SQLServer 索引总结
测试案例:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SET STATISTICS PROFILE ON
SELECT count(A.CarrierTrackingNumber) FROM SALES.SALESORDERDETAIL A
WHERE A.SalesOrderDetailID>10000 AND A.SalesOrderDetailID<10100
执行计划:

测试loopup 和索引查找:
第一步 走了扫描 和通过聚集索引查找 OutputList字段;
我们这里可以添加索引 不过建议创建包含索引;复合索引快 但是维护起来要复杂些,也影响性能;
我做了下比较:
CREATE NONCLUSTERED INDEX [IX_TEST] ON [Sales].[SalesOrderDetail]
(
[SalesOrderDetailID] ASC
)
INCLUDE ( [CarrierTrackingNumber]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
CREATE NONCLUSTERED INDEX [IX_TEST1] ON [Sales].[SalesOrderDetail]
(
[SalesOrderDetailID],[CarrierTrackingNumber] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
蓝色是包含索引,红色是复合索引,我们无论单独创建哪个索引他都会把第一步合成一个步骤索引查找;(就不截图了)
然后我们做下两者的速度;
DBCC FREEPROCCACHE

测试包含、联合索引:
查询优化器智能走向是test1 复合索引;
我们看下io开销:
包含索引test:

复合索引:

复合索引逻辑读是3,这个很好解释,因为联合索引的索引叶要比包含索引叶子大,包含索引是只是存储包含字段的一个指针,而复合是实际的值;
如果数据量很大,性能差距也很明显:
我们把条件改下,返回的结果集大点,然后下面一句我们使用强制索引,强制语句选择使用包含索引:

轻而易举我们发现ix_test1 联合索引 明显绝对性优势;
计算函数对索引影响:
SELECT count(A.CarrierTrackingNumber) FROM SALES.SALESORDERDETAIL A
WHERE CONVERT(NUMERIC(9,3),A.SALESORDERDETAILID/100)=100
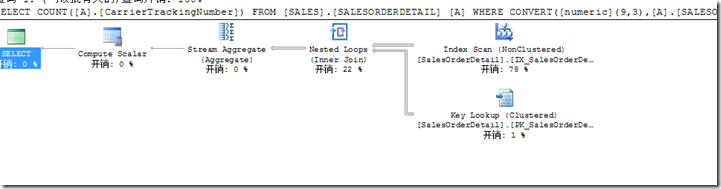
这个字段我们上面两个索引都加过了,结果错误的走向了[IX_SalesOrderDetail_ProductID]这个索引;
一般函数在’=’’<’’>’左侧不会走索引! 这个要修改语句逻辑了!
SCAN未必是很差的选择:
PKID 列上有个非聚集索引;
pkid=100093 有2万行数据;
pkid=10094 大概有10条结果;
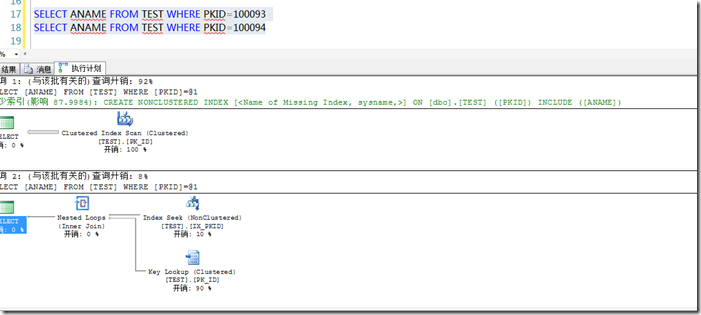
下图得到结果是pkid=100093走了聚集索引扫描,优化器认为这样比通过索引叶查询+聚集rid look 要快;
我们可以尝试下 很简单的测试:
SELECT ANAME FROM TEST with(index=ix_pkid) WHERE PKID=100093
SELECT ANAME FROM TEST WHERE PKID=100093

很显然 全表扫描要快;
我再补上IO次数;

差距是不是很明显,索引优化器还是比较很聪明;
还一点 我也顺便测试了
我把这个语句打包成存储过程,直接缓存到缓存中;我们看下效果:
CREATE PROC SCAN (@I INT)
AS
SELECT ANAME FROM TEST WHERE PKID=@I
DBCC FREEPROCCACHE
我们先执行这个数量少的给优化器看,骗她存入缓存计划;
exec scan 100094

当我们执行这个一般大概2次,sqlserer就会存入缓存当中;
开始测试第二个:
exec scan 100093


你看很好骗吧,太坑了!!!
我们重新编译下:
sp_recompile 'scan'
exec scan 100093
哪天优化器能识别优化这个就更厉害了!!

