ES 基础知识点总结
为什么使用 ES?
在传统的数据库中,如果使用某列记录某件商品的标题或简介。在检索时要想使用关键词来查询某个记录,那么是很困难的,假设搜索关键词 "小米",那么 sql 语句就是
select * from product where title like concat("%","小米","%")
这样即使 title 列上包含索引,索引也会失效。而如果使用全文索引,因为 B+ 树不支持全文索引,所以选择了全文索引就失去了 B+ 遍历高效的优点。所以 ES 就登场了,ES 之所以能高效检索,主要原因就是其倒排索引的特点。常规的索引,也就是正向索引,查询的过程是获取整条数据,然后从整条数据中来匹配关键词,如果包含就返回。而倒排索引是将数据拆分成多个关键词,每个关键词都作为一个倒排索引,然后查询时直接判断匹配,如果存在就返回该数据。这样因为使用了索引效率就极大的提高了。
概念
索引:相当于 MySQL 的库概念。
类型:相当于 MySQL 的表概念,在 ES7被移除。
文档:相当于 MySQL 的行记录概念。
字段:相当于 MySQL 的列概念。
分片:将某一类字段的文档拆分出来作为一个分片,查询时如果是这个字段的,直接去这个分片里查,可以提高系统整体的吞吐量。
副本:分片的复制,可以提高吞吐量(查询请求可以直接走副本)和分区容错性(分片所在的节点宕机后包含该分片副本的节点可以代替分片作用)
语法结构
query条件
Match:匹配查询
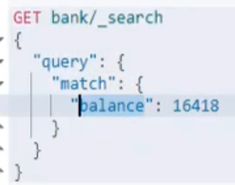
Balance:用于匹配的字段(相当于列名),如果是一个字符串就是部分匹配,如果是一个数字类型,就是短语查询。比如address:”a b c”那么只要包含a,b,c三个中任意一个就算匹配(如果abc连在一起那么就是包含完整的abc)。短语匹配就相当于Match_phrase,完整匹配
Match_phrase:短语匹配
无论是数字还是字符串都是完整匹配,以 address:"abc" 为例,address 包含 "abc" 这个字符串就算匹配。

字段后面加一个“.keyword”表示查询完全匹配的字段。以address:”abc”为例,address必须为abc才算匹配。
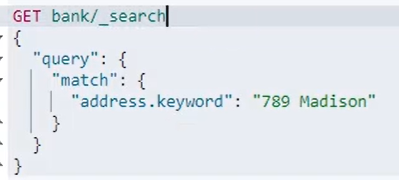
Match_all:所有字段
Multi_match:多字段匹配
多个字段只要有一个包含就满足,返回,同时也支持分词匹配
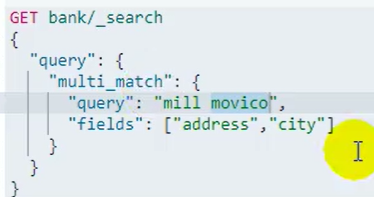
Address、city列只要有一个包含 mill和movico其中一个就满足
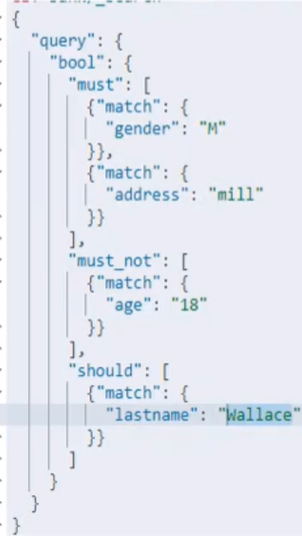
Bool:复合查询(多条件复杂查询)
Must:必须满足的
Match:匹配查询,字符串模糊查询,数字精确查询
Must_not:必须不满足
Should:可以满足可以不满足,满足的得分更高,排在前面。
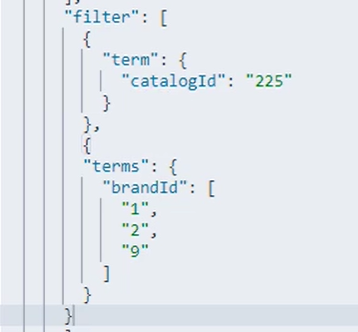
Filter:与must一样,但是不会贡献得分


