Storm保证消息处理
Guaranteeing Message Processing
Storm保证每一个tuple被完全处理。Strom中一个核心的机制是它提供了一种跟踪tuple血统的能力,它使用了一种十分有效的方式跟踪topology中的tuple。
Storm中最基本的抽象是提供了至少一次(at-least-once)处理的保证,当你使用队列系统的时候也可以提供相同的保证。
Messages are only replayed when there are failures.(消息只有在失败的时候才会被重新投放)
Trident是在基本抽象之上的更高层面的抽象,它可以实现精准的只执行一次的处理。
对于保证消息处理,Storm提供了几种不同的级别,包括尽最大努力、至少一次处理、精确的一次处理。( best effort、at least once、exactly once)
一个消息被“完全处理”是什么意思?
从一个spout出来的一个tuple可能触发上千个tuples。考虑下面的例子:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
这个topology读取从一个Kestrel队列出来的句子,并且将句子分割成单词,然后发送每个单词已经它们出现的次数。从一个spout出来的一个tuple可能触发上千个tuples在这里的意思是:每个单词都是一个tuple,并且每个每个单词都要更新它们出现的次数。这个例子中,消息树可能看起来是这样的:

当这个tuple树被耗尽并且树中每个消息都已经被处理了,那么这个时候这个从一个spout出来的一个tuple被称之为“完全处理”。当一个消息树中的消息在指定的超时时间内没有被完全处理,则认为这个tuple失败了。默认的超时时间是30秒。
如果一个消息被完全处理或者失败了将会发生什么?
为了理解这个问题,让我们看一下从spout处理的一个tuple的生命周期。(let's take a look at the lifecycle of a tuple coming off of a spout)
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先,Storm通过在Spout中调用nextTuple方法从Spout中请求一个tuple。这个Spout使用open方法中提供的SpoutOutputCollector来发送一个tuple到其中一个streams。在发送一个tuple的时候,这个Spout提供一个“message id”用来表示这个tuple。发送消息的代码可能看起来是这样的:
_collector.emit(new Values("field1", "field2", 3) , msgId);
接下来,这个tuple达到bolt,并且Storm对于跟踪这个tuple的消息树很关心。如果Storm发现一个tuple被完全处理,那么Storm将会调用原始的那个带有message id的Spout中的ack方法。同样的,如果一个tuple超时,那么Storm将会调用那个Spout的fail方法。注意,一个tuple只能被创建它的那个Spout任务所acked或者failed。
让我们用KestrelSpout再回顾一遍Spout是怎样保证消息处理的。当KestrelSpout从Kestrel队列中消费了一个消息以后,它“opens”这个消息。意思是这个消息并没有实际的从队列中删除,代替的只是标记这个消息为“pending”状态,等待消息被完成以后的确认。处于pending状态的消息不会被发送给队列的其它消费者。另外,如果一个客户端连接断开了,那么它所持有的所有pending状态的消息将会被重新放回队列。当一个消息被打开的时候,Kestrel提供这个消息数据给客户端,并且给这个消息一个唯一的id。当发送tuple给SpoutOutputCollector的时候KestrelSpout用这个精确的id作为这个tuple的“message id”。随后,当这个KestrelSpout上的ack或者fail被调用的时候,这个KestrelSpout发送ack或者fail消息给Kestrel,同时还带上message id,以决定是从队列中删除这个消息还是将这个消息重新放回队列。
Storm的可靠性API是什么?
想要使用Storm的可靠性,有两件事情是你必须做的。第一,无论何时你在为一个tuple树创建一个新的链接的时候你必须告诉Storm。第二,你必须告诉Storm什么时候一个单个的tuple算是完成处理了。通过做以上两件事情,Storm就可以发现什么时候这个tuple的树是被完全处理了,并且在适当的时候ack或者fail这个tuple。Storm的API提供了一些简洁的方式来做上面说的这些事情。
Specifying a link in the tuple tree is called anchoring. Anchoring is done at the same time you emit a new tuple.
