JavaXML解析的四种方法(连载)
1. xml简介
XML:指可扩展标记语言, Extensible Markup Language;类似HTML。XML的设计宗旨是传输数据,而非显示数据。
一个xml文档实例:

1 <?xml version="1.0" encoding="UTF-8"?>
2 <company name="Tencent" address="深圳市南山区">
3 <department deptNo="001" name="development">
4 <employee id="devHead" position="minister">许刚</employee>
5 <employee position="developer">工程师A</employee>
6 </department>
7 <department deptNo="002" name="education">
8 <employee position="minister" telephone="1234567">申林</employee>
9 <employee position="trainee">实习生A</employee>
10 </department>
11 </company>
第一行是 XML 声明。它定义 XML 的版本 (1.0) 和所使用的编码.
下一行描述文档的根元素:<company>开始,该根元素具有2个属性“name”,"address"。
最后一行定义根元素的结尾。</company>。
· XML 文档形成一种树结构
· XML 文档必须包含根元素。该元素是所有其他元素的父元素。
· XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有元素均可拥有子元素:
1 <root>
2
3 <child>
4
5 <subchild>.....</subchild>
6
7 </child>
8
9 </root>
父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
1.1 节点
节点:XML文档中的所有节点组成了一个文档树(或节点树)。XML文档中的每个元素、属性、文本等都代表着树中的一个节点。树起始于文档节点,并由此继续伸出枝条,直到处于这棵树最低级别的所有文本节点为止,常用节点类型如下表所示:
|
节点类型 |
附加说明 |
实例 |
|
元素节点(Element) |
XML标记元素 |
<company>…</company> |
|
属性节点(Attribute) |
XML标记元素的属性 |
name=”Tencent” |
|
文本节点(Text) |
包括在XML标记中的文本段 |
工程师A |
|
文档类型节点(DocumentType) |
文档类型声明 |
﹤!DOCTYPE…﹥ |
|
注释节点Comment |
XmlComment类注释节点。 |
<!—文档注释-> |
(1) 节点关系
通过上面的XML文档,我们构建出如下树状文档对象模型:

1 <?xml version="1.0" encoding="UTF-8"?>
2 <bookstore>
3 <book category="COOKING">
4 <title lang="en">Everyday Italian</title>
5 <author>Giada De Laurentiis</author>
6 <year>2005</year>
7 <price>30.00</price>
8 </book>
9 <book category="CHILDREN">
10 <title lang="en">Harry Potter</title>
11 <author>J K. Rowling</author>
12 <year>2005</year>
13 <price>29.99</price>
14 </book>
15 <book category="WEB">
16 <title lang="en">Learning XML</title>
17 <author>Erik T. Ray</author>
18 <year>2003</year>
19 <price>39.95</price>
20 </book>
21 </bookstore>
再如上例xml文档:

例子中的根元素是 <bookstore>。文档中的所有 <book> 元素都被包含在 <bookstore> 中。<book> 元素有 4 个子元素:<title>、< author>、<year>、<price>。
(2)xml的特点
a). XML 的属性值须加引号。
· 与 HTML 类似,XML 也可拥有属性(名称/值的对)。
· 在 XML 中,XML 的属性值须加引号。
b). XML 文档必须有根元素.XML 文档必须有一个元素是所有其他元素的父元素。该元素称为根元素。
c). XML 标签对大小写敏感.
