python网络编程(线程)
一、socketserver模块
之前的例子中的C/S架构只能实现同一时刻只有一台客户端可以和服务端进行数据交互,我们可以通过socketserver模块实现并发。
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环。socketserver模块分为两大类,server类解决链接问题,request解决通信问题。
server类:

request类:
继承关系:
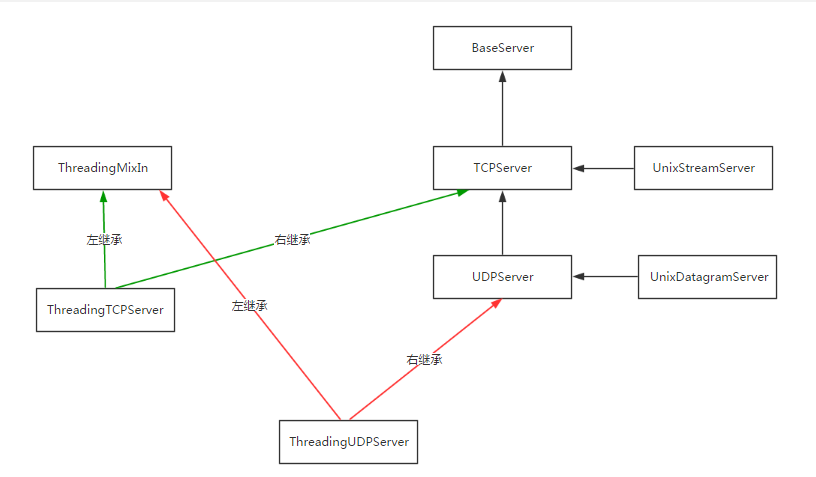

基于socketserver完成并发:
import socketserver#这个模块解决了并发的问题 #Ftpserver(conn, client_addr, obj) class FTPserver(socketserver.BaseRequestHandler): #通讯,标准语法,必须要继承socketserver.BaseRequestHandler
def handle(self):
print('=-=====>',self.request)
print(self.request)#self.request他就是conn的物理地址,拿到这个就可以链接并且收发信息了
while True:
data=self.request.recv(1024)
print(data)
self.request.send(data.upper()) if __name__ == '__main__':
obj=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FTPserver)#ThreadingTCPServer相当于雇了多个服务员,监听服务端
print(obj.server_address)
print(obj.RequestHandlerClass)
print(obj.socket) obj.serve_forever() #链接循环,会一直提供链接=一直有服务员可以服务你。
socketserver
以下述代码为例,分析socketserver源码:
ftpserver=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FtpServer)
ftpserver.serve_forever()
根据继承查找属性的顺序:ThreadingTCPServer->ThreadingMixIn->TCPServer->BaseServer
第一步,实例化得到ftpserver,先找类ThreadingTCPServer的__init__,在TCPServer中找到,进而执行server_bind,server_active
第二步,找ftpserver下的serve_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中
第三步,执行self._handle_request_noblock()进而执行request, client_address = self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request, client_address)
第四步,在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request, client_address)
上述四部分完成了链接循环,本部分开始进入处理通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找....