Term:检索数字类型
作用与match一样,但是它只能检索数字类型,字符串类型不起作用。一般约定term用来检索数字,其他用match
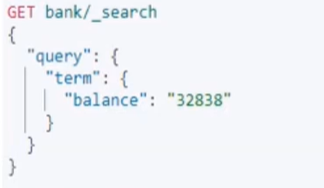
这里的 balance 是数字类型,双引号不需要加。
Terms:类似于 term,匹配多个值
其他
分页,指定返回的字段
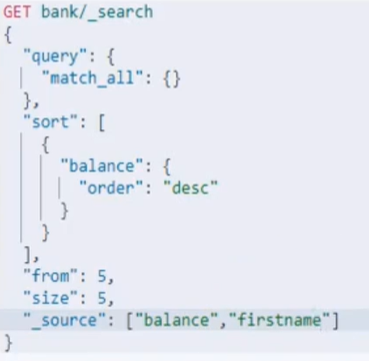
结果分析

聚合
聚合就是在查询结果的基础上,进行分组统计,聚合可以迭代。
AVG:平均值聚合
Terms:类型聚合
...等等

Aggs:表示是聚合,与query一样
ageAgg:聚合名,
Terms:类型聚合
Field:字段名
Size:取多少种
结果分析
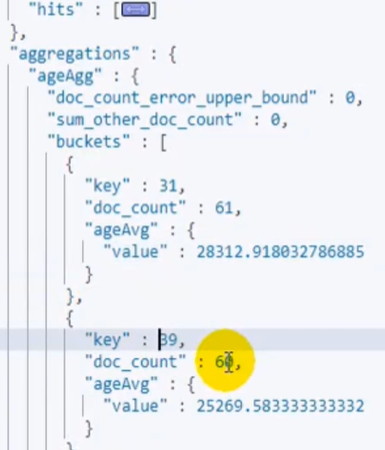
Key:年龄
Doc_count:结果数
ageAvg:子聚合
Value:子聚合的值
Mapping 映射
映射主要指的是 ES 字段的单位。主要包括 Integer、long、keyword、text、nested(嵌入式,防止扁平化处理)。
查看某个索引下的映射
Get /bank/_mapping

添加索引并指定其字段映射
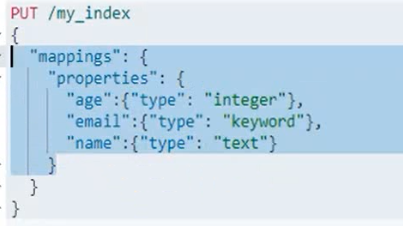
为某个索引添加新的字段并指定映射
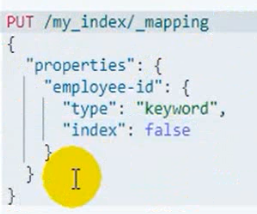
修改字段映射
不支持对已存在的索引进行映射修改。可以使用数据迁移来完成。
1、创建临时索引
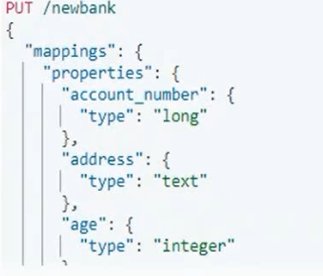
2、将之前的索引数据迁移到创建的临时索引中。
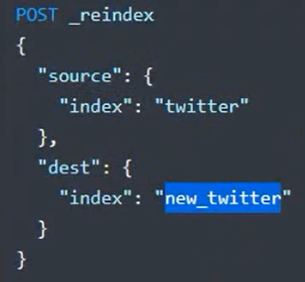
Source:原来的索引, index 来指定索引名也可以在index后面指定type,但是因为7开始移除了类型(相当于数据库表),所以不需要指定了。
Dest:要转移的索引名, index 来指定索引名。以当前例子来看就是 newbank
3、将原索引删除,再创建新的索引,指定映射。
DELETE bank
4、最后将临时索引数据迁移到新创建的索引中。
扁平化