· XML 元素使用 XML 标签进行定义。
· XML 标签对大小写敏感。在 XML 中,标签 <Letter> 与标签 <letter> 是不同的。必须使用相同的大小写来编写打开标签和关闭标签。
d). XML 中的注释语法:
<!-- This is a comment -->
e). XML 元素 vs. 属性
1 <person sex="female">
2 <firstname>Anna</firstname>
3 <lastname>Smith</lastname>
4 </person>
5
6 <person>
7 <sex>female</sex>
8 <firstname>Anna</firstname>
9 <lastname>Smith</lastname>
10 </person>
在第一行中,sex 是一个属性。在第7行中,sex 则是一个子元素。两个例子均可提供相同的信息。
2. xml 解析
xml解析方法有四种:
· DOM(JAXP Crimson 解析器):W3C为HTML和XML分析器制定的标准接口规范,基于树,可随机动态访问和更新文档的内容、结构、样式。
· SAX(simple API for XML):不是W3C的标准,而是由XML-DEV邮件列表成员于1998年为Java语言开发的一种基于事件的简单API。基于事件,逐行解析,顺序访问XML文档,速度快,处理功能简单。
· JDOM:鉴于DOM的低效率,而SAX又不能随机处理XML文档,Jason Hunter与Brett McLaughlin于2000年春天,开始创建一种能充分体现两者优势的API——JDOM(Java-based DOM,基于Java的DOM),它是一个基于Java的对象模型,树状结构,能使读取、操作和写入XML文档,比DOM更高效,比SAX更强大,但由于使用了大量的类而不使用接口导致灵活性降低。
· DOM4J:DOM4J是一个易用的,开源的库,用于XML,XPath,XSLT。它应用于Java平台,采用了Java集合框架并完全支持DOM,SAX,JAXP。它提供了大量的接口,因此比JDOM更具有灵活性。
2.1 DOM解析xml
DOM(Document Object Model文档对象模型),是W3C为HTML和XML分析器制定的标准接口规范。
特点:独立于语言,跨平台(可以在各种编程和脚本语言中使用),需要将整个文档读入内存,在内存中创建文档树,可随即访问文档中的特定节点,对内存的要求比较高,经过测试,访问速度相对于其他解析方式较慢,适用于简单文档的随即处理。
常用的节点属性:
|
属性 |
描述 |
|
nodeName |
结点名称 |
|
nodeValue |
结点内部值,通常只应用于文本结点 |
|
nodeType |
节点类型对应的数字 |
|
parentNode |
如果存在,指向当前结点的父亲结点 |
|
childNodes |
子结点列表 |
|
firstChild |
如果存在,指向当前元素的第一个子结点 |
|
lastChild |
如果存在,指向当前元素的最后一个子结点 |
|
previousSibling |
指向当前结点的前一个兄弟结点 |
|
nextSibling |
指向当前结点的后一个兄弟结点 |
|
attributes |
元素的属性列表 |
常用的节点方法:
|
操作类型 |
方法原型 |
描述 |
|
访问节点 |
getElementById(id) |
根据ID属性查找元素节点 |
|
getElementsByName(name) |
根据name属性查找元素集 |
|
|
getElementsByTagName(tagName) |
根据元素标记名称查找元素集 |
|
|
创建节点 |
createElement(tagName) |
创建元素节点 |
|
createTestNode(string) |
创建文本节点 |
|
|
createAttribute(name) |
创建属性节点 |
|
|
插入和添加节点 |
appendChild(newChild) |
添加子节点到目标节点上 |
|
insertBefore(newChild,targetChild) |
将newChild节点插入到targetChild节点之前 |
|
|
复制节点 |
CloneNode(bool) |
复制该节点,由bool确定是否复制子节点 |
|
删除和替换节点 |
removeChild(childName) |
删除由childName指定的节点 |
|
replaceChild(newChild,oldChild) |
用newChild替换oldChild |
|
|
属性节点操作 |
getAttribute(name) |
返回目标对象指定属性名称为name的属性值 |
|
setAttribute(name,value) |
修改目标节点指定属性名称为name的属性值为value |
|
|
removeAttribute(name) |
删除目标节点指定属性名称为name的属性 |
(1)读取本地xml文档解析为对象的步骤:
* 首先利用DocumentBuilderFactory创建一个DocumentBuilderFactory实例;然后利用DocumentBuilderFactory创建DocumentBuilder
//创建DocumentBuilderFactory工厂实例。
DocumentBuilderFactory dbfactory = DocumentBuilderFactory.newInstance();
//通过文档创建工厂创建文档创建器
DocumentBuilder dBuilder = dbfactory.newDocumentBuilder();
* 然后加载XML文档(Document) : 通过文档创建器DocumentBuilder的parse方法解析参数URL指定的XML文档,并返回一个Document 对象。
Document doc = dBuilder.parse(url);
* 然后获取文档的根结点(Element),
* 然后获取根结点中所有子节点的列表(NodeList),
* 然后使用再获取子节点列表中的需要读取的结点。
实例:第一种:Dom解析 (读取,增,删,改)
在实际开发中多思考,灵活运用,非是难事儿!,对于程序员来讲,精彩的代码是如何想出来的,远比看到精彩的代码更加令人期望!
