Java提高十六:TreeMap深入分析
上一篇容器元素比较Comparable&Comparator分析的时候,我们提到了TreeMap,但没有去细致分析它,只是说明其在添加元素的时候可以进行比较,从而使得集合有序,但是怎么做的呢?我们下面来进行分析。
一、认识TreeMap
之前的文章讲解了HashMap,它保证了以O(1)的时间复杂度进行增、删、改、查,从存储角度考虑,这两种数据结构是非常优秀的。
尽管如此,HashMap还是有自己的局限性----它们不具备统计性能,或者说它们的统计性能时间复杂度并不是很好才更准确,所有的统计必须遍历所有Entry,因此时间复杂度为O(N)。比如Map的Key有1、2、3、4、5、6、7,我现在要统计:
- 所有Key比3大的键值对有哪些
- Key最小的和Key最大的是哪两个
就类似这些操作,HashMap做得比较差,此时我们可以使用TreeMap。TreeMap的Key按照自然顺序进行排序或者根据创建映射时提供的Comparator接口进行排序。TreeMap为增、删、改、查这些操作提供了log(N)的时间开销,从存储角度而言,这比HashMap的O(1)时间复杂度要差些;但是在统计性能上,TreeMap同样可以保证log(N)的时间开销,这又比HashMap的O(N)时间复杂度好不少。
因此总结而言:如果只需要存储功能,使用HashMap是一种更好的选择;如果还需要保证统计性能或者需要对Key按照一定规则进行排序,那么使用TreeMap是一种更好的选择。
二、红黑树介绍
红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
我们知道一颗基本的二叉树他们都需要满足一个基本性质--即树中的任何节点的值大于它的左子节点,且小于它的右子节点。按照这个基本性质使得树的检索效率大大提高。我们知道在生成二叉树的过程是非常容易失衡的,最坏的情况就是一边倒(只有右/左子树),这样势必会导致二叉树的检索效率大大降低(O(n)),所以为了维持二叉树的平衡,大牛们提出了各种实现的算法,如:AVL,SBT,伸展树,TREAP ,红黑树等等。
平衡二叉树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。
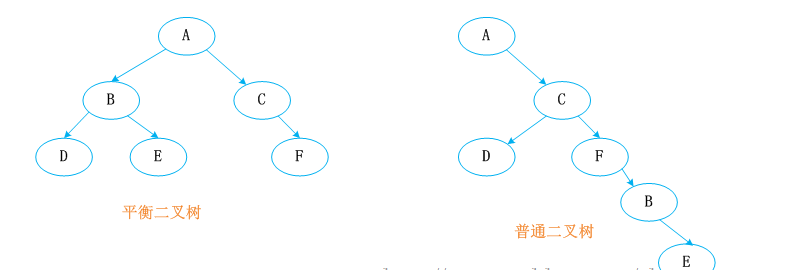
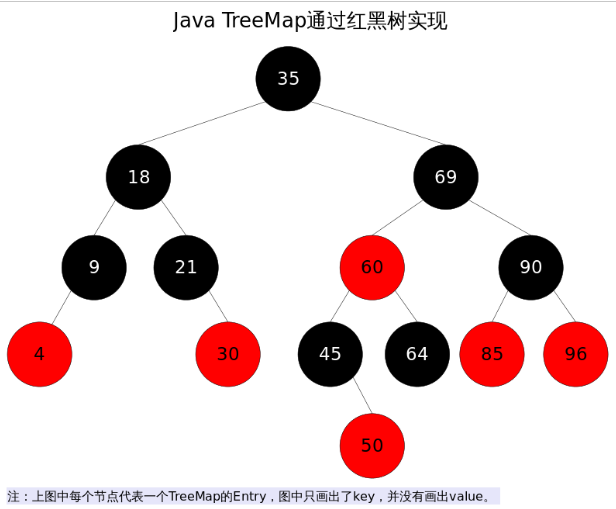
红黑树顾名思义就是节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡。对于一棵有效的红黑树二叉树而言我们必须增加如下规则:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这棵树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。所以红黑树它是复杂而高效的,其检索效率O(log n)。下图为一颗典型的红黑二叉树。
对于红黑二叉树而言它主要包括三大基本操作:左旋、右旋、着色。
 左边旋转
左边旋转
 右边旋转
右边旋转
(图片来自:http://www.cnblogs.com/yangecnu/p/Introduce-Red-Black-Tree.html)
注:由于本文主要是讲解Java中TreeMap,所以并没有对红黑树进行非常深入的了解和研究,如果想对其进行更加深入的研究提供几篇较好的博文:
1、红黑树系列集锦
3、红黑树
三、TreeMap的数据结构
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap继承AbstractMap,实现NavigableMap、Cloneable、Serializable三个接口。其中AbstractMap表明TreeMap为一个Map即支持key-value的集合, NavigableMap(更多)则意味着它支持一系列的导航方法,具备针对给定搜索目标返回最接近匹配项的导航方法 。
TreeMap中同时也包含了如下几个重要的属性:
//比较器,因为TreeMap是有序的,通过comparator接口我们可以对TreeMap的内部排序进行精密的控制
private final Comparator<? super K> comparator;
//TreeMap红-黑节点,为TreeMap的内部类
private transient Entry<K,V> root = null;
//容器大小
private transient int size = 0;
//TreeMap修改次数
private transient int modCount = 0;
//红黑树的节点颜色--红色
private static final boolean RED = false;
//红黑树的节点颜色--黑色
private static final boolean BLACK = true;
对于叶子节点Entry是TreeMap的内部类,它有几个重要的属性:
//键
K key;
//值
V value;
//左孩子
Entry<K,V> left = null;
//右孩子
Entry<K,V> right = null;
//父亲
Entry<K,V> parent;
//颜色
boolean color = BLACK;
四、核心方法put 分析
分析put方法的过程,我们采用实例来进行分析,下面我们是我们写的一段代码:
package com.pony1223; import java.util.Map;
import java.util.TreeMap; public class MapDemo
{
public static void main(String[] args)
{
TreeMap<Integer, String> treeMap = new TreeMap<Integer, String>();
treeMap.put(10, "10");
treeMap.put(83, "83");
treeMap.put(15, "15");