基于tcp的socketserver中,self.server即套接字对象,self.request即一个链接,self.client_address即客户端地址。
基于udp的socketserver中,self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', <socket.socket fd=200, family=AddressFamily.AF_INET, type=SocketKind.SOCK_DGRAM, proto=0, laddr=('127.0.0.1', 8080)>),self.client_address即客户端地址。
二、进程与线程
进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。正在进行的一个过程或者说一个任务。而负责执行任务则是cpu。峰哥时常强调进程是一个资源单位。程序的执行过程就是一个进程,同一个程序同时执行两次也是两个进程。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,并突破一个进程只能干一样事的缺陷,使到进程内并发成为可能。线程就是一个执行单位,在进程中具体的执行者还是线程。线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
两者之间的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
多线程的优点:
1)多线程共享一个进程的地址空间(资源)。
2) 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3) 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
三、并行与并发
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真是干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务。
并发是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发),简单的可以理解为快速在多个线程来回切换,感觉好像同时在做多个事情。
只有具备多个cpu才能实现并行,单核下,可以利用多道技术,多个核,每个核也都可以利用多道技术(多道技术是针对单核而言的)。
有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,cpu4,一旦任务1遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术 ,而一旦任务1的I/O结束了,操作系统会重新调用它(需知进程的调度、分配给哪个cpu运行,由操作系统说了算),可能被分配给四个cpu中的任意一个去执行。
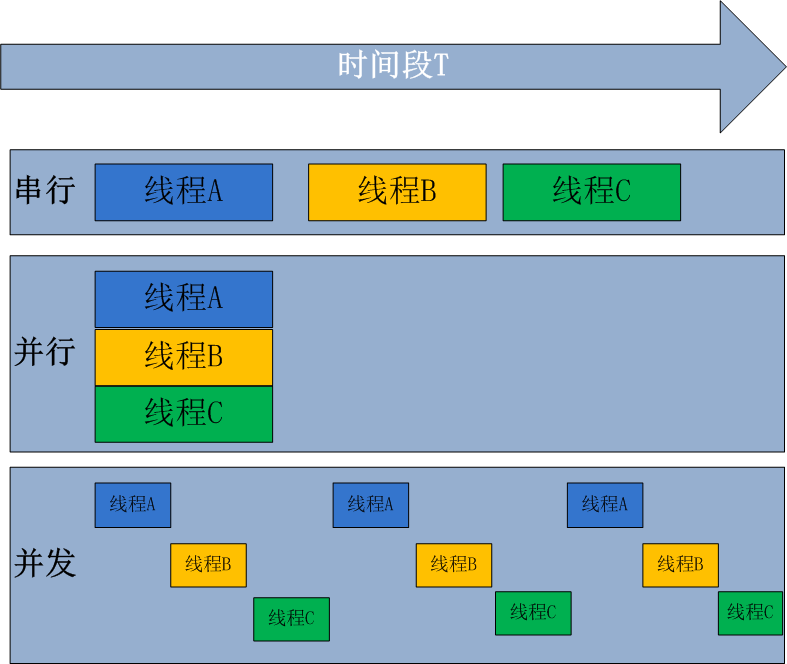
多道技术:内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)
同步执行:一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行
异步执行:一个进程在执行某个任务时,另外一个进程无需等待其执行完毕,就可以继续执行,当有消息返回时,系统会通知后者进行处理,这样可以提高执行效率
举个例子,打电话时就是同步通信,发短息时就是异步通信。
四、threading module
import threading
import time def countNum(n): # 定义某个线程要运行的函数 print("running on number:%s" %n) time.sleep(3) if __name__ == '__main__': t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例
t2 = threading.Thread(target=countNum,args=(34,)) t1.start() #启动线程
t2.start() print("ending!")
Thread类通过继承式创建
import threading
import time class MyThread(threading.Thread): def __init__(self,num):
threading.Thread.__init__(self)
self.num=num def run(self):
print("running on number:%s" %self.num)
time.sleep(3) t1=MyThread(56)
t2=MyThread(78) t1.start()
t2.start()
print("ending")
thread类的实例化方法
join():在子线程完成运行之前,这个子线程的父线程将一直被阻塞。
setDaemon(True):将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法。
import threading
from time import ctime,sleep
import time def Music(name): print ("Begin listening to {name}. {time}".format(name=name,time=ctime()))
sleep(3)
print("end listening {time}".format(time=ctime())) def Blog(title): print ("Begin recording the {title}. {time}".format(title=title,time=ctime()))
sleep(5)
print('end recording {time}'.format(time=ctime())) threads = [] t1 = threading.Thread(target=Music,args=('FILL ME',))
t2 = threading.Thread(target=Blog,args=('',)) threads.append(t1)
threads.append(t2) if __name__ == '__main__': #t2.setDaemon(True) for t in threads: #t.setDaemon(True) #注意:一定在start之前设置
t.start() #t.join() #t1.join()
