❤️❤️新生代农民工爆肝8万字,整理Python编程从入门到实践(建议收藏)已码:8万字❤️❤️
@

开发环境搭建
- Pycharm
- Python3
- window10/win7
安装 Python
打开Python官网地址
下载 executable installer,x86 表示是 32 位机子的,x86-64 表示 64 位机子的。

开始安装
- 双击下载的安装包,弹出如下界面

这里要注意的是:
- 将python加入到windows的环境变量中,如果忘记打勾,则需要手工加到环境变量中
- 在这里我选择的是自定义安装,点击“自定义安装”进行下一步操作
- 双击下载的安装包,弹出如下界面

{kind=link}
验证是否安装成功
- 按 Win+R 键,输入 cmd 调出命令提示符,输入 python:

安装Pycharm
- 打开Pycharm官网下载链接
- 选择下载的版本(当前下载的是Windows下的社区版)
- 专业版收费的,当前下载的社区版免费

配置pycharm
- 外观配置(推荐使用Darcula)

- 配色方案(推荐使用Monokai)

- 代码编辑区域字体及大设置(推荐使用Consolas)

- 控制台字体选择及大小设置

- 文件模版配置
编码规范
- 类名采用驼峰命名法,即类名的每个首字母都大写,如:class HelloWord,类名不使用下划线
- 函数名只使用小写字母和下划线
- 定义类后面包含一个文档字符串且与代码空一行,字符串说明也可以用双三引号
- 顶级定义之间空两行
- 两个类之间使用两个空行来分隔
- 变量等号两边各有一个空格 a = 10
- 函数括号里的参数 = 两边不需要空格
- 函数下方需要带函数说明字符串且与代码空一行
- 默认参数要写在最后,且逗号后边空一格
- 函数与函数之间空一行
- if语句后的运算符两边需要空格
- 变量名,函数名,类名等不要使用拼音
- 注释要离开代码两个空格

基本语法规则
保留字
- 保留字即关键字,我们不能把它们用作任何标识符名称。
- Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字
import keyword
keyword.kwlist
# 关键字列表
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
单行注释
Python中单行注释以 # 开头,实例如下:
# 第一个注释
print ("Hello, Python!") # 第二个注释
多行注释
多行注释可以用多个 # 号,还有'''和 """xxxx""":
# 第一个注释
# 第二个注释
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
行与缩进
- python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
- 缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
# 正确行与缩进
if True:
print ("True")
else:
print ("False")
# 错误的行与缩进
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
多行语句
- Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
数据类型
Python中数字有四种类型:整数、布尔型、浮点数和复数。
int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
bool (布尔), 如 True和False
float (浮点数), 如 1.23
complex (复数), 如 1 + 2j、 1.1 + 2.2j查看类型,用type()方法
字符串
python中单引号和双引号使用完全相同
使用三引号('''或""")可以指定一个多行字符串
空行
def hello():
pass
# 此处为空行
def word():
pass
等待用户输入
input("请输入你的名字")
print输出
x = "a"
y = "b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
运算符
本章节主要说明Python的运算符。举个简单的例子 1 +2 = 3 。 例子中,1 和 1、2 被称为操作数,"+" 称为运算符。
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 运算符优先级
算术运算符
以下假设变量:a=10,b=20
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加: 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘: 两个数相乘 | a * b 输出结果 200 |
| 返回一个被重复若干次的字符串,如:HI*3 | HI,HI,HI | |
| / | 除: x除以y(即两个数的商) | b / a 输出结果 2 |
| % | 取模:返商的余数 | b % a 输出结果 0 |
| ** | 幂:返回x的y次幂 | a**b 为10的20次方,输出结果100000000000000000000 |
| // | 取整除: 返回商的整数部分 | 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
注:加号也可用作连接符,但两边必须是同类型的才可以,否则会报错,如:23+ “Python” ,数字23和字符串类型不一致
比较运算符
以下假设变量a为10,变量b为20
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回 False |
| != | 不等于:比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于:返回x是否大于y | (a > b) 返回 False |
| < | 小于:返回x是否小于y | (a < b) 返回 True。 |
| >= | 大于等于:返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于等于:返回x是否小于等于y | (a <= b) 返回 True |
注:所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意True和False第一个字母是大写
赋值运算符
以下假设变量a为10,变量b为20
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与":如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值 | (a and b) 返回 20 |
| or | x or y | 布尔"或" :如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值 | (a or b) 返回 10 |
| not | not x | 布尔"非":如果 x 为 True,返回 False 。如果 x 为 False它返回 True | not(a and b) 返回 False |
成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,商,取余和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |

字符串
- 字符串是由数字,字母、下划线组成的一串字符
- 创建字符串,可以使用单引号('')和双引号("")
# -*- coding: utf-8 -*-
# @Author : 码上开始
var1 = 'Hello World!'
var2 = "Hello World!"
访问字符串中的值
- Python 访问子字符串,可以使用方括号 [] 来截取字符串
# -*- coding: utf-8 -*-
# @Author : 码上开始
var = “Hello World”
print(var[0])
#运行结果H
字符串更新
# -*- coding: utf-8 -*-
# @Author : 码上开始
print(var1[0:6] + “Python”)
#运行结果:Hello Python
另一种写法:
print(var1[:6] + “Python”)
#运行结果:Hello Python
合并连接字符串
- 使用+号连接字符
- +两边类型必须一致
#-*- coding: utf-8 -*-
#@Author : 码上开始
first_word = “码上”
last_word = “开始”
print(first_word + last_word)
#运行结果为:码上开始
删除空白
- ” Python”和”Python ”表面上看两个字符串是一样的,但实际代码中是认为不相同的
- 因为后面的字串符有空白,那么如何去掉空白?
# -*- coding: utf-8 -*-
# @Author : 码上开始
language = "Python "
language.rstrip() # 删除右边空格
language = " Python"
language.lstrip() # 删除左边空格
language = " Python " #
language.strip() # 删除左右空白
startswith()方法
# str传入的是字符串
str.startswith(str, beg=0,end=len(string))
方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
如果参数 beg 和 end 指定值,则在指定范围内检查。
# -*- coding: utf-8 -*-
# @Author : 码上开始
str = "this is string example....wow!!!"
# 默认从坐标0开始匹配this这个字符
print str.startswith( 'this' )
# 指定下标从2到4匹配is
print str.startswith( 'is', 2, 4 )
# 同上
print str.startswith( 'this', 2, 4 )
# 运行结果
True
True
False
传入的值为元组时
- 元组中只要任一元素匹配则返回True,反之为False
# -*- coding: utf-8 -*-
# @Author : 码上开始
string = "Postman"
# 元组中只要任一元素匹配则返回True,反之为False
print(string.startswith(("P", "man"),0))
# 虽然元组元素Po/man都存在字符中,但不匹配开始的下标,所以仍返回值Flase
print(string.startswith(("Po", "man"),1))
endswith()方法
# 语法
str.endswith(string,[, start[, end]])
Python endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。
可选参数"start"与"end"为检索字符串的开始与结束位置。
# -*- coding: utf-8 -*-
# @Author : 码上开始
string = "this is string example....wow!!!";
str = "wow!!!"
print(string.endswith(str))
print(string.endswith(str,20))
str1 = "is"
print(string.endswith(str1, 2, 4))
print(string.endswith(str1, 2, 6))
# 运行结果
True
True
True
False
字符串格式化
- %格式化:占位符%,搭配%符号一起使用
- 传整数时:%d
- 传字符串时:%s
- 传浮点数时:%f
# -*- coding: utf-8 -*-#
@Author : 码上开始
age = 29
print("my age is %d" %age)
#my age is 29
name = "makes"print("my name is %s" %name)
#my name is makes
print("%f" %2.3)#2.300000
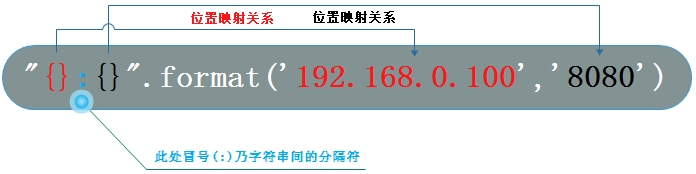
format()格式化:占位符{},搭配format()函数一起使用
位置映射
print("{}:{}".format('192.168.0.100',8888))#192.168.0.100:8888
关键字映射
print("{server}{1}:{0}".format(8888,'192.168.1.100',server='Web Server Info :'))
#Web Server Info :192.168.1.100:8888

字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 'HelloPython' |
| * | 重复输出字符串 | a * 2 'HelloHello' |
| [] | 通过索引获取字符串中字符 | a[1] 'e' |
| [ : ] | 截取字符串中的一部分 | a[1:4] 'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | "H" in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | "M" not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n' \n >>> print R'\n' \n |

列表
- 列表:用于存储任意数目、任意类型的数据集合。
1.基本语法[]创建
a = [1, 'jack', True, 100]
b = []
2. list()创建
使用list()可以将任何可迭代的数据转化成列表
a = list() # 创建一个空列表
b = list(range(5)) # [0, 1, 2, 3, 4]
c = list('nice') # ['n', 'i', 'c', 'e']
3. 通过range()创建整数列表
range()
可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为:`range([start,]end[,step])
start参数:可选,表示起始数字。默认是0。
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1。
python3中range()返回的是一个range对象,而不是列表。我们需要通过list()方法将其转换成列表对象。
a = list(range(-3, 2, 1)) # [-3, -2, -1, 0, 1]
b = list(range(2, -3, -1)) # [2, 1, 0, -1, -2]
4. 列表推导式
a = [i * 2 for i in range(5) if i % 2 == 0] # [0, 4, 8]
points = [(x, y) for x in range(0, 2) for y in range(1, 3)]
print(points) # [(0, 1), (0, 2), (1, 1), (1, 2)]
列表元素的增加
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。除非必要,我们一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
append()
>>>a = [20,40]
>>>a.append(80)
>>>a
[20,40,80]
+运算符
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
>>> a = [3, 1, 4]
>>> b = [4, 2]
>>> a + b
[3, 1, 4, 4, 2]
extend()
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
>>> a = [3, 2]
>>> a.extend([4, 6])
>>> a
[3, 2, 4, 6]
insert()
使用insert()方法可以将指定的元素插入到列表对象的任意指定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:remove()、pop()、del(),它们在删除非尾部元素时也会发生操作位置后面元素的移动。
>>> a = [2, 5, 8]
>>> a.insert(1, 'jack')
>>> a
[2, 'jack', 5, 8]
- 乘法
使用乘法扩展列表,生成一个新列表,新列表元素时原列表元素的多次重复。
>>> a = [4, 5]
>>> a * 3
[4, 5, 4, 5, 4, 5]
适用于乘法操作的,还有:字符串、元组。
列表元素的删除
del()
删除列表指定位置的元素。
>>> a = [2, 3, 5, 7, 8]
>>> del a[1]
>>> a
[2, 5, 7, 8]
pop()
删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
>>> a = [3, 6, 7, 8, 2]
>>> b = a.pop()
>>> b
2
>>> c = a.pop(1)
>>> c
6
remove()
删除首次出现的指定元素,若不存在该元素抛出异常。
>>> a=[10,20,30,40,50,20,30,20,30]
>>> a.remove(20)
>>> a
[10, 30, 40, 50, 20, 30, 20, 30]
clear()
清空一个列表。
a = [3, 6, 7, 8, 2]
a.clear()
print(a) # []
列表元素的访问
- 通过索引直接访问元素
>>> a = [2, 4, 6]
>>> a[1]
4
index()获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的索引位置。语法是:index(value,[start,[end]])。其中,start和end指定了搜索的范围。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.index(20)
1
>>> a.index(20, 3)
5
>>> a.index(20, 6, 8)
7
列表元素出现的次数
返回指定元素在列表中出现的次数。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.count(20)
3
切片(slice)
[起始偏移量start:终止偏移量end[:步长step]]
三个量为正数的情况下
| 操作和说明 | 示例 | 结果 |
| ---------------------------------------------------- | ------------------------------------- | -------------- |
|[:]提取整个列表 |[10, 20, 30][:]|[10, 20, 30]|
|[start:]从start索引开始到结尾 |[10, 20, 30][1:]|[20, 30]|
|[:end]从头开始到 end-1 |[10, 20, 30][:2]|[10, 20]|
|[start:end]从 start 到 end-1 |[10, 20, 30, 40][1:3]|[20, 30]|
|[start:end:step]从 start 提取到 end-1,步长是step |[10, 20, 30, 40, 50, 60, 70][1:6:2]|[20, 40, 60]|三个量为负数的情况
| 示例 | 说明 | 结果 |
| ------------------------------------- | ---------------------- | ------------------------ |
|[10, 20, 30, 40, 50, 60, 70][-3:]| 倒数三个 |[50, 60, 70]|
|[10, 20, 30, 40, 50, 60, 70][-5:-3]| 倒数第五个至倒数第四个 |[30, 40]|
|[10,20,30,40,50,60,70][::-1]| 逆序 |[70,60,50,40,30,20,10]|
t1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
print(t1[100:]) # []
print(t1[0:-1]) # [11, 22, 33, 44, 55, 66, 77, 88]
print(t1[1:5:-1]) # []
print(t1[-1:-5:-1]) # [99, 88, 77, 66]
print(t1[-5:-1:-1]) # []
print(t1[5:-1:-1]) # []
print(t1[::-1]) # [99, 88, 77, 66, 55, 44, 33, 22, 11]
# 注意以下两个
print(t1[3::-1]) # [44, 33, 22, 11]
print(t1[3::1]) # [44, 55, 66, 77, 88, 99]
123456789101112131415161718
列表的排序
- 修改原列表,不创建新列表的排序
a = [3, 2, 8, 4, 6]
print(id(a)) # 2180873605704
a.sort() # 默认升序
print(a) # [2, 3, 4, 6, 8]
print(id(a)) # 2180873605704
a.sort(reverse=True)
print(a) # [8, 6, 4, 3, 2]
12345678
# 将序列的所有元素随机排序
import random
b = [3, 2, 8, 4, 6]
random.shuffle(b)
print(b) # [4, 3, 6, 2, 8]
12345
- 创建新列表的排序
通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
a = [3, 2, 8, 4, 6]
b = sorted(a) # 默认升序
c = sorted(a, reverse=True) # 降序
print(b) # [2, 3, 4, 6, 8]
print(c) # [8, 6, 4, 3, 2]
12345
- 冒泡排序
list1 = [34,54,6,5,65,100,4,19,50,3]
#冒泡排序,以升序为例
#外层循环:控制比较的轮数
for i in range(len(list1) - 1):
#内层循环:控制每一轮比较的次数,兼顾参与比较的下标
for j in range(len(list1) - 1 - i):
#比较:只要符合条件则交换位置,
# 如果下标小的元素 > 下标大的元素,则交换位置
if list1[j] < list1[j + 1]:
list1[j],list1[j + 1] = list1[j + 1],list1[j]
print(list1)
- 选择排序
li = [17, 4, 77, 2, 32, 56, 23]
# 外层循环:控制比较的轮数
for i in range(len(li) - 1):
# 内层循环:控制每一轮比较的次数
for j in range(i + 1, len(li)):
# 如果下标小的元素>下标大的元素,则交换位置
if li[i] > li[j]:
li[i], li[j] = li[j], li[i]
print(li)
列表元素的查找
- 顺序查找
# 顺序查找
# 1.需求:查找指定元素在列表中的位置
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 6
for i in range(len(list1)):
if key == list1[i]:
print("%d在列表中的位置为:%d" % (key,i))
# 2.需求:模拟系统的index功能,只需要查找元素在列表中第一次出现的下标,如果查找不到,打印not found
# 列表.index(元素),返回指定元素在列表中第一次出现的下标
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 10
for i in range(len(list1)):
if key == list1[i]:
print("%d在列表中的位置为:%d" % (key,i))
break
else:
print("not found")
# 3.需求:查找一个数字列表中的最大值以及对应的下标
num_list = [34, 6, 546, 5, 100, 16, 77]
max_value = num_list[0]
max_index = 0
for i in range(1, len(num_list)):
if num_list[i] > max_value:
max_value = num_list[i]
max_index = i
print("最大值%d在列表中的位置为:%d" % (max_value,max_index))
# 4.需求:查找一个数字列表中的第二大值以及对应的下标
num_list = [34, 6, 546, 5, 100, 546, 546, 16, 77]
# 备份
new_list = num_list.copy()
# 升序排序
for i in range(len(new_list) - 1):
for j in range(len(new_list) - 1 - i):
if new_list[j] > new_list[j + 1]:
new_list[j],new_list[j + 1] = new_list[j + 1],new_list[j]
print(new_list)
# 获取最大值
max_value = new_list[-1]
# 统计最大值的个数
max_count = new_list.count(max_value)
# 获取第二大值
second_value = new_list[-(max_count + 1)]
# 查找在列表中的位置:顺序查找
for i in range(len(num_list)):
if second_value == num_list[i]:
print("第二大值%d在列表中的下表为:%d" % (second_value,i))
- 二分法查找
# 二分法查找的前提:有序
li = [45, 65, 7, 67, 100, 5, 3, 2, 35]
# 升序
new_li = sorted(li)
key = 100
# 定义变量,表示索引的最小值和最大值
left = 0
right = len(new_li) - 1
# left和right会一直改变
# 在改变过程中,直到left==right
while left <= right:
# 计算中间下标
middle = (left + right) // 2
# 比较
if new_li[middle] < key:
# 重置left的值
left = middle + 1
elif new_li[middle] > key:
# 重置right的值
right = middle - 1
else:
print(f'key的索引为{li.index(new_li[middle])}')
break
else:
print('查找的key不存在')
列表的其他方法
reverse()
用于列表中数据的逆序排列。
a = [3, 2, 8, 4, 6]
a.reverse()
print(a) # [6, 4, 8, 2, 3]
copy()
复制列表,属于浅拷贝。
a = [3, 6, 7, 8, 2]
b = a.copy()
print(b) # [3, 6, 7, 8, 2]
列表相关的内置函数
max()和min()
返回列表中的最大值和最小值
a = [3, 2, 8, 4, 6]
print(max(a)) # 8
print(min(a)) # 2
sum()
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
a = [3, 2, 8, 4, 6]
print(sum(a)) # 23
字典
字典的特点
- 字典中的元素是key: value的形式存储数据,即键值对
- 字典是无序数据,即没有索引值
- key是唯一的,如果key重复, 则覆盖前面的值,支持数据类型有:int,float, bool, str, 元组(不能为列表)
- value支持任何数据类型,就是说字典的值可以进行:增删改的操作
- 字典不支持加号拼接和乘号多次输出