books.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<books>
<book typeId="1">
<bookId>001</bookId>
<bookName>Maven实战</bookName>
<bookPrice>51</bookPrice>
<bookAuthor>陈晓斌</bookAuthor>
</book>
<book typeId="2">
<bookId>002</bookId>
<bookName>谈谈支付宝底层体系架构的大家</bookName>
<bookPrice>151</bookPrice>
<bookAuthor>程立</bookAuthor>
</book>
<book TypeId="3">
<bookId>003</bookId>
<bookName>预约死亡</bookName>
<bookPrice>99</bookPrice>
<bookAuthor>毕淑敏</bookAuthor>
</book>
<book TypeId="3">
<bookId>003</bookId>
<bookName>预约死亡</bookName>
<bookPrice>56</bookPrice>
<bookAuthor>毕淑敏</bookAuthor>
</book>
</books>
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Result;
import javax.xml.transform.Source;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList; public class Test {
/**
* XML读取
* @throws Exception
*/
public static void xml() throws Exception{
//1.构建一个工厂
DocumentBuilderFactory dbFactory =DocumentBuilderFactory.newInstance();
//2.构建builder1
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//3.Document对象
//一般放相对路径就可以了,程序自动在项目下寻址
Document document = dbBuilder.parse("books.xml");
//4.XML解析
NodeList list =document.getElementsByTagName("book");
for (int i = 0; i < list.getLength(); i++) {
Element item = (Element)list.item(i);
String attribute=item.getAttribute("typeId");
String bookId=item.getElementsByTagName("bookId").item(0).getTextContent();
String bookName=item.getElementsByTagName("bookName").item(0).getTextContent();
String bookPrice=item.getElementsByTagName("bookPrice").item(0).getTextContent();
String bookAuthor=item.getElementsByTagName("bookAuthor").item(0).getTextContent();
System.out.println(bookId);
System.out.println(bookName);
System.out.println(bookPrice);
System.out.println(bookAuthor);
//System.out.println(attribute);
System.out.println("-----------------");
}
}
/**
* XML添加
* @throws Exception
*/
public static void insert() throws Exception{
//1.构建一个工厂
DocumentBuilderFactory dbFactory =DocumentBuilderFactory.newInstance();
//2.构建builder1
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//3.Document对象
Document document = dbBuilder.parse("books.xml");
//1.伪造内存中的节点,游离节点
Element book = document.createElement("book");
book.setAttribute("TypeId", "3");
Element bookId=document.createElement("bookId");
bookId.setTextContent("003");
Element bookName = document.createElement("bookName");
bookName.setTextContent("预约死亡");
Element bookPrice = document.createElement("bookPrice");
bookPrice.setTextContent("56");
Element bookAuthor = document.createElement("bookAuthor");
bookAuthor.setTextContent("毕淑敏");
book.appendChild(bookId);
book.appendChild(bookName);
book.appendChild(bookPrice);
book.appendChild(bookAuthor); //1.将Book节点和整篇文档建立关联
document.getElementsByTagName("books").item(0).appendChild(book);
//1.传输工厂
