DFS和BFS(无向图)Java实现
package practice; import java.util.Iterator;
import java.util.Stack; import edu.princeton.cs.algs4.*; public class TestMain {
public static void main(String[] args) {
Graph a = new Graph(6);
a.addEdge(2, 4);
a.addEdge(2, 3);
a.addEdge(1, 2);
a.addEdge(0, 5);
a.addEdge(0, 1);
a.addEdge(0, 2);
a.addEdge(3, 4);
a.addEdge(3, 5);
System.out.println(a); DisposeMap df = new DisposeMap(a);
/*df.dfs(0);
System.out.println(df.hasPathTo(1));
System.out.println(df.hasPathTo(2));
Stack<Integer> aStack = df.pathTo(1);
while (!aStack.isEmpty()) {
System.out.print(aStack.pop() + "->");
}
System.out.println("end");*/ df.bfs(0);
for (int i = 0; i < 6; i++) {
System.out.println(df.marked(i));
}
Stack<Integer> aStack = df.pathTo(4);
while (!aStack.isEmpty()) {
System.out.print(aStack.pop() + "->");
}
System.out.println("end");
}
} /*
* 图处理dispose
*/
class DisposeMap {
private boolean[] marked; //将已经搜素过的节点储存为true
private int count = 0;
private Graph G;
private int s; //起点
private int[] edgeTo; //edgeTo[w] = v,w为图中的节点,v为它的父节点 public DisposeMap(Graph G) {
this.G = G; marked = new boolean[G.V];
edgeTo = new int[G.V];
for (int i = 0; i < marked.length; i++) {
marked[i] = false;
}
}
/*
* 深度优先搜索,储存以s为起点所能到达的所有点
*/
public void dfs(int s) {
marked[s] = true; count++;
System.out.println("Search" + s);
for (Integer b : G.adj(s)) { //搜索一个节点的相邻的第一个没有被标记过的节点
if (marked[b] == false) { //如果没有搜索过这个节点,就搜索它
edgeTo[b] = s;
dfs(b);
}
}
}
/*
* 广度优先搜索
*/
public void bfs(int s) {
edu.princeton.cs.algs4.Queue<Integer> queue = new Queue<Integer>();
queue.enqueue(s);
marked[s] = true; while (!queue.isEmpty()) {
Integer temp = queue.dequeue();
for (Integer b : G.adj(temp)) { //搜索一个节点的所有的相邻的节点
if (marked[b] == false) { //如果没有搜索过这个节点,就搜索它
queue.enqueue(b);
edgeTo[b] = temp;
marked[b] = true;
}
}
}
}
/*
* 查看某点是否被标记
*/
public boolean marked(int w) { return marked[w];}
/*
* 搜索了几个点
*/
public int count() { return count;}
/*
* 是否存在s到v的路径
*/
public boolean hasPathTo(int v) {
return marked(v);
}
/*
* s到v的路径,有则返回一个Stack,没有则返回null
*/
public Stack<Integer> pathTo(int v) {
Stack<Integer> a = new Stack<Integer>();
for (int i = v; i != s; i = edgeTo[i])
a.push(i);
a.push(s);
return a;
}
} /*
* 图
*/
class Graph {
Bag<Integer>[] graph; //这里使用背包的数组,邻借表
int V;
int E; public Graph(int V) {
this.V = V;
graph = (Bag<Integer>[]) new Bag[V];
for (int i = 0; i < graph.length; i++) {
graph[i] = (Bag<Integer>) new Bag();
}
}
/*
* 返回顶点数
*/
public int V() { return V;}
/*
* 返回边数
*/
public int E() { return E;}
/*
* 向图中添加一条边
*/
public void addEdge(int v, int w) {
graph[v].add(w);
graph[w].add(v);
E++;
}
/*
* 和v相邻的所有顶点
*/
public Iterable<Integer> adj(int v) {
return graph[v];
}
/*
* 计算v的度数
*/
public static int degree(Graph G, int v) {
int degree = 0;
for (Integer bag : G.graph[v]) degree++;
return degree;
}
@Override
public String toString() {
String s = V + " vertices, " + E + " edges\n";
for (int v = 0; v < V; v++) {
s += v + ": ";
for (Integer integer : this.adj(v)) {
s += integer + " ";
}
s += "\n";
}
return s;
}
} /*
* 背包
*/
class Bag<T> implements Iterable<T> {
Node first; private class Node {
T value;
Node next;
} public void add(T value) {
Node oldfirst = first;
first = new Node();
first.value = value;
first.next = oldfirst;
} public void delete(T value) { } @Override
public Iterator<T> iterator() {
return new BagIterator();
} private class BagIterator implements Iterator<T> {
Node node = first; @Override
public boolean hasNext() {
return node != null;
} @Override
public T next() {
T tempt = node.value;
node = node.next;
return tempt;
}
}
}
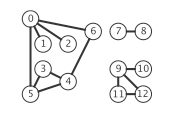
代码中的无向图
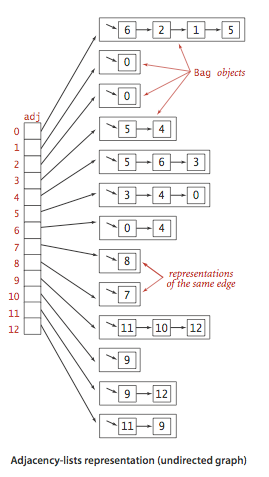
图的储存-邻接表示意图
DFS和BFS(无向图)Java实现的更多相关文章
- Java数据结构——图的DFS和BFS
1.图的DFS: 即Breadth First Search,深度优先搜索是从起始顶点开始,递归访问其所有邻近节点,比如A节点是其第一个邻近节点,而B节点又是A的一个邻近节点,则DFS访问A节点后再访 ...