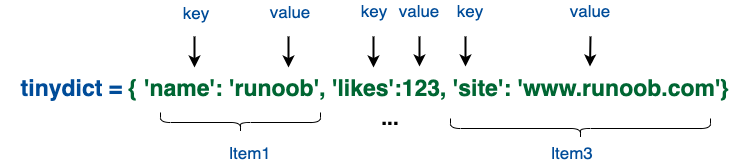
定义字典
- 定义空字典: dict = { }
- 定义非空字典 dict = {key1: value1,key2: value2}
字典基本操作
- 描述中统一字典名为:dict,键为:key,值为:value,根据实际情况进行调整
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
读取字典的值
- 语法:dict[key]
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
print(dict["CSDN"])
# 运行结果
码上开始
增加字典的值
- 语法:dict[key]=value
- key为不存在的,如果是存在的则是修改当前key的值
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
dict["age"] = 35
print(dict)
# 运行结果
{'CSDN': '码上开始', 'name': '老猪', 'age': 35}
删除单个元素
- 语法:del dict[key]
- 也可以使用dict.pop()
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
del dict["name"]
# dict.pop("name")
print(dict)
# 运行结果
{'CSDN': '码上开始'}
删除整个字典
- 语法:dict.clear()
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
dict.clear()
print(dict)
# 运行结果
{}
修改字典的值
- dict[key]=value
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
dict["CSDN"]="乌托邦"
print(dict)
# 运行结果
{'CSDN': '乌托邦', 'name': '老猪'}
字典常用方法
dict.keys()---获取字典里所有的键
常搭配for循环使用
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
for key in dict.keys():
print(key)
# 运行结果
CSDN
name
- dict.values()---获取字典里所有的键
- 常搭配for循环使用
# -*- coding: utf-8 -*-
# @Author : 码上开始
dict = {"CSDN": "码上开始", "name": "老猪"}
for value in dict.values():
print(value)
# 运行结果
码上开始
老猪
- dict.itmes()---获取字典里的所有键和值
- 常搭配for循环使用
# -*- coding: utf-8 -*-# @Author : 码上开始dict = {"CSDN": "码上开始", "name": "老猪"}for key, value in dict.items(): print("key值:", key) print("value:", value) # 运行结果key值: CSDNvalue: 码上开始key值: namevalue: 老猪
数据转换
将列表或元组转成字典
语法:dict(list/tuple)
# -*- coding: utf-8 -*-# @Author : 码上开始tuple = (("CSDN, "码上开始"), ("name", "老猪"))# list = [["CSDN", "码上开始"], ["name", "老猪"]]print(dict(tuple))# 运行结果{'CSDN': '码上开始', 'name': '老猪'}
嵌套
- 有时候,需要将一系列字典存储在列表中,或将列表作为值存储在字典中,这称为嵌套
- 可以在列表中嵌套字典、在字典中嵌套列表甚至在字典中嵌套字典
# -*- coding: utf-8 -*-# @Author : 码上开始words = {"name": {"CSDN": "码上开始"}}print(words["name"]["CSDN"])# 运行结果码上开始
字典常用内置函数
- len(dict):计算字典元素个数,即键的总数
- type():返回输入的变量类型,如果变量是字典就返回字典类型
元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改
元组与列表类似,下标索引从 0 /-1开始,可以进行截取,组合等
定义元组
- 元组使用小括号 ( )
- 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可
- 元组中只包含一个元素时,需要在元素后面添加逗号

创建元组
- 创建空元组
# -*- coding: utf-8 -*-
# @Author : 码上开始
songs = ()
- 创建非空元组
# -*- coding: utf-8 -*-
# @Author : 码上开始
songs = ("千里之外", "东风破", "比我幸福")
访问元组
- 通过下标取值
- 取值方式同列表
# -*- coding: utf-8 -*-
# @Author : 码上开始
songs = ("千里之外", "东风破", "比我幸福")
print(songs[0])
# 运行
千里之外
修改元组
- 元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
- 只有一个元素时,需要加逗号
# -*- coding: utf-8 -*-
# @Author : 码上开始
songs = ("千里之外", "东风破")
singers = ("周杰伦",)
starts = songs + singers
print(starts)
删除元组
- 元组中的元素值是不允许删除的
- 但我们可以使用del语句来删除整个元组
# -*- coding: utf-8 -*-
# @Author : 码上开始
songs = ("千里之外", "东风破")
del songs
# 运行报错,提示变量没有定义
print(songs)
元组运算符
- 与字符串一样,元组之间可以使用 + 号和 * 号进行运算
- 可以组合和复制,运算后会生成一个新的元组
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print (x,) | 1 2 3 | 迭代 |
元组切片取值
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素
也可以截取索引中的一段元素
操作方式和列表一样
tup = ('Google', 'Runoob', 'Taobao', 'Wiki', 'Weibo','Weixin')

| Python 表达式 | 结果 | 描述 |
|---|---|---|
| tup[1] | 'Runoob' | 读取第二个元素 |
| tup[-2] | 'Weibo' | 反向读取,读取倒数第二个元素 |
| tup[1:] | ('Runoob', 'Taobao', 'Wiki', 'Weibo', 'Weixin') | 截取元素,从第二个开始后的所有元素。 |
| tup[1:4] | ('Runoob', 'Taobao', 'Wiki') | 截取元素,从第二个开始到第四个元素(索引为 3)。 |
集合
- 集合(set)是一个无序的不重复元素序列。
- 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
{}定义集合
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
# 重复的元素,打印结果中只会显一个
fruit = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
# 打印结果
{'pear', 'orange', 'apple', 'banana'}
使用set函数创建集合
# -*- coding:utf-8 -*-
# @Author: "码上开始"
fruit = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
new_set = set(fruit)
# 重复的元素,打印结果中只会显一个
print(new_set)
# 结果
{'banana', 'apple', 'orange', 'pear'}
集合运算
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
a = set('abracadabra') # {'r', 'a', 'd', 'c', 'b'}
b = set('alacazam') # {'m', 'a', 'z', 'c', 'l'}
# a包含b不包含的元素
c = a - b
print(c)
# 结果
{'b', 'r', 'd'}
# 集合a或b中包含的所有元素
c = a | b
print(c)
# 结果
{'m', 'a', 'r', 'l', 'd', 'z', 'b', 'c'}
# 集合a和b中都包含了的元素
c = a & b
print(c)
# 结果
{'c', 'a'}
# 不同时包含于a和b的元素
c = a ^ b
print(c)
# 结果
{'r', 'm', 'z', 'b', 'd', 'l'}
集合的基本操作
添加元素(add/update)
- 如果添加元素如果存在,则不进行任何操作
- 可添加元素,也可以列表、元组、字典等
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
num = {1, 2, 3}
num.add(4)
print(num)
# 结果
{1, 2, 3, 4}
# -*- coding:utf-8 -*-
# @Author: "码上开始"
# 如果添加为列表等,则要用update方法
num = {1, 2, 3}
list = [4, 5]
num.update(list)
print(num)
# 结果
{1, 2, 3, 4, 5}
移除元素(remove/pop)
# -*- coding:utf-8 -*-
# @Author: "码上开始"
num = {1, 2, 3}
num.remove(1)
print(num)
# 结果
{2, 3}
# -*- coding:utf-8 -*-
# @Author: "码上开始"
# 随机删除集合中的元素
num = {1, 2, 3}
num.pop()
print(num)
# 结果
{2, 3}
计算集合元素个数
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
num = {1, 2, 3}
print(len(num))
# 结果
3
清空集合
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
num ={1, 2, 3}
num.clear()
print(num)
# 结果
set()
判断元素是否在集合中存在
判断元素 x 是否在集合中,存在返回 True,不存在返回 False
# -*- coding:utf-8 -*-
# @Time : 2020/10/8 9:59
# @File :day1.py
# @Author: "码上开始"
num ={1, 2, 3}
if 1 in num:
print("存在集合中")
集合内置方法完整列表
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
条件语句
每条if语句的核心都是一个值为True或False的表达式,这种表达式被称为条件测试。
Python 根据条件测试的值为True还是False来决定是否执行if语句中的代码。
如果条件测试的值为True, Python就执行紧跟在if语句后面的代码.
Python程序语言指定任何非0和非空(null)值为True,0 或者 null为False。
可以通过下图来简单了解条件语句的执行过程:
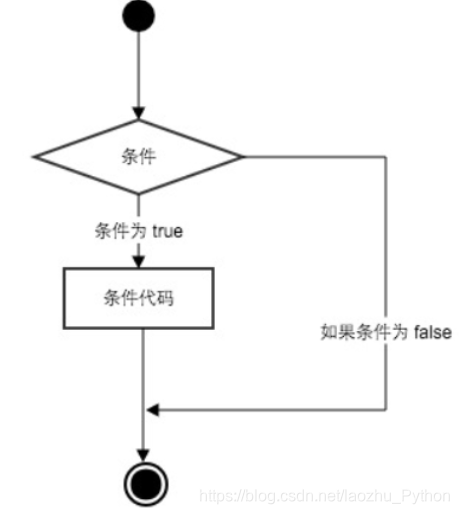
代码执行过程
- 如果条件为ture,一直执行if下的代码,直到条件为False
- 如果条件false直接执行else语句,如果没有else则不执行操作