#t2.join() # 分别使用t1与t2jion方法来试一试运行的时间 print ("all over %s" %ctime())
thread实例对象的方法除了上述以外还有:
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
threading模块的方法有:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread,currentThread,activeCount
import os,time,threading
def talk():
print('%s is running' %currentThread().getName()) if __name__ == '__main__':
# t=Thread(target=talk,name='egon')
t=Thread(target=talk)
t.start()
# print(t.name)
# print(t.getName())
# print(t.is_alive())
# print(currentThread().getName())
print(threading.enumerate())
time.sleep(3)
print(t.is_alive())
print('主',activeCount())
test
五、GIL全局解释锁
GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。
GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。在调用任何Python C API之前,要先获得GIL。
GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作。
解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。
GIL带来的影响,Python在执行一个进程的时候会淡定的在同一时刻只允许一个线程运行。python是无法利用多核CPU实现多线程的。这导致了python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。

解决这个问题的方法就是使用多进程,用multiprocessing替代Thread multiprocessing库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
#coding:utf8
from multiprocessing import Process
import time def counter():
i = 0
for _ in range(40000000):
i = i + 1 return True def main(): l=[]
start_time = time.time() for _ in range(2):
t=Process(target=counter)
t.start()
l.append(t)
#t.join() for t in l:
t.join() end_time = time.time()
print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__':
main() ''' py2.7:
串行:6.1565990448 s
并行:3.1639978885 s py3.5:
串行:6.556925058364868 s
并发:3.5378448963165283 s '''
计算密集型
这种方式也存在缺点:他引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量,对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocessing由于进程之间无法看到对方的数据,只能通过在主线程申明一个Queue,put再get或者用share memory的方法。这个额外的实现成本使得本来就非常痛苦的多线程程序编码,变得更加痛苦了。
因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能 - 如果对并行计算性能较高的程序可以考虑把核心部分也成C模块,或者索性用其他语言实现 - GIL在较长一段时间内将会继续存在,但是会不断对其进行改进。
计算密集型与I/O密集型pk:
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(4):
p=Process(target=work) #耗时5s多
p=Thread(target=work) #耗时18s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
计算密集型,多进程更优
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)
print('===>') if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(400):
# p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上
p=Thread(target=work) #耗时2s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
I/O密集型,多线程更优
六、lock
import time
import threading def addNum():
global num #在每个线程中都获取这个全局变量
#num-=1 temp=num
time.sleep(0.1)
num =temp-1 # 对此公共变量进行-1操作 num = 100 #设定一个共享变量 thread_list = [] for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t) for t in thread_list: #等待所有线程执行完毕
t.join() print('Result: ', num)
这个例子的问题在于全局变量num在阻塞时还没有进行减一的操作就切到另一个线程,另一个线程拿到的num变量还没来得及减一,所以如果time的时间加长那么得出的结果不是0,而是99,因为一秒以内足够完成这次操作,每个线程拿到的num都是100,减一得到99。所以我们需要一把锁,锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁:
