Pytorch入门中 —— 搭建网络模型
本节内容参照小土堆的pytorch入门视频教程,主要通过查询文档的方式讲解如何搭建卷积神经网络。学习时要学会查询文档,这样会比直接搜索良莠不齐的博客更快、更可靠。讲解的内容主要是pytorch核心包中TORCH.NN中的内容(nn是Neural Netwark的缩写)。
通常,我们定义的神经网络模型会继承torch.nn.Module类,该类为我们定义好了神经网络骨架。

卷积层
对于图像处理来说,我们通常使用二维卷积,即使用torch.nn.Conv2d类:
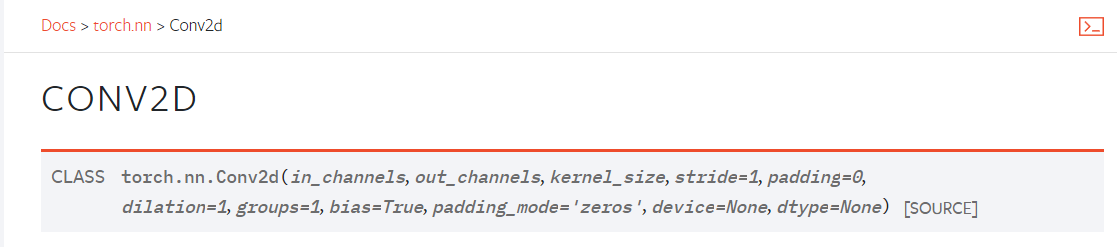
创建该类时,我们通常只需要传入以下几个参数,其他不常用参数入门时可以不做了解,使用默认值即可,以后需要时再查询文档:
in_channels (int):输入数据的通道数,图片通常为3
out_channels (int):输出数据的通道数,也是卷积核的个数
kernel_size (int or tuple):卷积核大小,传入int表示正方形,传入tuple代表高和宽
stride (int or tuple, optional):卷积操作的步长,传入int代表横向和纵向步长相同,默认为1
padding (int, tuple or str, optional):填充厚度,传入int代表上下左右四个边填充厚度相同,默认为0,即不填充
padding_mode (string, optional):填充模式,默认为'zeros',即0填充
卷积操作后输出的张量的高和宽计算公式如下:

其中input和output中的N代表BatchSize,C代表通道数,他们不影响H和W的计算。在保持dilation为默认值1的情况下,计算公式可简化为如下:
\]
\]
池化层
常用的二维最大池化定义在torch.nn.MaxPool2d类中:
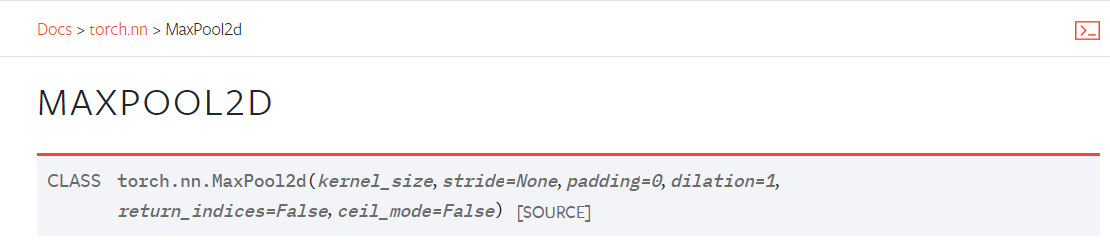
创建该类时,我们通常只需要传入以下几个参数,其他不常用参数入门时可以不做了解,使用默认值即可,以后需要时再查询文档:
kernel_size:池化操作时的窗口大小
stride:池化操作时的步长,默认为kernel_size
padding:每个边的填充厚度(0填充)
池化操作后输出的张量的高和宽计算公式与卷积操作后的计算公式相同。
非线性激活
常见的ReLU激活定义在torch.nn.ReLU类中:

参数inplace代表是否将ouput直接修改在input中。
线性层
线性层的定义在torch.nn.Linear类中:

创建线性层使用的参数如下:
in_features:输入特征大小
out_features:输出特征大小
bias:是否添加偏置,默认为True
模型搭建示例
下图是一个CIFAR10数据集上的分类模型,下面将根据图片进行模型代码的编写。
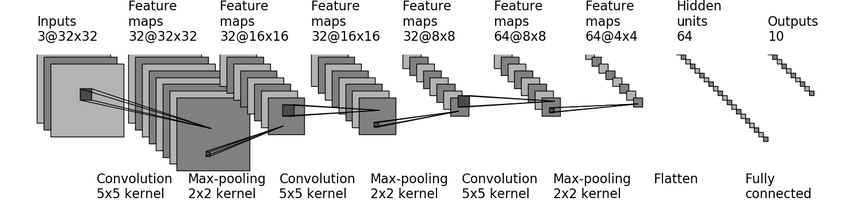
1.由于CIFAR10数据集中图片为3*32*32,所以图中模型的输入为3通道,高宽都为32的张量。
2.使用 5*5的卷积核进行卷积操作,得到通道数为32,高和宽为32的张量。因此我们可以推出该卷积层的参数如下:
in_channels = 3
out_channels = 32
kernel_size = 5
stride = 1
padding = 2
注:将 Hin = 32,Hout = 32 以及kernal_size[0] = 5三个参数带入:
\]
有:
\]
发现stride[0] = 1和padding[0] = 2可以使得等式成立。同理可以得到stride[1] = 1和padding[1] = 2。
