L0/L1/L2范数的联系与区别
L0/L1/L2范数的联系与区别
标签(空格分隔): 机器学习
最近快被各大公司的笔试题淹没了,其中有一道题是从贝叶斯先验,优化等各个方面比较L0、L1、L2范数的联系与区别。
L0范数
L0范数表示向量中非零元素的个数:
\(||x||_{0} = \#(i)\ with\ \ x_{i} \neq 0\)
也就是如果我们使用L0范数,即希望w的大部分元素都是0. (w是稀疏的)所以可以用于ML中做稀疏编码,特征选择。通过最小化L0范数,来寻找最少最优的稀疏特征项。但不幸的是,L0范数的最优化问题是一个NP hard问题,而且理论上有证明,L1范数是L0范数的最优凸近似,因此通常使用L1范数来代替。
L1范数 -- (Lasso Regression)
L1范数表示向量中每个元素绝对值的和:
\(||x||_{1} = \sum_{i=1}^{n}|x_{i}|\)
L1范数的解通常是稀疏性的,倾向于选择数目较少的一些非常大的值或者数目较多的insignificant的小值。
L2范数 -- (Ridge Regression)
L2范数即欧氏距离:
\(||x||_{2} = \sqrt{\sum_{i=1}^{n}x_{i}^{2}}\)
L2范数越小,可以使得w的每个元素都很小,接近于0,但L1范数不同的是他不会让它等于0而是接近于0.
L1范数与L2范数的比较:
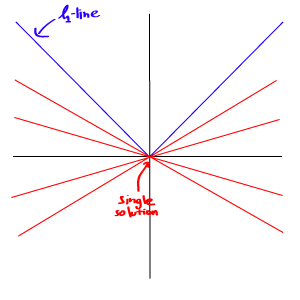
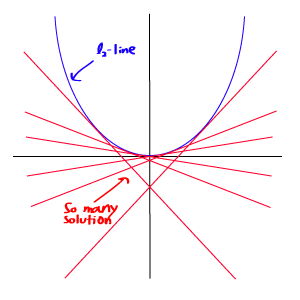
但由于L1范数并没有平滑的函数表示,起初L1最优化问题解决起来非常困难,但随着计算机技术的到来,利用很多凸优化算法使得L1最优化成为可能。
贝叶斯先验
从贝叶斯先验的角度看,加入正则项相当于加入了一种先验。即当训练一个模型时,仅依靠当前的训练数据集是不够的,为了实现更好的泛化能力,往往需要加入先验项。
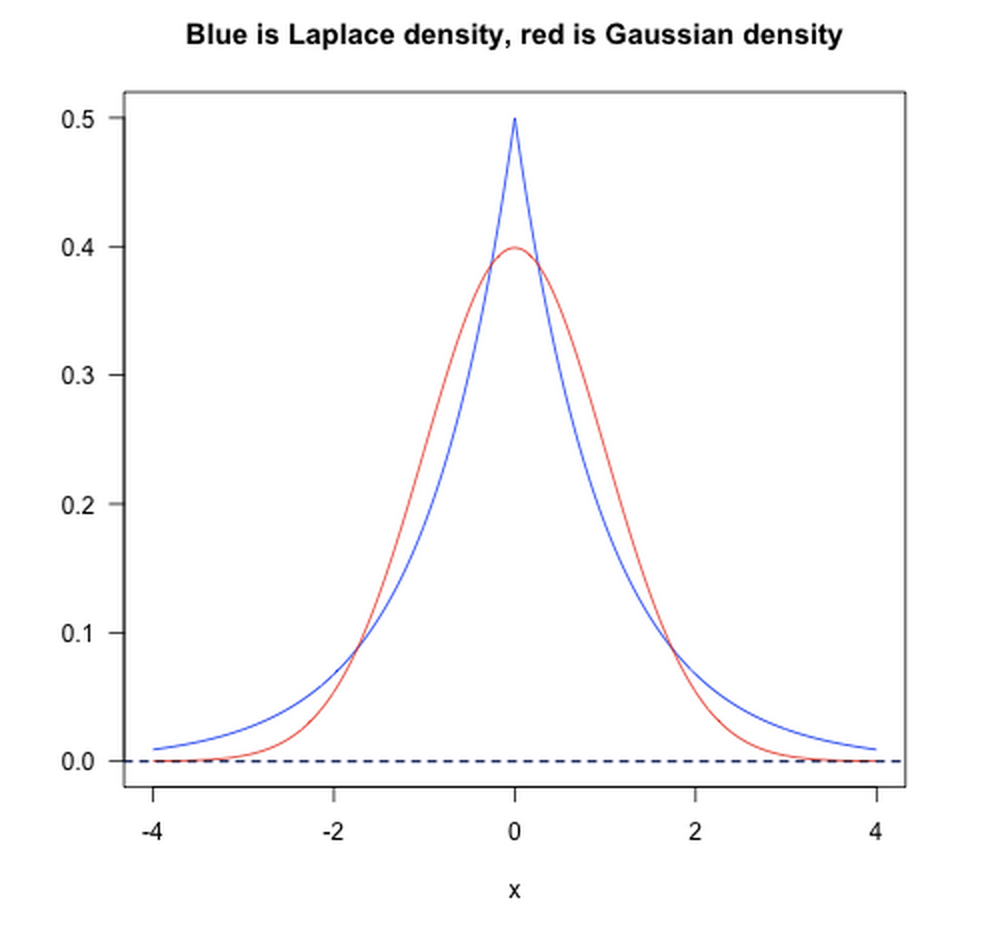
- L1范数相当于加入了一个Laplacean先验;
- L2范数相当于加入了一个Gaussian先验。
如下图所示:
【Reference】
1. http://blog.csdn.net/zouxy09/article/details/24971995
2. http://blog.sciencenet.cn/blog-253188-968555.html
3. http://t.hengwei.me/post/%E6%B5%85%E8%B0%88l0l1l2%E8%8C%83%E6%95%B0%E5%8F%8A%E5%85%B6%E5%BA%94%E7%94%A8.html
L0/L1/L2范数的联系与区别的更多相关文章
- L0/L1/L2范数(转载)
一.首先说一下范数的概念: 向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离. 向量的范数定义:向量的范数是一个函数||x||,满足非负性||x|| > ...