TransformerFactory transformerFactory = TransformerFactory.newInstance();
//2.传输器
Transformer transformer = transformerFactory.newTransformer();
Source source = new DOMSource(document);
StreamResult result = new StreamResult("books.xml");
//3.传输方法
transformer.transform(source, result);
System.out.println("save ok!");
}
/**
* XML修改
* @throws Exception
*/
public static void update() throws Exception{
//1.构建一个工厂
DocumentBuilderFactory dbFactory =DocumentBuilderFactory.newInstance();
//2.构建builder1
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//3.Document对象
Document document = dbBuilder.parse("books.xml");
//修改指定item的书的价格
//"E:/eclispsespace/JavaOOP-Day-09-0100/books.xml"
Element book = (Element)document.getElementsByTagName("book").item(2);
book.getElementsByTagName("bookPrice").item(0).setTextContent("99");
//传输工程
TransformerFactory transformerFactory = TransformerFactory.newInstance();
//传输器
Transformer transformer =transformerFactory.newTransformer();
Source source = new DOMSource(document);
Result result = new StreamResult("books.xml");
transformer.transform(source, result);
System.out.println("修改完毕!");
}
/**
* XML删除
* @throws Exception
*/
public static void delXml() throws Exception{
//1.构建一个工厂
DocumentBuilderFactory dbFactory =DocumentBuilderFactory.newInstance();
//2.构建builder1
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//3.Document对象
//一般放相对路径就可以了,程序自动在项目下寻址
Document document = dbBuilder.parse("books.xml");
Element book = (Element)document.getElementsByTagName("book").item(2);
document.getElementsByTagName("books").item(0).removeChild(book);
//传输工程
TransformerFactory transformerFactory = TransformerFactory.newInstance();
//传输器
Transformer transformer = transformerFactory.newTransformer();
Source source = new DOMSource(document);
Result result =new StreamResult("books.xml");
transformer.transform(source, result);
System.out.println("删除成功!"); }
public static void main(String[] args) throws Exception {
//xml();//读取
//insert();//增加
//update();//修改
delXml() ;//删除 } }
第二种:使用Dom4j解析XML
Dom4j:
Dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的。dom4j是一个十分优秀的JavaXML API,具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件,可以在SourceForge上找到它。在IBM developerWorks上面还可以找到一篇文章,对主流的Java XML API进行的性能、功能和易用性的评测,所以可以知道dom4j无论在哪个方面都是非常出色的。如今可以看到越来越多的Java软件都在使用dom4j来读写XML,特别值得一提的是连Sun的JAXM也在用dom4j。这已经是必须使用的jar包,Hibernate也用它来读写文件。
所需jar包:dom4j-1.6.1.jar
实例图:
XML文件:
<?xml version="1.0" encoding="UTF-8"?>
<people city="beijing">
<student name="milton" age="22"></student>
<student name="lego" age="23"></student>
<teacher name="bruce" age="27"></teacher>
<teacher name="ziven" age="29"></teacher>
</people>
对应entity:
People类:

Student类:
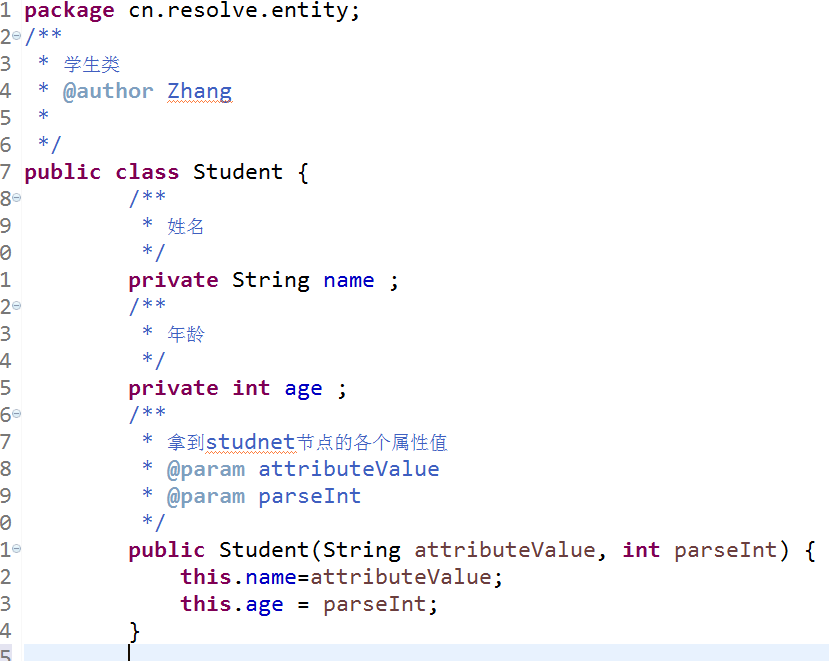
Teacher类:
TestXml类:
package cn.resolve.dom4j;
import java.io.File;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import cn.resolve.entity.People;
