[Scikit-learn] 4.4 Dimensionality reduction - PCA
2.5. Decomposing signals in components (matrix factorization problems)
- 2.5.1. Principal component analysis (PCA)
4.4. Unsupervised dimensionality reduction
- 4.4.1. PCA: principal component analysis
PCA+ICA 解混过程:https://www.zhihu.com/question/28845451
一、PCA的理解
PCA是将n维特征映射到k维上(k<n),这k维特征是全新的正交特征,称为主元,
是重新构造出来的k维特征,而不是简单的从n维特征中去除其余n-k维特征。
最大方差理论
From: https://www.zhihu.com/question/40043805/answer/138429562
没错,PCA的基本假设是:数据集的分布是一个n维正态分布,并由此对协方差矩阵进行贝叶斯估计(其中期望这一参数被中心化消去了)。
然而n维正态分布的协方差矩阵能不能被进一步简化呢?可以,一个自然而然简化矩阵的手段就是SVD。事实上对于一个n维正态分布的协方差矩阵作SVD和PCA是等价的。
不过PCA并不仅仅是巧合般利用了SVD,
- PCA的本质是对于一个以矩阵为参数的分布进行似然估计,
- SVD是矩阵近似的有效手段,仅此而已。
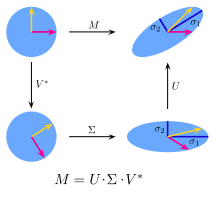
二、PCA的数学原理
Link: http://www.360doc.com/content/13/1124/02/9482_331688889.shtml
"发明一遍PCA"
(1). 基变换:旧坐标 --> 新坐标
单个坐标点
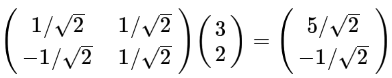
三个坐标点
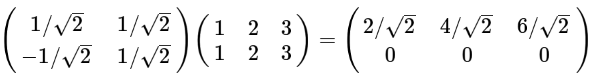
(2). 基的数量如果小于向量本身的维度
有两行,表示两个字段。
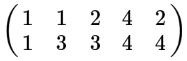
中心化后如下。

坐标表示。
关键思想:降为一维后,希望投影后的投影值尽量的分散。
- 使用方差度量分散度。
- 两个字段的协方差表示其相关性。
正对角线:两个字段的反差
反对角线: 协方差

三、举个栗子
简单例子
对该数据进行PCA降维。

工程例子
Ref: Faces recognition example using eigenfaces and SVMs
通常就是pca + gmm or pca+svm的模式;降维后方便线性可分。
当然,主特征最好是天然正交的!
# #############################################################################
# Split into a training set and a test set using a stratified k fold # split into a training and testing set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42) # #############################################################################
# Compute a PCA (eigenfaces) on the face dataset (treated as unlabeled
# dataset): unsupervised feature extraction / dimensionality reduction
n_components = 150 print("Extracting the top %d eigenfaces from %d faces"
% (n_components, X_train.shape[0]))
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True).fit(X_train)
print("done in %0.3fs" % (time() - t0)) eigenfaces =pca.components_.reshape((n_components, h, w)) print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in %0.3fs" % (time() - t0)) # Jeff
print(pca.components_.shape)
print(eigenfaces.shape)
如下可见,协方差矩阵只有前150行被采用,作为了主特征。
pca.components_
类型:array,[n_components,n_features]
意义:特征空间中的主轴,表示数据中最大方差的方向。按explain_variance_排序。
Extracting the top 150 eigenfaces from 912 faces
done in 0.228s
Projecting the input data on the eigenfaces orthonormal basis
done in 0.024s
(150, 1850)
(150, 50, 37)
这些恐怖头像表示什么意思?