treeMap.put(72, "72");
treeMap.put(20, "20");
treeMap.put(60, "60");
treeMap.put(30, "30");
treeMap.put(50, "50"); for (Map.Entry<Integer, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
} } }
我们打印结果发现:
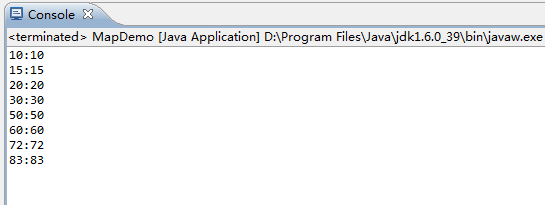
事实再次证明TreeMap是有序的。
接下来的内容会给出插入每条数据之后红黑树的数据结构是什么样子的。首先看一下treeMap的put方法的代码实现:
public V put(K key, V value) {
//用t表示二叉树的当前节点
Entry<K,V> t = root;
//t为null表示一个空树,即TreeMap中没有任何元素,直接插入
if (t == null) {
//比较key值,个人觉得这句代码没有任何意义,空树还需要比较、排序?
compare(key, key); // type (and possibly null) check
//将新的key-value键值对创建为一个Entry节点,并将该节点赋予给root
root = new Entry<>(key, value, null);
//容器的size = 1,表示TreeMap集合中存在一个元素
size = 1;
//修改次数 + 1
modCount++;
return null;
}
int cmp; //cmp表示key排序的返回结果
Entry<K,V> parent; //父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; //指定的排序算法
//如果cpr不为空,则采用既定的排序算法进行创建TreeMap集合
if (cpr != null) {
do {
parent = t; //parent指向上次循环后的t
//比较新增节点的key和当前节点key的大小
cmp = cpr.compare(key, t.key);
//cmp返回值小于0,表示新增节点的key小于当前节点的key,则以当前节点的左子节点作为新的当前节点
if (cmp < 0)
t = t.left;
//cmp返回值大于0,表示新增节点的key大于当前节点的key,则以当前节点的右子节点作为新的当前节点
else if (cmp > 0)
t = t.right;
//cmp返回值等于0,表示两个key值相等,则新值覆盖旧值,并返回新值
else
return t.setValue(value);
} while (t != null);
}
//如果cpr为空,则采用默认的排序算法进行创建TreeMap集合
else {
if (key == null) //key值为空抛出异常
throw new NullPointerException();
/* 下面处理过程和上面一样 */
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//将新增节点当做parent的子节点
Entry<K,V> e = new Entry<>(key, value, parent);
//如果新增节点的key小于parent的key,则当做左子节点
if (cmp < 0)
parent.left = e;
//如果新增节点的key大于parent的key,则当做右子节点
else
parent.right = e;
/*
* 上面已经完成了排序二叉树的的构建,将新增节点插入该树中的合适位置
* 下面fixAfterInsertion()方法就是对这棵树进行调整、平衡,具体过程参考上面的五种情况
*/
fixAfterInsertion(e);
//TreeMap元素数量 + 1
size++;
//TreeMap容器修改次数 + 1
modCount++;
return null;
}
从这段代码,先总结一下TreeMap添加数据的几个步骤:
1.获取根节点,根节点为空,产生一个根节点,将其着色为黑色,退出余下流程
2.获取比较器,如果传入的Comparator接口不为空,使用传入的Comparator接口实现类进行比较;如果传入的Comparator接口为空,将Key强转为Comparable接口进行比较
3.从根节点开始逐一依照规定的排序算法进行比较,取比较值cmp,如果cmp=0,表示插入的Key已存在;如果cmp>0,取当前节点的右子节点;如果cmp<0,取当前节点的左子节点
4.排除插入的Key已存在的情况,第(3)步的比较一直比较到当前节点t的左子节点或右子节点为null,此时t就是我们寻找到的节点,cmp>0则准备往t的右子节点插入新节点,cmp<0则准备往t的左子节点插入新节点
5.new出一个新节点,默认为黑色,根据cmp的值向t的左边或者右边进行插入
6.插入之后进行修复,包括左旋、右旋、重新着色这些操作,让树保持平衡性
第1~第5步都没有什么问题,红黑树最核心的应当是第6步插入数据之后进行的修复工作,对应的Java代码是TreeMap中的fixAfterInsertion方法,下面看一下put每个数据之后TreeMap都做了什么操作,借此来理清TreeMap的实现原理。
put(10, "10")
首先是put(10, "10"),由于此时TreeMap中没有任何节点,因此10为根且根节点为黑色节点,put(10, "10")之后的数据结构为:
put(83, "83")
接着是put(83, "83"),这一步也不难,83比10大,因此在10的右节点上,即执行上面代码中do{}代码块,它是实现排序二叉树的核心算法,通过该算法我们可以确认新增节点在该树的正确位置。找到正确位置后将插入即可,但是由于83不是根节点,我知道TreeMap的底层实现是红黑树,红黑树是一棵平衡排序二叉树,普通的排序二叉树可能会出现失衡的情况,所以下一步就是要进行调整。fixAfterInsertion(e); 调整的过程务必会涉及到红黑树的左旋、右旋、着色三个基本操作。