import threading R=threading.Lock() R.acquire()
'''
对公共数据的操作
'''
R.release()
lock
死锁
死锁是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
import threading
import time mutexA = threading.Lock()
mutexB = threading.Lock() class MyThread(threading.Thread): def __init__(self):
threading.Thread.__init__(self) def run(self):
self.fun1()
self.fun2() def fun1(self): mutexA.acquire() # 如果锁被占用,则阻塞在这里,等待锁的释放 print ("I am %s , get res: %s---%s" %(self.name, "ResA",time.time())) mutexB.acquire()
print ("I am %s , get res: %s---%s" %(self.name, "ResB",time.time()))
mutexB.release()
mutexA.release() def fun2(self): mutexB.acquire()
print ("I am %s , get res: %s---%s" %(self.name, "ResB",time.time()))
time.sleep(0.2) mutexA.acquire()
print ("I am %s , get res: %s---%s" %(self.name, "ResA",time.time()))
mutexA.release() mutexB.release() if __name__ == "__main__": print("start---------------------------%s"%time.time()) for i in range(0, 10):
my_thread = MyThread()
my_thread.start()
死锁例子
这种情况下fun1与fun2都等待对方先把钥匙拿来所以产生了死锁现象,python解决这种死锁现象的方法就是使用RLock,RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,直到一个线程所有的acquire都被release,counter=0,其他的线程才能获得资源。
七、Event对象
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象(解决线程之间沟通的问题)。
对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。为真时它将唤醒所有等待这个Event对象的线程。
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
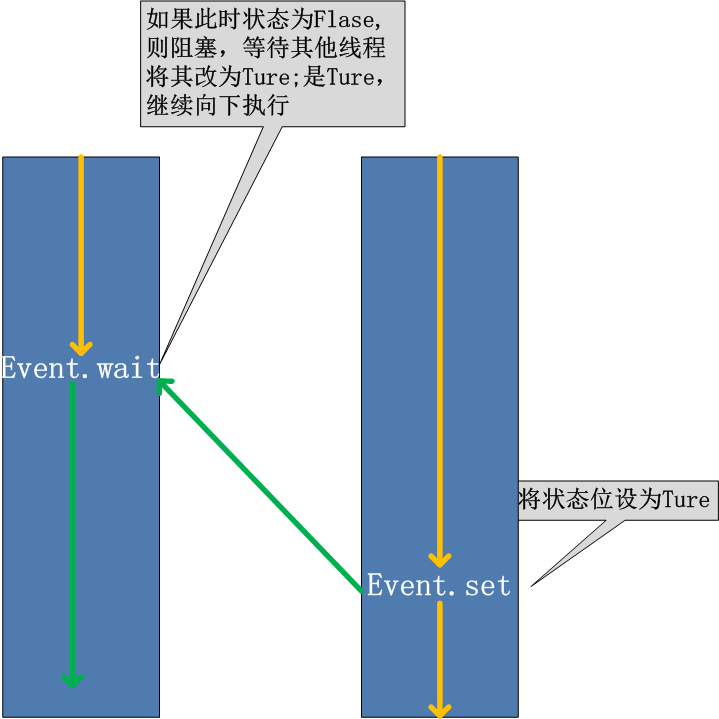
例如,我们有多个线程从Redis队列中读取数据来处理,这些线程都要尝试去连接Redis的服务,一般情况下,如果Redis连接不成功,在各个线程的代码中,都会去尝试重新连接。如果我们想要在启动时确保Redis服务正常,才让那些工作线程去连接Redis服务器,那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作:主线程中会去尝试连接Redis服务,如果正常的话,触发事件,各工作线程会尝试连接Redis服务。
import threading
import time
import logging logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',) def worker(event):
logging.debug('Waiting for redis ready...')
event.wait()
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1) def main():
readis_ready = threading.Event()
t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1')
t1.start() t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2')
t2.start() logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event')
time.sleep(3) # simulate the check progress
readis_ready.set() if __name__=="__main__":
main()
链接Redis
默认情况下如果事件一致没有发生,wait方法会一直阻塞下去,wait里的加参数就是如果阻塞时间超过这个参数设定的值之后,wait方法会返回。我们可以让子进程只要没连接上Redis,每隔几秒就提醒一下我们链接否。
def worker(event):
while not event.is_set():
logging.debug('Waiting for redis ready...')
event.wait(2)
logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime())
time.sleep(1)
监听Redis
python网络编程(线程)的更多相关文章
- python网络编程--线程(锁,GIL锁,守护线程)
1.线程 1.进程与线程 进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率.很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观 ...
- python网络编程-线程队列queue
一:线程queu作用 Python中,queue是线程间最常用的交换数据的形式. 队列两个作用:一个是解耦,一个是提高效率 二:语法 1)队列的类 class queue.Queue(maxsize= ...
- python网络编程--线程event
一:线程event作用 Python提供了Event对象用于线程间通信,它是线程设置的信号标志,如果信号标志位真,则其他线程等待直到信号结束. Event对象实现了简单的线程通信机制,它提供了设置信号 ...
