Cosmos OpenSSD--greedy_ftl1.2.0(二)
FTL的整个流程如下:

下面先来看写的流程:
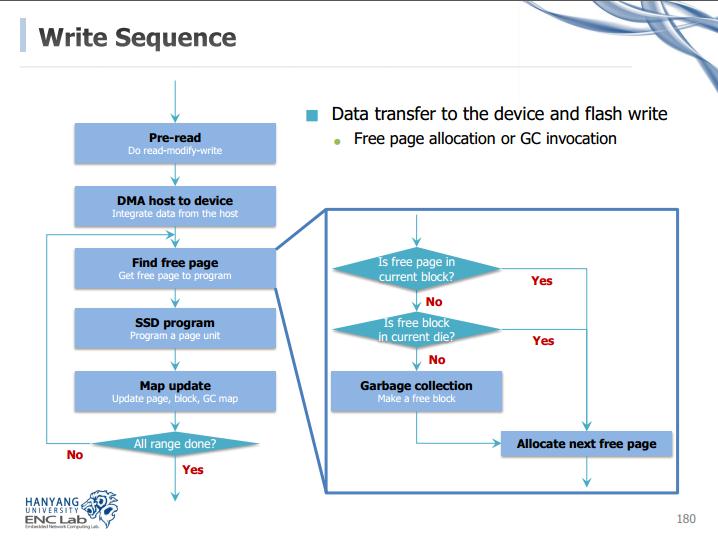
写的代码如下:
if((hostCmd.reqInfo.Cmd == IDE_COMMAND_WRITE_DMA) || (hostCmd.reqInfo.Cmd == IDE_COMMAND_WRITE))
{
// xil_printf("write(%d, %d)\r\n", hostCmd.reqInfo.CurSect, hostCmd.reqInfo.ReqSect); PrePmRead(&hostCmd, RAM_DISK_BASE_ADDR); deviceAddr = RAM_DISK_BASE_ADDR + (hostCmd.reqInfo.CurSect % SECTOR_NUM_PER_PAGE)*SECTOR_SIZE;
reqSize = hostCmd.reqInfo.ReqSect * SECTOR_SIZE;
scatterLength = hostCmd.reqInfo.HostScatterNum; DmaHostToDevice(&hostCmd, deviceAddr, reqSize, scatterLength); PmWrite(&hostCmd, RAM_DISK_BASE_ADDR); CompleteCmd(&hostCmd);
}
首先来看PrePmRead,其中最开始会涉及一个FlushPageBuf函数,FlushPageBuf里面有个FindFreePage函数,所以我们先分析FindFreePage函数的功能
lpn = hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE;
u32 dieNo = lpn % DIE_NUM;
这里传入一个dieNo参数
int FindFreePage(u32 dieNo)
{
blockMap = (struct bmArray*)(BLOCK_MAP_ADDR);
dieBlock = (struct dieArray*)(DIE_MAP_ADDR); if(blockMap->bmEntry[dieNo][dieBlock->dieEntry[dieNo].currentBlock].currentPage == PAGE_NUM_PER_BLOCK-) //当前块已经写完最后一页,则用下一个block
{
dieBlock->dieEntry[dieNo].currentBlock++; int i;
for(i=dieBlock->dieEntry[dieNo].currentBlock ; i<(dieBlock->dieEntry[dieNo].currentBlock + BLOCK_NUM_PER_DIE) ; i++) /*遍历整个die的所有block,到结尾之后又从开始找,直到找到一个可用的block*/
{
if((blockMap->bmEntry[dieNo][i % BLOCK_NUM_PER_DIE].free) && (!blockMap->bmEntry[dieNo][i % BLOCK_NUM_PER_DIE].bad)) //块free且不是坏块就可用
{
blockMap->bmEntry[dieNo][i % BLOCK_NUM_PER_DIE].free = ;
dieBlock->dieEntry[dieNo].currentBlock = i % BLOCK_NUM_PER_DIE; // xil_printf("allocated free block: %4d at %d-%d\r\n", dieBlock->dieEntry[dieNo].currentBlock, dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM); return dieBlock->dieEntry[dieNo].currentBlock * PAGE_NUM_PER_BLOCK; //返回页号
}
} dieBlock->dieEntry[dieNo].currentBlock = GarbageCollection(dieNo); //整个die没有可用块之后就进行垃圾回收 // xil_printf("allocated free block by GC: %4d at %d-%d\r\n", dieBlock->dieEntry[dieNo].currentBlock, dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM); return (dieBlock->dieEntry[dieNo].currentBlock * PAGE_NUM_PER_BLOCK) + blockMap->bmEntry[dieNo][dieBlock->dieEntry[dieNo].currentBlock].currentPage;
}