/**
* 新增节点后的修复操作
* x 表示新增节点
*/
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED; //新增节点的颜色为红色 //循环 直到 x不是根节点,且x的父节点不为红色
while (x != null && x != root && x.parent.color == RED) {
//如果X的父节点(P)是其父节点的父节点(G)的左节点
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
//获取X的叔节点(U)
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
//如果X的叔节点(U) 为红色(情况三)
if (colorOf(y) == RED) {
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的叔节点(U)设置为黑色
setColor(y, BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//如果X的叔节点(U为黑色);这里会存在两种情况(情况四、情况五)
else {
//如果X节点为其父节点(P)的右子树,则进行左旋转(情况四)
if (x == rightOf(parentOf(x))) {
//将X的父节点作为X
x = parentOf(x);
//右旋转
rotateLeft(x);
}
//(情况五)
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
//以X的父节点的父节点(G)为中心右旋转
rotateRight(parentOf(parentOf(x)));
}
}
//如果X的父节点(P)是其父节点的父节点(G)的右节点
else {
//获取X的叔节点(U)
Entry<K,V> y = leftOf(parentOf(parentOf(x)));
//如果X的叔节点(U) 为红色(情况三)
if (colorOf(y) == RED) {
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的叔节点(U)设置为黑色
setColor(y, BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
}
//如果X的叔节点(U为黑色);这里会存在两种情况(情况四、情况五)
else {
//如果X节点为其父节点(P)的右子树,则进行左旋转(情况四)
if (x == leftOf(parentOf(x))) {
//将X的父节点作为X
x = parentOf(x);
//右旋转
rotateRight(x);
}
//(情况五)
//将X的父节点(P)设置为黑色
setColor(parentOf(x), BLACK);
//将X的父节点的父节点(G)设置红色
setColor(parentOf(parentOf(x)), RED);
//以X的父节点的父节点(G)为中心右旋转
rotateLeft(parentOf(parentOf(x)));
}
}
}
//将根节点G强制设置为黑色
root.color = BLACK;
}
我们看第6行的代码,它将默认的插入的那个节点着色成为红色,这很好理解:
根据红黑树的性质(3),红黑树要求从根节点到叶子所有叶子节点上经过的黑色节点个数是相同的,因此如果插入的节点着色为黑色,那必然有可能导致某条路径上的黑色节点数量大于其他路径上的黑色节点数量,因此默认插入的节点必须是红色的,以此来维持红黑树的性质(3).
当然插入节点着色为红色节点后,有可能导致的问题是违反性质(2),即出现连续两个红色节点,这就需要通过旋转操作去改变树的结构,解决这个问题。
接着看
while (x != null && x != root && x.parent.color == RED)
的判断,前两个条件都满足,但是因为83这个节点的父节点是根节点的,根节点是黑色节点,因此这个条件不满足,while循环不进去,直接执行一次
root.color = BLACK;
行的代码给根节点着色为黑色(因为在旋转过程中有可能导致根节点为红色,而红黑树的根节点必须是黑色,因此最后不管根节点是不是黑色,都要重新着色确保根节点是黑色的)。
那么put(83, "83")之后,整个树的结构变为:
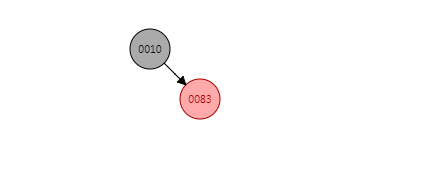
一、为根节点
若新插入的节点N没有父节点,则直接当做根据节点插入即可,同时将颜色设置为黑色
二、父节点为黑色
这种情况新节点N同样是直接插入,同时颜色为红色,由于根据规则四它会存在两个黑色的叶子节点,值为null。同时由于新增节点N为红色,所以通过它的子节点的路径依然会保存着相同的黑色节点数,同样满足规则5。
在看put(15, "15")之前,必须要先过一下fixAfterInsertion方法。第11行~第41行的代码和第43行~第73行的代码是一样的,无非一个是操作左子树另一个是操作右子树而已,因此就看前一半:
while (x != null && x != root && x.parent.color == RED) {
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x)));
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
if (x == rightOf(parentOf(x))) {
x = parentOf(x);
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateRight(parentOf(parentOf(x)));
}
}
....
}
第2行的判断注意一下,用语言描述出来就是:判断当前节点的父节点与当前节点的父节点的父节点的左子节点是否同一个节点。翻译一下就是:当前节点是否左子节点插入.