- python网络编程--线程锁(互斥锁Mutex)
一:为什么需要线程锁 一个进程下可以启动多个线程,多个线程共享父进程的内存空间,也就意味着每个线程可以访问同一份数据,此时,如果2个线程同时要修改同一份数据,会出现什么状况? 很简单,假设你有A,B两 ...
- python网络编程--线程join和Daemon(守护进程)
一:什么情况下使用join join([timeout])调用join函数会使得主调线程阻塞,直到被调用线程运行结束或超时. 参数timeout是一个数值类型,用来表示超时时间,如果未提供该参数,那么 ...
- python网络编程--线程使用threading
一:线程使用 线程使用有两种方法,一种是直接使用,二是通过继承threading.Thread类使用 二:函数式使用 函数式:调用thread模块中的start_new_thread()函数来产生新线 ...
- python网络编程--线程GIL(全局解释器锁)
一:什么是GIL 在CPython,全局解释器锁,或GIL,是一个互斥体防止多个本地线程执行同时修改同一个代码.这把锁是必要的主要是因为当前的内存管理不是线程安全的.(然而,由于GIL存在,其他特性已 ...
- python网络编程--线程的方法,线程池
一.线程的其他方法(Thread其他属性和方法) ident() 获取线程id Thread实例对象的方法 isAlive() 设置线程名 getName() 返回线程名 setName() 设置线程 ...
- python网络编程--线程Semaphore(信号量)
一:Semaphore(信号量) 互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才 ...
- python网络编程--线程递归锁RLock
一:死锁 所谓死锁:是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进 ...
随机推荐
- jenkins - ssh Server Groups Center
- (转)log4j(四)——如何控制不同风格的日志信息的输出?
一:测试环境与log4j(一)——为什么要使用log4j?一样,这里不再重述 1 老规矩,先来个栗子,然后再聊聊感受 import org.apache.log4j.*; //by godtrue p ...
- linux查看是否安装Apache,mysql,python等
1.Apache httpd -v service httpd start 启动 service httpd restart 重新启动 service httpd stop 停止服务 2.mysql ...
- Eclipse详细设置护眼背景色和字体颜色并导出
Eclipse详细设置护眼背景色和字体颜色并导出 Eclipse是一款码农们喜闻乐见的集成开发平台,但是其默认的主题和惨白的背景色实在是太刺激眼球了.下面,将给大家详细介绍如何设置成护眼主题的方法,也 ...
- Android 类似duplicate entry: android/support/v4/internal/view/SupportSubMenu.class问题解决办法汇总
这种问题一般是v4或者v7包版本不一致导致的. 一般情况下进行在你的工程的入口module的build.gradle 的android标签下defaultConfig子标签中 添加如下的配置就能解决. ...
- jsp 之 解决 Mysql net start mysql启动,提示发生系统错误 5 拒绝访问的问题
在dos下运行net start mysql时 !!!提示发生系统错误 5:拒绝访问!只要切换到管理员模式就可以启动了. 所以我们要以管理员身份来运行cmd程序来启动mysql. 1.在开始菜单的搜索 ...
- 红帽 Red Hat Linux相关产品iso镜像下载【百度云】(转载)
不为什么,就为了方便搜索,特把红帽EL 5.EL6.EL7 的各版本整理一下,共享出来.正式发布 6.9 :RedHat Enterprise Server 6.9 for x86_64:rhel-s ...
- 13. leetcode 453. Minimum Moves to Equal Array Elements
Given a non-empty integer array of size n, find the minimum number of moves required to make all arr ...
- NYOJ--325--深度优先搜索--zb的生日
/* Name: NYOJ--325--zb的生日 Author: shen_渊 Date: 15/04/17 08:18 Description: 输入时计算总质量,DFS搜索和总质量差值一般最接近 ...
- 身在魔都的她,该不该继续"坚持"前端开发?
一 这个女孩儿,是我很好很好很好的一位朋友,也是中学的同学,去年从她的本科大学毕业,毕业后由于没找到合适的工作而选择去培训机构培训了比较火爆的前端开发,之后去了上海找工作,但是由于一些原因在从上一家公 ...