else //当前块还有页可用就直接接着上一页继续写
{
blockMap->bmEntry[dieNo][dieBlock->dieEntry[dieNo].currentBlock].currentPage++;
return (dieBlock->dieEntry[dieNo].currentBlock * PAGE_NUM_PER_BLOCK) + blockMap->bmEntry[dieNo][dieBlock->dieEntry[dieNo].currentBlock].currentPage;
}
}
由此可见,FindFreePage这个函数其实就是找一个可用的页,没有空间了就进行垃圾回收操作
接下来看上一级的函数FlushPageBuf
void FlushPageBuf(u32 lpn, u32 bufAddr)
{
if (lpn == 0xffffffff) //最开始page缓存内是没有东西的,所以无需flush
return; u32 dieNo = lpn % DIE_NUM; //计算出die number
u32 dieLpn = lpn / DIE_NUM; //计算出lpn在die中是第几个lpn,可以理解为die0上是lpn0,lpn16……对应为dieLpn0,dieLpn1
u32 ppn = pageMap->pmEntry[dieNo][dieLpn].ppn; if (ppn == 0xffffffff) //表示page缓存还没有写入ppn
{
u32 freePageNo = FindFreePage(dieNo); // xil_printf("free page: %6d(%d, %d, %4d)\r\n", freePageNo, dieNo%CHANNEL_NUM, dieNo/CHANNEL_NUM, freePageNo/PAGE_NUM_PER_BLOCK); WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdProgram(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, freePageNo, bufAddr);
WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM); // pageMap update
pageMap->pmEntry[dieNo][dieLpn].ppn = freePageNo;
pageMap->pmEntry[dieNo][freePageNo].lpn = dieLpn;
}
}
继续来看再上一级PrePmRead函数
int PrePmRead(P_HOST_CMD hostCmd, u32 bufferAddr)
{
u32 lpn;
u32 dieNo;
u32 dieLpn; pageMap = (struct pmArray*)(PAGE_MAP_ADDR);
lpn = hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE; if (lpn != pageBufLpn) //新的请求和上个请求不是同一个lpn
{
FlushPageBuf(pageBufLpn, bufferAddr);
上面这一段进行了FlushPageBuf操作
if((((hostCmd->reqInfo.CurSect)%SECTOR_NUM_PER_PAGE) != )
|| ((hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE) == (((hostCmd->reqInfo.CurSect)+(hostCmd->reqInfo.ReqSect))/SECTOR_NUM_PER_PAGE)))
{
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM; if(pageMap->pmEntry[dieNo][dieLpn].ppn != 0xffffffff)
{
// xil_printf("PrePmRead pdie, ppn = %d, %d\r\n", dieNo, pageMap->pmEntry[dieNo][dieLpn].ppn); WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdRead(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, pageMap->pmEntry[dieNo][dieLpn].ppn, bufferAddr);
WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM); pageBufLpn = lpn;
}
}
}
疑问:这个判断条件第一个是请求开端不要是每个lpn的开始,第二个是请求的大小在同一页,那么这个条件就是只要满足不是请求跨页且从一个lpn的开始的就进入判断?有什么实际意义呢?