def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
4.4.1. PCA: principal component analysis 的内容,可进一步深入。
四、主特征选择
Ref: 选择主成分个数
我们该如何选择  ,即保留多少个PCA主成分?在上面这个简单的二维实验中,保留第一个成分看起来是自然的选择。对于高维数据来说,做这个决定就没那么简单:如果 过大,数据压缩率不高,在极限情况
,即保留多少个PCA主成分?在上面这个简单的二维实验中,保留第一个成分看起来是自然的选择。对于高维数据来说,做这个决定就没那么简单:如果 过大,数据压缩率不高,在极限情况 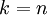 时,等于是在使用原始数据(只是旋转投射到了不同的基);相反地,如果 过小,那数据的近似误差太太。
时,等于是在使用原始数据(只是旋转投射到了不同的基);相反地,如果 过小,那数据的近似误差太太。
决定 值时,我们通常会考虑不同 值可保留的方差百分比。
具体来说,如果 ,那么我们得到的是对数据的完美近似,也就是保留了100%的方差,即原始数据的所有变化都被保留下来;相反,如果 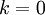 ,那等于是使用零向量来逼近输入数据,也就是只有0%的方差被保留下来。
,那等于是使用零向量来逼近输入数据,也就是只有0%的方差被保留下来。
一般而言,设 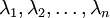 表示
表示 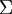 的特征值(按由大到小顺序排列),使得
的特征值(按由大到小顺序排列),使得 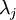 为对应于特征向量
为对应于特征向量 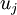 的特征值。那么如果我们保留前 个成分,则保留的方差百分比可计算为:
的特征值。那么如果我们保留前 个成分,则保留的方差百分比可计算为:
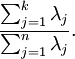
在上面简单的二维实验中,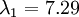 ,
,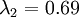 。因此,如果保留
。因此,如果保留 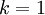 个主成分,等于我们保留了
个主成分,等于我们保留了 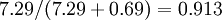 ,即91.3%的方差。
,即91.3%的方差。
对保留方差的百分比进行更正式的定义已超出了本教程的范围,但很容易证明,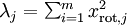 。因此,如果
。因此,如果 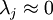 ,则说明
,则说明 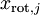 也就基本上接近于0,所以用0来近似它并不会产生多大损失。这也解释了为什么要保留前面的主成分(对应的 值较大)而不是末尾的那些。 这些前面的主成分 变化性更大,取值也更大,如果将其设为0势必引入较大的近似误差。
也就基本上接近于0,所以用0来近似它并不会产生多大损失。这也解释了为什么要保留前面的主成分(对应的 值较大)而不是末尾的那些。 这些前面的主成分 变化性更大,取值也更大,如果将其设为0势必引入较大的近似误差。
以处理图像数据为例,一个惯常的经验法则是选择 以保留99%的方差,换句话说,我们选取满足以下条件的最小 值:
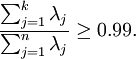
对其它应用,如不介意引入稍大的误差,有时也保留90-98%的方差范围。若向他人介绍PCA算法详情,告诉他们你选择的 保留了95%的方差,比告诉他们你保留了前120个(或任意某个数字)主成分更好理解。
五、Fisher Linear Discriminant Analysis (LDA)
补充:from http://blog.pluskid.org/?p=290
区分不同类别:[Scikit-learn] 1.2 Dimensionality reduction - Linear and Quadratic Discriminant Analysis
虽然 PCA 极力降低 reconstruction error ,试图得到可以代表原始数据的 components ,但是却无法保证这些 components 是有助于区分不同类别的。如果我们有训练数据的类别标签,则可以用 Fisher Linear Discriminant Analysis 来处理这个问题。
目的和作用
同 PCA 一样,Fisher Linear Discriminant Analysis 也是一个线性映射模型,只不过它的目标函数并不是 Variance 最大化,而是有针对性地使投影之后:
(1) 属于同一个类别的数据之间的 variance 最小化,
(2) 属于不同类别的数据之间的 variance 最大化。
具体的形式和推导可以参见《Pattern Classification》这本书的第三章 Component Analysis and Discriminants。
当然,很多时候(比如做聚类)我们并不知道原始数据是属于哪个类别的,此时 Linear Discriminant Analysis 就没有办法了。不过,如果我们假设原始的数据形式就是可区分的的话,则可以通过保持这种可区分度的方式来做降维。
MDS 是 PCA 之外的另一种经典的降维方法,它降维的限制就是要保持数据之间的相对距离。实际上 MDS 甚至不要求原始数据是处在一个何种空间中的,只要给出他们之间的相对“距离”,它就可以将其映射到一个低维欧氏空间中,通常是三维或者二维,用于做 visualization 。
End.