- 机器学习中正则惩罚项L0/L1/L2范数详解
https://blog.csdn.net/zouxy09/article/details/24971995 原文转自csdn博客,写的非常好. L0: 非零的个数 L1: 参数绝对值的和 L2:参数 ...
- 机器学习中的规则化范数(L0, L1, L2, 核范数)
目录: 一.L0,L1范数 二.L2范数 三.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问 ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- 13. L1,L2范数
讲的言简意赅,本人懒,顺手转载过来:https://www.cnblogs.com/lhfhaifeng/p/10671349.html
- L1与L2损失函数和正则化的区别
本文翻译自文章:Differences between L1 and L2 as Loss Function and Regularization,如有翻译不当之处,欢迎拍砖,谢谢~ 在机器学习实 ...
- L0、L1及L2范数
L1归一化和L2归一化范数的详解和区别 https://blog.csdn.net/u014381600/article/details/54341317 深度学习——L0.L1及L2范数 https ...
- Machine Learning系列--L0、L1、L2范数
今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大,为了不吓到大家,我将这个五个 ...
随机推荐
- zw版_zw中文增强版Halcon官方Delphi例程
[<zw版·delphi与halcon系列原创教程>zw版_zw中文增强版Halcon官方Delphi例程 源码下载:http://files.cnblogs.com/files/ziwa ...
- Java笔试题解答和部分面试题
面试类 银行类的问题 问题一:在多线程环境中使用HashMap会有什么问题?在什么情况下使用get()方法会产生无限循环? HashMap本身没有什么问题,有没有问题取决于你是如何使用它的.比如,你 ...
- OpenStack 新加计算节点后修改
Contents [hide] 1 前提 2 iptables禁止snat= 3 vlan支持 4 Quota支持 5 修改物理资源设置. 6 添加collectd 7 重启服务 前提 我们使用fue ...
- [转]Delphi多线程编程入门(二)——通过调用API实现多线程
以下是一篇很值得看的关于Delphi多线程编程的文章,内容很全面,建议收藏. 一.入门 ㈠. function CreateThread( lpThreadAttributes: Pointer ...
- android textView 添加超链接(两种实现方式)
在textView添加超链接,有两种方式,第一种通过HTML格式化你的网址,一种是设置autolink,让系统自动识别超链接,下面为大家介绍下这两种方法的实现 在textView添加超链接,有两种方式 ...
- owner window 和 parent window 有什么区别?
1.Pop-up窗口: 一个弹出窗口是必须具有WS_POPUP属性的窗口,弹出窗口只能是一个Top-Level窗口,不能是子窗口,弹出窗口多用于对话框和消 ...
- zabbix源码安装
Zabbix通过C/S模式采集数据,通过B/S模式在web端展示和配置. 被监控端:主机通过安装agent方式采集数据,网络设备通过SNMP方式采集数据 Server端:通过收集SNMP和agent发 ...
- Linux系统中“动态库”和“静态库”那点事儿【转】
转自:http://blog.chinaunix.net/uid-23069658-id-3142046.html 今天我们主要来说说Linux系统下基于动态库(.so)和静态(.a)的程序那些猫腻. ...
- git简介及安装配置
Git是一种分布式版本控制系统.它和集中式版本控制系统的区别有如下几点: 1).分布式版本控制没有中央服务器,每个人的电脑上都有完整的版本库: 2).分布式管理系统的安全性要高,如果某一台电脑的坏了, ...
- JSONArray传值的使用小结
今天使用了SpringMVC+mybatis传值.从controller中传到service中.可是由于版本问题参数中不能有大写和下划线,在service中只能用String 来接受json字符串.接 ...