redis复制原理和应用
1.前言
说到分布式高可用,必然少不了复制,一来是为了做个冗余备份防止数据丢失,二来还可以达到分流来提高性能的目的。基本架构:
下面用M表示Master(主服务器),S表示Slave(从服务器),话不多说,先敲代码
2.配置
- slaveof 192.168.1.1 6379
在S端配置slaveof就可以实现复制了,意思是我从192.168.1.1 6379这台M复制数据。注意第一次复制的时候S上面的数据会被覆盖。下面就在我的虚拟机上面实操一下,配置3台redis,6379是M,6380、6381是S
配置M
- $ cp redis.conf redis_6379.conf
- $ vi redis_6379.conf
- bind 192.168.56.10 #修改ip为本机
配置S
- $ cp redis_6379.conf redis_6380.conf
- $ vi redis_6380.conf
- #修改端口号和pid文件名
- port 6380
- pidfile /var/run/redis_6380.pid
- slaveof 192.168.56.10 6379 #设定复制
- #同样拷贝一份配置按照上面的步骤修改6381的配置
- $ cp redis_6380.conf redis_6381.conf
启动
- $ src/redis-server redis_6379.conf
- $ src/redis-server redis_6380.conf
- $ src/redis-server redis_6381.conf
测试复制
- $ src/redis-cli -h 192.168.56.10 -p 6379
- 192.168.56.10:6379> set name pigfly
- OK
- 192.168.56.10:6379> quit
- $ src/redis-cli -h 192.168.56.10 -p 6380
- 192.168.56.10:6380> get name
- "pigfly" #复制成功
- 192.168.56.10:6380> quit
- $ src/redis-cli -h 192.168.56.10 -p 6379
- 192.168.56.10:6379> del name
- (integer) 1
- 192.168.56.10:6379> quit
- $ src/redis-cli -h 192.168.56.10 -p 6380
- 192.168.56.10:6380> get name
- (nil) #删除同步成功
- 192.168.56.10:6380> set age 23
- #注意S只读,这是默认配置,如果要S可写修改read-only=no
#一般来说不建议这样做,因为复制的时候会把数据覆盖- (error) READONLY You can't write against a read only slave.
- 192.168.56.10:6380> quit
- $ src/redis-cli -h 192.168.56.10 -p 6379
- 192.168.56.10:6379> setex address 10 xxstreat
- OK
- 192.168.56.10:6379> quit
- $ src/redis-cli -h 192.168.56.10 -p 6380
- 192.168.56.10:6380> get address
- (nil) #过期同步成功
3.原理
当M和S连接正常时,redis通过命令传播来同步数据,每当M执行一个写命令,就会把命令发送给S,S执行后,两者达到数据的一致性。当S第一次连接或者断线后重连M的时候,复制过程是这样子的:
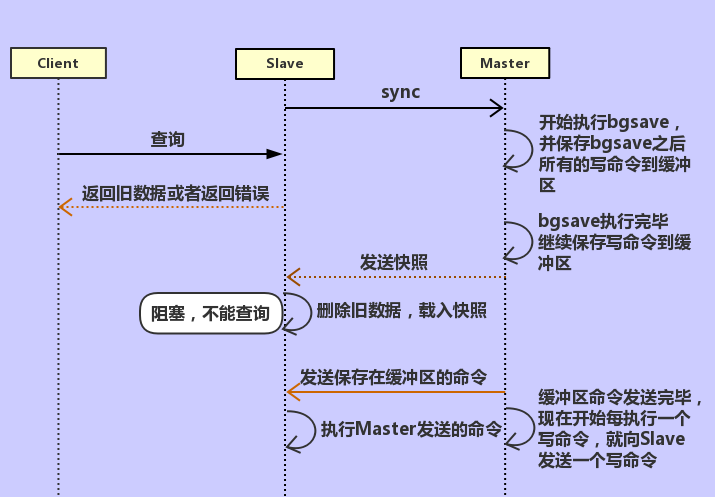
这个过程也可以称作是sync全量复制,每一次复制,M执行bgsave把所有数据打包成快照文件发给S,S再解包载入内存。
M执行bgsave消耗CPU、内存、磁盘I/O,传输过程消耗网络带宽,如果S是第一次连接M,不可避免会执行上述操作,但如果S是断线重连的情况,就有点不划算了,因为S真正需要复制的数据是断线以后的,如果全量复制就太浪费资源和时间了,所以redis2.8以后的版本做了改进,加了psync增量复制,psync(part-sync)跟sync不同的是,psync只发送S真正需要的命令流,大大地提高了打包和传输的效率,那么redis是怎么实现增量复制的呢?