3.使用2*2的核进行最大池化操作,得到通道数为32,高和宽为16的张量。可以推出该池化层的参数如下:
kernel_size = 2
stride = 2
padding = 0
注:stride和padding推导方式与2中相同。
4.使用 5*5的卷积核进行卷积操作,得到通道数为32,高和宽为16的张量。因此我们可以推出该卷积层的参数如下:
in_channels = 32
out_channels = 32
kernel_size = 5
stride = 1
padding = 2
5.使用2*2的核进行最大池化操作,得到通道数为32,高和宽为8的张量。可以推出该池化层的参数如下:
kernel_size = 2
stride = 2
padding = 0
6.使用 5*5的卷积核进行卷积操作,得到通道数为64,高和宽为8的张量。因此我们可以推出该卷积层的参数如下:
in_channels = 32
out_channels = 64
kernel_size = 5
stride = 1
padding = 2
7.使用2*2的核进行最大池化操作,得到通道数为64,高和宽为4的张量。可以推出该池化层的参数如下:
kernel_size = 2
stride = 2
padding = 0
8.将64*4*4的张量进行展平操作得到长为1024的向量。
9.将长为1024的向量进行线性变换得到长为64的向量(隐藏层),可以推出该线性层的参数如下:
in_features:1024
out_features:64
10.将长为64的向量进行线性变换得到长为10的向量,可以推出该线性层的参数如下:
in_features:64
out_features:10
因此,模型代码如下:
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5, padding=2)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 32, 5, padding=2)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(32, 64, 5, padding=2)
self.max_pool3 = nn.MaxPool2d(2)
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(1024, 64)
self.linear2 = nn.Linear(64, 10)
# 必须覆盖该方法,该方法会在实例像函数一样调用时被调用,后面会有示例
def forward(self, x):
x = self.conv1(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = self.max_pool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
sequential
使用torch.nn.sequential可以简化模型的搭建代码,他是一个顺序存放Module的容器。当sequential执行时,会按照Module在构造函数中的先后顺序依次调用,前面Module的输出会作为后面Module的输入。
使用sequential,上一节的代码可以简化为:
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super.__init__(MyModel, self)
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