在上面代码中说到的情况三、四、五的意思是;
三、若父节点P和P的兄弟节点U都为红色
对于这种情况若直接插入肯定会出现不平衡现象(不能出现两个连着的红色)。怎么处理?P、U节点变黑、G节点变红。这时由于经过节点P、U的路径都必须经过G所以在这些路径上面的黑节点数目还是相同的。但是经过上面的处理,可能G节点的父节点也是红色,这个时候我们需要将G节点当做新增节点递归处理。
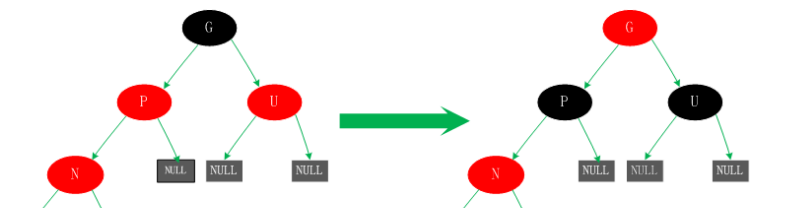
四、若父节点P为红色,叔父节点U为黑色或者缺少,且新增节点N为P节点的右孩子
对于这种情况我们对新增节点N、P进行一次左旋转。这里所产生的结果其实并没有完成,还不是平衡的(违反了规则四),这是我们需要进行情况5的操作。
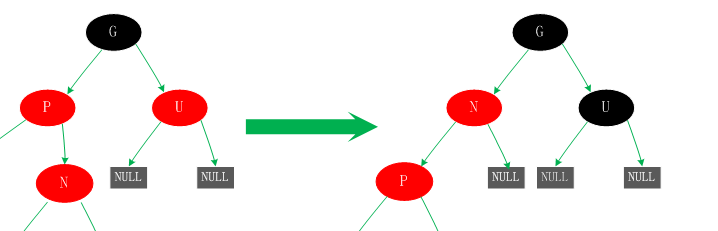
五、父节点P为红色,叔父节点U为黑色或者缺少,新增节点N为父节点P左孩子
这种情况有可能是由于情况四而产生的,也有可能不是。对于这种情况先已P节点为中心进行右旋转,在旋转后产生的树中,节点P是节点N、G的父节点。但是这棵树并不规范,它违反了规则4,所以我们将P、G节点的颜色进行交换,使之其满足规范。开始时所有的路径都需要经过G其他们的黑色节点数一样,但是现在所有的路径改为经过P,且P为整棵树的唯一黑色节点,所以调整后的树同样满足规范5。

总结:对于第四种情况和第五种情况而言这两种插入方式的处理是不同的,区别是第四种情况插入多一步左旋操作。能看出,红黑树的插入最多只需要进行两次旋转,不管这棵红黑树多么复杂,都可以根据这五种情况来进行生成。
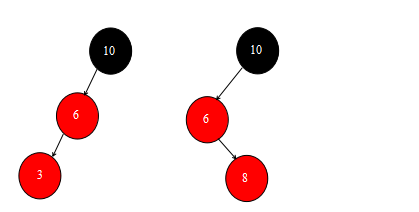
其中左边的是左子树外侧插入,右边的是左子树内侧插入
put(15, "15")
看完fixAfterInsertion方法流程之后,继续添加数据,这次添加的是put(15, "15"),15比10大且比83小,因此15最终应当是83的左子节点,默认插入的是红色节点,因此首先将15作为红色节点插入83的左子节点后的结构应当是:
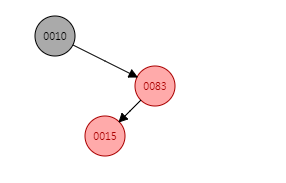
但是显然这里违反了红黑树的性质(2),即连续出现了两个红色节点,因此此时必须进行旋转。回看前面fixAfterInsertion的流程,上面演示的是左子树插入流程,右子树一样,可以看到这是右子树内侧插入,需要进行两次旋转操作:
- 对新插入节点的父节点进行一次右旋操作
- 新插入节点的父节点着色为黑色,新插入节点的祖父节点着色为红色
- 对新插入节点的祖父节点进行一次左旋操作
旋转是红黑树中最难理解也是最核心的操作,右旋和左旋是对称的操作,我个人的理解,以右旋为例,对某个节点x进行右旋,其实质是:
- 降低左子树的高度,增加右子树的高度
- 将x变为当前位置的右子节点
左旋是同样的道理,在旋转的时候一定要记住这两句话,这将会帮助我们清楚地知道在不同的场景下旋转如何进行。
先看一下"对新插入节点的父节点进行一次右旋操作",源代码为rotateRight方法:
private void rotateRight(Entry<K,V> p) {
if (p != null) {
//将L设置为P的左子树
Entry<K,V> l = p.left;
//将L的右子树设置为P的左子树
p.left = l.right;
//若L的右子树不为空,则将P设置L的右子树的父节点
if (l.right != null)
l.right.parent = p;
//将P的父节点设置为L的父节点
l.parent = p.parent;
//如果P的父节点为空,则将L设置根节点
if (p.parent == null)
root = l;
//若P为其父节点的右子树,则将L设置为P的父节点的右子树
else if (p.parent.right == p)
p.parent.right = l;
//否则将L设置为P的父节点的左子树
else
p.parent.left = l;
//将P设置为L的右子树
l.right = p;
//将L设置为P的父节点
p.parent = l;
}
}
左旋与右旋是一个对称的操作,大家可以试试看把右图的b节点进行左旋,就变成了左图了。这里多说一句,旋转一定要说明是对哪个节点进行旋转,网上看很多文章讲左旋、右旋都是直接说旋转之后怎么样怎么样,我认为脱离具体的节点讲旋转是没有任何意义的。
这里可能会有的一个问题是:b有左右两个子节点分别为d和e,为什么右旋的时候要将右子节点e拿到a的左子节点而不是b的左子节点d?
