关于fork函数中的内存复制和共享
原来刚刚开始做linux下面的多进程编程的时候,对于下面这段代码感到很奇怪,
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop; for(loop=;loop<LEN;loop++)
{
if((pid=fork()) < )
err_exit("[fork:%d]: ",loop);
else if(pid == )
{
printf("Child process\n");
}
else
{
sleep();
}
} return ;
}
为什么这段程序会创建3个子进程,而不是两个,为什么在第20行后面加上一个return 0;就创建的又是两个子进程了?原来一直搞不明白,后来了解了C语言程序的存储空间布局以及在fork之后父子进程是共享正文段(代码段CS)之后才明白这其中的缘由!具体原理是啥,且容我慢慢道来!
首先得明白一个东西就是C程序的存储空间布局,如下图所示:
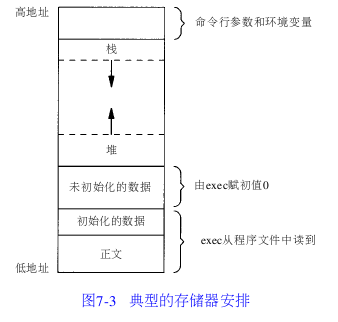 (原图出自《UNIX环境高级编程》7.6节)
(原图出自《UNIX环境高级编程》7.6节)
当一个C程序执行之后,它会被加载到内存之中,它在内存中的布局如上图,分为这么几个部分,环境变量和命令行参数、栈、堆、数据段(初始化和未初始化的)、正文段,下面挨个来说明这几段分别代表了什么:
环境变量和命令行参数:这些指的就是Unix系统上的环境变量(比如$PATH)和传给main函数的参数(argv指针所指向的内容)。
数据段:这个是指在C程序中定义的全局变量,如果没有初始化,那么就存放在未初始化的数据段中,程序运行时统一由exec赋值为0。否则就存放在初始化的数据段中,程序运行时由exec统一从程序文件中读取。(了解汇编的朋友们想必知道汇编语言中的数据段DS,这和汇编中的数据段其实是一个东西)。
堆:这一部分主要用来动态分配空间。比如在C语言中用malloc申请的空间就是在这个区域申请的。
正文段:C语言代码并不是直接执行的,而是被编译成了机器指令才能够在电脑上执行,最终生成的机器指令就是存放在这个区域(汇编中的代码段CS指的就是这片区域)。
栈:个人感觉这是C程序内存布局最关键的部分了。这个部分主要用来做函数调用。具体而言怎么说呢,程序刚开始栈中只有main这一个函数的内容(即main的栈帧),如果main函数要调用func函数,那么func函数的返回地址(main函数的地址),func函数的参数,func函数中定义的局部变量,还有func函数的返回值等等这些都会被压入栈中,这时栈中就多了func函数的内容(func的栈帧)。然后func函数运行完了之后再来弹栈,把它原来压的内容去掉(即清除掉func栈帧),此时栈中又只剩下了main的栈帧。(这片区域就是汇编中的栈段SS)
OK,这就是C程序的存储器布局。这里我联想到另外一点,就是全局变量和静态变量是存储在数据段中的,而局部变量是存储在栈中的,栈中数据在函数调用完之后一弹栈就没了,这就是为什么全局变量的生存周期比局部变量的生存周期要长的原因。
了解了C程序在存储器的布局之后,我们再来了解fork的内存复制机制,关于这个,我们只需要了解一句话就够了,“子进程复制父进程的数据空间(数据段)、栈和堆,父、子进程共享正文段。”也就是说,对于程序中的数据,子进程要复制一份,但是对于指令,子进程并不复制而是和父进程共享。具体来看下面这段代码(这是我在上面那段代码上稍微添加了一点东西):
/* 这个程序会创建3个子进程,理解这句话,父子进程复制数据段、栈、堆,共享正文段
*
*/
#include<unistd.h>
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<stdarg.h>
#include<errno.h>
#define BUFSIZE 512
#define LEN 2
void err_exit(char *fmt,...);
int main(int argc,char *argv[])
{
pid_t pid;
int loop; for(loop=;loop<LEN;loop++)
{
printf("Now is No.%d loop:\n",loop); if((pid=fork()) < )
err_exit("[fork:%d]: ",loop);
else if(pid == )
{
printf("[Child process]P:%d C:%d\n",getpid(),getppid());
}
else
{
sleep();
}
} return ;
}
为什么上面那段代码会创建三个子进程?我们来具体分析一下它的执行过程:
首先父进程执行循环,通过fork创建一个子进程,然后sleep5秒。
再来看父进程创建的这个子进程,这里我们记为子进程1.子进程1完全复制了这个父进程的数据部分,但是需要注意的是它的正文段是和父进程共享的。也就是说,子进程1开始执行代码的部分并不是从main的 { 开始执行的,而是主函数执行到哪里了,它就接着执行,具体而言就是它会执行fork后面的代码。所以子进程1首先会打印出它的ID和它的父进程的ID。然后继续第二遍循环,然后这个子进程1再来创建一个子进程,我们记为子进程11,子进程1开始sleep。
子进程11接着子进程1执行的代码开始执行(即fork后面),它也是打印出它的ID和父进程ID(子进程1),然后此时loop的值再加1就等于2了,所以子进程2直接就返回了。
那个子进程1sleep完了之后也是loop的值加1之后变成了2,所以子进程1也返回了!