让我们用下面这个bolt作为例子来具体看一下:
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
Each word tuple is anchored by specifying the input tuple as the first argument to emit. Since the word tuple is anchored, the spout tuple at the root of the tree will be replayed later on if the word tuple failed to be processed downstream.(这段话的意思是,调用emit方法的时候指定它的第一个参数tuple的时候,这个被指定的tuple就被anchored了,一旦这个tuple被anchored以后它将作为它的消息tree的root,如果这个tuple在随后处理失败了,这个tuple会被重新投放)
与之相对的,我们再看一下下面这种发送方式:
_collector.emit(new Values(word));
这种方式会造成这个unanchored,也就是说,用这种方式的话tuple就不能被anchored。如果这个tuple在下游被处理失败了,那么根tuple不会被重新投放。根据你的系统的容错性要求来决定,有时候用一个unanchored的tuple也很合适。
一个输出tuple可以被anchored到多个输入tuple。在做stream的join或者聚集很有用。一个multi-anchored的tuple失败会造成多个tuple被重放。例如:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
DAG和tree是一回事,只是在先前的版本中叫tree。
当你已经完成了对tuple树中某一个tuple的处理的时候,你可以调用OutputCollector的ack或者fail方法。
你可以在OutputCollector中用fail方法来立即失败这个tuple。通过明确失败这个tuple,这个tuple可以被快速重放而不是等待这个tuple超时以后再重放。
你处理的每一个tuple都必须被acked或者failed。Storm用内存来跟踪每一个tuple,因此如果你不ack/fail每一个tuple,那么这个任务将会一直存在于内存中。
大量的bolts有相同的行为模式:它们读取一个输入tuple,然后基于这个tuple发送tuple,在execute方法的最后ack这个tuple。Storm有一个叫做BasicBolt的接口已经为你封装好了这种模式。下面这个例子就是:
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
这种实现方式比前面的例子中那种方式更简单,而且表达的语义完全相同。Tuple被发送给BasicOutputCollector的时候自动被anchored,并且输入tuple在execute方法执行完以后自动被acked。
考虑到tuple会被重放,我应该怎么做才能使我的应用正常工作?
视情况而定
Storm如何有效地实现可靠性?
一个Storm topology有一组特殊的“acker”任务跟踪每一个spout tuple的DAG(有向无环图)。当一个acker看到一个DAG被完成的时候,它一个消息给那个创建这个spout tuple的spout task来确认这个消息。你可以设置一个topology的acker任务的数量,默认是每个woker一个这样的task。
理解Storm的可靠性实现最好的方式就是看tuples的生命周期和tuple的DAG。当一个tuple在topology中被创建的时候,无论是在spout中还是在bolt中被创建,都会被指定一个64位的id。这些id被acker用来跟踪每个spout tuple的DAG。
当你在一个bolt中发送一个新的tuple的时候,已经被ahchored过的那些tuple的id会被复制到新的tuple中,因此,每一个tuple都知道它所在的tuple树中所有spout tuples的id。当tuple被确认的时候,它给acker任务发一个消息告诉acker这个tuple树怎样变化的。特别的,它会告诉acker“我现在已经这个spout tuple的树中完成了,这有一个新tuple被anchored”。