注意
- 1、每个条件后面要使用冒号 : 表示接下来是满足条件后要执行的语句块。
- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
if
score = 90
if score >= 90:
print("成绩优秀")
if...else
score = 80
if score >= 90:
print("成绩优秀")
else:
print("成绩中等")
if..elif..else
score = 60
if score >= 90:
print("成绩优秀")
elif score > 60 :
print("成绩刚刚及格")
else:
print("你没及格喔,加油!")
循环
for循环是在python开发中用的很多的一种循环类型, 需要熟练掌握。
for循环的使用场景
- for循环用于重复执行具体次数操作
- for循环主要用来遍历、循环、列表、集合、字典,文件、甚至是自定义类或函数。
for循环操作列表实例演示
- 使用for循环经常结合if语句使用,对列表进行遍历元素、修改元素、删除元素、统计列表中元素的个数。
for循环用来遍历整个列表
#for循环主要用来遍历、循环、序列、集合、字典
Fruits = ['apple','orange','banana','grape']
for fruit in Fruits:
print(fruit)
print("结束遍历")
结果演示:
apple
orange
banana
grape
结速遍历
for循环用来修改列表中的元素
#for循环主要用来遍历、循环、序列、集合、字典
#把banana改为Apple
Fruits=['apple','orange','banana','grape']
for i in range(len(Fruits)):
if Fruits[i] == 'banana':
Fruits[i] ='apple'
print(Fruits)
结果演示:['apple', 'orange', 'apple', 'grape']
- for循环用来删除列表中的元素
Fruits=['apple','orange','banana','grape']
for i in Fruits:
if i == 'banana':
Fruits.remove(i)
print(Fruits)
结果演示:['apple', 'orange', 'grape']
for循环统计列表中某一元素的个数
#统计apple的个数
Fruits = ['apple','orange','banana','grape','apple']
count = 0
for i in Fruits:
if i=='apple':
count+=1
print("Fruits列表中apple的个数="+str(count)+"个")
结果演示:Fruits列表中apple的个数=2个
注:列表某一数据统计还可以使用Fruit.count(object)
for循环实现1到9相乘
sum=1
for i in list(range(1,10)):
sum *= i
print("1*2...*9=" + str(sum))
结果演示:1*2...*10=362880
遍历字符串
for str in 'abc':
print(str)
结果演示:
a
b
c
遍历集合对象
for str in {'a',2,'bc'}:
print(str)
结果演示:
a
2
bc
遍历文件
for content in open("D:\\test.txt"):
print(content)
结果演示:
朝辞白帝彩云间,千里江陵一日还。
两岸猿声啼不住,轻舟已过万重山。
遍历字典
for key,value in {"name":'码上开始',"age":22}.items():
print("键---"+key)
print("值---"+str(value))
结果演示:
键---name
值---码上开始
键---age
值---22
函数
- 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
- 函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
定义一个函数
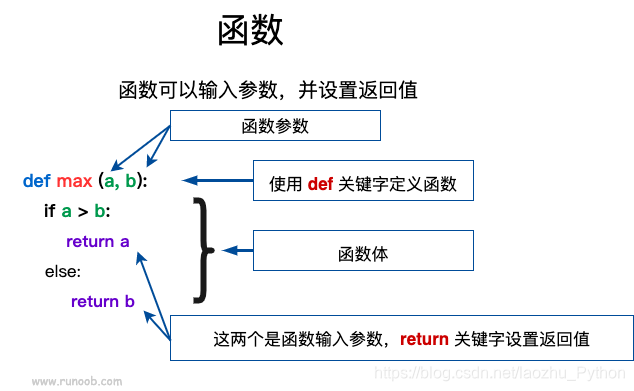
你可以定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
#! /usr/bin/python3
# @Author : 码上开始
def example():
'''
一个简单的函数
'''
print("Hello World !")
example()
打印结果:
Hello World !
三引号中间的内容属于函数的注释文档,注释的作用是告诉别人或以后查看代码知道能快速知道这段干嘛是做什么的。
函数还可以嵌套,也就是函数里面有函数
#! /usr/bin/python3
# @Author : 码上开始
def exapmle(name):
def go(name):
print('我最棒:' + name)
go(name)
example('小明')
打印结果:
我最棒:小明
函数的参数
形参和实参
#! /usr/bin/python3
# @Author : 码上开始
def example(username):
print("Hello World ! My name is " + str(username))
example("小明")
example("小花")
打印结果:
Hello World ! My name is 小明
Hello World ! My name is 小花
这是一个带参数的函数,在函数example中,username就是一个形参,也就是形式参数,是用来接收调用函数时传入的参数,你传的是啥它就是啥,传人它就是人,传鬼它就是鬼的那种。
实参就是实际参数,在调用函数的时候,传递是小明,那么小明就是实参,传递的是小花,那么小花也是实参,实参传递给函数后,会赋值给函数中的形参,然后我们就可以在函数中使用到外部传入的数据了。
参数默认值
写Java的时候最痛恨的就是方法不能设置默认值,使得必须得重载才行。
python允许我们给函数的形参设置一个默认值,不传参数调用的话,就统一默认是这个值。
#! /usr/bin/python3
# @Author : 码上开始
def welcome(username = '奥特曼'):
print("Hello World ! My name is " + str(username))
welcome("小明")
welcome()
打印结果:
Hello World ! My name is 小明
Hello World ! My name is 奥特曼
修改参数后影响外部
在函数中修改参数内容会不会影响到外部,这个问题取决于实参的类型是不是可变的,可不可变就是可不可以修改。
字符串就是一种不可变的类型。
比如:
name = "小明"
name = "小花"
请问,我是把"小明"修改成了"小花"吗? 答案是 非也。
实际上我是把"小花"这个字符串赋值给了name,让name指向了这个新字符串,替换掉了原来的"小明",原来的"小明"仍然是"小明",没有受到一点改变。
在python中,不可变类型有:整数、字符串、元组,可变类型有:列表、字典。如果传递的参数包含可变类型,并且在函数中对参数进行了修改,那么就会影响到外部的值。
#! /usr/bin/python3
# @Author : 码上开始
def change(lis):
lis[1] = '小明他二舅'
names = ['小明','小花','小红']
change(names)
print(names)
打印结果:
['小明', '小明他二舅', '小红']
如果我们不希望出现这种事情,那么就将对象复制一份再传递给函数。
#! /usr/bin/python3
# @Author : 码上开始
def change(lis):
lis[1] = '小明他大爷'
names = ['小明','小花','小红']
change(names[:])
print(names)
打印结果:['小明', '小花', '小红']
我们用切片的方法拷贝了一份names,函数中尽管修改了参数,也不过是修改的是副本,不会影响到原始的names。
关键字参数
关键字参数让你可以不用考虑函数的参数位置,你需以键值对的形式指定参数的对应形参。
#! /usr/bin/python3
# @Author : 码上开始
def welcome(name,address):
print(f"你好 {name} , 欢迎来到 {address} !")
welcome(address='长沙',name='小强')
打印结果:你好 小强 , 欢迎来到 长沙 !
收集参数
有时候我们需要允许用户提供任意数量的参数,函数的形参可以带个星号来接收,不管调用函数的时候传递了多少实参,都将被收集到形参这个变量当中,形参的类型是元组。
#! /usr/bin/python3
# @Author : 码上开始
def welcome(*names):
print(names)
welcome('乐迪','天天','酷飞','小黑')
打印结果:('乐迪', '天天', '酷飞', '小黑')
还有一种是带两个星号的形参,用于接收键值对形式的实参,导入到函数中的类型是字典。
#! /usr/bin/python3
# @Author : 码上开始
def welcome(**names):
print(names)
welcome(name='小明',age=20,sex='男')
打印结果:{'name': '小明', 'age': 20, 'sex': '男'}
分配参数
分配参数是收集参数的相反操作,可使得一个元组或字典变量自动分配给函数中的形参。
#! /usr/bin/python3
# @Author : 码上开始
def welcome(name,address):
print(f"你好 {name} , 欢迎来到 {address} !")
a = ('小明','广州')
welcome(*a)
打印结果:你好 小明 , 欢迎来到 广州 !
我们改成字典的方式:
#! /usr/bin/python3
# @Author : 码上开始
def welcome(name,address):
print(f"你好 {name} , 欢迎来到 {address} !")
a = {'address':'山东','name':'小红'}
welcome(**a)
打印结果:你好 小红 , 欢迎来到 山东 !
函数的返回值
首先说明,所有的函数都是有返回值的,如果编程人员没有指定返回值,那么默认会返回None,对标其他语言中的null。
一个简单的函数返回值的例子:
#! /usr/bin/python3
# @Author : 码上开始
def get_full_name(first_name,last_name):
return first_name + last_name
r = get_full_name('王','大拿')
print(r)
打印结果:王大拿
然而python中的函数还可以返回多个值,返回出的值被装载到元组中:
#! /usr/bin/python3
# @Author : 码上开始
def func(num):
return num**2,num**3,num**4
result = func(2)
print(result)
打印结果:(4, 8, 16)
在python中函数定义的时候没有返回值的签名,导致我们无法提前知道函数的返回值是什么类型,返回的什么完全看函数中的return的是什么,特别是逻辑代码比较多的函数,比如里面有多个if判断,有可能这个判断return出来的是布尔值,另一个判断return出来的是列表,还一个判断啥也不return,你调用的时候你都搞不清楚该怎么处理这个函数的返回值,在这一点来说,Java完胜。
所以在无规则限制的情况下,代码写的健不健壮,好不好用,主要取决于编程人员的素质。
匿名函数
匿名函数就是不用走正常函数定义的流程,可以直接定义一个简单的函数并把函数本身赋值给一个变量,使得这个变量可以像函数一样被调用,在python中可以用lambda关键字来申明定义一个匿名函数。
我们把王大锤的例子改一下:
# -*- coding: utf-8 -*-
# @Author : 一凡
get_full_name = lambda first_name,last_name : first_name + last_name
r = get_full_name('王','大锤')
print(r)
打印结果:王大锤
函数的作用域
访问全局作用域
python每调用一个函数,都会创建一个新命名空间,也就是局部命名空间,函数中的变量就叫做局部变量,与外部的全局命名空间不会相互干扰。
这是常规状态,当然也会有非常规需求的时候,所以python给我们提供了globals()函数,让我们可以在局部作用域中访问到全局的变量。
#! /usr/bin/python3
# @Author : 码上开始
def func():
a = globals()
print(a['name'])
name = '小明'
func()
打印结果:小明
globals()函数只能让我们访问到全局变量,但是是无法进行修改的,如果我们要修改全局变量,需要用到global关键字将全局变量引入进来。
#! /usr/bin/python3
# @Author : 码上开始
def func():
global name
name = '小花'
name = '小明'
func()
print(name)
打印结果:小花
面向对像
类

类顾名思义,就是一类事物、或者叫做实例,它用来描述具有共同特征的一类事物
我们在Python中声明类的关键词是class,类还有功能和属性,属性就是这类事物的特征,而功能就是它能做什么,也是就是方法或者函数
比如把人为一类,人的名字,年龄,身高,肤色是属性,人可以跑,跳这种为方法
定义类:
class 类名(object):
def function1(self):
pass
def function2(self):
pass
.....
构造方法:_init_
- 类中的函数称为方法;你前面学到的有关函数的一切都适用于方法,就目前而言,唯一重要的差别是调用方法的方式。
- _init_ 是一个特殊的方法(注:两边为双下划线),每当你根据类创建新实例时,Python都会自动运行它。如何理解呢?
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Test():
def __init__(self):
print("我是构造方法, 实例化对像后就会自动调用")
def test01(self):
print("该方法没有执行")
test = Test()
# 运行结果
我是构造方法, 实例化对像后就会自动调用
给属性指定默认值
- 类中的每个属性都必须有初始值,哪怕这个值是0或空字符串
- 假设购买手机预算3500
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def money(self):
print("手机价格是:", self.phone_money)
# 实例化对像
test = Phone()
test.money()
# 运行结果
手机价格是: 3500
直接修改属性值
我提高了手机购买预算,价格为6000,通过直接修改默认价格的方法修改
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def money(self):
print("手机价格是:", self.phone_money)
# 实例化对像
test = Phone()
# 直接修改价格--对像名.属性名
test.phone_money= 6500
test.money()
通过方法修改属性
- 当然也可以通过修改方法方法,将money作为参数传入,修改属性的值
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Phone(object):
def money(self, m):
self.mobile_money = m
print("手机价格是:", self.mobile_money)
# 实例化对像
test = Phone()
test.money(5000)
test.money(6000)
# 运行结果
手机价格是: 5000
手机价格是: 6000
通过方法对属性的值进行递增
- 手机预算价格为3500,但我想买个更好的手机,预算价格提高2500
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Phone(object):
def __init__(self):
self.phone_money = 3500
def update(self,money):
self.phone_money += money
print("手机价格是:", self.phone_money)
# 实例化对像
test = Phone()
test.update(2500)
# 运行结果
手机价格是:6000
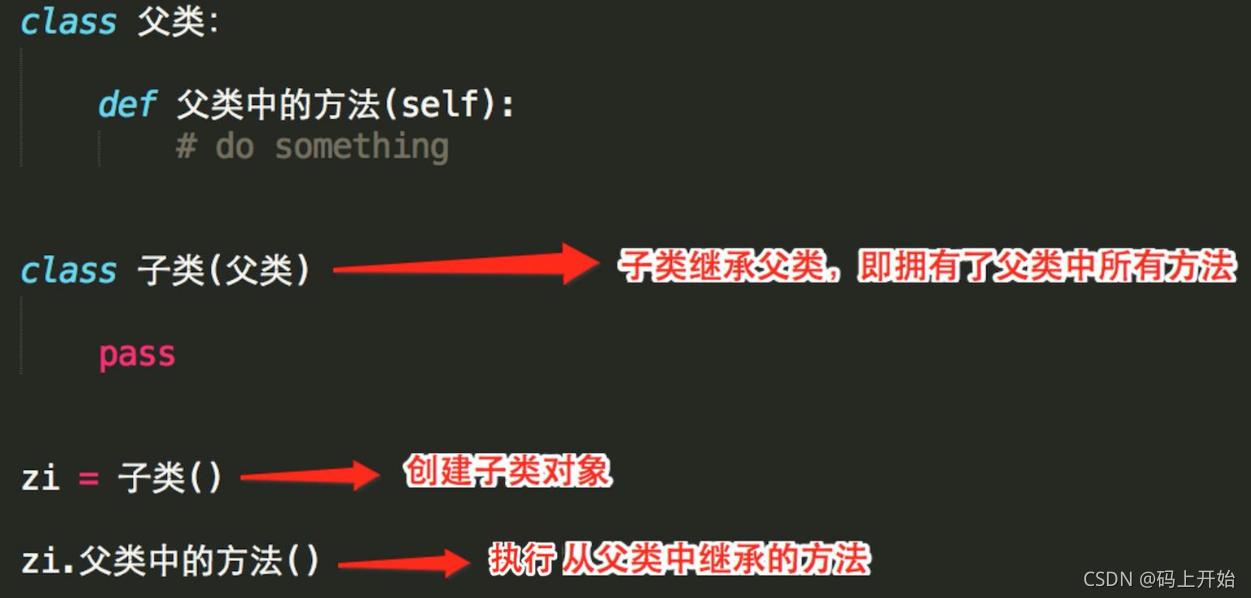
类的继承
- 继承特性:子类继承父类后,自动拥有了父类里的方法
- 可以只继承一个父类,也可以继承多个父类
- 比如:以前的非智能手机为父类,现在的是智能手机是子类
- 智能手机拥有非智能机的通话功能和发短信等功能,这就是继承
- 继承后就可以调用父类里的方法
实例:
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Mobile:
'''创建父类手机'''
def call(self):
print("可以拨打电话")
# 创建智能手机子类,且继承父类
class Smartphone(Mobile):
'''创建智能手机子类'''
pass
# 子类实例
phone = Smartphone()
# 子类调用父类方法
phone.call()
类方法重写
子类和父类中拥有方法名相同的方法,说明子类重写了父类的方法
重写的作用:父类中已经有了这个方法,但子类想修改里面的内容,直接修改父类是不好的,就需要用到重写
实例:
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Mobile:
'''创建父类手机'''
def call(self):
print("可以拨打电话")
# 创建智能手机子类,且继承父类
class Smartphone(Mobile):
'''创建智能手机子类'''
def call(self):
print("不仅可以打电话,还能发送微信语音")
# 子类实例
phone = Smartphone()
# 调用自己方法,重写父类call方法
phone.call()
多继承
- 多继承可以让子类对象,同时具有多个父类的属性和方法
# -*- coding: utf-8 -*-
# @Author : 码上开始
class Mobile:
'''创建父类手机'''
def call(self):
print("可以拨打电话")
class Music():
movie = "可以看电影"
def music(self):
print("可以播放音乐")
# 继承了多个父类
class Smartphone(Mobile, Music):
pass
# 子类实例
phone = Smartphone()
# 调用父类方法
phone.call()
phone.music()
# 调用类中属性
print(phone.movie)
继承构造方法
- 子类自动调用父类的构造方法
class Father():
def __init__(self):
print("自动调用父类构造方法")
def hello(self):
print("hello, 码上开始")
class Son(Father):
pass
son = Son()
son.hello()
多态
以封装和继承为前提,不同的子类对像调用相同的方法,产生不同的执行结果
在定义变量时,不需要提前指定数据类型,变量的数据类会根据你赋值的数据来决定
a= 1当前为整数类型
a="hello"当前为字符串类型
# @Time : 2021/1/9 16:11
# @Author : 码上开始
class WeChatPay():
def payfor(self):
print("微信支付")
class ALiPay():
def payfor(self):
print("支付宝支付")
class StartPay():
def start(self, pay_method):
pay_method.payfor()
wx = WeChatPay()
zfb = ALiPay()
zf = StartPay()
# 传入微信实例对像
zf.start(wx)
# 传入支付宝实例对像
zf.start(zfb)
异常处理