损失函数、反向传播以及优化器
上面两节我们已经将CIFAR10的分类模型搭建好,但还需要进行训练后才能用来预测分类。训练模型时,会用损失函数来衡量模型的好坏,并利用反向传播来求梯度,然后利用优化器对模型参数进行梯度下降,多次循环往复以训练出最优的模型。
模型训练代码如下:
import torch
from torch.optim import SGD
import torchvision
from torch.utils.data import DataLoader
from cifar10_model import MyModel
from torch import nn
from torch.utils import tensorboard
def train():
# 获取 cifar10 数据集
root = "./dataset"
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_cifar10 = torchvision.datasets.CIFAR10(root=root, train=True,
transform=transform,
download=True)
# 创建dataloader
train_dataloader = DataLoader(dataset=train_cifar10, batch_size=64,
shuffle=True,
num_workers=16)
# 创建模型
model = MyModel()
# 创建交叉熵损失函数
loss = nn.CrossEntropyLoss()
# 创建优化器,传入需要更新的参数,以及学习率
optim = SGD(model.parameters(), lr=0.01)
# 创建 SummaryWriter
writer = tensorboard.SummaryWriter("logs")
# 写入模型图,随机生成一个输入
writer.add_graph(model, torch.randn(64, 3, 32, 32))
for epoch in range(20):
loss_temp = 0.0
for batch_num, batch_data in enumerate(train_dataloader):
images, targets = batch_data
# 像调用方法一样调用实例
outputs = model(images)
loss_res = loss(outputs, targets)
loss_temp = loss_res
# 清空前一次计算的梯度
optim.zero_grad()
# 反向传播求梯度
loss_res.backward()
# 更新参数
optim.step()
# 记录每个epoch之后的loss
writer.add_scalar("Loss/train", loss_temp, epoch)
writer.close()
if __name__ == "__main__":
train()
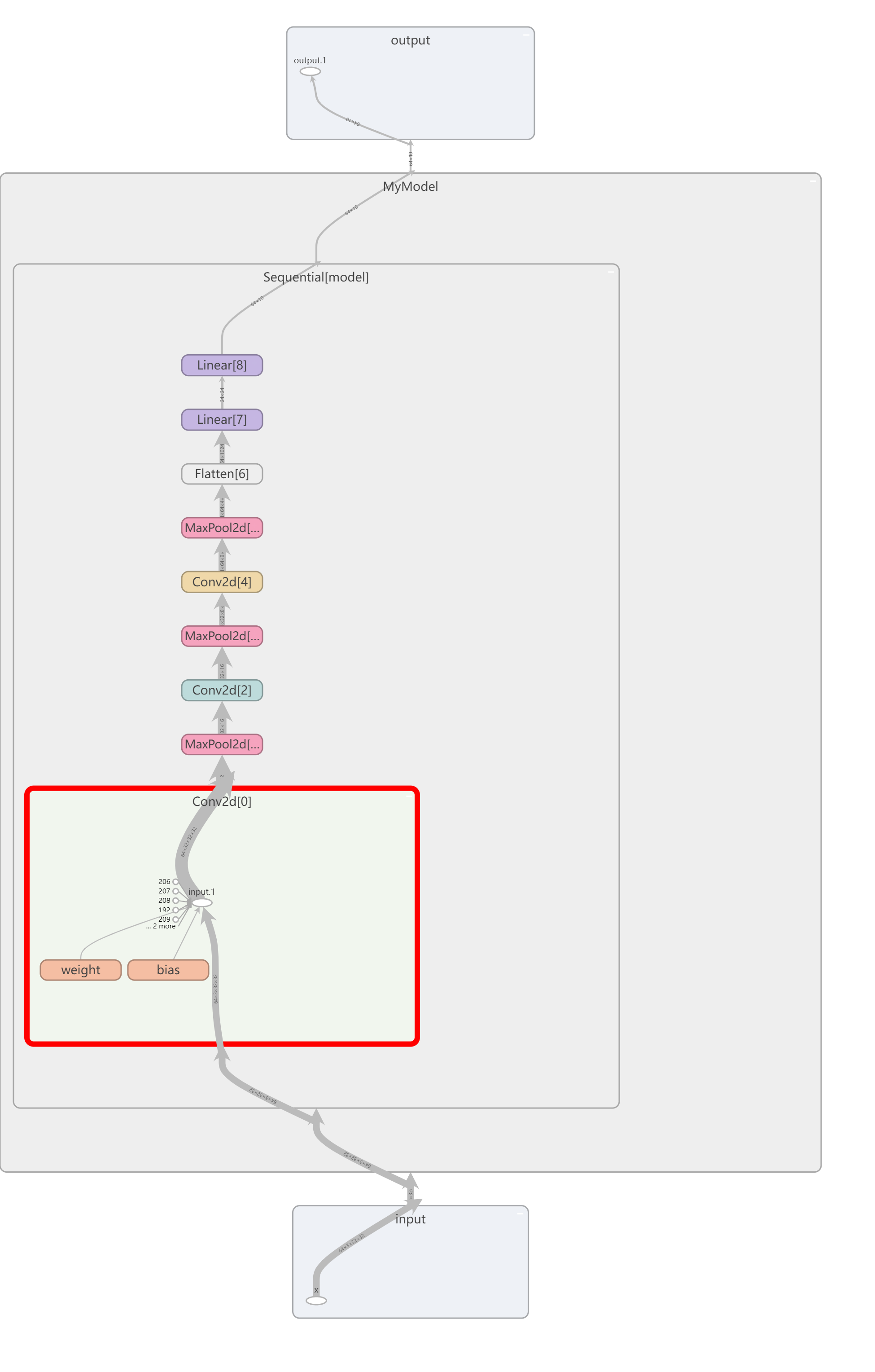
模型图如下:
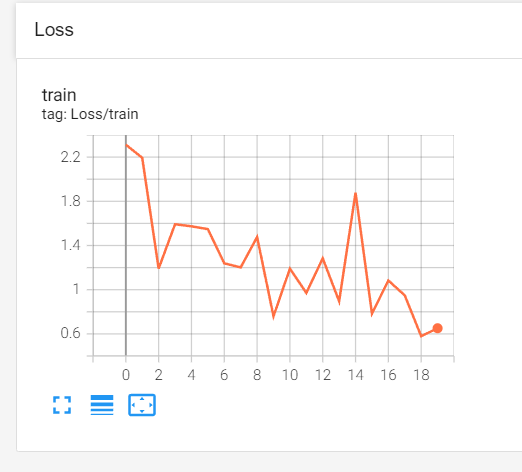
损失函数随训练周期的下降情况如下:
Pytorch入门中 —— 搭建网络模型的更多相关文章
- Pytorch入门随手记
Pytorch入门随手记 什么是Pytorch? Pytorch是Torch到Python上的移植(Torch原本是用Lua语言编写的) 是一个动态的过程,数据和图是一起建立的. tensor.dot ...