import cn.resolve.entity.Student;
import cn.resolve.entity.Teacher;
/**
* 测试使用dom4j解析XML
* @author Zhang
*
*/
public class TestXml {
public static People xmlParse(String xmlPath){
File xmlFile = new File(xmlPath);
System.out.println(xmlFile.getPath());
//判断文件是否存在
if (xmlFile.exists()) {
SAXReader reader = new SAXReader();
People people = new People();
try {
//读入文档流
Document document = reader.read(xmlFile);
//获取根节点
Element root =document.getRootElement();
//创建两个对象集合
List<Student> students = new ArrayList<Student>();
List<Teacher> teachers = new ArrayList<Teacher>();
//拿到attribute属性的值
people.setCity(root.attributeValue("city"));
//解析student节点
for (Iterator iterator = root.elementIterator("student");iterator.hasNext();) {
Element eStudent= (Element)iterator.next();
Student student = new Student(eStudent.attributeValue("name"),Integer.parseInt(eStudent.attributeValue("age")));
//添加到集合
students.add(student);
}
//解析teacher节点
for (Iterator iterator= root.elementIterator("teacher");iterator.hasNext();) {
Element eTeacher = (Element)iterator.next();
Teacher teacher = new Teacher(eTeacher.attributeValue("name"),Integer.parseInt(eTeacher.attributeValue("age")));
teachers.add(teacher);
}
people.setStudent(students);
people.setTeacher(teachers);
System.out.println("success!");
} catch (DocumentException e) {
e.printStackTrace();
}
return people;
}else {
System.out.println("file is not exist!");
return null;
}
}
public static void main(String[] args) {
String xmlpath = "src/people.xml";
//解析people.xml
People people =xmlParse(xmlpath);
System.out.println("file full path is xmlpath ");
List<Teacher> teachers = new ArrayList<Teacher>();
List<Student> students = new ArrayList<Student>();
System.out.println(people.getCity());
//处理解析结果
for (Student s : students) {
System.out.println("学生姓名/t/t年龄");
System.out.println(s.getName()+":"+s.getAge());
}
for (Teacher t: teachers) {
System.out.println("教师姓名/t/t年龄");
System.out.println();
}
}
}
JavaXML解析的四种方法(连载)的更多相关文章
- 解析Xml四种方法
关键字:Java解析xml.解析xml四种方法.DOM.SAX.JDOM.DOM4j.XPath [引言] 目前在Java中用于解析XML的技术很多,主流的有DOM.SAX.JDOM.DOM4j,下文 ...
- IOS中Json解析的四种方法
作为一种轻量级的数据交换格式,json正在逐步取代xml,成为网络数据的通用格式. 有的json代码格式比较混乱,可以使用此“http://www.bejson.com/”网站来进行JSON格式化校验 ...
- 【转】IOS中Json解析的四种方法
原文网址:http://blog.csdn.net/enuola/article/details/7903632 作为一种轻量级的数据交换格式,json正在逐步取代xml,成为网络数据的通用格式. 有 ...
- XML解析的四种方法 建议使用demo4j解析 测试可以用
https://www.cnblogs.com/longqingyang/p/5577937.html 4.DOM4J解析 特征: 1.JDOM的一种智能分支,它合并了许多超出基本XML文档表示的功 ...
- java解析XML四种方法
XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML. XML现在已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便 ...
- Java学习之路:详细解释Java解析XML四种方法
XML如今已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便. 对于XML本身的语法知识与技术细节,须要阅读相关的技术文献,这里面包含的内容有DO ...