- 本文实例分析了Python中的异常处理try/except/finally/raise用法。分享给大家供大家参考,具体如下:
- 异常发生在程序执行的过程中,如果python无法正常处理程序就会发生异常,导致整个程序终止执行,python中使用try/except语句可以捕获异常。
try/except
- 异常的种类有很多,在不确定可能发生的异常类型时可以使用Exception捕获所有异常:
try:
pass
except Exception as e:
print(e)
try/except/else
- 在try语句后也可以跟一个else语句,这样当try语句块正常执行没有发生异常,则将执行else语句后的内容:
try:
pass
except Exception as e:
print("No exception")
else:
print("我打印的是else")
try/Except/finally
- 在try语句后边跟一个finally语句,则不管try语句块有没有发生异常,都会在执行try之后执行finally语句后的内容:
try:
pass
except Exception as e:
print("Exception: ", e)
finally:
print("try is done")
raise抛出异常
使用raise来抛出一个异常:
a = 0
if a == 0:
raise Exception("a must not be zero")
最好指出异常的具体类型,如:
a = 0
if a == 0:
raise ZeroDivisionError(``"a must not be zero"``)
日志模块
python中的logging模块用于记录日志。用户可以根据程序实现需要自定义日志输出位置、日志级别以及日志格式。
将日志内容输出到屏幕
一个最简单的logging模块使用样例,直接打印显示日志内容到屏幕。
import logging
logging.critical("critical log")
logging.error("error log")
logging.warning("warning log")
logging.info("info log")
logging.debug("debug log")
输出结果如下:
CRITICAL:root:critical log
ERROR:root:error log
WARNING:root:warning log
说明:默认情况下python的logging模块将日志打印到标准输出,并且只显示大于等于warning级别的日志(critical > error > warning > info > debug)。
将日志内容输出到文件
将日志事件记录到文件是一种非常常见的情况,方便出现问题时快速定位问题。在logging模块默认配置条件下,记录日志内容,代码如下:
import logging
logging.basicConfig(filename='example.log',level=logging.DEBUG)
logging.debug('This message should go to the log file')
logging.info('So should this')
logging.warning('And this, too')
输出结果如下:
D:\pycharm\work>type example.log
DEBUG:root:This message should go to the log file
INFO:root:So should this
WARNING:root:And this, too
说明:type为dos窗口下查看文件内容命令
定制日志内容(日志级别、日志格式)
根据程序运行对日志记录的要求,通常需要自定义日志显示格式、输出位置以及日志显示级别。可以通过logging.basicConfig()定制满足自己要求的日志输出格式。
import logging
logging.basicConfig(format='[%(asctime)s %(filename)s line:%(lineno)d] %(levelname)s: %(message)s',
level=logging.DEBUG, filename="log.txt", filemode="w")
logging.debug('This message should appear on the console')
logging.info('So should this')
logging.warning('And this, too')
输出结果如下:
```python
D:\pycharm\work>type log.txt
[2020-02-02 10:31:42,994 json_pro.py line:5] DEBUG: This message should appear on the console
[2020-02-02 10:31:42,995 json_pro.py line:6] INFO: So should this
[2020-02-02 10:31:42,995 json_pro.py line:7] WARNING: And this, too
通过修改logging.basicConfig()函数中参数取值来定制日志显示。函数参数定义及含义如下:
filename 指定日志写入文件名。
filemode 文件打开方式,默认值为"a"
format 设置日志显示格式
dateft 设置日期时间格式
level 设置显示日志级别
stream 指定stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件。默认为sys.stderr。
format参数用到的格式化字符串如下:
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(filename)s 调用日志输出函数的模块的文件名
%(levelname)s 文本形式的日志级别
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(message)s 用户输出的消息
%(module)s 调用日志输出函数的模块名
多模块记录日志
如果开发的程序包含多个模块,就需要考虑日志间的记录方式。基本样例如下:
主程序文件:
import logging
import mylib
def main():
logging.basicConfig(format='[%(asctime)s %(filename)s line:%(lineno)d] %(levelname)s: %(message)s',
level=logging.DEBUG, filename="log.txt", filemode="w")
logging.info('Started')
mylib.do_something()
logging.info('Finished')
if __name__ == '__main__':
main()
日志同时输出屏幕和写入文件
logging模块可以通过FileHander和StreamHandler分别制定向文件和屏幕输出。
import logging
logger = logging.getLogger() # 不加名称设置root logger
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s: - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S')
# 使用FileHandler输出到文件
fh = logging.FileHandler('log.txt')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# 使用StreamHandler输出到屏幕
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# 添加两个Handler
logger.addHandler(ch)
logger.addHandler(fh)
logger.info('this is info message')
logger.warning('this is warn message')
控制台输出如下:
[2020-02-02 10:58:16 json_pro.py line:22] INFO: this is info message
[2020-02-02 10:58:16 json_pro.py line:23] WARNING: this is warn message
日志文件内容如下:
D:\pycharm\work>type log.txt
[2020-02-02 10:58:55 json_pro.py line:22] INFO: this is info message
[2020-02-02 10:58:55 json_pro.py line:23] WARNING: this is warn message
datatime模块
当我们在Python中需要使用到时间的时候,有两个关于时间的模块,分别是time和datetime。time模块偏底层,在部分函数运行的时候可能会出现不同的结果,而datetime模块提供了高级API,使用起来更为方便,我们通常在使用的时候会涉及到包含时间和日期的datetime、只包含日期的date以及只包含时间的time,本节我们就对这三种方法进行学习。
datetime的使用方法为:
datetime.dateto,e(year, month, day, hour``=``0``, minute``=``0``, second``=``0``, microsecond``=``0``, tzinfo``=``None``, ``*``, fold``=``0``)
其中year,month和day是不能缺少的,tzinfo为时区参数,可以为None或其他参数,其余参数的范围如下:
MINYEAR <= year <= MAXYEAR,
1 <= month <= 12,
1 <= day <= number of days in the given month and year,
0 <= hour < 24,
0 <= minute < 60,
0 <= second < 60,
0 <= microsecond < 1000000,
fold in [0, 1].
下面讲几种常用的方法
- datetime.datetime.now()
返回当前的日期和时间
代码如下:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
# 返回当前日期及时间
now_time = datetime.datetime.now()
print(now_time)
输出结果为:
2020``-``02``-``01` `19``:``18``:``59.926474
- date()
返回当前时间的日期
代码如下:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
#返回当前日期及时间``
now_time= datetime.datetime.now()
#输出当前的日期
print(now_time.date())
输出结果:
2020``-``02``-``01
- time()
返回当前的时间对象
代码如下:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
#返回当前日期及时间
now_time = datetime.datetime.now()
#输出当前的时间
print(now.time())
输出结果为:
19``:``22``:``10.948940
date
date对象是日期的专属对象,语法格式如下:
datetime.date(year,month,day),参数分别代表年月日。
date类中的常用功能有2种:
- datetime.date.today()
这种用法直接返回了当前的日期,代码如下:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
#返回当前日期
now_time = datetime.date.today()
print(now_time)
输出结果为:
2020``-``02``-``01
- datetime.date.fromtimestamp()
这种方式返回与时间戳对应的日期,代码如下:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
import time
c = time.time()
#返回当前的时间戳
print('当前的时间戳为:' ,c)
now_time = datetime.date.fromtimestamp(c)
#与时间戳对应的日期
print('当前时间戳对应的日期为:', now_time)
输出结果为:
当前的时间戳为: ``1580556848.3161435``当前时间戳对应的日期为: ``2020``-``02``-``01
在这个例题中我们先引入了time模块中的方法,time模块中的time.time()能返回当前时间戳,然后我们使用上面的方法可以返回与时间戳对应的日期。
time
time类中包含了一整天的信息,语法结构如下:
datetime.time(hour,moniute,second,microsecond,tzinfo``=``None``)
最后一个时区可以省略,看下面例子:
#! /usr/bin/python3
# @公众号 : 码上开始
import datetime
now_time = datetime.time(19, 42, 34, 12)
print(now_time)
输出结果为:
19:42:34.000012
总结
由于datetime模块中封装了time模块,所以我们使用datetime模块可以保证数据更为精确,在使用过程中也可以穿插着time模块中的部分功能,例如暂停time.sleep()等方法。
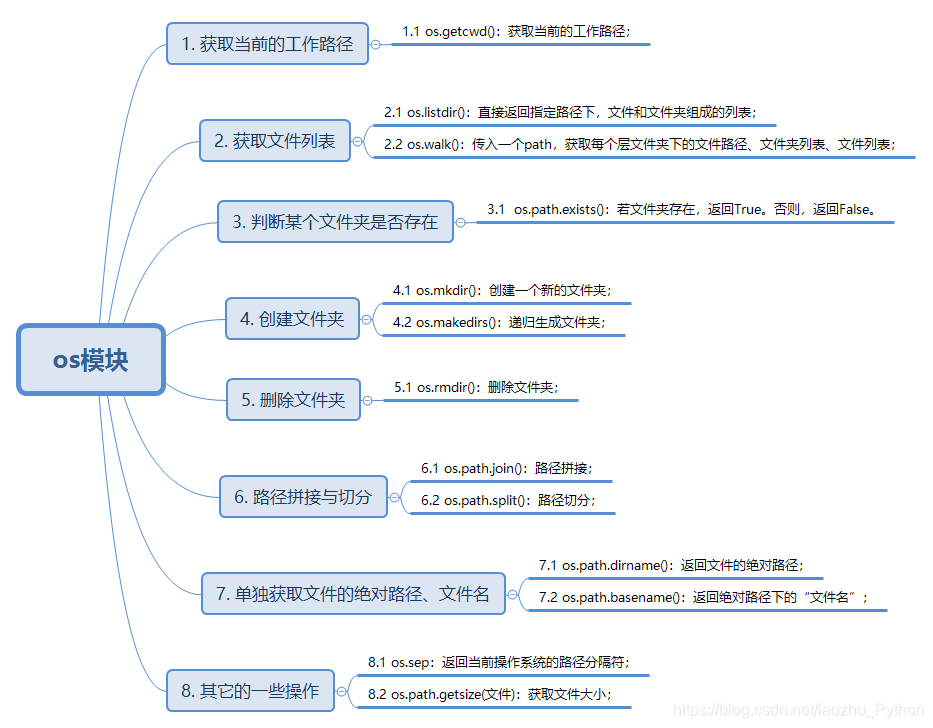
OS文件目录操作
- 为什么要学习os模块?
做为一名优秀的软件测试工程师,我们是要编写大量的python自动化代码和生成测试报告,我们需要访问和处理文件。如何能方便快捷的处理这些文件呢? - 能处理工作中什么样的问题?
在自动化测试中,经常需要查找操作文件,比如说查找配置文件(从而读取配置文件的信息),查找测试报告(从而发送测试报告邮件),经常要对大量文件和大量路径进行操作,这就依赖于os模块,所以今天整理下比较常用的几个方法。
os.getcwd()
- 得到当前工作目录,即当前python脚本目录路径
#! /usr/bin/python3
# @Author : 码上开始
import os
# 查看当前路径文件路径
print(os.getcwd())
# 运行结果
E:\study
os.listdir(path)
- 返回指定目录下的所有文 件和目录名
#! /usr/bin/python3
# @Author : 码上开始
import os
# 当前路径有哪些文件,返回的路径有哪些文件
print(os.listdir(os.getcwd()))
# 运行结果
['day1.py', 'day2.py', 'day3.py', 'day4.py', 'day5.py']
os.mkdir(path)
- Python的
mkdir()方法使用数字模式模式创建一个名为path的目录。默认模式为0777(八进制)
#! /usr/bin/python3
# @Author : 码上开始
import os
os.mkdir("E:/study/hello")
os.rmdir(path)
- 删除目录(删除path指定的空目录,如果目录非空,则抛出一个OSError异常。)
#! /usr/bin/python3
# @Author : 码上开始
import os
os.rmdir("E:/study/hello")
os.remove(path)
- 用于删除指定路径的文件。如果指定的路径是一个目录,将抛出OSError。
#! /usr/bin/python3
# @Author : 码上开始
import os
os.rmdir("E:/study/hello/day6.py")
os.path模块
os.path.dirname(path)
- 去掉文件名,返回目录返回文件路径
#! /usr/bin/python3
# @Author : 码上开始
import os
print(os.path.dirname("E:/study/day5.py"))
#运行结果
E:/study
os.path.join(path, name)
- 连接目录与文件名和目录(只是起到连接作用,不会生成这个文件)
#! /usr/bin/python3
# @Author : 码上开始
import os
print(os.path.join("E:/study/", 'day6.py'))
#运行结果
E:/study/day6.py
os.path.split(path)
- 返回目录名和文件名(返回结果为一个元组)
#! /usr/bin/python3
# @Author : 码上开始
import os
print(os.path.split("E:\study\day4.py"))
# 运行结果
('E:\\study', 'day4.py')
os.path.splitext(path)
- 分割路径,返回路径名和文件扩展名的元组(返回结果为一个元组)
#! /usr/bin/python3
# @Author : 码上开始
import os
print(os.path.splitext("E:\study\day4.py"))
# 运行结果
('E:\\study\\day4', '.py')
os.path.getmtime()
- 返回文件的最近修改时间(单位为秒)
- 该用法用于查找最新测试报告
#! /usr/bin/python3
# @Author : 码上开始
import os
print(os.path.getmtime("E:/study/old.html"))
print(os.path.getmtime("E:/study/new.html"))
# 运行结果
1597062314.1353853
1597062332.269248
random随机数
- 模块是python自带模块,用于生成随机数。软件测试中使用场景可生成随机手机号用于测试工作中。
模块常用方法
- random()函数,生成0到1的随机小数
#! /usr/bin/python3
# @Author : 码上开始
import random
num = random.random()
print(num)
# 运行结果
0.5234072981721078
- uniform(a,b)生成a到b的随机小数
#! /usr/bin/python3
