跳表--怎么让一个有序链表能够进行"二分"查找?
对于一个有序数组,如果要查找其中的一个数,我们可以使用二分查找(Binary Search)算法,将它的时间复杂度降低为O(logn).那查找一个有序链表,有没有办法将其时间复杂度也降低为O(logn)呢?
跳表(skip list),全称为跳跃链表,实质上就是一种可以进行二分查找的有序链表,它允许快速查询、插入和删除有序链表。
跳表使用的前提是链表有序,就像二分查找也要求有序数组
怎么理解跳表
比如我们有一个原始有序链表,如下图所示。
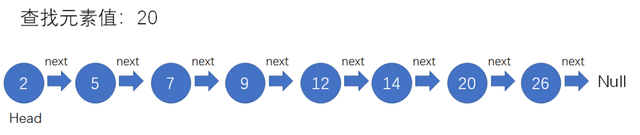
要查找其中值为20的元素,之前都是采取按顺序进行遍历的方法,但这样做时间复杂度就变成了O(n).怎样才能提高效率呢?我们可以通过对链表建立一级索引,查找的时候先遍历索引,通过索引找到原始层继续遍历。索引如下图所示

那么查找20的过程就变成了先使用索引遍历 2 -> 7 -> 12 -> 20,然后顺着索引链表的结点向下找到原始链表的结点20.之前需要遍历7次,现在需要遍历5次。在数据量小的时候跳表性能优化并不明显,但当有序链表包含大量数据时,结点的访问次数大致会减少一半。
现在我们添加两层索引,基于第一层的索引再添加一层,如下图所示

要查找20,先在第二层索引上遍历 2 -> 12 ,然后向下转到第一层索引遍历 12 - > 20,最后向下找到原始链表的结点20.
这个例子中,原始有序链表的结点数量很少,当结点数量很多时,可以抽出更多的索引层级,每一层索引结点的数量都是低层索引的一半。
跳表复杂度分析
时间复杂度
算法的执行效率可以通过时间复杂度来衡量,跳表的时间复杂度是多少呢?我们来分析一下。
前面我们每两个结点抽一个结点作为上一级索引的结点,那么假设原始链表的长度为n,第一层索引的结点个数为n/2,第二层索引的个数为n/4,第k级的索引结点个数就是n/(2k)。假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
m的值怎么计算呢?在上面的例子中,每一层最多只需要遍历三个元素,因此m=3,根据时间复杂度的计算规则,高阶的常数项也可以省略,因此跳表中查询任意数据的时间复杂度就是O(logn)
空间复杂度
每两个结点中抽一个结点作为上级索引,很明显,它的空间复杂度为O(n).
♂这是一个典型的空间换时间操作。原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,索引占用的额外空间就可以忽略了。
高效的插入和删除
插入操作
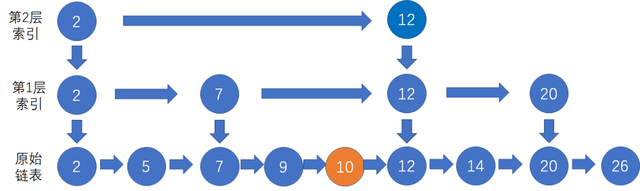
向链表插入数据的时间复杂度是O(1),但为了保持链表数据有序,需要先找到插入结点的前置结点,然后插入数据到前置结点后面,其时间复杂度为O(logn)。假设我们要插入10,需要先找到前置结点9,然后插入10。
删除操作
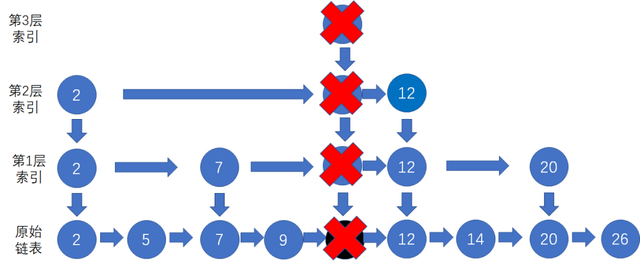
删除的话也是需要先找到要删除的结点,如果该结点在索引中也有出现的话,索引中的也需要删除。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。
动态更新索引
当我们一直往跳表中插入数据时,两个索引结点之间的数据可能会变得非常多,在极端情况下,跳表还会退化成单链表,这样的话跳表的优势也就没有了。
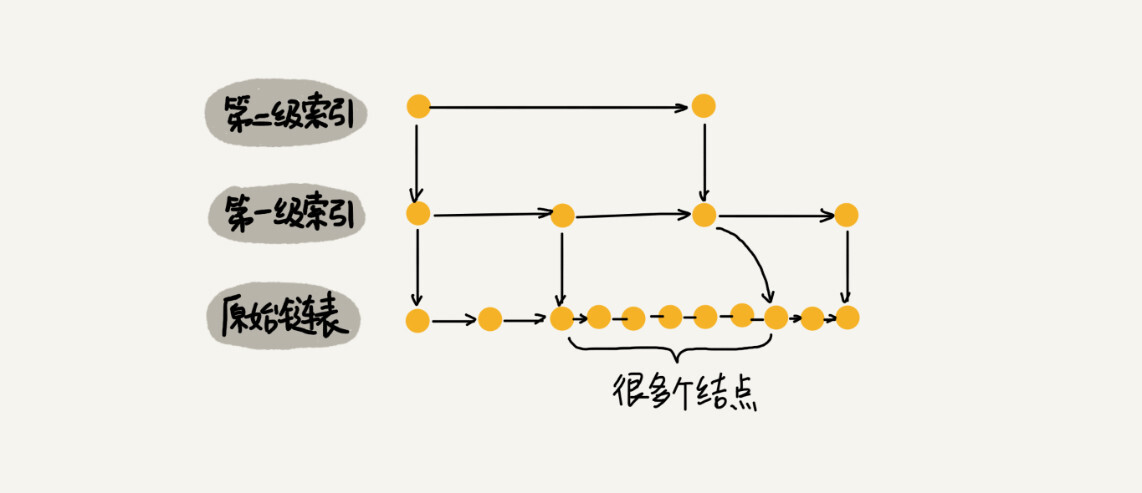