replid, offset
每个M和S都有上面这两个属性,replid是M的唯一标识。offset是命令流的字节数,简单来说,只要有写入命令(就算没有S),这个offset就会增加

M维护着上图这样一个固定长度、先进先出的队列来保存最近的命令流

上图就是增量复制的过程,假定S当前offset=offset_s,M当前offset=offset_m:
1.M判断replid是否和自己的replid相等,如果不相等,跳出执行全量复制
2.M检查offset_s是否还在缓冲队列,如果是,发送从offset_s开始到offset_m的命令流,如果没有了,跳出执行全量复制
3.S执行命令流,更新offset_s = offset_m
复制的机制和特点:
- 当M和S连接良好时,S定时请求M进行复制,M向S发送命令流来保持同步
- redis默认使用高性能的异步复制,S会异步向M确认收到的数据
- 当M和S由于网络问题或者超时导致断开连接,S会尝试重新连接,请求增量复制
- 不能增量复制时,执行全量复制
- 一个M可以有多个S
- S也可以复制其他S
- 复制在M端是非阻塞的,也就是M向S复制的过程中,M的查询不受影响
- 复制在S端也基本上是非阻塞的,初始化同步的时候,S可以提供旧数据来使查询不受影响,载入数据的时候,S将会阻塞连接不提供查询服务(非常大的数据也只需要短短几秒就同步完了),旧数据将会被删除,新数据将会被载入
- 可以把耗时查询放到S上面来提高主机的性能
- 可以使用复制来避免M持久化带来的开销,让一个S来持久化,但是应该避免M重启,因为M重启之后数据是空的,这时候如果同步的话S的数据也变成空了。就算是用redis的sentinel实现的高可用方案,也不要把持久化关了,说不定sentinel还没来得及检测到故障,M就已经宕机然后重启了。为了避免这种情况,建议M和S都打开持久化,下面就演示数据是如何丢失的:
- A,B,C三台redis服务器,A是M,B和C是S
- 因为某些原因,A宕机了,它执行自动重启机制,这时候因为关闭了持久化,磁盘里是没有备份数据的,内存里的数据也因为重启丢失了,所以重启之后数据全部丢了
- B和C尝试同步,它们也不管A的数据是不是空,照常同步过来了,所以B和C的数据也丢了
redis复制如何处理过期的缓存?
- S不处理,而是等M处理过期后给S发送DEL命令
- 当M没有及时发送DEL命令,导致过期的缓存仍然存在于S,S将会根据自己的逻辑时钟报告缓存已过期,并且设置为只读
- Lua脚本运行的时候,不执行缓存回收
- 一旦S变身为M,它马上自个儿执行缓存回收
使用Docker和NAT的情况,如何配置?
使用端口转发和网络地址转换的时候,redis复制要特别小心,特别是使用redis-sentiner,它是根据INFO命令来获取IP地址的,这种情况下可以配置IP端口映射,来让M获取到S正确的地址:
- slave-announce-ip 5.5.5.5
- slave-announce-port 1234
这样M执行INFO命令看到S的IP就是映射过的:
- # Replication
- role:master
- connected_slaves:1
- slave0:ip=5.5.5.5,port=1234,state=online,offset=420,lag=1
INFO命令
通过info命令可以查看复制的参数和状态
- $ src/redis-cli -h 192.168.56.10 -p 6381
- 192.168.56.10:6381> info
- # Replication
- role:master
- connected_slaves:1
- slave0:ip=192.168.56.10,port=6379,state=online,offset=644,lag=1
- master_replid:b01608293384f8ea87b5bd0aabe081948f33a3dd
- master_replid2:0000000000000000000000000000000000000000
- master_repl_offset:644
- second_repl_offset:-1
- repl_backlog_active:1
- repl_backlog_size:1048576
- repl_backlog_first_byte_offset:1
- repl_backlog_histlen:644
4.性能优化
1.调整缓冲队列的大小来尽可能达到增量复制而避免全量复制,repl-backlog-size默认1mb
5.参考资料
redis实战
redis设计与实现
redis复制原理和应用的更多相关文章
- 深入理解redis复制原理
原文:深入理解redis复制原理 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了 slaveof ...
- Redis 复制原理及特性
摘要 早期的RDBMS被设计为运行在单个CPU之上,读写操作都由经单个数据库实例完成,复制技术使得数据库的读写操作可以分散在运行于不同CPU之上的独立服务器上,Redis作为一个开源的.优秀的key- ...