答:这里很关键,涉及一段数据,假如开始的地方没有和page对齐的话,那么在每个page里面请求开始前面的数据就得先读出来,如果是缓存命中的话,就无需操作,因为可以直接修改,那么没命中的话,即使是page对齐了,如果数据没有跨页的话,也还是要读出来,不然请求末尾内page的内容就丢失了。如下图
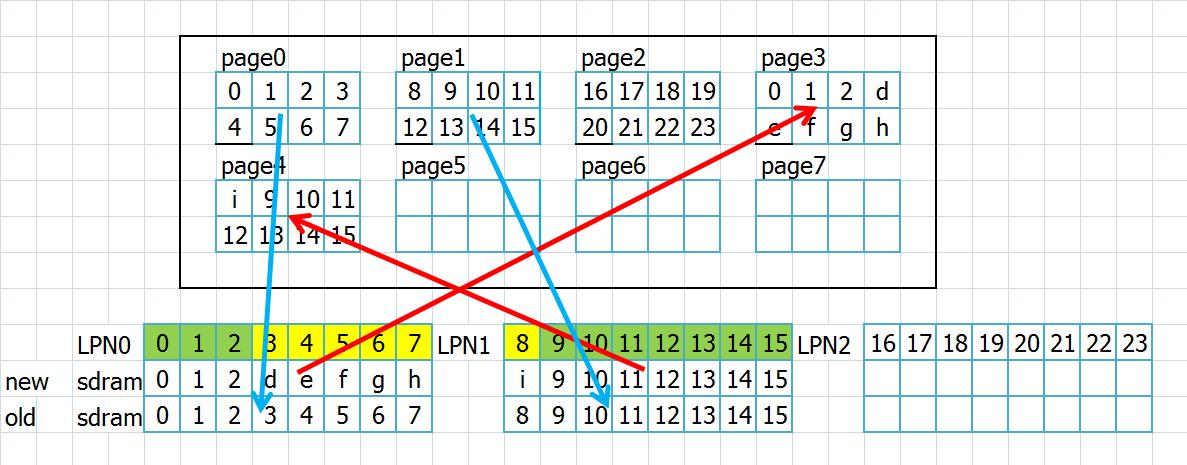
假如我要改写345678这些数据,因为数据是按页保存的,所以我只修改这些数据的话,我还得绿色部分的读取出来,然后修改后一起保存到一个页里面,所以请求的开始的lpn如果不是页对齐,我就得read-modify-write,同理,即使页对齐了,但是数据不足一页,那么一页后面几项数据也得先读出来。如果对齐且大小刚好等于一页的话,if失败,这个时候一页也是刚好可以直接修改。至于中间页的数据,本来就是一整页的,所以直接把原来的页无效,然后写入新页即可。这里这个判断条件是在页缓存没有命中的情况下,如果命中了,因为此页还没有刷新到nandflash,所以就无需取出而直接在SDRAM里面修改就行了
if(((((hostCmd->reqInfo.CurSect)+(hostCmd->reqInfo.ReqSect))% SECTOR_NUM_PER_PAGE) != )
&& ((hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE) != (((hostCmd->reqInfo.CurSect)+(hostCmd->reqInfo.ReqSect))/SECTOR_NUM_PER_PAGE)))
{
lpn = ((hostCmd->reqInfo.CurSect)+(hostCmd->reqInfo.ReqSect))/SECTOR_NUM_PER_PAGE;
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM; if(pageMap->pmEntry[dieNo][dieLpn].ppn != 0xffffffff)
{ // xil_printf("PrePmRead pdie, ppn = %d, %d\r\n", dieNo, pageMap->pmEntry[dieNo][dieLpn].ppn); WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdRead(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, pageMap->pmEntry[dieNo][dieLpn].ppn,
bufferAddr + ((((hostCmd->reqInfo.CurSect)% SECTOR_NUM_PER_PAGE) + hostCmd->reqInfo.ReqSect)/SECTOR_NUM_PER_PAGE*PAGE_SIZE));
WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
}
} return ;
}
上面是头,那这一部分就是尾,尾部如果不是请求对齐到page尾的话,那么也会有数据得不到更新,就如同上图lpn1的9到15,要把page内没修改的数据一起读出来更新,这里不仅是要不是结尾,而且是要跨页,这里分几种情况,假如缓存命中,没有跨页的话直接更新缓存就行了,只有跨页了,才需要进行read-modify-write操作;假如缓存没有命中,系统先把之前的缓存flush到nandflash里面,如果此时数据没有跨页的话,那么上面的操作就已经会读取那个页,也就无需下面再多此一举了,具体的写操作可以看下一篇文档。
接下来来看真正的写操作PmWrite
int PmWrite(P_HOST_CMD hostCmd, u32 bufferAddr)
{
u32 tempBuffer = bufferAddr; u32 lpn = hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE; int loop = (hostCmd->reqInfo.CurSect % SECTOR_NUM_PER_PAGE) + hostCmd->reqInfo.ReqSect; u32 dieNo;
u32 dieLpn;
u32 freePageNo; pageMap = (struct pmArray*)(PAGE_MAP_ADDR); // page buffer utilization
if (lpn != pageBufLpn)
pageBufLpn = lpn; UpdateMetaForOverwrite(lpn); // pageMap update
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM;
pageMap->pmEntry[dieNo][dieLpn].ppn = 0xffffffff; //写入一页不立即更新 lpn++;
tempBuffer += PAGE_SIZE;
loop -= SECTOR_NUM_PER_PAGE; while(loop > ) //接下来还有页请求的话,寻找新页,写入,更新页表
{
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM;
