scrapy爬虫框架之理解篇(个人理解)
提问: 为什么使用scrapy框架来写爬虫 ?
在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的10%的吗?显然不是。scrapy框架是为了让我们的爬虫更强大、更高效。接下来我们一起学习一下它吧。
1.scrapy 的基础概念:
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html

2. scrapy 的工作流程:
之前我们所写爬虫的流程:
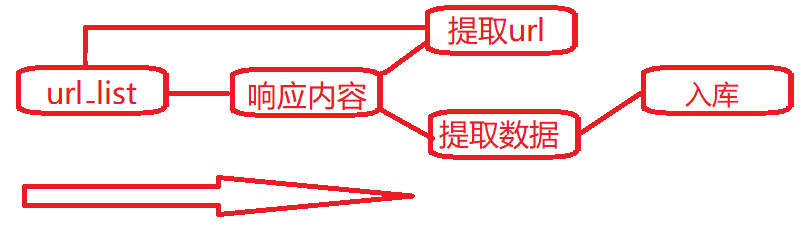
那么 scrapy是如何帮助我们抓取数据的呢?
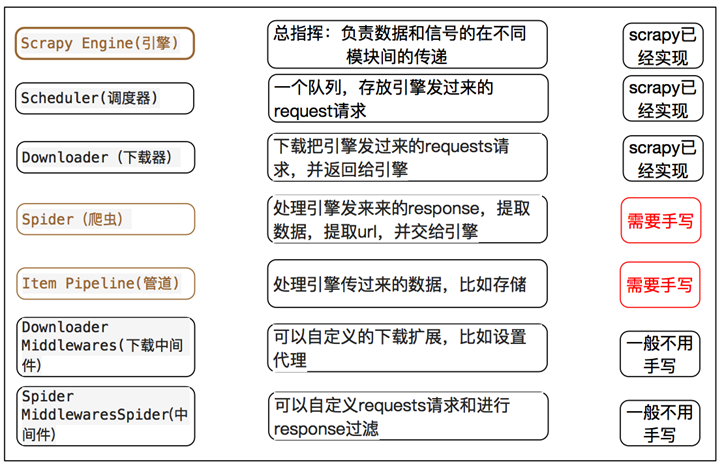
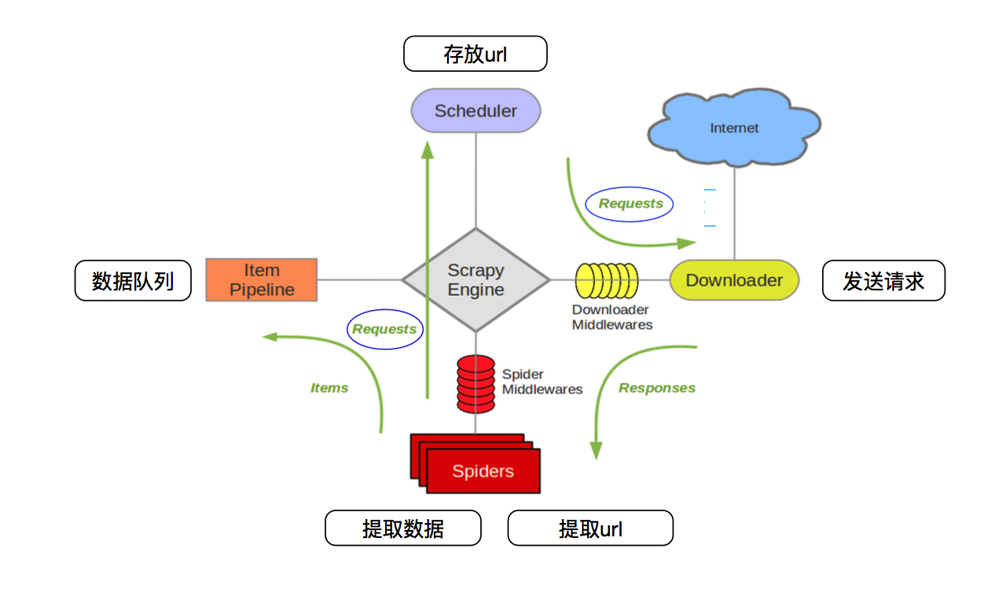
scrapy框架的工作流程:1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy爬虫框架之理解篇(个人理解)的更多相关文章
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
随机推荐
- 记一次使用快速幂与Miller-Rabin的大素数生成算法
大家都知道RSA的加密的安全性就是能够找到一个合适的大素数,而现在判断大素数的办法有许多,比如Fermat素性测试或者Miller-Rabin素性测试,而这里我用了Miller-Rabin素性测试的算 ...
- MSSQL查询数据分页
这几天刚好碰到数据的分页查询,觉得不错,Mark一下,方法有两种,都是使用select top,效率如何就不在这讨论 方法1:利用select top配合not in(或者not exists),查询 ...
- scala位压缩与行情转换二进制
import org.jboss.netty.buffer.{ChannelBuffers, ChannelBuffer} import java.nio.charset.Charset import ...
- Android基础知识笔记01—框架结构与四大组件
-----------Andriod 01--------------->>> Andriod系统架构 linux内核与驱动层. 系统运行库层. 应用框架层. 应用层 内核驱动 ...
- css 页面特殊显示效果
1.移动端最小设置字体为12px,如果想要更小字体效果: -webkit-transform:scale(0.9); 2.文字超过两行时,末尾显示点点的效果: overflow:hidden;text ...
- Golang开发者常见的坑
Golang开发者常见的坑 目录 [−] 初级 开大括号不能放在单独的一行 未使用的变量 未使用的Imports 简式的变量声明仅可以在函数内部使用 使用简式声明重复声明变量 偶然的变量隐藏Accid ...
- 前端页面中如何在窗口缩放时让两个div始终在同一行显示
直接贴代码吧 先总结一下吧 有两种方法 一 最外层设置一个大div 给这个大div固定的宽度和高度 给里面两个小div 设置浮动 设置宽高 <!DOCTYPE html> &l ...
- JS难点--组件开发
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 15.0px Consolas; color: #a5b2b9 } span.Apple-tab-span ...
- 【20171025中】alert(1) to win 脚本渲染自建
游戏误人生,一下午玩了将近四个小时的三国杀,后悔不已,然后重新拾起xss challenge,突发奇想,自己构建渲染后的html. 从最简单的开始. 自动检测html: <!DOCTYPE ht ...
- 日志管理之 Docker logs - 每天5分钟玩转 Docker 容器技术(87)
高效的监控和日志管理对保持生产系统持续稳定地运行以及排查问题至关重要. 在微服务架构中,由于容器的数量众多以及快速变化的特性使得记录日志和监控变得越来越重要.考虑到容器短暂和不固定的生命周期,当我们需 ...