一个很简单的解释是:如果将b的左子节点d拿到a的左子节点,那么b右旋后右子节点指向a,b原来的右子节点e就成为了一个游离的节点,游离于整个数据结构之外。
回到实际的例子,对83这个节点进行右旋之后还有一次着色操作(2),分别是将x的父节点着色为黑色,将x的祖父节点着色为红色,然后对节点10进行一次左旋操作(3),左旋之后的结构为:

put(72, "72")
put(72, "72")就很简单了,72是83的左子节点,由于72的父节点以及叔父节点都是红色节点,因此直接将72的父节点83、将72的叔父节点10着色为黑色即可,72这个节点着色为红色,即满足红黑树的特性,插入72之后的结构图为:
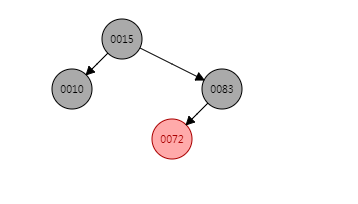
put(20, "20")
put(20, "20"),插入的位置应当是72的左子节点,默认插入红色,插入之后的结构图为:
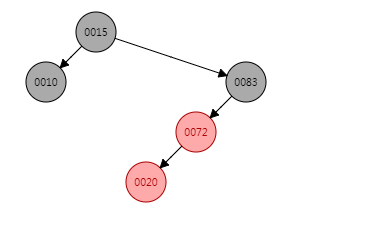
问题很明显,出现了连续两个红色节点,20的插入位置是一种左子树外侧插入的场景,因此只需要进行着色+对节点83进行一次右旋即可,着色+右旋之后数据结构变为:
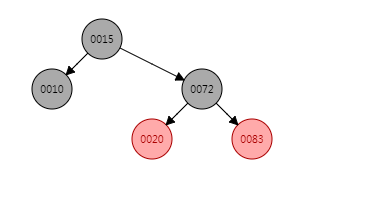
put(60, "60")
下面进行put(60, "60")操作,节点60插入的位置是节点20的右子节点,由于节点60的父节点与叔父节点都是红色节点,因此只需要将节点60的父节点与叔父节点着色为黑色,将节点60的组父节点着色为红色即可。
那么put(60, "60")之后的结构为:
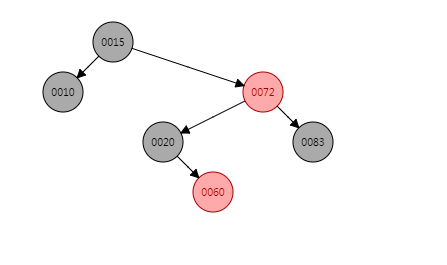
put(30, "30")
put(30, "30"),节点30应当为节点60的左子节点,因此插入节点30之后应该是这样的:
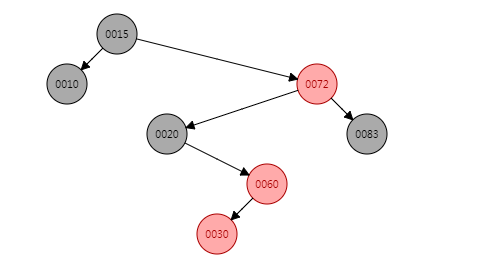
显然这里违反了红黑树性质即连续出现了两个红色节点,因此这里要进行旋转。
put(30, "30")的操作和put(15, "15")的操作类似,同样是右子树内侧插入的场景,那么需要进行两次旋转:
- 对节点30的父节点节点60进行一次右旋
- 右旋之后对节点60的祖父节点20进行一次左旋
右旋+着色+左旋之后,put(30, "30")的结果应当为:
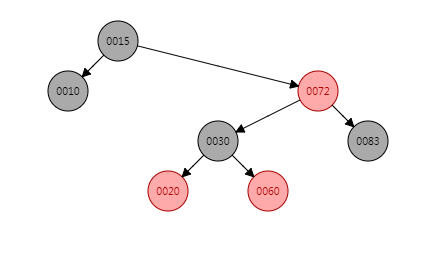
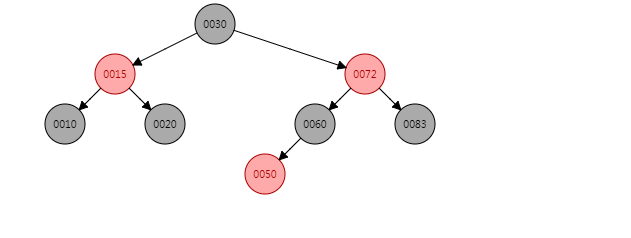
put(50, "50")
private void rotateLeft(Entry<K,V> p) {
if (p != null) {
//获取P的右子节点,其实这里就相当于新增节点N(情况四而言)
Entry<K,V> r = p.right;
//将R的左子树设置为P的右子树
p.right = r.left;
//若R的左子树不为空,则将P设置为R左子树的父亲
if (r.left != null)
r.left.parent = p;
//将P的父亲设置R的父亲
r.parent = p.parent;
//如果P的父亲为空,则将R设置为跟节点
if (p.parent == null)
root = r;
//如果P为其父节点(G)的左子树,则将R设置为P父节点(G)左子树
else if (p.parent.left == p)
p.parent.left = r;
//否则R设置为P的父节点(G)的右子树
else
p.parent.right = r;
//将P设置为R的左子树
r.left = p;
//将R设置为P的父节点
p.parent = r;
}
}
五、delete方法分析
针对于红黑树的增加节点而言,删除显得更加复杂,使原本就复杂的红黑树变得更加复杂。同时删除节点和增加节点一样,同样是找到删除的节点,删除之后调整红黑树。但是这里的删除节点并不是直接删除,而是通过走了“弯路”通过一种捷径来删除的:找到被删除的节点D的子节点C,用C来替代D,不是直接删除D,因为D被C替代了,直接删除C即可。所以这里就将删除父节点D的事情转变为了删除子节点C的事情,这样处理就将复杂的删除事件简单化了。子节点C的规则是:右分支最左边,或者 左分支最右边的。
红-黑二叉树删除节点,最大的麻烦是要保持 各分支黑色节点数目相等。 因为是删除,所以不用担心存在颜色冲突问题——插入才会引起颜色冲突。