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- 判断图连通的三种方法——dfs,bfs,并查集
Description 如果无向图G每对顶点v和w都有从v到w的路径,那么称无向图G是连通的.现在给定一张无向图,判断它是否是连通的. Input 第一行有2个整数n和m(0 < n,m < ...
- 图的DFS与BFS遍历
一.图的基本概念 1.邻接点:对于无向图无v1 与v2之间有一条弧,则称v1与v2互为邻接点:对于有向图而言<v1,v2>代表有一条从v1到v2的弧,则称v2为v1的邻接点. 2.度:就是 ...
- 列出连通集(DFS及BFS遍历图) -- 数据结构
题目: 7-1 列出连通集 (30 分) 给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集.假设顶点从0到N−1编号.进行搜索时,假设我们总是从编号最小的顶点出发,按编号递 ...
- 图论相关知识(DFS、BFS、拓扑排序、最小代价生成树、最短路径)
图的存储 假设是n点m边的图: 邻接矩阵:很简单,但是遍历图的时间复杂度和空间复杂度都为n^2,不适合数据量大的情况 邻接表:略微复杂一丢丢,空间复杂度n+m,遍历图的时间复杂度为m,适用情况更广 前 ...
随机推荐
- 二.GC相关之Java内存模型
根据上节描述的问题,我们知道其最终原因是GC导致的.本节我们就先详细探讨下与GC息息相关的Java内存模型. 名词解释:变量,理解为java的基本类型.对象,理解为java new出来的实例. Jav ...
- [BZOJ 4720][NOIP 2016] 换教室
记得某dalao立了"联赛要是考概率期望我直播吃键盘"的$flag$然后就有了这道题233333 4720: [Noip2016]换教室 Time Limit: 20 Sec M ...
- 完整版百度地图点击列表定位到对应位置并有交互动画效果demo
1.前言 将地图嵌入到项目中的需求很多,好吧,我一般都是用的百度地图.那么今天就主要写一个完整的demo.展示一个列表,点击列表的任一内容,在地图上定位到该位置,并有动画效果.来来来,直接上demo ...
- NET中解决KafKa多线程发送多主题的问题
一般在KafKa消费程序中消费可以设置多个主题,那在同一程序中需要向KafKa发送不同主题的消息,如异常需要发到异常主题,正常的发送到正常的主题,这时候就需要实例化多个主题,然后逐个发送. 在NET中 ...
- java8之lambda表达式入门
1.基本介绍 lambda表达式,即带有参数的表达式,为了更清晰地理解lambda表达式,先上代码: 1.1 两种方式的对比 1.1.1 方式1-匿名内部类 class Student{ privat ...
- Linux - 简明Shell编程07 - 数组(Array)
脚本地址 https://github.com/anliven/L-Shell/tree/master/Shell-Basics 示例脚本及注释 #!/bin/bash test0=() # 定义数组 ...
- .NET并行计算和并发3-Invoke
Control.Invoke 方法 (Delegate) 在拥有此控件的基础窗口句柄的线程上执行指定的委托. Invoke方法搜索沿控件的父级链,直到它找到的控件或窗口具有一个窗口句柄: 如果尚不存在 ...
- include包含头文件的语句中,双引号和尖括号的区别
include包含头文件的语句中,双引号和尖括号的区别 #include <>格式:引用标准库头文件,编译器从标准库目录开始搜索 #incluce ""格式:引用非 ...
- 小白对Salesforce的简单认识(01)
1. Salesforce为我们提供的服务? Salesforce基于云平台为我们提供SAAS和 PAAS服务. SAAS(Salesforce.com is Software as a Servic ...
- Python 写网络爬虫思路分析
首先从程序入口开始分析,在程序入口处传入一个待爬取的网址, 使用下载器Html_downloader类下载该地址的内容,使用解释器 parser分析内容,利用BeautifulSoup包抓取想要爬取的 ...