# @Author : 码上开始
import random
num = random.uniform(1, 10)
print(num)
#运行结果
2.1220664313759947
- randint(a, b)生成一个a到b的随即整数
#! /usr/bin/python3
# @Author : 码上开始
import random
num = random.randint(1, 10)
print(num)
# 运行结果
6
- choice() 随机返回一个列表里面的元素
#! /usr/bin/python3
# @Author : 码上开始
import random
num = random.choice(["135", "138", "186"])
print(num)
# 运行结果
135
- shuffle()将列表的元素随机打乱
#! /usr/bin/python3
# @Author : 码上开始
import random
list = [1, 2, 3, 4]
random.shuffle(list)
print("随机排序列表 : ", list)
random.shuffle(list)
print("随机排序列表 : ", list)
# 运行结果
随机排序列表 : [2, 4, 1, 3]
随机排序列表 : [3, 1, 2, 4]
- sample(, k)从列表中随机抽取k个元素
#! /usr/bin/python3
# @Author : 码上开始
import random
num = random.sample(["135", "138", "186"], 2)
print(num)
# 运行结果
['186', '135']
有趣好玩的伪装者模块:Faker
在软件需求、开发、测试过程中,有时候需要使用一些测试数据,针对这种情况,我们一般要么使用已有的系统数据,要么需要手动制造一些数据。
在手动制造数据的过程中,可能需要花费大量精力和工作量,现在好了,有一个Python包能够协助你完成这方面的工作。
1.什么是Faker
Faker是一个Python包,开源的GITHUB项目,主要用来创建伪数据,使用Faker包,无需再手动生成或者手写随机数来生成数据,只需要调用Faker提供的方法,即可完成数据的生成。
项目地址:https://github.com/joke2k/faker
安装
pip install Faker
如果下载速度比较慢的话,可以使用国内镜像源来下载
国内源:
例如:pip3 install -i https://pypi.doubanio.com/simple/ faker
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 阿里云:http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 华中理工大学:http://pypi.hustunique.com/
- 山东理工大学:http://pypi.sdutlinux.org/
- 豆瓣:http://pypi.douban.com/simple/
基本使用
from faker import Faker
#创建对象,默认生成的数据为为英文,使用zh_CN指定为中文
fake = Faker('zh_CN')
print(fake.name())#随机生成姓名
print(fake.address())#随机生成地址
print(fake.phone_number())#随机生成电话号码
print(fake.pystr())#随机生成字符串
print(fake.email())#随机生成邮箱地址
for i in range(10):
print(fake.name())#随机生成10个姓名
输出:
徐博
云南省玉市璧山梧州路p座 523028
13039830591
RPHadhNxNMISoBTbQbQn
yili@taogang.net
张淑英
叶燕
陈琳
王俊
胡秀荣
阮淑英
徐娟
黄冬梅
梁丽华
袁琴
常用方法
地理信息类
- city_suffix():市,县
- country():国家
- country_code():国家编码
- district():区
- geo_coordinate():地理坐标
- latitude():地理坐标(纬度)
- longitude():地理坐标(经度)
- postcode():邮编
- province():省份
- address():详细地址
- street_address():街道地址
- street_name():街道名
- street_suffix():街、路
基础信息类
- ssn():生成身份证号
- bs():随机公司服务名
- company():随机公司名(长)
- company_prefix():随机公司名(短)
- company_suffix():公司性质,如‘信息有限公司’
- fake.credit_card_expire(start=‘now’, end=’+10y’, date_format=’%m/%y’):- - 随机信用卡到期日如’03/30’
- credit_card_full():生成完整信用卡信息
- credit_card_number():信用卡号
- credit_card_provider():信用卡类型
- credit_card_security_code():信用卡安全码
- job():随机职位
- first_name_female():女性名
- first_name_male():男性名
- name():随机生成全名
- name_female():男性全名
- name_male():女性全名
- phone_number():随机生成手机号
- phonenumber_prefix():随机生成手机号段,如139
邮箱信息类
- ascii_company_email():随机ASCII公司邮箱名
- ascii_email():随机ASCII邮箱:
- company_email():
- email():
- safe_email():安全邮箱
网络基础信息类
- domain_name():生成域名
- domain_word():域词(即,不包含后缀)
- ipv4():随机IP4地址
- ipv6():随机IP6地址
- mac_address():随机MAC地址
- tld():网址域名后缀(.com,.net.cn,等等,不包括.)
- uri():随机URI地址
- uri_extension():网址文件后缀
- uri_page():网址文件(不包含后缀)
- uri_path():网址文件路径(不包含文件名)
- url():随机URL地址
- user_name():随机用户名
- image_url():随机URL地址
浏览器信息类
- chrome():随机生成Chrome的浏览器user_agent信息
- firefox():随机生成FireFox的浏览器user_agent信息
- internet_explorer():随机生成IE的浏览器- user_agent信息
- opera():随机生成Opera的浏览器user_agent信息
- safari():随机生成Safari的浏览器user_agent信息
- linux_platform_token():随机Linux信息
- user_agent():随机user_agent信息
数字信息
- numerify():三位随机数字
- random_digit():0~9随机数
- random_digit_not_null():1~9的随机数
- random_int():随机数字,默认0~9999,可以通过设置min,max来设置
- random_number():随机数字,参数digits设置生成的数字位数
- pyfloat():left_digits=5 #生成的整数位数, right_digits=2 #生成的小数位数, - - positive=True #是否只有正数
- pyint():随机Int数字(参考random_int()参数)
- pydecimal():随机Decimal数字(参考pyfloat参数)
文本加密类
- pystr():随机字符串
- random_element():随机字母
- random_letter():随机字母
- paragraph():随机生成一个段落
- paragraphs():随机生成多个段落
- sentence():随机生成一句话
- sentences():随机生成多句话,与段落类似
- text():随机生成一篇文章
- word():随机生成词语
- words():随机生成多个词语,用法与段落,句子,类似
- binary():随机生成二进制编码
- boolean():True/False
- language_code():随机生成两位语言编码
- locale():随机生成语言/国际 信息
- md5():随机生成MD5
- null_boolean():NULL/True/False
- password():随机生成密码,可选参数:length:密码长度;special_chars:是否能使用特殊字符;- - digits:是否包含数字;upper_case:是否包含大写字母;lower_case:是否包含小写字母
- sha1():随机SHA1
- sha256():随机SHA256
- uuid4():随机UUID
时间信息类
- date():随机日期
- date_between():随机生成指定范围内日期,参数:start_date,end_date
- date_between_dates():随机生成指定范围内日期,用法同上
- date_object():随机生产从1970-1-1到指定日期的随机日期。
- date_time():随机生成指定时间(1970年1月1日至今)
- date_time_ad():生成公元1年到现在的随机时间
- date_time_between():用法同dates
- future_date():未来日期
- future_datetime():未来时间
- month():随机月份
- month_name():随机月份(英文)
- past_date():随机生成已经过去的日期
- past_datetime():随机生成已经过去的时间
- time():随机24小时时间
- timedelta():随机获取时间差
- time_object():随机24小时时间,time对象
- time_series():随机TimeSeries对象
- timezone():随机时区
- unix_time():随机Unix时间
- year():随机年份
发送邮箱件模块
- 发送邮件,我们在平时工作中经用到,做为测试人员,在自动化测试中用的也比较多,需要发送邮件给某领导
- SMTP是Python默认的邮件模块,可以发送纯文本、富文本、HTML 等格式的邮件
发送邮件步骤

邮件发送前的准备工作
- 开启邮箱SMTP服务和获取授权码
- 登录 QQ 邮箱为例,我们需要开启 SMTP 服务,登录邮箱依次点击设置-账户
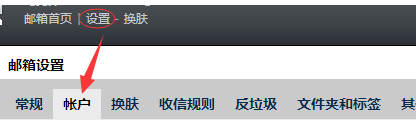
开启SMTP

生成授权码
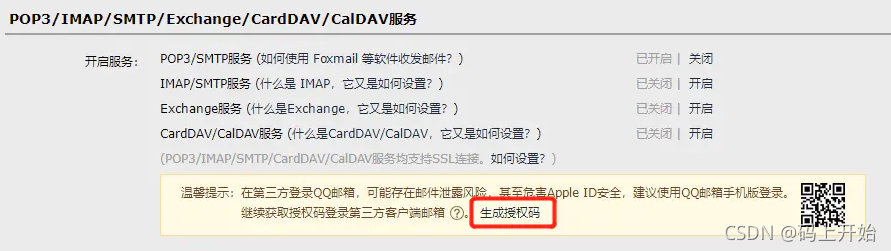
注:
需要开启POP3/SMTP服务
授权码做为邮箱密码
方式一:smtplib(不推荐使用)
- smtplib是 Python 自带的依赖库,可以直接导入使用,通过邮箱账号、授权码、邮箱服务器地址初始化一个 SMTP 实例,然后进行连接,初学者感觉这个会挺复杂,请继续往下看
方式二:zmail
由于SMPT太过于麻烦复杂,所以就用zamil发送邮件试试。
zmail模块只支持Python3模块,该模块为第3方模块,需自行安装(pip install zmail)
使用 Zmail 发送接收邮件方便快捷,不需手动添加服务器地址、端口以及适合的协议,可以轻松创建 MIME 对象和头文件
注意:Zmail 仅支持 Python3,不支持 Python2
#!/usr/bin/python3
import zmail
def send_mail():
# 定义邮件
mail = {"subject": "接口测试报告",# 任一填写
'content_text': '手机号归属地_API自动化测试报告',# 任一填写
# 多个附件使用列表
"attachments": "E:/report/result.html"
}
# 自定义服务器
server = zmail.server("发送人邮箱.com",
"QQ邮箱是用授权码",
smtp_host="smtp.qq.com",
smtp_port = 465)
# 发送邮件
server.send_mail("收件人QQ邮箱", mail)
try:
send_mail()
except FileNotFoundError:
print("未找到文件")
else:
print("发送成功")
方式三:yagmail
他们都说yagmail 只需要三行代码,就可以实现发送邮件,爽歪歪!
相比 zmail,yagmail 实现发送邮件的方式更加简洁优雅
首先,安装依赖库(pip install yagmail)
发送邮件有三个步骤:
1、连接服器(类似你先要登录邮箱)
2、编辑邮件内容和主题
3、发送邮件
#!/usr/bin/python3
import yagmail
# 定义用户名、授权码、服务器地址且连接服务器
mail_server = yagmail.SMTP(user='发件人邮箱', passwd='授权码', host='smtp.qq.com')
# 发送对象列表
Email_to = ['收件人邮箱']
subject = '任一填写'
Email_text = "任一填写内容"
# 多个附件用逗号隔开
attachments = ['html报告目录地址']
# 发送邮件
mail_server.send(Email_to, subject, Email_text, attachments)
POM设计模型
Page Object Model (POM) 直译为“页面对象模型”,这种设计模式旨在为每个待测试的页面创建一个页面对象(class),将那些繁琐的定位操作封装到这个页面对象中,只对外提供必要的操作接口,是一种封装思想。
POM优势有哪些
- 让UI自动化更早介入项目中,可项目开发完再进行元素定位的适配与调试
- POM 将页面元素定位和业务操作流程分开,分离了测试对象和测试脚本
- 如果UI页面元素更改,测试脚本不需要更改,只需要更改页面对象中的某些代码就可以
- POM能让我们的测试代码变得可读性更好,高可维护性,高复用性
- 可多人共同维护开发脚本,利于团队协作
为什么使用POM设计模式
- 少数的自动化测试用例维护起来看起来是很容易的。但随着时间的迁移,测试套件将持续的增长。脚本也将变得越来越臃肿庞大。
- 如果变成我们需要维护10个页面,100个页面,甚至1000个呢?而且页面元素很多是公用的。那页面元素的任何改变都会让我们的脚本维护变得繁琐复杂,而且变得耗时易出错。
如何设计POM
思路解析
- 需要一个文件用于管理页面元素,如login_page.py
- 封装一个公用的操作方法
- 最后需要一个文件用于编写测试用例
login_page.py文件
- 该文件用于管理登录页面所有的元素,操作这些元素的方法
#! /usr/bin/python3
#-*- coding:utf-8 -*-
'''管理登录页面所有的元素,操作这些元素的方法'''
from selenium.webdriver.common.by import By
class LoginPage:
username_input = (By.XPATH,'//*[@id="name"]') #登录页面的用户名输入框
password_input = (By.XPATH,'//*[@id="password"]') #登录页面的密码输入框
login_button = (By.XPATH,'//*[@id="submit"]') #登录按钮
common.py
- 该文件有用于封装一些共用的操作方法
#! /usr/bin/python3
#-*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
'''封装一些常用公共方法'''
class InitBrowser():
'''浏览器常用操作封装'''
def __init__(self):
self.driver = webdriver.Firefox() # 启动谷歌浏览器
self.driver.get('https://sso.kuaidi100.com/sso/authorize.do') # 打开网站
def wait_element_visible(self, locate):
ele = WebDriverWait(self.driver, 10).until(EC.visibility_of_element_located(locate)) #等待元素出现再去操作
print('等待元素出现')
return ele
def click_until_visible(self, locate):
self.wait_element_visible(locate).click()
def send_keys_until_visible(self, locate, value):
self.wait_element_visible(locate).send_keys(value)
TestCase.py
- 该文件用于管理测试用例
#! /usr/bin/python3
#-*- coding:utf-8 -*-
'''管理测试用例'''
import unittest
from common import InitBrowser
# 导入Pages文件下的login_page文件中的LoginPage类
from Pages.login_page import LoginPage
class TestCases(unittest.TestCase, InitBrowser, LoginPage):
def setUp(self) -> None:
'''前置操作初始化:打开浏览器,连接数据库,初始化数据'''
InitBrowser.__init__(self)
def testcase01(self):
'''测试用例'''
self.send_keys_until_visible(LoginPage.username_input, "账号")
self.send_keys_until_visible(LoginPage.password_input, "密码")
self.click_until_visible(LoginPage.login_button)
def tearDown(self) -> None:
'''后置操作:关闭浏览器,关闭数据库连接,清理测试数据'''
self.driver.quit()
if __name__=='__main__':
unittest.main()