红黑树删除节点同样会分成几种情况,这里是按照待删除节点有几个儿子的情况来进行分类:
1、没有儿子,即为叶结点。直接把父结点的对应儿子指针设为NULL,删除儿子结点就OK了。
2、只有一个儿子。那么把父结点的相应儿子指针指向儿子的独生子,删除儿子结点也OK了。
3、有两个儿子。这种情况比较复杂,但还是比较简单。上面提到过用子节点C替代代替待删除节点D,然后删除子节点C即可。
下面就论各种删除情况来进行图例讲解,但是在讲解之前请允许我再次啰嗦一句,请时刻牢记红黑树的5点规定:
1、每个节点都只能是红色或者黑色
2、根节点是黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个结点是红的,则它两个子节点都是黑的。也就是说在一条路径上不能出现相邻的两个红色结点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
诚然,既然删除节点比较复杂,那么在这里我们就约定一下规则:
1、下面要讲解的删除节点一定是实际要删除节点的后继节点(N),如前面提到的C。
2、下面提到的删除节点的树都是如下结构,该结构所选取的节点是待删除节点的右树的最左边子节点。这里我们规定真实删除节点为N、父节点为P、兄弟节点为W兄弟节点的两个子节点为X1、X2。
删除元素的过程和普通二叉搜索树的搜索过程大体也比较类似,首先是根据待删除节点的情况进行分析:
1. 待删除节点没有子节点, 则直接删除该节点。如下图:
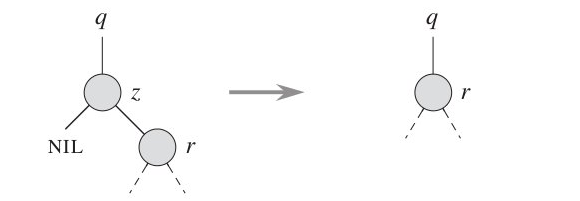
2. 待删除节点有一个子节点,则用该子节点替换它的父节点:

3. 待删除节点有两个子节点,则取它的后继节点替换它,并删除这个后继节点原来的位置。它可能有种情况
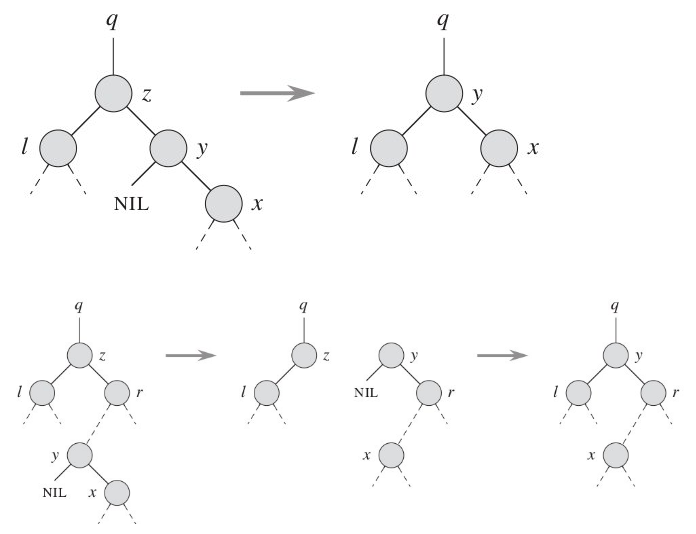
删除后的调整
删除元素之后的调整和前面的插入元素调整的过程比起来更复杂。它不是一个简单的在原来过程中取反。我们先从一个最基本的点开始入手。首先一个,我们要进行调整的这个点肯定是因为我们要删除的这个点破坏了红黑树的本质特性。而如果我们删除的这个点是红色的,则它肯定不会破坏里面的属性。因为从前面删除的过程来看,我们这个要删除的点是已经在濒临叶节点的附近了,它要么有一个子节点,要么就是一个叶节点。如果它是红色的,删除了,从上面的节点到叶节点所经历的黑色节点没有变化。所以,这里的一个前置条件就是待删除的节点是黑色的。
在前面的那个前提下,我们要调整红黑树的目的就是要保证,这个原来是黑色的节点被删除后,我们要通过一定的变化,使得他们仍然是合法的红黑树。我们都知道,在一个黑色节点被删除后,从上面的节点到它所在的叶节点路径所经历的黑色节点就少了一个。我们需要做一些调整,使得它少的这个在后面某个地方能够补上。
ok,有了这一部分的理解,我们再来看调整节点的几种情况。
1. 当前节点和它的父节点是黑色的,而它的兄弟节点是红色的:
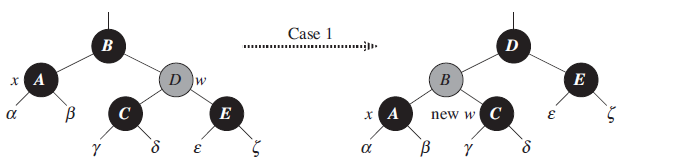
这种情况下既然它的兄弟节点是红色的,从红黑树的属性来看,它的兄弟节点必然有两个黑色的子节点。这里就通过节点x的父节点左旋,然后父节点B颜色变成红色,而原来的兄弟节点D变成黑色。这样我们就将树转变成第二种情形中的某一种情况。在做后续变化前,这棵树这么的变化还是保持着原来的平衡。
2. 1) 当前节点的父节点为红色,而它的兄弟节点,包括兄弟节点的所有子节点都是黑色。

在这种情况下,我们将它的兄弟节点设置为红色,然后x节点指向它的父节点。这里有个比较难以理解的地方,就是为什么我这么一变之后它就平衡了呢?因为我们假定A节点是要调整的节点一路调整过来的。因为原来那个要调整的节点为黑色,它一旦被删除就路径上的黑色节点少了1.所以这里A所在的路径都是黑色节点少1.这里将A的兄弟节点变成红色后,从它的父节点到下面的所有路径就都统一少了1.保证最后又都平衡了。
当然,大家还会有一个担忧,就是当前调整的毕竟只是一棵树中间的字数,这里头的节点B可能还有父节点,这么一直往上到根节点。你这么一棵字数少了一个黑色节点,要保证整理合格还是不够的。这里在代码里有了一个保证。假设这里B已经是红色的了。那么代码里那个循环块就跳出来了,最后的部分还是会对B节点,也就是x所指向的这个节点置成黑色。这样保证前面亏的那一个黑色节点就补回来了。
2) 当前节点的父节点为黑色,而它的兄弟节点,包括兄弟节点的所有子节点都是黑色。