由于扁平化的占用,在检索 first 为 John,last 为 white 的文档时,也会检索到。所以对于子类中包含两个或以上属性的,应该将父类字段映射设为 nested 类型来防止 ES 的扁平化处理。(默认空间的不会进行扁平化,也就是properties下第一层的不会)
例子如下:
映射:

查询:
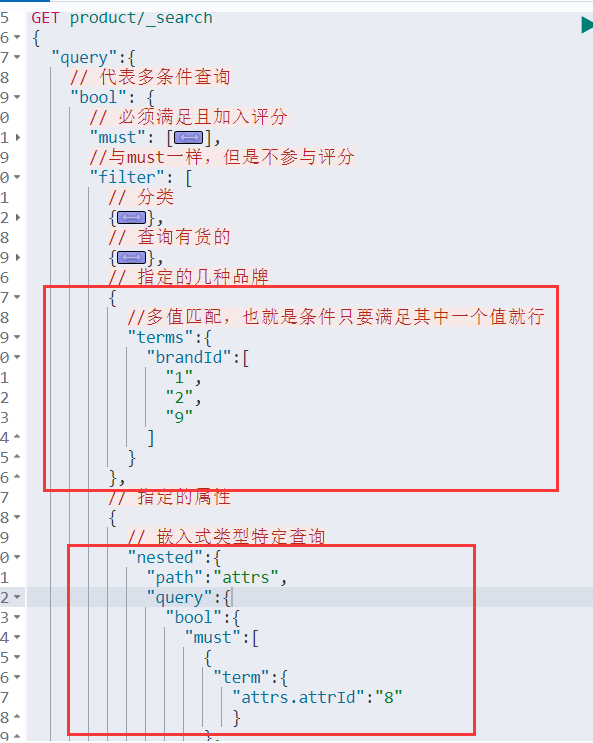
聚合:
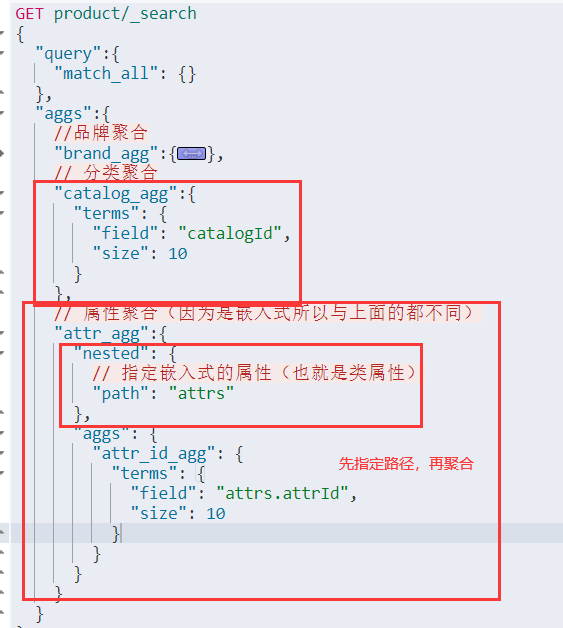
映射结果分析