因此我们需要用一些方法来维护索引和原始链表之间的平衡,也就是在增加原始链表中结点内容的时候适当增加索引的大小。为了维护平衡,跳表的设计者采用了一种有趣的方法:“抛硬币”,也就是随机决定新结点是否建立索引,两个结点建立一个索引的话,每层的概率为50%。
Java实现跳表
下面是王争老师 数据结构与算法之美 课程中的代码
package skiplist;
/**
* 跳表的一种实现方法。
* 跳表中存储的是正整数,并且存储的是不重复的。
*
* Author:ZHENG
*/
public class SkipList {
private static final float SKIPLIST_P = 0.5f;
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // 带头链表
public Node find(int value) {
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
public void insert(int value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; ++i) {
update[i] = head;
}
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;// use update save node in search path
}
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; ++i) {
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
}
// update node hight
if (levelCount < level) levelCount = level;
}
public void delete(int value) {
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
while (levelCount>1&&head.forwards[levelCount]==null){
levelCount--;
}
}
// 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
// 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 50%的概率返回 1
// 25%的概率返回 2
// 12.5%的概率返回 3 ...
private int randomLevel() {
int level = 1;
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
public class Node {
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}总结

跳表--怎么让一个有序链表能够进行"二分"查找?的更多相关文章
- [PHP] 算法-合并两个有序链表为一个有序链表的PHP实现
合并两个有序的链表为一个有序的链表: 类似归并排序中合并两个数组的部分 1.遍历链表1和链表2,比较链表1和2中的元素大小 2.如果链表1结点大于链表2的结点,该结点放入第三方链表 3.链表1往下走一 ...
- 【LC_Lesson7】---将两个有序链表合成新的一个有序链表
将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4 输出:1->1->2- ...