这种情况和前面比较类似。如果接着前面的讨论来,在做了那个将兄弟节点置成红色的操作之后,从父节点B开始的所有子节点都少了1.那么这里从代码中间看的话,由于x指向了父节点,仍然是黑色。则这个时候以父节点B作为基准的子树下面都少了黑节点1. 我们就接着以这么一种情况向上面推进。
3. 当前节点的父节点为红色,而它的兄弟节点是黑色,同时兄弟节点有一个节点是红色。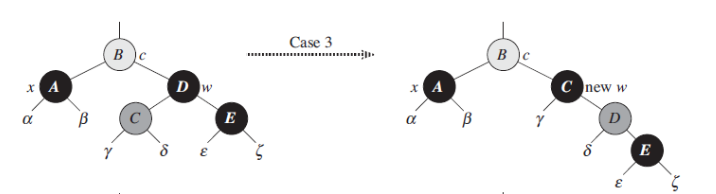
这里所做的操作就是先将兄弟节点做一个右旋操作,转变成第4种情况。当然,前面的前提是B为红色,在B为黑色的情况下也可以同样的处理。
4. 在当前兄弟节点的右子节点是红色的情况下。
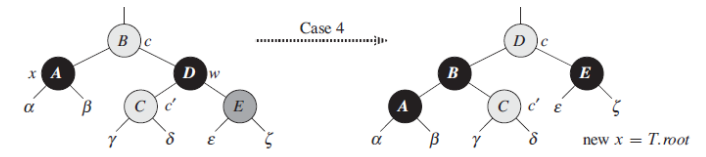
这里是一种比较理想的处理情况,我们将父节点做一个左旋操作,同时将父节点B变成黑色,而将原来的兄弟节点D变成红色,并将D的右子节点变成黑色。这样保证了新的子树中间根节点到各叶子节点的路径依然是平衡的。大家看到这里也许会觉得有点奇怪,为什么这一步调整结束后就直接x = T.root了呢?也就是说我们一走完这个就可以把x直接跳到根节点,其他的都不需要看了。这是因为我们前面的一个前提,A节点向上所在的路径都是黑色节点少了一个的,这里我们以调整之后相当于给它增加了一个黑色节点,同时对其他子树的节点没有任何变化。相当于我内部已经给它补偿上来了。所以后续就不需要再往上去调整。
前面讨论的这4种情况是在当前节点是父节点的左子节点的条件下进行的。如果当前节点是父节点的右子节点,则可以对应的做对称的操作处理,过程也是一样的。
其他
TreeMap的红黑树实现当然也包含其他部分的代码实现,如用于查找元素的getEntry方法,取第一个和最后一个元素的getFirstEntry, getLastEntry方法以及求前驱和后继的predecesor, successor方法。这些方法的实现和普通二叉搜索树的实现没什么明显差别。这里就忽略不讨论了。这里还有一个有意思的方法实现,就是buildFromSorted方法。它的实现过程并不复杂,不过经常被作为面试的问题来讨论。
六、小节
这篇博文确实是有点儿长,在这里非常感谢各位看客能够静下心来读完,我想你通过读完这篇博文一定收获不小。
同时这篇博文我写的过程中,看了、参考了大量的博文。同时不免会有些地方存在借鉴之处,在这里对其表示感谢。
另外,我想说的是,重点要掌握的是put方法即可,其它如果精力足够可以细细品读。
参考资料:
1、红黑树数据结构剖析:http://www.cnblogs.com/fanzhidongyzby/p/3187912.html
2、红黑二叉树详解及理论分析 :http://blog.csdn.net/kartorz/article/details/8865997
3、教你透彻了解红黑树:blog.csdn.net/v_july_v/article/details/6105630
4、经典算法研究系列:五、红黑树算法的实现与剖析 :http://blog.csdn.net/v_JULY_v/article/details/6109153
5、示例,红黑树插入和删除过程:http://saturnman.blog.163.com/blog/static/557611201097221570/
6、红黑二叉树详解及理论分析 :http://blog.csdn.net/kartorz/article/details/8865997
7、红黑树概念、红黑树的插入及旋转操作:http://www.cnblogs.com/xrq730/p/6867924.html
8、treemap:http://blog.csdn.net/chenssy/article/details/26668941
Java提高十六:TreeMap深入分析的更多相关文章
- JAVA提高十:ArrayList 深入分析
前面一章节,我们介绍了集合的类图,那么本节将学习Collection 接口中最常用的子类ArrayList类,本章分为下面几部分讲解(说明本章采用的JDK1.6源码进行分析,因为个人认为虽然JDK1. ...
- “全栈2019”Java第九十六章:抽象局部内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第二十六章:流程控制语句中循环语句do-while
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第十六章:下划线在数字中的意义