freePageNo = FindFreePage(dieNo); // xil_printf("free page: %6d(%d, %d, %4d)\r\n", freePageNo, dieNo%CHANNEL_NUM, dieNo/CHANNEL_NUM, freePageNo/PAGE_NUM_PER_BLOCK); WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdProgram(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, freePageNo, tempBuffer); UpdateMetaForOverwrite(lpn); // pageMap update
pageMap->pmEntry[dieNo][dieLpn].ppn = freePageNo;
pageMap->pmEntry[dieNo][freePageNo].lpn = dieLpn; lpn++;
tempBuffer += PAGE_SIZE;
loop -= SECTOR_NUM_PER_PAGE;
} int i;
for(i= ; i<DIE_NUM ; ++i)
WaitWayFree(i%CHANNEL_NUM, i/CHANNEL_NUM); return ;
}
接下来看读
int PmRead(P_HOST_CMD hostCmd, u32 bufferAddr)
{
u32 tempBuffer = bufferAddr; u32 lpn = hostCmd->reqInfo.CurSect / SECTOR_NUM_PER_PAGE;
int loop = (hostCmd->reqInfo.CurSect % SECTOR_NUM_PER_PAGE) + hostCmd->reqInfo.ReqSect; u32 dieNo;
u32 dieLpn; pageMap = (struct pmArray*)(PAGE_MAP_ADDR); if (lpn == pageBufLpn) //缓存命中,就无需读取第一页,直接就在内存里面
{
lpn++;
tempBuffer += PAGE_SIZE;
loop -= SECTOR_NUM_PER_PAGE;
}
else
{
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM; if(pageMap->pmEntry[dieNo][dieLpn].ppn != 0xffffffff) //防止第一次读空页
{
FlushPageBuf(pageBufLpn, bufferAddr);
pageBufLpn = lpn;
}
} while(loop > ) //把接下来的页一次读取出来
{
dieNo = lpn % DIE_NUM;
dieLpn = lpn / DIE_NUM; // xil_printf("requested read lpn = %d\r\n", lpn);
// xil_printf("read pdie, ppn = %d, %d\r\n", dieNo, pageMap->pmEntry[dieNo][dieLpn].ppn); if(pageMap->pmEntry[dieNo][dieLpn].ppn != 0xffffffff)
{
// xil_printf("read at (%d, %2d, %4x)\r\n", dieNo%CHANNEL_NUM, dieNo/CHANNEL_NUM, pageMap->pmEntry[dieNo][dieLpn].ppn); WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdRead(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, pageMap->pmEntry[dieNo][dieLpn].ppn, tempBuffer);
} lpn++;
tempBuffer += PAGE_SIZE;
loop -= SECTOR_NUM_PER_PAGE;
} int i;
for(i= ; i<DIE_NUM ; ++i)
WaitWayFree(i%CHANNEL_NUM, i/CHANNEL_NUM); return ;
}
Cosmos OpenSSD--greedy_ftl1.2.0(二)的更多相关文章
- ASP.NET Core 3.0 : 二十四. 配置的Options模式
上一章讲到了配置的用法及内部处理机制,对于配置,ASP.NET Core还提供了一种Options模式.(ASP.NET Core 系列目录) 一.Options的使用 上一章有个配置的绑定的例子,可 ...
- ASP.NET Core 3.0 : 二十八. 在Docker中的部署以及docker-compose的使用
本文简要说一下ASP.NET Core 在Docker中部署以及docker-compose的使用 (ASP.NET Core 系列目录). 系统环境为CentOS 8 . 打个广告,求职中.. 一 ...
- Visual Studio 2019 使用.Net Core 3.0 二
一.遇到难题 在微软官方逛了一圈,看到了这个. 马上点击,进去看看什么情况. 1.安装previewVisual studio 2019 2.设置SDK previews in Visual Stud ...
