5 score
array([[105, 105, 96],
[ 90, 95, 105],
[105, 93, 86],
[ 93, 90, 86],
[ 85, 83, 91]])
# 分数不允许超过满分(即100)
score[score > 100] = 100 score
array([[100, 100, 96],
[ 90, 95, 100],
[100, 93, 86],
[ 93, 90, 86],
[ 85, 83, 91]])
# 前面2个同学是否都满分
np.all(score[:2] >= 100)
False
# 前面2个同学是否有满分的
np.any(score[:2] >= 100)
True
# 分数大于90且小于95的置为1,否则为0
np.where(np.logical_and(score > 90, score < 95), 1, 0)
array([[0, 0, 0],
[0, 0, 0],
[0, 1, 0],
[1, 0, 0],
[0, 0, 1]])
# 分数为100或者小于90置为1,否则为0
np.where(np.logical_or(score == 100, score < 90), 1, 0)
array([[1, 1, 0],
[0, 0, 1],
[1, 0, 1],
[0, 0, 1],
[1, 1, 0]])
统计运算
如果想统计分数的最大值、最小值、平均值、方差,该怎么做?
上面演示过程中,把成绩都弄乱了。这里先恢复一下最开始的数据。
score = np.array(
[[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]]) score
array([[92, 99, 91, 85, 90],
[95, 85, 88, 81, 88],
[85, 81, 80, 78, 86]])
# 每门课的最高分(axis=0表示按照列的维度去统计)
np.max(score, axis=0)
array([95, 99, 91, 85, 90])
# 每个学生的最高分(axis=1表示按照行的维度去统计)
np.max(score, axis=1)
array([99, 95, 86])
如果想知道每门课最高分对应的是哪个同学,怎么办?
# 每门课的最高分对应的学生(即下标)
np.argmax(score, axis=0)
array([1, 0, 0, 0, 0])
其他统计函数也都类似。
# 每门课的最低分
np.min(score, axis=0)
array([85, 81, 80, 78, 86])
# 每门课的平均分
np.mean(score, axis=0)
array([90.66666667, 88.33333333, 86.33333333, 81.33333333, 88. ])
# 每门课的中位数
np.median(score, axis=0)
array([92., 85., 88., 81., 88.])
# 每门课的方差
np.var(score, axis=0)
array([17.55555556, 59.55555556, 21.55555556, 8.22222222, 2.66666667])
# 每门课的标准差
np.std(score, axis=0)
array([4.18993503, 7.7172246 , 4.64279609, 2.86744176, 1.63299316])
数组与数的运算
arr = np.array([[1, 2, 3], [11, 22, 33]])
arr
array([[ 1, 2, 3],
[11, 22, 33]])
arr * 10 + 1
array([[ 11, 21, 31],
[111, 221, 331]])
数组与数组的运算
通常对于两个numpy数组的相加、相减以及相乘都是对应元素之间的操作。
arr + arr
array([[ 2, 4, 6],
[22, 44, 66]])
arr - arr
array([[0, 0, 0],
[0, 0, 0]])
arr / arr
array([[1., 1., 1.],
[1., 1., 1.]])
arr * arr
array([[ 1, 4, 9],
[ 121, 484, 1089]])
数组在进行矢量化运算时,要求数组的形状是相等的。当两个数组的形状不相同的时候,可以通过扩展数组的方法来实现相加、相减、相乘等操作,这种机制叫做广播(broadcasting)。
矩阵乘法
大学线性代数课程中讲过矩阵的知识。矩阵在这里可以看成二维数组。
矩阵乘法:(M行, N列) * (N行, L列) = (M行, L列)。计算过程如下图所示:

下面举一个简单的例子说明矩阵乘法的应用。

很多学科的最终成绩都是综合平时成绩与期末成绩得到的,即:
平时成绩 * 0.3 + 期末成绩 * 0.7 = 最终成绩
用矩阵乘法来计算就是:

看下在NumPy中如何计算矩阵乘法:
a = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
b = np.array([[0.3], [0.7]])
np.matmul(a, b)
array([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
另外,np.dot也可以计算矩阵乘法,如下:
np.dot(a, b)
array([[84.2],
[80.6],
[80.1],
[90. ],
[83.2],
[87.6],
[79.4],
[93.4]])
与np.matmul不同的是,np.dot还可以与标量进行乘法运算:
np.dot(a, 2)
array([[160, 172],
[164, 160],
[170, 156],
[180, 180],
[172, 164],
[164, 180],
[156, 160],
[184, 188]])
快速上手NumPy的更多相关文章
- 快速上手pandas(上)
pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation to ...
- 【Python五篇慢慢弹】快速上手学python
快速上手学python 作者:白宁超 2016年10月4日19:59:39 摘要:python语言俨然不算新技术,七八年前甚至更早已有很多人研习,只是没有现在流行罢了.之所以当下如此盛行,我想肯定是多 ...
- Pandas快速上手(一):基本操作
本文包含一些 Pandas 的基本操作,旨在快速上手 Pandas 的基本操作. 读者最好有 NumPy 的基础,如果你还不熟悉 NumPy,建议您阅读NumPy基本操作快速熟悉. Pandas 数据 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- 三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 前文:三分钟快速上手TensorFlow 2.0 (上)——前置基础.模型建立与可视化 tf.train. ...
- 三分钟快速上手TensorFlow 2.0 (上)——前置基础、模型建立与可视化
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 学习笔记类似提纲,具体细节参照上文链接 一些前置的基础 随机数 tf.random uniform(sha ...
- 几个小实践带你快速上手MindSpore
摘要:本文将带大家通过几个小实践快速上手MindSpore,其中包括MindSpore端边云统一格式及华为智慧终端背后的黑科技. MindSpore介绍 MindSpore是一种适用于端边云场景的新型 ...
- 快速上手Unity原生Json库
现在新版的Unity(印象中是从5.3开始)已经提供了原生的Json库,以前一直使用LitJson,研究了一下Unity用的JsonUtility工具类的使用,发现使用还挺方便的,所以打算把项目中的J ...
- [译]:Xamarin.Android开发入门——Hello,Android Multiscreen快速上手
原文链接:Hello, Android Multiscreen Quickstart. 译文链接:Hello,Android Multiscreen快速上手 本部分介绍利用Xamarin.Androi ...
随机推荐
- PTE 准备之 Repeat sentence
Repeat sentence After listening to a sentence ,repeat the sentence 3-9 seconds 15 seconds Strategies ...
- Python中的描述器
21.描述器:Descriptors 1)描述器的表现 用到三个魔术方法.__get__() __set__() __delete__() 方法签名如下: object.__get__(self ...
- github文件快速下载
目录 一,提升加载速度 二,提升下载速度 只是想快速下载文件的直接看第二部分. github加载速度慢究其原因还是伟大的墙的存在.我们需要赞美墙,但就算墙很伟大,问题还是要解决的. 有问题就解决问题, ...
- 创建数据库 UTF-8
CREATE DATABASE db_name DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
- 我叫小M,立志建立MySQL帝国。
我是小M,我在卡拉巴拉星球. 我喜欢数据,我立志成为一个数据管理者. 所以我来 Y 公司应聘,听说他们的数据量挺大的. 面试过程还是挺简单的. 我用 007 这三个数字就轻易打败了一堆吹嘘 996 的 ...
- Tomcat详解系列(3) - 源码分析准备和分析入口
Tomcat - 源码分析准备和分析入口 上文我们介绍了Tomcat的架构设计,接下来我们便可以下载源码以及寻找源码入口了.@pdai 源代码下载和编译 首先是去官网下载Tomcat的源代码和二进制安 ...
- [递推]B. 【例题2】奇怪汉诺塔
B . [ 例 题 2 ] 奇 怪 汉 诺 塔 B. [例题2]奇怪汉诺塔 B.[例题2]奇怪汉诺塔 题目描述 汉诺塔问题,条件如下: 这里有 A A A. B B B. C C C 和 D D D ...
- spring5源码编译过程中必经的坑
spring源码编译流程:Spring5 源码下载 第 一 步 : https://github.com/spring-projects/spring-framework/archive/v5.0.2 ...
- 考前自救题库NABCD分析
考前自救题库NABCD分析 项目 内容 这个作业属于哪个课程 2021春季软件工程(罗杰 任健) 这个作业的要求在哪里 团队项目-初次邂逅,需求分析 项目名称:考前自救题库(暂定) 项目简介:本产品计 ...
- java io系列
java io系列01之 "目录" java io系列02之 ByteArrayInputStream的简介,源码分析和示例(包括InputStream) java io系列03之 ...