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析
因为最近工作太忙了,连续的晚上支撑和上班,因此没有精力来写下这篇博客,今天上午正好有一点空,因此来复习一下不太常用的集合体系大家族中的几个类:WeakHashMap&EnumMap&L ...
- JAVA提高十二:HashMap深入分析
首先想说的是关于HashMap源码的分析园子里面应该有很多,并且都是分析得很不错的文章,但是我还是想写出自己的学习总结,以便加深自己的理解,因此就有了此文,另外因为小孩过来了,因此更新速度可能放缓了, ...
- Java提高十五:容器元素比较Comparable&Comparator深入分析
我们经常用容器来存放元素,通常而言我们是不关系容器中的元素是否有序,但有些场景可能要求容器中的元素是有序的,这个时候用ArrayList LinkedList Hashtable HashMap ...
- JAVA提高十四:HashSet深入分析
前面我们介绍了HashMap,Hashtable,那么还有一个hash家族,那就是HashSet;在讲解HashSet前,大家先要知道的是HashSet是单值集合的接口,即是Collection下面的 ...
- JAVA提高十八:Vector&Stack深入分析
前面我们已经接触过几种数据结构了,有数组.链表.Hash表.红黑树(二叉查询树),今天再来看另外一种数据结构:栈. 什么是栈呢,我们先看一个例子:栈就相当于一个很窄的木桶,我们往木桶里放东西,往外拿东 ...
随机推荐
- Win10打补丁KB4022725出现0x80073712错误
周末从老家回来折腾电脑,发现又收到了一大堆补丁,其中包括6月累积更新KB4022725.在安装过程中,一不小心手滑碰到了插线板,电脑断电了!!尼玛,这是要悲催的节奏么? 重新上完电开机,开机界面显示正 ...
- 作为前端Web开发者,这12个终端命令不可不会
对于开发人员来说,终端是最重要的工具之一.掌握终端,能够有效的提升开发人员的工作流程.使用终端,许多日常任务都被简化为了编写简单的命令并按下 Enter 按钮. 本文列举了一系列 Linux 命令,旨 ...
- windows server git
我有一个阿里云,windows server,我想把代码放阿里云 我去做git,只需要安装copssh 下载git https://git-for-windows.github.io/ 下载Copss ...
- 初学者易上手的SSH-hibernate01环境搭建
这里我们继续学习SSH框架中的另一框架-hibernate.那么hibernate是什么?Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序 ...
- springcloud干货之服务消费者(ribbon)
本章介绍springcloud中的服务消费者 springcloud服务调用方式有两种实现方式: 1,restTemplate+ribbon, 2,feign 本来想一篇讲完,发现篇幅有点长,所以本章 ...
- 如何升级laravel5.4到laravel5.5并使用新特性?
如何升级laravel5.4到laravel5.5并使用新特性? 修改composer.json: "laravel/framework": "5.5.*", ...
- VNC 远程连接vmware下centOS7
VNC ( Virtual Network Computing)是一个linux下提供远程桌面支持的服务,类似于windows下的远程桌面服务,本来我是准备用xmanager来远程连我虚拟机中的cen ...
- php 不能取得session值的一个解决方法
1.确认下<?php session_start(); ?> 这句话是不是在<HTML> 标志之前. 不在的话,请放到<HTML> 标志之前. 2.如果上面操作后 ...
- Leetcode题解(六)
21.Merge Two Sorted Lists 题目 直接上代码: class Solution { public: ListNode *mergeTwoLists(ListNode *l1, L ...
- Problem G
Problem Description A relay is a race for two or more teams of runners. Each member of a team runs o ...