- 从一个NOI题目再学习二分查找。
二分法的基本思路是对一个有序序列(递增递减都可以)查找时,测试一个中间下标处的值,若值比期待值小,则在更大的一侧进行查找(反之亦然),查找时再次二分.这比顺序访问要少很多访问量,效率很高. 设:low ...
- Search in Rotated Sorted Array, 查找反转有序序列。利用二分查找的思想。反转序列。
问题描述:一个有序序列经过反转,得到一个新的序列,查找新序列的某个元素.12345->45123. 算法思想:利用二分查找的思想,都是把要找的目标元素限制在一个小范围的有序序列中.这个题和二分查 ...
- leetcode 31. Next Permutation (下一个排列,模拟,二分查找)
题目链接 31. Next Permutation 题意 给定一段排列,输出其升序相邻的下一段排列.比如[1,3,2]的下一段排列为[2,1,3]. 注意排列呈环形,即[3,2,1]的下一段排列为[1 ...
- C语言跳表(skiplist)实现
一.简介 跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入.删除.查找的复杂度均为O(logN).LevelDB的核心数据结构是用跳表实现的,redis的sorted set数据结构也 ...
- 【转】SkipList跳表基本原理
增加了向前指针的链表叫作跳表.跳表全称叫做跳跃表,简称跳表.跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表.跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找.跳表不仅 ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
随机推荐
- linux下静态库的制作
在我们编写软件的过程当中,少不了需要使用别人的库函数.因为大家知道,软件是一个协作的工程.作为个人来讲,你不可能一个人完成所有的工作.另外,网络上一些优秀的开源库已经被业内广泛接受,我们也没有必要把 ...
- ubuntu黑屏无法进入系统【Recovery Mode急救】
一.问题 前言:因为一次美化配置ubuntu导致系统启动黑屏,无法进入系统.之前并没有系统备份,后果严重还好修复了,记录下修复步骤备用. 事件:就是因为修改了 /usr/share/gnome-sh ...
- Mybatis--级联(一)
级联是resultMap中的配置. 级联分为3种 鉴别器(discrimination):根据某些条件采用具体实现具体实现类级联,如体检表根据性别去区分 一对一:学生和学生证 一对多:班主任和学生. ...
- ☕【Java技术指南】「TestNG专题」单元测试框架之TestNG使用教程指南(上)
TestNG介绍 TestNG是Java中的一个测试框架, 类似于JUnit 和NUnit, 功能都差不多, 只是功能更加强大,使用也更方便. 详细使用说明请参考官方链接:https://testng ...
- OVN架构
原文地址 OVN架构 1.简介 OVN,即Open Virtual Network,是一个支持虚拟网络抽象的系统. OVN补充了OVS的现有功能,增加了对虚拟网络抽象的原生(native)支持,比如虚 ...
- git《一》
org.eclipse.jgit.api.errors.TransportException: https://gitee.com/wbweb/springboot_vue.git: Authenti ...
- ros-kinetic install error: sudo rosdep init ImportError: No module named 'rosdep2'
refer to: https://blog.csdn.net/yueyueniaolzp/article/details/85070093 方法一 将Ubuntu默认python版本设置为2.7 方 ...
- jquery/vue/react前端多语言国际化翻译方案指南
❝ 本文章共3470字,预计阅读时间5-10分钟. ❞ 国际化-前言 每个开发者能希望编写的程序可以让全世界的用户使用,它要求从产品中抽离所有地域语言,国家/地区和文化相关的元素.换种说法,「应用程序 ...
- 16 bit 的灰度图如何显示
16 bit 的灰度图如何在QT中显示 用Mat构造的 16 bit 灰度图 无法直接显示,需要转换成 8 bit 的灰度图在QT中显示, 使用OpenCV自带的最大最小值归一法, cv::norma ...
- Python之requests模块-cookie
cookie并不陌生,与session一样,能够让http请求前后保持状态.与session不同之处,在于cookie数据仅保存于客户端.requests也提供了相应到方法去处理cookie. 在py ...