- 【Java】详解Java解析XML的四种方法
XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML.本文将详细介绍用Java解析XML的四种方法. AD: XML现在已经成为一种通用的数据交换格式,它的平台无关性,语 ...
- Java解析XML的四种方法详解 - 转载
XML现在已经成为一种通用的数据交换格式,平台的无关性使得很多场合都需要用到XML.本文将详细介绍用Java解析XML的四种方法 在做一般的XML数据交换过程中,我更乐意传递XML字符串,而不是格式化 ...
- 织梦DedeCMS模板防盗的四种方法
织梦(DedeCMS)模板也是一种财富,不想自己辛辛苦苦做的模板被盗用,在互联网上出现一些和自己一模一样的网站,就需要做好模板防盗.本文是No牛收集整理自网络,不过网上的版本都没有提供 Nginx 3 ...
随机推荐
- IntelliJ IDEA竟然出了可以在云端编码的功能?
前言 自从我用了正版的IntelliJ IDEA后,基本上都是与时俱进,出一个新版本就立马更新,这也能能让我体验到最新最快的功能. 最近在闲逛Jetbrains的官网时,看到了最新的2021.3EAP ...
- 微信公众号生成海报(uniapp)
前言 这几天接到一个需求,要在公众号内生成分享海报.之前有做过H5和小程序的,心想直接复制过来就行了.没想到踩了不少的坑,搞了好几天终于搞好了,特此分享一下,希望能对大家有所帮助. 效果图 代码实现 ...
- [gym102412D]The Jump from Height of Self-importance to Height of IQ Level
考虑使用平衡树维护该序列,操作显然可以用fhq treap的分裂+合并来实现 进一步的,问题即变为维护哪些信息来支持push up的操作(并判定是否存在$a_{i}<a_{j}<a_{k} ...
- 高并发异步解耦利器:RocketMQ究竟强在哪里?
上篇文章消息队列那么多,为什么建议深入了解下RabbitMQ?我们讲到了消息队列的发展史: 并且详细介绍了RabbitMQ,其功能也是挺强大的,那么,为啥又要搞一个RocketMQ出来呢?是重复造轮子 ...
- watch异步操作
异步操作: 1.ajax, 2.定时器 3.点击事件 4.数据库操作 特点:代码不等待,后续代码会继续执行. watch:{ //watch作用监测已经存在的数据 newVal 新值,oldVal 旧 ...
- BFS实现迷宫问题
BFS实现迷宫问题 问题描述,要求从起点走到终点,找出最短的距离,要避开障碍 输入描述,输入一个二维数组表示地图,其中等于10就是终点,等于-10就是起点,等于1就是障碍,等于0就是可以走的 代码: ...
- Abp Vnext Blazor替换UI组件 集成BootstrapBlazor(详细过程)
Abp Vnext自带的blazor项目使用的是 Blazorise,但是试用后发现不支持多标签.于是想替换为BootstrapBlazor. 过程比较复杂,本人已经把模块写好了只需要替换掉即可. 点 ...
- Redis线程模型的前世今生
一.概述 众所周知,Redis是一个高性能的数据存储框架,在高并发的系统设计中,Redis也是一个比较关键的组件,是我们提升系统性能的一大利器.深入去理解Redis高性能的原理显得越发重要,当然Red ...
- 面向对象编程之Python学习一
在实际的程序设计中,使用Java面向对象编程方法编写算法能够很清楚的理解其来龙去脉. 习惯了面向对象思维,学习Python也自然使用这种思维. 目前,由于Python很多软件包能够容易的获取和利用,人 ...
- 洛谷 P4887 -【模板】莫队二次离线(第十四分块(前体))(莫队二次离线)
题面传送门 莫队二次离线 mol ban tea,大概是这道题让我第一次听说有这东西? 首先看到这类数数对的问题可以考虑莫队,记 \(S\) 为二进制下有 \(k\) 个 \(1\) 的数集,我们实时 ...