总结
- 当我们再次使用登录时,只需要修改login_page.py里的定位元素方法和值就可以了
- 以上代码当然还有很多不足的地方,比如账号密码没有提出来,小伙伴可自行尝试
Python操作Excel
| id | url | boke |
|---|---|---|
| 1 | https://blog.csdn.net/laozhu_Python | 骑着乌龟找猪 |
| 2 | https://www.cnblogs.com/zzpython | 码上开始 |
需求分析
- 方便读取数据,将每一行数据结合标题生成字典:{“id”: 1, "url": "https://blog.csdn.net/laozhu_Pythonrl", "boke": "骑着乌龟找猪"}
- 然后将生成的数据存放在一个列表中[{“id”: 1, "url": "https://blog.csdn.net/laozhu_Pythonrl", "boke": "骑着乌龟找猪"}]
操作流程
处理一个表格,首先要知道路径,所以我们需要知道文件路径然后打开这张表
#! /usr/bin/python3 # @Time : 2020/8/5 13:30
# @Author : 码上开始 import xlrd # 定义文件路径
path = "E:/data.xls"
# 然后打开一个表
data = xlrd.open_workbook(path)
打开表之后,通过获取表对像来操作这个表,相当于我们用鼠标选中这个Sheet1就能操作这个表里内容了,明白了吗?

#! /usr/bin/python3
# @Author : 码上开始
import xlrd
# 定义文件路径
path = "E:/data.xls"
# 然后打开一个表
data = xlrd.open_workbook(path)
# 通过表名获取表对象,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
- 获取表对像后,我们需要这个表格行和列数,才方便查找数据
#! /usr/bin/python3
# @Author : 码上开始
import xlrd
# 打开需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通过下标获取表对象,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列数
cols = sheet1.ncols
# 行数
rows = sheet1.nrows
- id/url/boke我们每一行数据都需要用这个,所以我们需要提出来进行循环操作
#! /usr/bin/python3
# @Author : 码上开始
import xlrd
# 打开需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通过下标获取表对象,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列数
cols = sheet1.ncols
# 行数
rows = sheet1.nrows
# 定义空列表和字典用于存放数据
list = [ ]
# 获取第一行的值
one_value = sheet1.row_values(0)
# 通过打印来检查是不是获取到表里第一行的值
print(one_value)
完整 代码
#! /usr/bin/python3
# @Author : 码上开始
import xlrd
# 打开需要操作的表
path = "E:/data.xls"
data = xlrd.open_workbook(path)
# 通过下标获取表对象,用于操作表
sheet1 = data.sheet_by_name("Sheet1")
# 列数
cols = sheet1.ncols
# 行数
rows = sheet1.nrows
# 定义空列表和字典用于存放数据
list = [ ]
# 获取第一行的值
one_value = sheet1.row_values(0)
# 打印结果是:["id", "url", "boke"]
print(one_value)
# 代码最重要的一段
# 外循环行数(我们从excel表里第2行开始,即下标从1开始,括号里即(1, 3)总循环次数两次
for i in range(1, rows):
# 定义一个字典存放每一行的数据
dict = { }
# 列的数据则是从0开始(就是第1列)结束是我们或取的列值即:(0, 3)
for y in range(0, cols):
# 第一次循环字典是这样写入的:dict["id"] = 1
# 然后依次把数字套进去
dict[one_value[y]] = sheet1.row_values(i)[y]
# 然后将字典数据存放在列表中
list.append(dict)
print(list)
运行结果
[{'id': '1', 'url': 'https://blog.csdn.net/laozhu_Python', 'boke': '骑着乌龟找猪'}, {'id': '2', 'url': 'https://www.cnblogs.com/zzpython/', 'boke': '码上开始'}]
file文件操作
实际工作中,我们经常需要用Python读取文txt文件中的数据. 我们使用open()函数来打开一个文件, 获取到文件句柄. 然后通过文件句柄就可以进行各种各样的操作了. 根据打开方式的不同能够执行的操作也会有相应的差异
常用的文件操作模式
- 打开文件的方式: r, w, a, r+, w+, a+, rb, wb, ab, r+b, w+b, a+b 默认使用的是r(只读)模式
只读(r, rb)
#! /usr/bin/python3
# @公众号 : 码上开始
file = open("E:\\study\\good.txt", "r", encoding="utf-8")
line = file.read()
print(line)
# open模式打开文件一定要记得关闭操作
file.close()
# 运行结果
好好学习
公众号:码上开始
- read() 将文件中的内容全部读取出来. 弊端: 占内存. 如果文件过大.容易导致内存崩溃
- 需要注意encoding表示编码集. 根据文件的实际保存编码进行获取数据, 对于我们而言. 更多的是utf-8
- rb. 读取出来的数据是bytes类型, 在rb模式下. 不能选择encoding字符集
只写(w, wb)
- 写的时候注意. 如果没有文件. 则会创建文件
- 如果文件存在. 则将原件中原来的内容删除, 再写入新内容
#! /usr/bin/python3
# @公众号 : 码上开始
f = open("study.txt", mode="w", encoding="utf-8")
f.write("好好学习Python")
# 刷新. 养成好习惯
f.flush()
f.close()
r+ 读写
- 对于读写模式. 必须是先读. 因为默认光标是在开头的. 准备读取的. 当读完了之后再进行
写入. 我们以后使用频率最⾼的模式就是r+ - 所以记住: r+模式下. 必须是先读取. 然后再写入
#! /usr/bin/python3
# @公众号 : 码上开始
file = open("study.txt", mode="r+", encoding="utf-8")
# 先读取
content = file.read()
# 再写入
file.write("好好学, 天天向上")
print(content)
# 刷新. 养成好习惯
f.flush()
file.close()
# 运行结果
好好学, 天天向上
a+写读(追加写读)
- 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
- 文件指针将会放在文件的结尾所以该示例找不到内容,打印没任何结果
#! /usr/bin/python3
# @公众号 : 码上开始
file = open("study.txt", mode="a+", encoding="utf-8")
# 先读取
content = file.read()
# 再写入
file.write("好好学习")
file.write("天天向上")
# 刷新. 养成好习惯
f.flush()
print(file.readline())
file.close()
安装第3方库
学Python的小伙伴都知道,Python学习过程中需要装不少的第3方的库,今天就和大家一起分享下第3方库的安装方法
在线安装(推荐安装方式)
- 点开Pycharm--file--Project--选择Project Interpreter
通过Terminal安装(Pycharm版本为社区版,版本不同可能存在位置差异,请查行查找)
- Python目录安装
打开安装目录--右键空白处--选择powershell输入--pip install xlwrd--回车

等待完装完毕
离线安装方式
在线安装模式经常会出现安装失败的情况,这时候可以进行离线安装方式
有时候在线安装第三方模块的时,会因为网络原因总是装不上,那怎么办呢?那就手动安装
- 下载所需要的模块包(离线安装出现的机率相对较少所以基本可以忽略,大家知道有这种方式就可以)
- 解压该文件
- 将文件名改短,然后放入非C盘且放在根目录
- 打开cmd---->E:---->cd xlrd---->python setup.py install
- 等待完装完毕
- 导入模块 import xlrd,运行如果没报错就说明安装正常
Web自动化浏览器和驱动的解决办法
在我学习Ui自动化时,总会遇到浏览器驱动版本问题,小伙伴也是一头雾水也找不到下载的地方,今天给大家整理
| chromedriver版本 | 支持的chrome版本 |
|---|---|
| v2.46 | v72-74 |
| v2.45 | v70-72 |
| v2.44 | v69-71 |
| v2.43 | v69-71 |
| v2.42 | v68-70 |
| v2.41 | v67-69 |
| v2.40 | v66-68 |
| v2.39 | v66-68 |
| v2.38 | v65-67 |
| v2.37 | v64-66 |
| v2.36 | v63-65 |
| v2.35 | v62-64 |
| v2.34 | v61-63 |
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
==============================================================================

谷歌浏览器驱动版本对应以及下载:
- 点击下载chrome的webdriver:http://chromedriver.storage.googleapis.com/index.html
- 点击下载chrome的历史版本:https://www.chromedownloads.net/
- 点击进入谷歌官方版本对应页面:https://sites.google.com/a/chromium.org/chromedriver/downloads
edge浏览器驱动版本对应以及下载:
点击进入微软edge浏览器wendriver版
ie浏览器驱动官方地址:
- 点击进入ie浏览器driver下载:http://selenium-release.storage.googleapis.com/index.html
- 点击进入ie浏览器官方github:https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
safari浏览器官方地址:
- 点击进入safari浏览器官方地址:https://developer.apple.com/safari/download/
Web自动化三种等待
我们在做WEB自动化时,经常听到小伙伴说,明明代码没问题,死活定位不到元素,一运行就报错啊。是因为有时候因为网络或其它原因导致我们需要定位的元素还没加载出来,我们代码就执行下一步操作了,这个时候就需要我们在某些场景下加等待时间。
我们平常用到的有三种等待方式:
强制等待
- 就是说不管元素有没有加载出来,必须等3秒钟,时间一到就就执下面代码,导入time模块就可以实现
# -*- coding: utf-8 -*-
# @Author : 一凡
from selenium import webdriver
# 启动浏览器
driver = webdriver.Chrome()# 打开百度首页
driver.get('https://www.baidu.com/')# 强制等待3秒
time.sleep(3)
driver.find_element_by_css_selector("#kw").send_keys("python")# 退出
driver.quit()
隐式等待
第二种办法叫隐性等待,implicitly_wait(xx),隐性等待的意义是:闪电侠和凹凸曼约定好,不论闪电侠去哪儿,都要等凹凸曼xx秒,如果凹凸曼在这段时间内来了,则俩人立即出发去打怪兽,如果凹凸曼在规定时间内没到,则闪电侠自己去,那自然就等着凹凸曼给你抛异常吧。
# -*- coding: utf-8 -*-
# @Author : 一凡
# 启动浏览器
driver = webdriver.Chrome()# 打开百度首页
driver.get(r'https://www.baidu.com/')
driver.find_element_by_css_selector("#kw").send_keys("python")
driver.find_element_by_css_selector("#su").click()# 隐式等待30秒
driver.implicitly_wait(30)
result = driver.find_elements_by_css_selector("h3.t>a")for i in result:print(i.text)# 退出
driver.quit()
显示等待
第三种办法就是显性等待,WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
主要有4个参数:
- driver:浏览器驱动
- timeout:等待时间
- poll_frequency:检测的间隔时间,默认0.5s
- ignored_exceptions:超时后的异常信息,默认抛出NoSuchElementException
# -*- coding: utf-8 -*-
# @Author : 一凡
from seleniumimport webdriver
from selenium.webdriver.support.wait importWebDriverWait
driver = webdriver.Chrome()# 打开百度首页
driver.get(r'https://www.baidu.com/')
driver.find_element_by_css_selector("#kw").send_keys("selenium")
driver.find_element_by_css_selector("#su").click()# 超时时间为30秒,每0.2秒检查1次,直到class="tt"的元素出现
text =WebDriverWait(driver, 30, 0.2).until(lambda x:x.find_element_by_css_selector(".tt")).text
print(text)# 退出
driver.quit()
Python读取Text,Excel,Yaml文件
读取Text
需求:
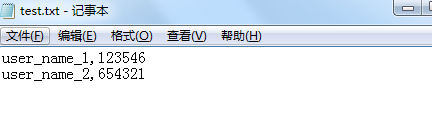
问题解析:
1.打开txt文件
2.读取每一行数据
3.将文件存放在列表中(方便循环读取)
# -*- coding: utf-8 -*-
# @Author : 一凡
with open("E:/test.txt", "r") as f:
#readlines读取文件内每一行数据
for line in f.readlines():
line = line.strip('\n') #去掉列表中每一个元素的换行符
# split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
data = (line.split(","))
print(data)
- 运行结果
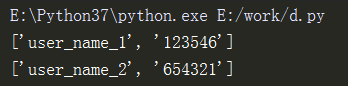
读取Excel
小伙伴都知道,测试用例是写在Excel里的,如果是少量的用例很容易处理,如果用例成百上千条呢?
自动化测试的话,需要对用例数据进行读取,那必须循环读取才可以实现自动化。那么问题来了,怎么做呢?
用例如下图:

问题解析:
1、用列表存放这些用例数据,所以要用到列表
2、每一行用例要存放在字典内,所以需要用到字典
3、循环写入到字典,然后存放到列表内
# -*- coding: utf-8 -*-
# @Author : 一凡
import xlrd
class excel_data:
"""读取excl表接口数据"""
data_path = "E:\\api_interface\\data\\interface.xlsx"
# 打开文件
excel = xlrd.open_workbook(data_path)
# 通过下标定位表格
sheet = excel.sheet_by_index(0)
# 行: 6 和列数: 5
rows, cols = sheet.nrows, sheet.ncols
def read_excl(self):
# 获取第一行数据key
first_row = self.sheet.row_values(0)
# print(first_row) # [编号,接口方式,host, params, result]
# 定义空列表,用于存放用例数据
self.result = []
# 从第一行用例开始循环(1, 6)循环5次
for i in range(1, self.rows):
# 定义空字典
info_dict = {}
# 每1次大循环要循环5次(字典里有5组数据)
for j in range(0, self.cols):
# j=0,1,2,3,4
# 添加到字典 (1)[0]---第2行第1例的值,依次循环
info_dict[first_row[j]] = self.sheet.row_values(i)[j]
# 将数据存放在列表中
self.result.append(info_dict)
print(self.result)
if __name__ == "__main__":
ex = excel_data()
ex.read_excl()
- 运行结果

读取Yaml
- yaml文件后缀名为yaml,如文名件.yaml
- yaml为第3方模块,需另行安装pip install pyyaml
问题解析:
1.定义文件地址
2.打开yaml文件
3.读取文件后转成字典以方便读取
#!/usr/bin/python3
import yaml
import os
# 获取当前脚本所在文件夹路径
curPath = os.path.dirname(os.path.realpath(__file__))
# 获取yaml文件路径
yamlPath = os.path.join(curPath, "E:\\api_interface\\config\\yaml.yaml")
# open方法打开直接读出来
open_file = open(yamlPath, 'r', encoding='utf-8')
result = open_file.read()
file_dict = yaml.load(result, Loader=yaml.FullLoader) # 用load方法转字典
print(file_dict)
- 运行结果

读取ini文件
大家应该接触过.ini格式的配置文件。配置文件就是把一些配置相关信息提取出去来进行单独管理,如果以后有变动只需改配置文件,无需修改代码。
特别是后续做自动化的测试,代码和数据分享,进行管理。比如说发送邮件的邮箱配置信息、数据库连接等信息。
今天介绍一些如何用Python读取ini配置文件。
一、ini文件格式
- 格式如下:
;这是注释
[section]
key1 = value1
key2= value2
[section] key3=value3 key4=value4
[section]:ini的section模块,是下面参数值的一个统称,方便好记就行key = value:参数以及参数值- ini 文件中,使用英文分号“;”进行注释
- section不能重复,里面数据通过section去查找,每个seletion下可以有多个key和vlaue的键值
Py3和Py2区别
# python3
import configParser
# python2
import ConfigParser
二、读取ini文件
Python自带有读取配置文件的模块ConfigParser,配置文件不区分大小写。
有一系列的方法可提供。
read(filename):读取文件内容sections():得到所有的section,并以列表的形式返回。options(section):得到该section的所有option。items(section):得到该section的所有键值对。get(section,option):得到section中option的值,返回string类型。getint(section,option):得到section中option的值,返回int类型。
示例:
# -*- coding: utf-8 -*-
# @Author : 一凡
import os
import configparser
# 当前文件路径
proDir = os.path.split(os.path.realpath(__file__))
# 在当前文件路径下查找.ini文件
configPath = os.path.join(proDir, "config.ini")
print(configPath)
conf = configparser.ConfigParser()
# 读取.ini文件
conf.read(configPath)
# get()函数读取section里的参数值
name = conf.get("section1","name")
print(name)
print(conf.sections())
print(conf.options('section1'))
print(conf.items('section1'))
运行结果:
D:\Python_project\python_learning\config.ini
2号
['section1', 'section2', 'section3', 'section_test_1']
['name', 'sex', 'option_plus']
[('name', '2号'), ('sex', 'female'), ('option_plus', 'value')]
三、修改并写入ini文件
write(fp):将config对象写入至某个ini格式的文件中。add_section(section):添加一个新的section。set(section,option,value):对section中的option进行设置,需要调用write将内容写入配置文件。remove_section(section):删除某个section。remove_option(section,option):删除某个section下的option
接上部分
# -*- coding: utf-8 -*-
# @Author : 一凡
# 写入配置文件 set()
# 修改指定的section的参数值
conf.set("section1",'name','3号')
# 增加指定section的option
conf.set("section1","option_plus","value")
name = conf.get("section1","name")
print(name)
conf.write(open(configPath,'w+'))
# 增加section
conf.add_section("section_test_1")
conf.set("section_test_1","name","test_1")
conf.write(open(configPath,'w+'))
Yaml数据完整篇
什么是yaml
- 一种标记语言。yaml 是专门用来写配置文件的语言,非常简洁和强大
- 更直观,更方便,有点类似于json格式
自动化测试需要做到代码和数据分离,我们经常需要将不同的数据放到不同的文件内进行读取,比如用例放到Excel表里,配置文件放到ini文件里等等。yaml专门用于写配置文件
yaml基本语法规则
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
表示注释,这个和python的注释一样
安装yaml
pip install pyyaml
读取yaml
键值对(dict)
yaml文件,test.yaml
user: admin
pwd: 123456
- 用python读取yaml文件案例如下,先用open方法读取文件数据,再通过load方法转成Python对像,这个load跟json里面的load是相似的。
#! /usr/bin/python3
# @Author : 码上开始
import yaml
# 定义yaml文件路径
yaml_path = "E:\\study\\date.yaml"
# 打开yaml文件
file = open(yaml_path, "r", encoding="utf-8")
# 读取
string = file.read()
dict = yaml.load(string)
# 转换后数据类型为:dict
print(type(dict))
print(dict)
# 运行结果:
{'usr': 'admin', 'pwd': 123456}
序列(list)
- yaml里面写一个数组,前面加一个‘-’符号,如下
- admin1
- admin2
- admin3
#! /usr/bin/python3
# @Author : 码上开始
import yaml
# 定义文件路径
yaml_path = "E:\\study\\date.yaml"
file = open(yaml_path, "r", encoding="utf-8")
string = file.read()
print(string)
# 转换后数据类型为列表
list = yaml.load(string, Loader=yaml.FullLoader)
print(list)
# 运行结果
<class 'list'>
['admin1', 'admin2', 'admin3']
纯量(str)
- 单个的、不可再分的值。如:字符串、布尔值、整数、浮点数、Null、时间、日期
# 布尔值true/false
n: true
# int
n1: 12
# float
n2: 12.3
# None
n3: ~
{'n': True, 'n1': 12, 'n2': 12.3, 'n3': None}
混合使用
- 字典镶嵌在列表内
- usr:
name: admin
pwd: 123456
- mail:
user: xxxx@qq.com
pwd: 123456
运行结果:
[{'usr': {'name': 'admin', 'pwd': 123456}}, {'mail': {'user': 'xxxx@qq.com', 'pwd': 123456}}]
数据写入yaml
- 使用yaml下的dump方法将数据写入到yaml文件内
#! /usr/bin/python3
# @Author : 码上开始
import yaml
写入键值对
# data = {"send_mail": "xxxx@qq.com"}
# 写入列表
# data =["xxxx@qq.com", "xxxx@qq.com"]
# 写入混合数据
# data = [{"mai": {"send": "xxxx@qq.com"}}]
# yaml文件路径
yaml_path = "E:\\study\\date.yaml"
# 打开文件,a是在文件末尾写入内容
file = open(yaml_path, "a", encoding="utf-8")
# 写入数据, allow_unicode=True
yaml.dump(data, file)
# 关闭文件
file.close()
运行结果
# 键值对
send_mail: xxxx@qq.com
# 列表
- xxxx@qq.com
- xxxx@qq.com
# 混合数据
- mai:
send: xxxxx@qq.com
实战
上面我们说了yaml用于在自动化测试中实现代码和数据分离。那么我们在企业项目中如何用yaml实现代码和数据分离呢?有一个场景,我们要发送邮件给指定收件人。
编写yaml文件
- 将收发邮件人数据写到yaml文件内
# 发件人邮箱和授权码
- send_mail: xxx@qq.com
password: QQ邮箱的授权码
# 收件人邮箱
- get_mail: yyyy@qq.com
读取yaml文件
#! /usr/bin/python3
# 公众号 : 码上开始
import yaml
def read_yaml():
"""读取yaml文件"""
# 定义yaml文件路径
yaml_path = "E:\\mail\\date\\yaml.yaml"
# 打开yaml文件
file = open(yaml_path, "r")
# 读取文件
string = file.read()
# 转换为python对像,类型为字典
dict = yaml.load(string)
print(dict)
# 返回数据为字典类型
return dict
运行结果
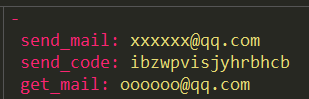
[{'send_mail': 'xxx@qq.com', 'password': 'code'}, {'get_mail': 'yyyy@qq.com'}]
发送邮件
# -*- coding: utf-8 -*-
# @Author : 一凡
import zmail
# 导入common文件下的read_yaml函数
from common import read_yaml
# 调用yaml文件里的数据
response = read_yaml.read_yaml()
def send(send_mail, password, get_mail):
"""发送测试报告"""
report_path = "E:\\mail\\report\\test.html"
MAIL = {
'subject': '邮件主题',
'content_text': '测试发送邮件',
'attachments': report_path,
}
server = zmail.server(send_mail, password)
server.send_mail(get_mail, MAIL)
send(response[0]["sendmail"], response[0]["password"], response[1]["getmail"])
Python结合Web电商+Mysql实战
为什么要做python连接mysql,一般是解决什么问题的
自动化测试中,经常需要向数据库添加或删除数据,也需要验证测试数据和数据库的数据是否一致。这个时候就需要用Python连接Mysql
安装PyMySQL
pip install PyMySQL
连接MySql
# -*- coding: utf-8 -*-
# @Author : 一凡
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "111223", "study_date")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print("Database version : %s " % data)
# 关闭数据库连接
db.close()
数据库基本操作
增加数据
insert 语句可以用来将一行或多行数据插到数据库表中, 使用的一般形式如下:
insert into 表名 [(列名1, 列名2, 列名3, ...)] values (值1, 值2, 值3, ...);
# -*- coding: utf-8 -*-
# @Author : 一凡
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "111223", "study_date")
# 使用cursor()方法获取操作游标,以字典的方式获取数据,原数据类型为元组
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
insert_sql = "insert into studys(id, name, age) values(3, '骑着乌龟赶猪', 35)"
# 执行sql语句
cursor.execute(insert_sql)
# 提交到数据库执行
db.commit()
# 关闭数据库连接
db.close()
删除数据
delete 语句用于删除表中的数据
delete from 表名称 where 删除条件;
# -*- coding: utf-8 -*-
# @Author : 一凡
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "111223", "study_date")
# 使用cursor()方法获取操作游标,以字典的方式获取数据,原数据类型为元组
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
# SQL 删除数据
del_sql = "delete from studys where id=3"
# 执行sql语句
cursor.execute(del_sql)
# 提交到数据库执行
db.commit()
# 关闭数据库连接
db.close()
修改数据
update 语句可用来修改表中的数据
update 表名称 set 列名称=新值 where 更新条件;
update studys set age=25 where id=1
# -*- coding: utf-8 -*-
# @Author : 一凡
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "111223", "study_date")
# 使用cursor()方法获取操作游标,以字典的方式获取数据,原数据类型为元组
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
# SQL 修改数据
updata_sql = "update studys set age=30 where id=2"
# 执行sql语句
cursor.execute(updata_sql)
# 提交到数据库执行
db.commit()
# 关闭数据库连接
db.close()
查询数据
语法:
fetchone()
例如要查询 students 表中所有学生的名字和年龄, 输入语句
select name, age from studys
fetchone()获取一行数据
# 导入模块
# -*- coding: utf-8 -*-
# @Author : 一凡
import pymysql
# 打开数据库连接 数据库地址
db = pymysql.connect("localhost", "root", "111223", "study_date")
# 使用cursor()方法获取操作游标,以字典的方式获取数据,原数据类型为元组
cursor = db.cursor(cursor=pymysql.cursors.DictCursor)
# 使用 execute()方法执行 SQL 查询
# 通配符,意思是查询表里所有内容
cursor.execute("select * from studys")
# 使用 fetchone() 方法获取一行数据.
data = cursor.fetchone()
print(data)
# 关闭数据库连接
db.close()
电商项目实战--判断主界面商品分类是否与数据库一致
传送门如何搭建网站教程
第1步:获取界面分类数据
# -*- coding: utf-8 -*-
# @Author : 一凡
from selenium import webdriver
url = "http://localhost:8080/Shopping/index.jsp"
driver = webdriver.Chrome()
driver.get(url)
复数形式定位定位
els = driver.find_elements_by_xpath("/html/body/table[5]/tbody/tr/td[2]/table[1]/tbody/tr/td/a")
空列表用于存放数据
list = [ ]
for i in els:
# 获取text文本然后添加到列表
list.append(i.text)
print("界面数据:", list)
第2步:获取数据库商品分类数据
db = pymysql.connect(host="localhost", user="root", password="111223", database="db_shopping")
cur = db.cursor(cursor=pymysql.cursors.DictCursor)
# 从tb_bigtype数据库中选择bigName列表
sql = "select bigName from tb_bigtype"
cur.execute(sql)
db.commit()