- Redis从出门到高可用--Redis复制原理与优化
Redis从出门到高可用–Redis复制原理与优化 单机有什么问题? 1.单机故障; 2.单机容量有瓶颈 3.单机有QPS瓶颈 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/s ...
- 搞懂Redis复制原理
前言 与大多数db一样,Redis也提供了复制机制,以满足故障恢复和负载均衡等需求.复制也是Redis高可用的基础,哨兵和集群都是建立在复制基础上实现高可用的.复制不仅提高了整个系统的容错能力,还可以 ...
- Redis复制原理
无论是在集群中还是主从结构中,redis新加入的节点和已有主(从)节点的消息同步都是通过sync命令的形式 下面来实践一下redis的同步机制, 新建主服务器于从服务器 主 从: 这是正常的主从结 ...
- Redis 复制原理及分析
1.测试 见master-slave测试帖 2 原理 第一次.Slave向Master同步的实现是: Slave向Master发出同步请求(发送sync命令),Master先dump出rdb文件,然后 ...
- Redis 之深入江湖-复制原理
一.前言 上一篇文章Redis 之复制-初入江湖中,讲了关于Redis复制配置,如:如何建立配置.如何断开复制.关于链接的安全性等等,那么本篇文章将深入的去说一下关于Redis复制原理,如下: 复制过 ...
- Redis复制实现原理
摘要 我的前一篇文章<Redis 复制原理及特性>已经介绍了Redis复制相关特性,这篇文章主要在理解Redis复制相关源码的基础之上介绍Redis复制的实现原理. Redis复制实现原理 ...
- redis系列--主从复制以及redis复制演进
一.前言 在之前的文章已经详细介绍了redis入门基础已经持久化相关内容包括redis4.0所提供的混合持久化. 通过持久化功能,Redis保证了即使在服务器宕机情况下数据的丢失非常少.但是如果这台服 ...
随机推荐
- 面向接口编程实现不改代码实现Redis单机/集群之间的切换
开发中一般使用Redis单机,线上使用Redis集群,因此需要实现单机和集群之间的灵活切换 pom配置: <!-- Redis客户端 --> <dependency> < ...
- Java的继承、封装与多态
Java的继承.封装与多态 基本概念 面向对象OO(Object Oriented):把数据及对数据的操作方法放在一起,作为一个相互依存的整体,即对象. 对同类对象抽象出共性,即类. 比如人就是一个类 ...
- idea 创建多模块依赖Maven项目
本来网上的教程还算多,但是本着自己有的才是自己的原则,还是自己写一份的好,虽然可能自己也不会真的用得着. 1. 创建一个新maven项目 2. 3. 输入groupid和artifactid,后面步骤 ...
- 关于对vector3及其衍生变量的理解
关于对vector3,vector2类及其衍生变量的理解 vector3简单来讲即表示向量和点的系统类,这个结构用于处理向量和点,也包含许多做向量运算的函数. 而vector2即少一维向量的类,用于处 ...
- Leetcode题解(十五)
42.Trapping Rain Water 题目 这道题目参考http://www.cnblogs.com/felixfang/p/3713197.html 观察下就可以发现被水填满后的形状是先升后 ...
- HDU 5783 Divide the Sequence (训练题002 B)
Description Alice has a sequence A, She wants to split A into as much as possible continuous subsequ ...
- EduSoho程序上线实录
1.1 修改配置文件 [root@web01 nginx]# cat /application/nginx/conf/extra/edusoho.conf server { listen 80; se ...
- R-CNN论文翻译——用于精确物体定位和语义分割的丰富特征层次结构
原文地址 我对深度学习应用于物体检测的开山之作R-CNN的论文进行了主要部分的翻译工作,R-CNN通过引入CNN让物体检测的性能水平上升了一个档次,但该文的想法比较自然原始,估计作者在写作的过程中已经 ...
- windows查看端口占用命令
开始--运行--cmd 进入命令提示符 输入netstat -aon 即可看到所有连接的PID 之后在任务管理器中找到这个PID所对应的程序如果任务管理器中没有PID这一项,可以在任务管理器中选&qu ...
- 通讯框架 T-io 学习——给初学者的Demo:ShowCase设计分析
前言 最近闲暇时间研究Springboot,正好需要用到即时通讯部分了,虽然springboot 有websocket,但是我还是看中了 t-io框架.看了部分源代码和示例,先把helloworld敲 ...