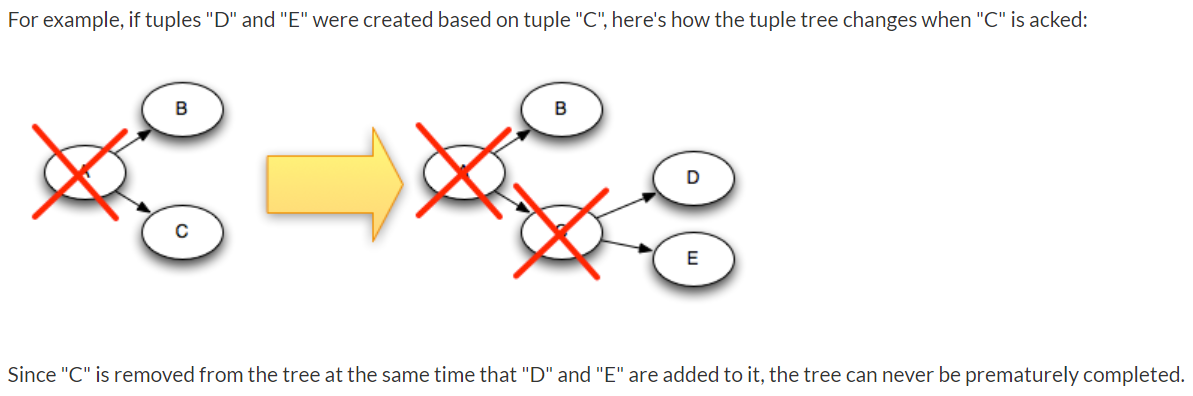
现在,你已经理解了可靠性的算法,让我们来复习一下所有失败的情况,并且看一下对于每一中情况Strom是如何避免数据丢失的:
- A tuple isn't acked because the task died:这种情况下,失败的那个tuple的tuple树的根tuple将会超时并且重放
- Acker task dies:这种情况下,这个acker跟踪的所有的spout tuple都将超时并且重放
- Spout task dies:这种情况下,由spout的源来负责消息的重放。例如:队列想Kestrel和RabbitMQ在客户端连接断开的时候将所有pending状态的消息重新放回队列。
本节重点
1、一个tuple的tuple树被耗尽并且树中的每个消息都被处理,则称这个tuple被完全处理。反之,没有被完全处理则认为这个tuple失败。默认处理超时时间是30秒。
2、Strom通过调用Spot中的nextTuple方法请求一个tuple。在Spout中发送一个tuple的时候,Spout提供一个"message id"用于标识这个tuple。
3、如果Storm发现一个tuple被完成处理,那么将会在原始的那个Spout中调用ack方法,同时将message id作为参数。同样的,如果tuple失败,则调用那个Spout中的fail方法。注意,tuple被acked或者failed都是在创建这个tuple的那同一个Spout中调用。
4、Specifying a link in the tuple tree is called anchoring. Anchoring is done at the same time you emit a new tuple.
5、在Bolt中将特定的输入tuple作为OutputCollector的emit方法第一个参数,那么这个输出Bolt是被anchored的,因而如果这个输出tuple在下游被处理失败的话,这个tuple所在的tuple树的根tuple将会被重放。否则,如果没有将输入tuple作为第一个参数的话,则是unanchored,进而失败的时候也不会被重放。
6、Storm topology有专门的task来跟踪每一个spout tuple的DAG,这些特殊的task被叫做"acker"。默认每个worker一个acker。当acker发现一个DAG完成的时候,它发消息给创建这个spout tuple的spout task以此来确认这个消息。
7、在topology中,当一个tuple被创建的时候,都会被指定一个64位的id。acker用这个id来跟踪每个tuple。
8、由于tuple可能会重放,因此在处理的时候需要根据message id去重
进一步精简
每一个从Spout出来的tuple都带着一个"message id",重放的时候会用到这个id。
每一个tuple在创建的时候都被指定了一个64位的id,在acker跟踪tuple的DAG(也叫tuple tree)会用到。
每一个tuple被acked的时候,它会发一个消息告诉acker这个tuple tree发生了怎样的改变
一个tuple从Spout出来,随后会经历很多个Bolt,在一步的Bolt中都可能产生新的tuple。因此,由这个原始的tuple开始将会衍生出很多tuple,这些tuple构成一个tuple tree(也叫tuple DAG)。只有当tree耗尽并且其中所有的tuple都处理完成,这个tuple才叫完全处理,否则tuple失败。tuple完全处理后将会在原始那个Spout上调用ack方法,并且用message id作为参数,tuple失败以后同样在那个Spout上调用fail方法。当tuple tree中某一个tuple完成处理以后可以调用OutputCollector的ack方法确认,这个tuple便会从DAG中删除。当acker发现DAG完成以后,发消息告诉那个Spout task来确认这个消息。
参考 http://storm.apache.org/releases/current/Guaranteeing-message-processing.html
Storm保证消息处理的更多相关文章
- Storm 入门教程
在这个教程中,你将学会如何创建 Storm 的topology并将他们部署到 Storm 集群上, 主要的语言是 Java,但是少数几个例子用 Python 编写来说明 Storm 的多语言支持能力. ...