cur.execute(sql)
data = cur.fetchall()
db_list = []
print("数据库数据:",data)
for i in data:
for j in i.values():
db_list.append(j)
print(db_list)
第3步:两组数据进行断言
第一种方法:
# 反向排序列表
list.reverse()
if db_list == list:
print("一致")
else:
print("不一致")
第二种方式断言:
断言>>集合>>求交集
if set(list) & set(db_list):
print("两者一致")
else:
print("不一致")
Python接口测试自动化(附源码)
接口定义
接口普遍有两种意思,一种是API(Application Program Interface),应用编程接口,它是一组定义、程序及协议的集合,通过API接口实现计算机软件之间的相互通信。而另外一种则是Interface,它是面向对象语言如java,c#等中一个规范,它可以实现多继承的功能。接口测试中的接口指的是API。
为什么要使用接口:
假如公司的产品前端开发还没开发完,接口开发好了。有天领导说,小王,你测下这个登录功能,要是你不懂接口的话就会对领导说这个功能测不了啊,页面没开发完。领导会把你!@¥@)¥!
接口测试是不需要看前端页面的,可以更早的介入到测试工作中,提高工作效率。
根据测试金字塔,越底层成本越低,一个底层的bug可能会引起上一层的多个bug,所以测试越底层,越能保证产品的质量,也越能节省测试的成本。而单元测试一般是由开发来完成的,所以对于测试来说,接口测试是非常必要的。
对于自动化测试来说,UI的变动性最大,所以UI自动化测试的维护成本很高。而接口的改动很小,所以接口自动化测试是最实用,最节约成本的。
基础流程
接口功能自动化测试流程如下:
需求分析 -> 用例设计 -> 脚本开发 -> 测试执行 -> 结果分析
示例接口
手机号码归属地
接口地址:http://apis.juhe.cn/mobile/get
返回格式:json/xml
请求方式:get
请求示例:http://apis.juhe.cn/mobile/get?phone=手机号&key=您申请的KEY
需求分析

需求分析是参考需求、设计等文档,在了解需求的基础上还需清楚内部的实现逻辑,并且可以在这一阶段提出需求、设计存在的不合理或遗漏之处。
如:手机号归属地接口,输入不同号码段的手机号,查看手机号归属和手机号码属于哪个运营商
用例设计
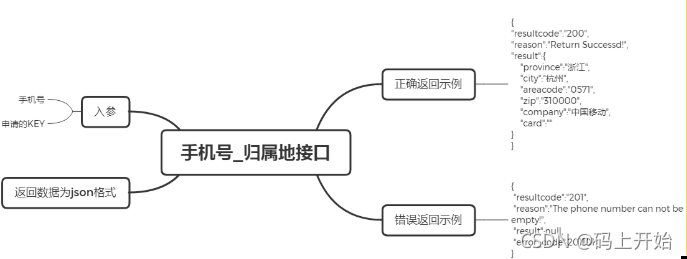
脚本开发
5.1 模块安装
使用pip命令安装即可:pip install requests
5.2 接口调用
使用requests库,我们可以很方便的编写上述接口调用方法(如输入phone=手机号,示例代码如下):
在实际编写自动化测试脚本时,我们需要进行一些封装。
import unittest
import requests
import json
class Test_Moblie(unittest.TestCase):
# 封装公共的数据
def common(self, phone):
url = "http://apis.juhe.cn/mobile/get"
date = {
'key': "4391b7dd8213662798c3ac3da9f54ca8",
'phone': phone
}
self.response = requests.get(url, params=date)
return self.response
def test_1(self):
self.common("1857110")
print(self.response.text)
def test_2(self):
self.common("1868115")
print(self.response.text)
if __name__ == '__main__':
unittest.main()
我们按照测试用例设计,依次编写每个功能的自动化测试脚本即可。
5.3 结果校验
在手工测试接口的时候,我们需要通过接口返回的结果判断本次测试是否通过,自动化测试也是如此。
对于本次的接口,输入手机,我们需要判断返回的结果resultcode是不是等于200结果分页时需要校验返回的结果数是否正确等。完整结果校验代码如下:
# -*- coding: utf-8 -*-
# @Author : 一凡
import unittest
import requests
class Test_Moblie(unittest.TestCase):
# 封装公共的数据
def common(self, phone):
url = "http://apis.juhe.cn/mobile/get"
date = {
'key': "4391b7dd8213662798c3ac3da9f54ca8",
'phone': phone
}
self.response = requests.get(url, params=date)
return self.response
def test_2(self):
self.common("1868115")
print(self.response.json())
dict_2 = self.response.json()
# 打印值省份值为:200
resultcode = dict_2["resultcode"]
# 为演式错误的示例,将对比值改为200,正确值为200,可自行修改
self.assertEqual(resultcode, "200", msg='失败原因:%s != %s' % (resultcode, "200"))
if __name__ == '__main__':
unittest.main()
运行结果
5.4 生成测试报告用例执行完之后,那就需要发报告给领导。
那么我们使用HTMLTestRunner第3方模块插件生成html格式测试报告
# -*- coding: utf-8 -*-
# @Author : 一凡
from unittest import TestSuite
from unittest import TestLoader
import requests
import json
import HTMLTestRunner
import unittest
class Test_Moblie(unittest.TestCase):
# 封装公共的数据
def common(self, phone):
url = "http://apis.juhe.cn/mobile/get"
date = {
'key': "4391b7dd8213662798c3ac3da9f54ca8",
'phone': phone
}
self.response = requests.get(url, params=date)
return self.response
def test_1(self):
"""判断状态码"""
self.common("1857110")
print(self.response.json())
# 返回数据为dict
print(type(self.response.json()))
dict_1 = self.response.json()
# 打印值省份值为:湖北
province = dict_1["result"]["province"]
self.assertEqual(province, "湖北", msg='失败原因:%s != %s' % (province, "湖北"))
def test_2(self):
"""判断省份"""
self.common("1868115")
print(self.response.json())
dict_2 = self.response.json()
# 打印值省份值为:湖北
resultcode = dict_2["resultcode"]
# 为演式错误的示例,将对比值改为201,正确值为200,可自行修改
self.assertEqual(resultcode, "201", msg='失败原因:%s != %s' % (resultcode, "200"))
if __name__ == '__main__':
report = "E:/report_path/result.html"
file = open(report,"wb")
# 创建测试套件
testsuit = unittest.TestSuite()
testload = unittest.TestLoader()
# 括号内传入的是类名,会自动找到以test开头全部的用例
# 用例以例表形式存储
case = testload.loadTestsFromTestCase(Test_Moblie)
testsuit.addTests(case)
run = HTMLTestRunner.HTMLTestRunner(stream=file,
title="接口自动化测试报告",
description="用例执行结果")
run.run(testsuit)
file.close()
5.5发送邮件报告
- 测试完成之后,我们可以使用zmail模块提供的方法发送html格式测试报告
- 基本流程是读取测试报告 -> 添加邮件内容及附件 -> 连接邮件服务器 -> 发送邮件 -> 退出,示例代码如下:
# -*- coding: utf-8 -*-
# @Author : 一凡
import zmail
def send_mail():
# 定义邮件
mail = {"subject": "接口测试报告",# 任一填写
'content_text': '手机号归属地_API自动化测试报告',# 任一填写
# 多个附件使用列表
"attachments": "E:/report/result.html"
}
# 自定义服务器
# 如果不知道如何查看授权码,请查看这一篇博客:https://www.cnblogs.com/zzpython/p/13095749.html
server = zmail.server("发送人邮箱.com",
"QQ邮箱是用授权码",
smtp_host="smtp.qq.com",
smtp_port = 465)
# 发送邮件
server.send_mail("收件人QQ邮箱", mail)
try:
send_mail()
except FileNotFoundError:
print("未找到文件")
else:
print("发送成功")
结果展示
- 打开完成后生成的测试报告,可以看出本次测试共执行了2条测试用例,1条成功,1条失败
最终发送测试报告邮件,截图如下:
分享Python自学历程
其实关于编程这事儿没有接触的那么早,大一的时候没什么关注点,有一门课是vb,一天天的,就抄抄作业啥的就完事儿了。当时也觉的自己不是学编程的料,想着以后估摸也不会干开发相关的工作。

我的自学历程
- 阴差阳错的进入到了软件测试行业,入行比较早。懵懵懂懂。也没想着会学习编程。总觉的自己不是觉这块的料。后来因为项目的一些需求,慢慢接触了编程.
三人行必有我师
为什么是名师指路,因为确实需要老师来指点你的学习,关于这个老师,没有一个确切的点,父母可为师,同学也可以为师,甚至比自己年纪小、资历少的人也可以为师。
重要的是在我们迷茫的时候有一个人带来帮助和指点,所以我觉得,这一点是无比重要的,我们需要的是方向,而不是事事都给你解决掉的人,就好像是父亲,他会给你指明方向,会骂你,但是不管如何都不会替你做你应该做的事
爱上学习
其实这件事对于我来说是顺其自然的,由于我个人没有那么衰,相信在此的各位也都是积极向上的,爱上学习这件事是很容易的,尤其是最近疫情期间在家一直躺到想起床学习。
最重要的,是我们要正视学习和娱乐,我们所谓的放松不是打一把游戏就算了,要知道职业选手一天要打十几个小时的游戏,换成我们这些普通人同样也hold不住,所以学习同样是一种放松,正确的看待游戏和学习
在这里我觉得很有必要的是要有求知欲,这不是说我想有就能有的,这真的是要自己去探索,有一张图很好,贴在这里一下,做一个分享

乐于分享
大概自学的同学,都是看视频或着看博客来学的,总会感觉到讲师有多么的厉害,其实这最能体现的就是,把一个东西教给别人的时候,能学习到更多的东西,能够检查自己学习是否全面,是否掌握,这个时候,不仅他人能够受益,自己收获也会很大,要乐于把自己学会的东西分享出去,有了反馈之后一定会有不一样的感受
一起学习
自学最大挑战,就是坚持不下去,所以,可以找同学一起学习,当然,也可以发帖找人一起打卡,每天分享心得,这样,有了反馈,有人一起,学习的效率就会更高,当然也就会更优秀。听过一句话,一个人可以走的很快,一群人会走的很远。找个伙伴可能会体会到不一样的感觉,奥利给!!!
说在最后
其实学习这件事很容易,不局限于编程,学习是一件持久的事情,从始至终,有句话说得好,“知之者不如好之者,好之者不如乐之者”,我们要爱上学习。

表白python
作为一名软件测试工程师,我是很喜欢Python的,每当解决了工作中的问题,会觉的很高兴,帮助我实现了我想要的功能,大大提高了我的工作效率。
编写代码时的优雅是无与伦比的,我喜欢他那多样化的编写方式,深深地使我折服,那流畅的语言,是你与计算机独特的交流方式,和计算机共同构建着这独一无二的艺术品,外部功能的完善,内部代码的优雅,巧夺天工都不足以来形容。
❤️❤️新生代农民工爆肝8万字,整理Python编程从入门到实践(建议收藏)已码:8万字❤️❤️的更多相关文章
- ❤️❤️爆肝3万字整理小白快速入门分布式版本管理软件:Git,图文并茂(建议收藏)--已码一万字❤️❤️
@ 目录 什么是Git SVN VS Git 什么是版本控制 安装Git 谁在操作? Git本地仓库 本地仓库构造 重点 Git基本操作 git add git commit git diff git ...
- 设置应用程序的样式并对其进行部署——《Python编程从入门到实践》
我们将使用应用程序django-bootstrap3为Web应用程序设计样式.我们将把项目"学习笔记"部署到Heroku,这个网站能让我们们将项目推送到其服务器,让任何有网络连接的 ...
- Python编程从入门到实践笔记——异常和存储数据
Python编程从入门到实践笔记——异常和存储数据 #coding=gbk #Python编程从入门到实践笔记——异常和存储数据 #10.3异常 #Python使用被称为异常的特殊对象来管理程序执行期 ...
- Python编程从入门到实践笔记——文件
Python编程从入门到实践笔记——文件 #coding=gbk #Python编程从入门到实践笔记——文件 #10.1从文件中读取数据 #1.读取整个文件 file_name = 'pi_digit ...
- Python编程从入门到实践笔记——类
Python编程从入门到实践笔记——类 #coding=gbk #Python编程从入门到实践笔记——类 #9.1创建和使用类 #1.创建Dog类 class Dog():#类名首字母大写 " ...
- Python编程从入门到实践笔记——函数
Python编程从入门到实践笔记——函数 #coding=gbk #Python编程从入门到实践笔记——函数 #8.1定义函数 def 函数名(形参): # [缩进]注释+函数体 #1.向函数传递信息 ...
- Python编程从入门到实践笔记——用户输入和while循环
Python编程从入门到实践笔记——用户输入和while循环 #coding=utf-8 #函数input()让程序暂停运行,等待用户输入一些文本.得到用户的输入以后将其存储在一个变量中,方便后续使用 ...
- Python编程从入门到实践笔记——字典
Python编程从入门到实践笔记——字典 #coding=utf-8 #字典--放在{}中的键值对:跟json很像 #键和值之间用:分隔:键值对之间用,分隔 alien_0 = {'color':'g ...
- Python编程从入门到实践笔记——if语句
Python编程从入门到实践笔记——if语句 #coding=utf-8 cars=['bwm','audi','toyota','subaru','maserati'] bicycles = [&q ...
随机推荐
- COM笔记-Widows 注册表
Widows 注册表 HKEY_CLASSES_ROOT在此关键字之下,可以看到有一个CLSID关键字.在CLSID关键字之下列有系统中安装的所有组件的CLSID.注册表CLSID是一个具有如下格式的 ...
- jsoup的Document类
一.简介 Document是一个装载html的文档类,它是jsoup一个非常重要的类.类声明:public class Document extends Element .Document是Node间 ...
- 设置一个元素的HTML内容
问题 你需要一个元素中的HTML内容 方法 可以使用Element中的HTML设置方法具体如下: Element div = doc.select("div").first(); ...
- webapp网络定位
1 <script> 2 var x=document.getElementById("demo"); 3 function getLocation() 4 { 5 i ...
- Mysql慢查询explain
转自:https://www.toutiao.com/i6776461352522220036/?tt_from=weixin&utm_campaign=client_share&wx ...
- jQuery最后案例:商标展示
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <hea ...
- 未解决:为什么在struts2下新建ognl的包,会出错?
首先开始在src下新建了一个名叫ognl的包: 发现在其中放置了一个loginAction,即使是最简单的跳转都不能实现: 直接抛出了java.lang.Exception; 传递参数更出现了异常: ...
- react项目实现多语言切换
网站的语言切换功能大家都见过不少,一般都是一个下拉框选择语言,如果让我们想一下怎么实现这个功能,我相信大家都是有哥大概思路,一个语言切换的select,将当前的选择的语言存在全局,根据这个语言的key ...
- Win10 pip install augimg 报 OSError: [WinError 126] 找不到指定的模块,解决办法
第一种Win10下python成功安装augimg的方法: 下载Shapely,地址https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely,选择对应版本 ...
- VSCode添加某个插件后,Python 运行时出现Segmentation fault (core dumped) 解决办法
在VSCode添加某个插件后,Debug出现Segmentation fault (core dumped) 解决方案,在当前environment下运行: conda update --all