[Scikit-learn] 4.4 Dimensionality reduction - PCA的更多相关文章
- [UFLDL] Dimensionality Reduction
博客内容取材于:http://www.cnblogs.com/tornadomeet/archive/2012/06/24/2560261.html Deep learning:三十五(用NN实现数据 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- 可视化MNIST之降维探索Visualizing MNIST: An Exploration of Dimensionality Reduction
At some fundamental level, no one understands machine learning. It isn’t a matter of things being to ...
- 海量数据挖掘MMDS week4: 推荐系统之数据降维Dimensionality Reduction
http://blog.csdn.net/pipisorry/article/details/49231919 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 第八章——降维(Dimensionality Reduction)
机器学习问题可能包含成百上千的特征.特征数量过多,不仅使得训练很耗时,而且难以找到解决方案.这一问题被称为维数灾难(curse of dimensionality).为简化问题,加速训练,就需要降维了 ...
- 壁虎书8 Dimensionality Reduction
many Machine Learning problems involve thousands or even millions of features for each training inst ...
- 单细胞数据高级分析之初步降维和聚类 | Dimensionality reduction | Clustering
个人的一些碎碎念: 聚类,直觉就能想到kmeans聚类,另外还有一个hierarchical clustering,但是单细胞里面都用得不多,为什么?印象中只有一个scoring model是用kme ...
- Seven Techniques for Data Dimensionality Reduction
Seven Techniques for Data Dimensionality Reduction Seven Techniques for Data Dimensionality Reductio ...
随机推荐
- RobotFramework自动化测试框架-移动手机自动化测试Clear Text关键字的使用
Clear Text关键字用来清除输入框的数据,该关键字接收一个参数[ locator ],这里的locator指的就是界面元素的定位方式. 示例1:Clear Text清除输入框数据时,采用reso ...
- TestNG简介与安装步骤
简述 TestNG是一个设计用来简化广泛的测试需求的测试框架, 从单元测试(隔离测试一个类) 到集成测试(测试由有多个类多个包甚至多个外部框架组成的整个系统, 例如运用服务器) . testNG灵感来 ...
- 框架应用:Spring framework (四) - 事务管理
事务控制 事务是什么?事务控制? 事务这个词最早是在数据库中进行应用,讲的用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的工作单位. 事务的管理是指一个事务的开启,内容添加, ...
- Eclipse插件springsource-tool-suite在线和离线安装步骤
springsource-tool-suite插件是一个基于Eclipse的开发环境,为开发Spring应用程序而定制.它提供了一个即用的环境来实现,调试,运行和部署Spring应用程序,包括Pivo ...
- 跨Storyboard调用
在开发中我们会有这种需求从一个故事板跳到另一个故事板 modal UIStoryboard *secondStoryboard = [UIStoryboard storyboardWithName:@ ...
- Qt全局宏和变量
1. Qt 全局宏定义 Qt版本号: QT_VERSION : (major << 16) + (minor << 8) + patch 检测版本号: QT_VERSION ...
- React Router 按需加载+服务器渲染的闪屏问题
伴随着React协议的『妥协』(v16采用MIT),React为项目的主体,这个在短期内是不会改变的了,在平时使用过程中发现了如下这个问题: 在服务器渲染的时候,刷新页面会出现闪屏的现象(白屏一闪而过 ...
- 最长回文 hdu3068(神代码)
最长回文 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- SpringBoot初体验
1.elipse中创建Springboot项目并启动 具体创建步骤请参考:Eclipse中创建新的Spring Boot项目 2.项目的属性配置 a.首先我们在项目的resources目录下appli ...
- CLR via 随书笔记
CTS(common type system) 通用类型系统规定,一个类型可以包含零个或者多个成员,如下: 字段(Field): 作为对象状态一部分的数据变量.字段根据名称和类型来区分 方法( ...