- storm如何保证at least once语义?
背景 前期收到的问题: 1.在Topology中我们可以指定spout.bolt的并行度,在提交Topology时Storm如何将spout.bolt自动发布到每个服务器并且控制服务的CPU.磁盘等资 ...
- Twitter Storm如何保证消息不丢失
storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍storm是怎么做到这个保证的,以及我们使用者怎么做才能充分利用storm的可靠性特点. 一个tuple被”完全处理”是什么意 ...
- Storm入门(五)Twitter Storm如何保证消息不丢失
转自:http://xumingming.sinaapp.com/127/twitter-storm如何保证消息不丢失/ storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍st ...
- 【转】Twitter Storm如何保证消息不丢失
Twitter Storm如何保证消息不丢失 发表于 2011 年 09 月 30 日 由 xumingming 作者: xumingming | 可以转载, 但必须以超链接形式标明文章原始出处和作者 ...
- Storm如何保证消息不丢失
storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍storm是怎么做到这个保证的,以及我们使用者怎么做才能充分利用storm的可靠性特点. 一个tuple被"完全处理 ...
- storm是怎样保证at least once语义的
背景 本篇看看storm是通过什么机制来保证消息至少处理一次的语义的. storm中的一些原语 要说明上面的问题,得先了解storm中的一些原语,比方: tuple和message 在storm中,消 ...
- storm是如何保证at least once语义的?
storm中的一些原语: 要说明上面的问题,得先了解storm中的一些原语,比如: tuple和messagetuple:在storm中,消息是通过tuple来抽象表示的,每个tuple知道它从哪里来 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
随机推荐
- [笔记]《JavaScript高级程序设计》- JavaScript简介
JavaScript实现 虽然JavaScript和ECMAScript通常都被人们用来表达相同的含义,但JavaScript的含义却比ECMA-262中规定的要多得多.一个完整的JavaScript ...
- 【树状数组】BZOJ3132 上帝造题的七分钟
3132: 上帝造题的七分钟 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 1004 Solved: 445[Submit][Status][Dis ...
- oracle之 RA-00054: resource busy and acquire with NOWAIT specified or timeout expired
1. truncate 表报 ORA-00054 ,标明有事务正在操作该表SQL> truncate table alldm.DM_XQKD_YUJING_D;truncate table al ...
- css 负边距
负边距 可以改变 他在文档流中的尺寸 当块级元素设置 margin: -10px; 这个快 的大小没变但是他的定位的位置向上串了,压住了上面的文字 而且在他后面的文字 会爬到他身上 而前面的文 ...
- islider结合react的简单实用
我用islider都是结合react来使用,主要运用在移动端,做首页轮播图,或者是手机图片预览,左右滑动 首先需要 npm install islider.js --save 让后在jsx文件头部引入 ...
- 迁移数据库数据到SQL Server 2017
概述 本篇我们将利用DMA一步一步实现SQL Server 的迁移.帮助大家理解现在的SQL Server与新版本的融合问题,同时需要我们做哪些操作来实现新版本的升级或者迁移. SQL Serve ...
- org.springframework.data.redis.serializer.SerializationException: Cannot serialize;
前言 本文中提到的解决方案,源码地址在:perfect-ssm,希望可以帮你解决问题. 问题描述 在Spring与Redis整合过程中,出现了如下报错: org.springframework.dat ...
- [翻译]QT core wallet manual 狗狗币核心钱包使用教程
译注:比特币没赶上可以玩狗狗币啊,水电厂包不起可以用CPU挖啊.为了顺应时代潮流,了解一下区(fa)块(heng)链(cai)和加密货币技术,准备从研究狗狗币开始.网上找了一圈没有看到很好的入门级教程 ...
- UINavigationController 返回手势与 leftBarButtonItem
UINavigationController 返回手势与 leftBarButtonItem UINavigationController 自带从屏幕左侧边缘向右滑动的返回手势,可以通过这个手势实现 ...
- Vue 环境搭建之Hello World
建 目录 webpack-vuedemo1 安装依赖组件 : 初始化 npm init npm install --save vue npm install --save-dev babel-core ...