然后我们再返回去看父进程,它仅仅循环了一次,sleep完之后再来进行第二次循环,这次又创建了一个子进程我们记为子进程2。然后父进程开始sleep,sleep完了之后也结束了。
那么那个子进程2怎么样了呢?它从fork后开始执行,此时loop等于1,它打印完它的ID和父进程ID之后,就结束循环了,整个子进程2就直接结束了!
这就是上面那段代码的运行流程,进程间的关系如下图所示:

上图中那个loop=%d就是当这个进程开始执行的时候loop的值。上面那段代码的运行结果如下图:

这里这个3498进程就是我们的主进程,3499就是子进程1,3500就是子进程11,3501就是子进程2。
最后,我们再来回答一下我们开始的时候提出的那个问题,为什么在子进程的处理部分“ if(pid == 0) ”最后加一个return 0,就会创建两个子进程了,就是因为子进程1运行到这里直接就结束了,不再进行第二遍循环了,所以就不会再去创建那个子进程11了,所以最后一共就是创建了两个子进程啊!
关于fork函数中的内存复制和共享的更多相关文章
- c++中函数中变量内存分配以及返回指针、引用类型的思考
众所周知,我们在编程的时候经常会在函数中声明局部变量(包括普通类型的变量.指针.引用等等). 同时,为了满足程序功能的需要,函数的返回值也经常是指针类型或是引用类型,而这返回的指针或是引用也经常指向函 ...
- 深入解析Linux中的fork函数
1.定义 #include <unistd.h> #include<sys/types.h> pid_t fork( void ); pid_t 是一个宏定义,其实质是int, ...
- 关于fork( )函数父子进程返回值的问题
fork()是linux的系统调用函数sys_fork()的提供给用户的接口函数,fork()函数会实现对中断int 0x80的调用过程并把调用结果返回给用户程序. fork()的函数定义是在init ...
- Linux环境fork()函数详解
Linux环境fork()函数详解 引言 先来看一段代码吧, 1 #include <sys/types.h> 2 #include <unistd.h> 3 #include ...
- 浅谈C++中对象的复制与对象之间的相互赋值
C++对象的复制 有时需要用到多个完全相同的对象,例如,同一型号的每一个产品从外表到内部属性都是一样的,如果要对每一个产品分别进行处理,就需要建立多个同样的对象,并要进行相同的初始化,用以前的办法定义 ...
- 知识点查缺补漏贴02:Linux环境fork()函数详解
引言 先来看一段代码吧, #include <sys/types.h> #include <unistd.h> #include <stdio.h> #includ ...
- C++中动态内存申请的结果
1,问题: 1,动态内存申请一定成功吗? 1,不一定成功: 2,常见的动态内存分配代码: 1,C 代码: * sizeof(int)); if( p != NULL ) { // ... ... } ...
- Java中JVM内存结构
Java中JVM内存结构 线程共享区 方法区: 又名静态成员区域,包含整个程序的 class.static 成员等,类本身的字节码是静态的:它会被所有的线程共享和是全区级别的: 属于共享内存区域,存储 ...
- Linux C 中 fork() 函数详解
一.fork入门知识 一个进程,包括代码.数据和分配给进程的资源.fork() 函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同 ...
随机推荐
- Spring中的AOP应用
AOP被称为面向切面编程,AOP中的几个重要概念是: 1.切面.切面就是要实现的功能.切面通常是在多数方法中会用到的相同功能,如写日志. 2.连接点.连接点就是应用程序执行过程中插入切面的地点.如:方 ...
- [Java] 对象排序示例
package test.collections; import java.util.ArrayList; import java.util.Collection; import java.util. ...
- substring与substr
一.substring package Test; public class SubstringTest { public static void main(String[] args) { Stri ...
- Address already in use: JVM_Bind<null>:8080错误的解决办法
myEclipse在启动tomcat时,有时候会出现8080端口被占用的情况, 提示这个错误:Address already in use: JVM_Bind<null>:8080. 按照 ...
- SELinux配置不当导致vsftpd系统用户不能登陆
1.测试是否是SELinux配置不当导致的: setenforce 0 再次登陆ftp,正常,说明是SELinux配置不当导致.还原配置 setenforce 1 2.查看配置: getsebool ...
- POJ 1703
种类并查集,基本思想是每次压缩路径都必须同时更新子节点和根节点的关系,这种关系是通过子节点和父亲节点的关系,以及父亲节点与根节点的关系运算出来. 压缩路径的findme();参考了大神的代码,做的第二 ...
- 9.链式A+B
题目描述 有两个用链表表示的整数,每个结点包含一个数位.这些数位是反向存放的,也就是个位排在链表的首部.编写函数对这两个整数求和,并用链表形式返回结果. 给定两个链表ListNode* A,ListN ...
- [ZOJ 3662] Math Magic (动态规划+状态压缩)
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3662 之前写过这道题,结果被康神吐槽说代码写的挫. 的确,那时候 ...
- checkbox与文字的间距
1. checkbox在更换了图片后, 与文字的距离有问题, 建议修改background为@null, 去除占据的位置. 2. checkbox的paddingleft可以控制图片和文字的间距.
- java中的 json 处理包
Jackson 以前很火 Fastjson 阿里巴巴出品