当然我们也有解决办法:
添加包含索引如下:
USE [AdventureWorks2014]
GO
CREATE NONCLUSTERED INDEX IDX_PKIDANAME ON [dbo].[TEST] ([PKID])
INCLUDE ([ANAME])
GO
这样结果就全是seek 了;具体问题具体分析了!
一般filter记录越早越好,对筛选条件SARG(SearchArgument)条件写法注意点:
走索引的SARG:
“列运算符<常量或变量>”
“<常量或变量>列运算符”
“=”
“<”
“>“
“>=”
“<=“
“IN”
”BETWEEN“
“LIKE ‘ABC%’”
”AND“
'50000'="SALESORDERID"
不走索引SARG:
NOT
<>
NOT EXISTS
NOT IN
NOT LIKE
CONVERT,UPPER
SQLServer 索引总结的更多相关文章
- SQLServer索引
SQLServer索引1.聚集和非聚集索引聚集索引:根据聚集索引进行排序,非聚集索引因为不根据索引键排序,所以聚集索引比非聚集索引快(一个表只有一个聚集索引)2.唯一索引和非唯一索引唯一索引时值不能重 ...
- mssql sqlserver 索引专题
摘要: 下文将详细讲述sql server 索引的相关知识,如下所示: 实验环境: sql server 2008 R2 sqlserver索引简介: mssql sqlsever 索引分类简介 ms ...
- sqlserver 索引的结构及其存储,索引内容
sqlserver 索引的结构及其存储,sql server索引内容 文章转载,原文地址: http://www.cnblogs.com/panchunting/p/SQLServer_IndexSt ...
- sqlserver 索引优化 CPU占用过高 执行分析 服务器检查
原文:sqlserver 索引优化 CPU占用过高 执行分析 服务器检查 1. 管理公司一台服务器,上面放的东西挺多的.有一天有个哥们告诉我现在程序卡的厉害.我给他说,是时候读点优化的书了.别一天到晚 ...
- 技术分享会(二):SQLSERVER索引介绍
SQLSERVER索引介绍 一.SQLSERVER索引类型? 1.聚集索引: 2.非聚集索引: 3.包含索引: 4.列存储索引: 5.无索引(堆表): 二.如何创建索引? 索引示例: 建表 creat ...
- sqlserver索引维护(重新组织生成索引)
sqlserver索引的维护 1:查看索引碎片大于百分三十以上的索引 select object_id= object_id,indexid = index_id,partitionnum = par ...
- SqlServer索引的原理与应用(转载)
SqlServer索引的原理与应用 索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类 ...
- SQLServer索引的四个高级特性
一Index Building Filter索引创建时过滤 二Index Include Column索引包含列 三聚集索引Cluster Index 四VIEW INDEX视图索引 SQLSer ...
- SqlServer索引的原理与应用
索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录 ...
- sqlserver索引小结
1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间 下面举两个简单的例子: 图书馆的例子:一个图书 ...
随机推荐
- Redis在centos6.4上的最详细图文安装教程
准备工作:一个redis3.0.0的安装包,没有可以点击下面的链接下载 https://pan.baidu.com/s/1kU5Ez2J 工具 安装环境 centos6.4 好了开始进入正题 输入 ...
- Linux基础-最基础
Linux基础 为了更好的学习知识,开通此博客,以前博客丢了...记录一下知识点,希望能在这里与大家互相学习交流. 20171113 14:00 Linux基础-基本知识 Linux树状文件系统结构 ...
- PCA, SVD以及代码示例
本文是对PCA和SVD学习的整理笔记,为了避免很多重复内容的工作,我会在介绍概念的时候引用其他童鞋的工作和内容,具体来源我会标记在参考资料中. 一.PCA (Principle component a ...
- 初学sheel脚本练习过程
以下是初学sheel脚本练习过程,涉及到内容的输出.基本的计算.条件判断(if.case).循环控制.数组的定义和使用.函数定义和使用 sheel脚本内容: #! /bin/bashecho &quo ...
- JDBC的使用
JDBC详解系列(一)之流程 ---[来自我的CSDN博客](http://blog.csdn.net/weixin_37139197/article/details/78838091)--- 使 ...
- react.js - 基于create-react-app的打包后文件根路径修改
用create-react-app脚手架搭建的react项目 使用 npm run build 之后生成的打包文件只能在根目录访问 这样放在服务器目录就访问不到了 报错为: 手动更改index.htm ...
- HBase1.0.1基本操作(java代码)
public class HQuery { private static ConnHBase connHbase=new ConnHBase(); /***************建表******** ...
- kafka入门样例 for java
1,生产者 import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.Key ...
- 调用接口http封装
public static String httpHandler(String URL,String xml){ try { URL url=new URL(URL); URLConnection c ...
- jQuery: $.extend()用法总结
1.重载原型 $.extend({},src1,src2,src3...) Jquery的扩展方法extend是我们在写插件的过程中常用的方法,该方法有一些重载原型. 它的含义是将src1,src2, ...