分词
分词是 ES 的倒排索引,所以分词器就决定了 ES 的倒排索引是什么,默认的分词器是选择空格隔开的英文作为一个分词,中文的话每一个字都会是一个分词。测试分词效果:
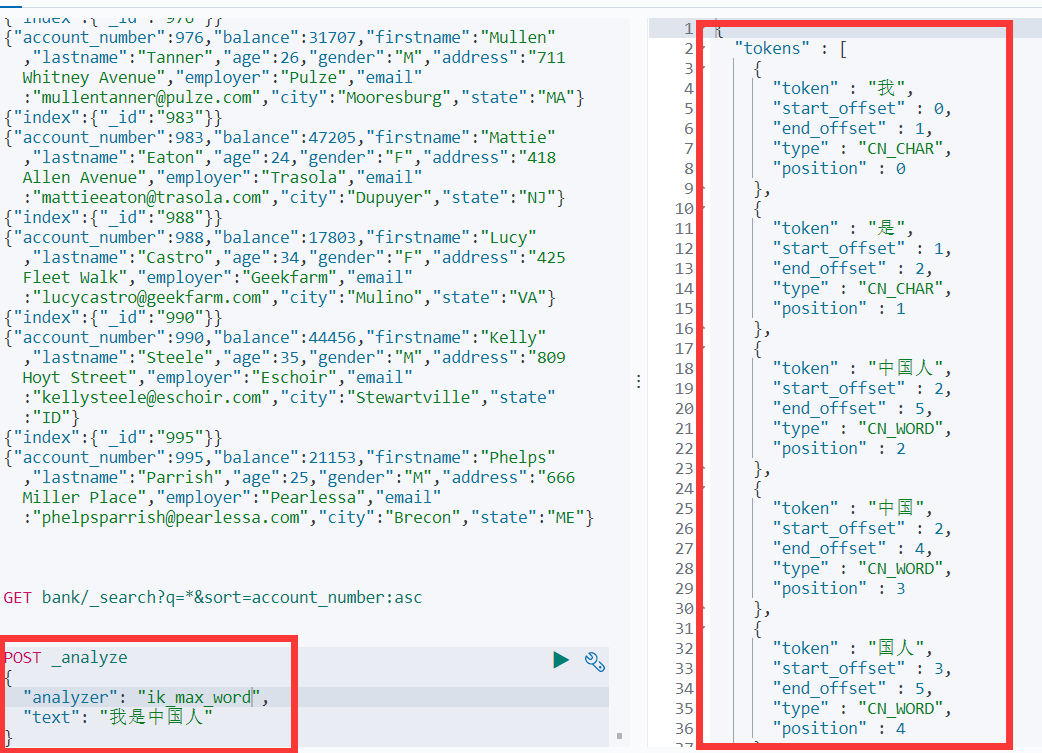
如果想使用常用的中文分词,可以使用 ik 分词器,可以满足绝大多数的中文分词,而对于一些特殊的分词,可以使用配置自定义的分词,然后将保存自定义分词的文件配置到 ik 分词器中。
原理
ES架构
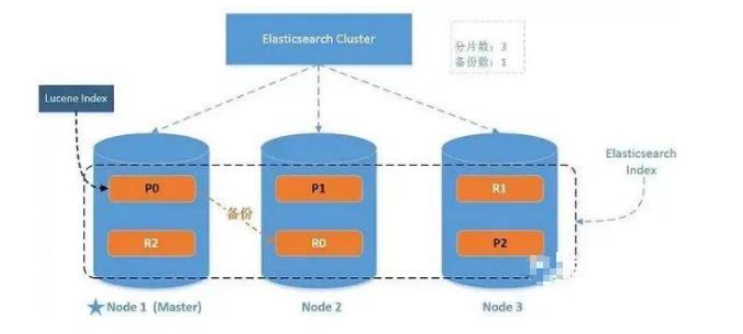
ES 是一个开源的高拓展的分布式全文搜索引擎,这句话表现出 ES 的两个重要特点,全文搜索和高拓展分布式。其中全文搜索可以通过倒排索引体现出,而高拓展的分布式则可以通过其架构体现出。上面就是一个 ES 集群的架构图,Node1、Node2、Node3 是三个节点服务器,其中 Node1 是主节点。在 ES 中配置了三个分片(P0、P1、P2,这三个分片保存着 ES 整个数据),同时,为了保证 ES 的分区容错性以及查询效率,每个分片还配置了一个副本(分别是 R0、R1、R2),原分片处理读和写操作,副本处理读操作。在分布中将副本与原分片拆开放置,避免某个节点宕机该分片的数据无法使用。并且在增加节点后,集群会自动分配分片和副本,保证均匀分布在不同的节点上。比如:
单节点:

二节点:

三节点:

操作过程
存储:根据存储数据的 hash 取余计算分配的节点位置,选择分片进行保存,随后再将保存数据更新到所有副本中。默认情况下当大多数副本都同步完成时,就返回存储完成的通知。这个可以通过 consistency 参数配置,all 表示必须所有的 副本都同步完成才返回存储完成的通知,one 表示只要主分片同步完成就返回存储完成的通知(检索结果可能会被还未同步的副本处理,造成未检索到),默认值是 quornum。
查询:轮询数据所在的分片和副本,发送请求。
更新:和存储一样,取余得到节点位置,找到分片后更新,再同步到其他副本,等到所有副本都同步完成后再返回更新成功的提示。
倒排索引的结构:倒排索引是无法修改的,好处是不用担心读写不一致的问题,但是缺点也非常明显,会大量的占用空间。为了减少空间占用,引入了段的概念,每个倒排索引都拥有一个段,在每次更新时都会将补充索引写入段中,然后检索时就会结合段中的数据和补充索引返回数据。
删除:每个段中都有一个 .del 文件,当该倒排索引被下达删除请求后,就会在 .del 文件进行标记,随后检索就会跳过当前段,也就是逻辑删除。当倒排索引特别多时,会进行合并,此时会将那些逻辑删除的段彻底删除。
持久化:ES 数据的保存和检索都在内存中,这也是它检索速度快的原因之一,而其也会定期持久化到磁盘。
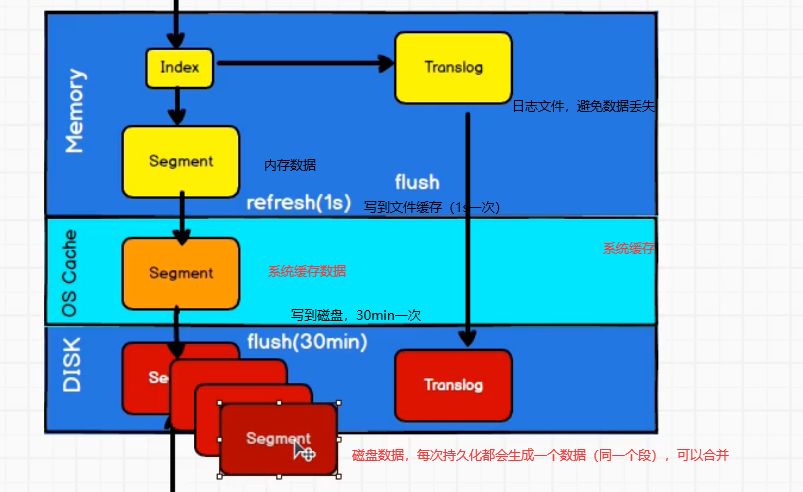
在分片执行更新、保存数据时,底层还伴随着定期持久化,在写入时,会先更新内存,随后写入内存中的 translog 里(避免断电导致内存数据丢失,类似于 mysql 中的 redo log)。然后进行 refresh(默认1s执行一次)到文件系统缓存,更新到系统缓存后数据才能被检索到。并且后台还会定期 flush(默认30min执行一次) ,将数据持久化到磁盘上。
本文主要参考某谷的ES视频
ES 基础知识点总结的更多相关文章
- HTML&&CSS基础知识点整理
HTML&&CSS基础知识点整理 一.WEB标准:一系列标准的集合 1. 结构(Structure):html 语言:XHTML[可扩展超文本标识语言]和XML[可扩展标记语言] 2. ...
- fastclick 源码注解及一些基础知识点
在移动端,网页上的点击穿透问题导致了非常糟糕的用户体验.那么该如何解决这个问题呢? 问题产生的原因 移动端浏览器的点击事件存在300ms的延迟执行,这个延迟是由于移动端需要通过在这个时间段用户是否两次 ...
- .NET基础知识点
.NET基础知识点 l .Net平台 .Net FrameWork框架 l .Net FrameWork框架提供了一个稳定的运行环境,:来保障我们.Net平台正常的运转 l 两种交 ...
- JavaScript 开发者经常忽略或误用的七个基础知识点(转)
JavaScript 本身可以算是一门简单的语言,但我们也不断用智慧和灵活的模式来改进它.昨天我们将这些模式应用到了 JavaScript 框架中,今天这些框架又驱动了我们的 Web 应用程序.很多新 ...
- JavaScript 开发者经常忽略或误用的七个基础知识点
JavaScript 本身可以算是一门简单的语言,但我们也不断用智慧和灵活的模式来改进它.昨天我们将这些模式应用到了 JavaScript 框架中,今天这些框架又驱动了我们的 Web 应用程序.很多新 ...
- JavaScript开发者常忽略或误用的七个基础知识点
JavaScript 本身可以算是一门简单的语言,但我们也不断用智慧和灵活的模式来改进它.昨天我们将这些模式应用到了 JavaScript 框架中,今天这些框架又驱动了我们的 Web 应用程序.很多新 ...
- JavaScript语言基础知识点图示(转)