- Pytorch入门下 —— 其他
本节内容参照小土堆的pytorch入门视频教程. 现有模型使用和修改 pytorch框架提供了很多现有模型,其中torchvision.models包中有很多关于视觉(图像)领域的模型,如下图: 下面 ...
- pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- 架构师入门:搭建双注册中心的高可用Eureka架构(基于项目实战)
本文的案例是基于 架构师入门:搭建基本的Eureka架构(从项目里抽取) 改写的. 在上文里,我们演示Eureka客户端调用服务的整个流程,在这部分里我们将在架构上有所改进.大家可以想象下,在上文里案 ...
- Spring Cloud 入门教程 - 搭建配置中心服务
简介 Spring Cloud 提供了一个部署微服务的平台,包括了微服务中常见的组件:配置中心服务, API网关,断路器,服务注册与发现,分布式追溯,OAuth2,消费者驱动合约等.我们不必先知道每个 ...
- ArcGIS API for Silverlight/ 开发入门 环境搭建
Silverlight/ 开发入门 环境搭建1 Silverlight SDK下载ArcGIS API for Microsoft Silverlight/WPF ,需要注册一个ESRI Gloab ...
- Spring MVC+Spring+Mybatis+MySQL(IDEA)入门框架搭建
目录 Spring MVC+Spring+Mybatis+MySQL(IDEA)入门框架搭建 0.项目准备 1.数据持久层Mybatis+MySQL 1.1 MySQL数据准备 1.2 Mybatis ...
- 基于flask的轻量级webapi开发入门-从搭建到部署
基于flask的轻量级webapi开发入门-从搭建到部署 注:本文的代码开发工作均是在python3.7环境下完成的. 关键词:python flask tornado webapi 在python虚 ...
随机推荐
- NFS导致df -h卡主解决
NFS导致df -h无法使用解决 NFS服务意外断开,导致挂载的客户端"df -Th"命令无法使用,及挂载目录无法"cd""ls"解决思路: ...
- [loj2135]幻想乡战略游戏
以1为根建树,令$D_{i}$为$i$子树内所有节点$d_{i}$之和 令$ans_{i}$为节点$i$的答案,令$fa$为$i$的父亲,则$ans_{i}=ans_{fa}+dis(i,fa)(D_ ...
- Svelte入门——Web Components实现跨框架组件复用
Svelte 是构建 Web 应用程序的一种新方法,推出后一直不温不火,没有继Angular.React和VUE成为第四大框架,但也没有失去热度,无人问津.造成这种情况很重要的一个原因是,Svelte ...
- 『学了就忘』Linux用户管理 — 52、用户组管理相关命令
目录 1.添加用户组 2.删除用户组 3.把用户添加进组或从组中删除 4.有效组(了解) 1.添加用户组 添加用户组的命令是groupadd. 命令格式如下: [root@localhost ~]# ...
- Matlab矢量图图例函数quiverkey
Matlab自带函数中不包含构造 quiver 函数注释过程,本文参照 matplotlib 中 quiverkey 函数,构造类似函数为 Matlab 中 quiver 矢量场进行标注. quive ...
- SNP 过滤(二)
本文转载于https://www.jianshu.com/p/e6d5dd774c6e SNP位点过滤 SNP过滤有两种情况,一种是仅根据位点质量信息(测序深度,回帖质量等)对SNP进行粗过滤.如果使 ...
- JForum论坛安装以及部署
转载链接:https://blog.csdn.net/jhyfugug/article/details/79467369 首先安装JForum之前,先准备好安装环境Windows7+JDK+Tomca ...
- 一个简单的BypassUAC编写
什么是UAC? UAC是微软为提高系统安全而在Windows Vista中引入的新技术,它要求用户在执行可能会影响计算机运行的操作或执行更改影响其他用户的设置的操作之前,提供权限或管理员密码.通过在 ...
- Swift-技巧(十一)重写运算符
摘要 基础数据的运算可以直接使用四则运算符.在 Swift 中也可以通过重写四则运算符的方式,让 struct 或者 class 创建的结构体或者对象也能像基础数据那样直接使用四则运算符. Swift ...
- 日常Java 2021/11/13
Java Applet基础 Applet是一种Java程序.它一般运行在支持Java的Web浏览器内.因为它有完整的Java API支持,所以Applet是一个全功能的Java应用程序.如下所示是独立 ...