- scratch3.0二次开发scratch3.0基本介绍(第一章)
为什么要自己开发而不使用官方版本? 这个问题要看我们的做少儿编程教育的需求是怎么样的. scratch本身提供了离线版本以及官网在线平台供我们使用,这足以满足我们对于编程教学模块的需求.但是对于一些教 ...
- CRMEB小程序商城v4.0二次开发对接集成阿里云短信
作者:廖飞 - CRMEB小程序商城研发项目组长 前言 cremb小程序商城v4.0版本支持短信平台为云信,但有部分用户有需求对接阿里云短信,这篇文章将对阿里云短信平台如何对接方以及对接流程详细说明. ...
- Linux 下从头再走 GTK+-3.0 (二)
仅仅创建一个空白窗口是不够的,下面我们为创建的窗口添加一个按钮. 以 Hello,World!为例. 首先创建一个源文件:example2.c 内容如下. #include <gtk/gtk.h ...
- struct{0}二
一直以为 ]={};是把a的所有元素初始化为0,]={};是把a所有的元素初始化为1. 调试的时查看内存发现不是那么一回事,翻了一下<The C++ Programming Language&g ...
- Cosmos OpenSSD架构分析--FSC
接口速度: type bw read 75μs 1s/75μs*8k/1s=104m/s write 1300μs 1s/1300μs*8k/1s=6m/s erase 3.8ms 1s/ ...
- Spring Boot 2.0(二):Spring Boot 2.0尝鲜-动态 Banner
Spring Boot 2.0 提供了很多新特性,其中就有一个小彩蛋:动态 Banner,今天我们就先拿这个来尝尝鲜. 配置依赖 使用 Spring Boot 2.0 首先需要将项目依赖包替换为刚刚发 ...
- spring boot2.0(二 ) lettcute访问redis
前言 此处已经省略redis的安装,请自行百度查找redis的服务端安装过程. 1.pom文件配置: <project xmlns="http://maven.apache.org/P ...
随机推荐
- 201521123074 《Java程序设计》第9周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 Q1.常用异常 题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自 ...
- Java:输入输出流 java.io包的层次结构
1.什么是IO Java中I/O操作主要是指使用Java进行输入,输出操作. Java所有的I/O机制都是基于数据流进行输入输出,这些数据流表示了字符或者字节数据的流动序列.Java的I/O流提供了读 ...
- Eclipse rap 富客户端开发总结(8) : 发布到tomcat后解决rap编码和字符集的问题
1 .解决 rap 字符集乱码的问题 字符集问题,解决办法: 在plugin.xml - build.properties 中添加 javacDefaultEncoding.. = UTF-8 ...
- [07] ServletContext上下文对象
1.上下文的概念 我们在说到Servlet的继承关系时,提到自定义Servlet实际上间接实现了Servlet和ServletConfig两个接口,其中ServletConfig接口中定义了一个方法叫 ...
- Socket类 以及 ServerSocket类 讲解
Socket类 套接字是网络连接的端点,套接字使应用可以从网络中读取数据,可以向网络中写入数据.不同计算机上的两个应用程序可以通过连接发送或接收字节流,以此达到相互通信的目的. 为了从一个应用程序向另 ...
- 升级与修改Nginx
自从上次安装了Nginx后,学到了很多新的东西,比如http2.0... 而且还发现nginx还出了新版本,遂决定升级下,还是那个URL,下载最新版. ./configure --user=www - ...
- SpringMVC的数据格式化-注解驱动的属性格式化
一.什么是注解驱动的属性格式化? --在bean的属性中设置,SpringMVC处理 方法参数绑定数据.模型数据输出时自动通过注解应用格式化的功能. 二.注解类型 1.DateTimeFormat @ ...
- mongodb 常用的命令
mongodb 常用的命令 对数据库的操作,以及登录 1 进入数据库 use admin 2 增加或修改密码 db.addUser('wsc', '123') 3查看用户列表 db.system.us ...
- HDU-3032
Problem Description Nim is a two-player mathematic game of strategy in which players take turns remo ...
- Java笔记—— 类与对象的几个例子
问题1 按要求编写java应用程序: 编写西游记人物类,属性有:身高,名字和武器.方法有:显示名字,显示武器. 在main方法中创建两个对象.猪八戒和孙悟空,并分别为他们的两个属性名字和武器赋值,最后 ...