一位牛人归纳的JavaScript 语言基础知识点图示. 1.JavaScript 数据类型 2.JavaScript 变量 3.Javascript 运算符 4.JavaScript 数组 5.Ja ...
- JavaScript 语言基础知识点总结
网上找到的一份JavaScript 语言基础知识点总结,还不错,挺全面的. (来自:http://t.cn/zjbXMmi @刘巍峰 分享 )
- c语言学习之基础知识点介绍(三):scanf函数
本节继续介绍c语言的基础知识点. scanf函数:用来接收用户输入的数据. 语法:scanf("格式化控制符",地址列表); 取地址要用到取地址符:&(shift+7) 例 ...
随机推荐
- THINKPHP_(7)_THINKPHP6的controller模型接收前端页面通过ajax返回的数据,会因为一个div而失败
这个随笔比较短. 同样的前端页面代码,修改了一下,后端模型接收不到数据. 利用beyond compare软件比对两个前端文件, 发现多了一个</div>标签. 多了一个</div& ...
- TVM交叉编译和远程RPC
TVM交叉编译和远程RPC 本文介绍了TVM中使用RPC的交叉编译和远程设备执行. 使用交叉编译和RPC,可以在本地计算机上编译程序,然后在远程设备上运行它.当远程设备资源受到限制时(如Raspber ...
- C++/VS基础篇
------------恢复内容开始------------ VS: 1.项目配置 2.IDE设置 错误列表是输出窗口的大概,根据error语法整理出,不准确. C++: 1.C++特点 优点 可直接 ...
- Docker-compose搭建ELK环境并同步MS SQL Server数据
前言 本文作为学习记录,供大家参考:一次使用阿里云(Aliyun)1核2G centos7.5 云主机搭建Docker下的ELK环境,并导入MS SQL Server的商品数据以供Kibana展示的配 ...
- 【NX二次开发】查找部件中的对象 UF_OBJ_cycle_objs_in_part
返回所有层上指定类型部件中的所有对象,不管它们的当前显示状态如何.这个例程不返回表达式.指定对象.临时(系统创建的)对象或休眠对象.休眠对象指的是从模型中删除的对象例如,如果你混合了一条边,那么这条边 ...
- 【C++】vector容器的用法
检测vector容器是否为空: 1 #include <iostream> 2 #include <string> 3 #include <vector> 4 us ...
- 「10.16晚」序列(....)·购物(性质)·计数题(DP)
A. 序列 考场不认真读题会死..... 读清题就很简单了,分成若干块,然后块内递增,块外递减,同时使最大的块长为$A$ B. 购物 考场思路太局限了,没有发现性质, 考虑将$a_{i}$,排序前缀和 ...
- Golang限制函数调用次数
Golang限制函数调用次数 项目环境 ubuntu+go1.14 需求描述 限制某个函数5秒内只能调用一次,5秒内的其他调用抛弃 工具包使用 这里用到了官方限流器/time/rate 该限流器是基于 ...
- 用python的matplotlib根据文件里面的数字画图像折线图
思路:用open打开文件,再用a=filename.readlines()提取每行的数据作为列表的值,然后传递列表给matplotlib并引入对应库画出图像 代码实现:import matplotli ...
- rsync 基本使用
基本参数 # rsync -P test.tar.gz ./ test.tar.gz 395,706,368 48% 377.34MB/s 0:00:01 Or # rsync -avPh test. ...