SQL Server 非聚集索引的覆盖,连接,交叉和过滤 <第二篇>
在SQL Server中,非聚集索引其实可以看做是一个含有聚集索引的表,但相对实际的表来说,非聚集索引中所存储的表的列数要少得多,一般就是索引列,聚集键(或RID)。非聚集索引仅仅包含源表中的非聚集索引的列和指向实际物理表的指针。
一、非聚集索引之INCLUDE
非聚集索引其实可以看做一个含有聚集索引的列表,当这个非聚集索引中包含了查询所需要的所有信息的时候,则就不再需要去查基本表,仅仅做非聚集索引就能够得到所需要的数据。INCLUDE实际上也能称为覆盖索引,但它不影响索引键的大小。
先来看下面一张表:
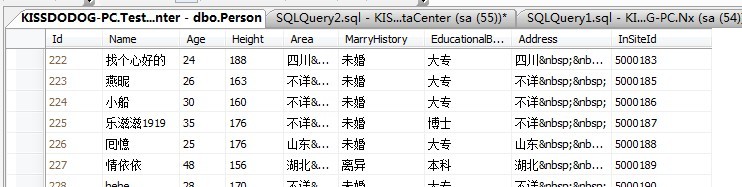
此表大约是15万数据左右。聚集索引列是Id,我们先来在Name列建立一个非聚集索引。
CREATE NONCLUSTERED
INDEX Index_Name ON Person(Name)
然后执行查询:
SELECT Name,Age FROM Person where Name = '欧琳琳'
执行计划如下:
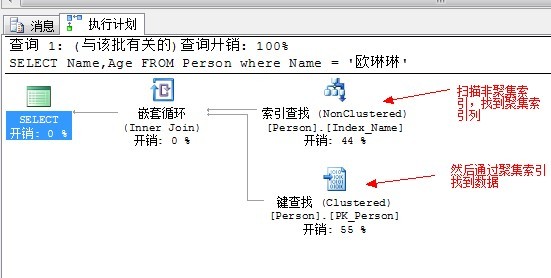
上面的执行过程是,先扫描非聚集索引列,找到聚集索引,然后在通过聚集索引定位到数据。
下面我们删除掉刚才那个索引,再建过另外一个。
DROP INDEX Person.Index_Name --删除非聚集索引Index_Name CREATE NONCLUSTERED --再重新建过一次,这次我们INCLUDE Age列
INDEX Index_Name ON Person(Name)
INCLUDE (Age)
现在我们再来看看刚才的查询的执行计划:
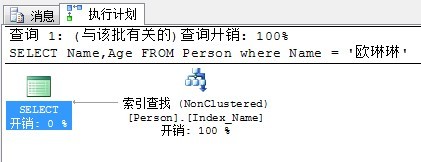
由于Age列也被INCLUDE进了非聚集索引INDEX_Name中,因此这次仅仅通过查找非聚集索引就能够得到所需的全部数据。不需要再扫描聚集索引了。明显这次查询要比刚才快。
要注意的是INCLUDE进来的列,并不作为索引使用,能当索引扫描的,只是索引列。
INCLUDE最好在以下情况中使用:
- 你不希望增加索引键的大小,但是仍然希望有一个覆盖索引;
- 你打算索引一种不能被索引的数据类型(除了文本、ntext和图像);
- 你已经超过了一个索引的关键字列的最大数量(但是最好避免这个问题);
二、非聚集索引之覆盖
索引覆盖指的是:建立的索引使得-SQL查询不用到达基本表仅仅通过索引查找就得到了所需数据。
如果查询遇到一个索引并且完全不需要引用数据表就得到了所需数据,那么这个索引就可以称为覆盖索引。覆盖索引对于减少查询的逻辑读是一种有用的技术。
下面删除之前创建的索引,在来看看索引的覆盖。
CREATE NONCLUSTERED INDEX INDEX_NAME ON Person(Name,Age) SELECT Name,Age FROM Person WHERE Name = '欧琳琳'
看看执行计划:

可以看到,也是仅仅查找了非聚集索引就得到了结果。效率非常快。
下面来看看覆盖和前面的INCLUDE有什么区别呢?我们将搜索条件改为Age。
覆盖索引:

INCLUDE:
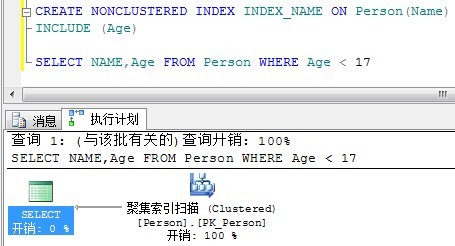
留意一下,INCLUDE是聚集表扫描了,而覆盖索引依然使用非聚集索引就找到了结果。
因此可以得出结论,INCLUDE列并不能当索引键使用。
为了利用覆盖索引,要注意SELECT语句的清单,应尽可能使用较少的列来保持小的覆盖索引的尺寸,使用INCLUDE语句来添加的列这时候才有意义。
在建立许多覆盖索引之前,考虑SQL Server如何有效和自动地使用索引交叉来为查询即时创建覆盖索引。
三、非聚集索引的交叉
如果一个表有多个索引,那么SQL Server可以使用多个索引来执行一个查询。SQL Server可以利用多个索引,根据每个索引选择小的数据子集,然后执行两个子集的一个交叉(即只返回满足所有条件的那些行)。SQL Server可以在一个表上开发多个索引,然后使用一个算法来在两个子集中得到交叉(可以理解为求交集)。
我们先删除掉前面建立的索引,再来新建过:
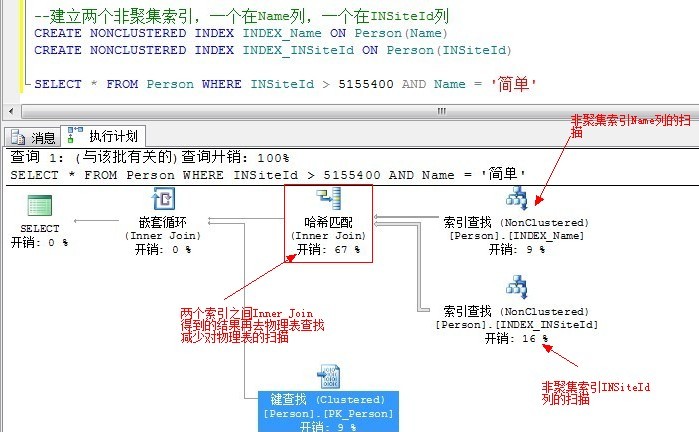
非聚集索引的本质是表,通过额外建立表使得几个非聚集索引之间进行像表一样的Join,从而使非聚集索引之间可以进行Join来在不访问基本表的情况下给查询优化器提供所需要的数据。
为了增进一个查询的性能,SQL Server可以在表上使用多个索引。因此,考虑创建多个窄索引来代替宽的索引键。SQL Server能够在需要的时候一起使用它们,当不需要时,查询可以从窄索引中获益。在创建一个覆盖索引时,需要确定索引的宽度是否可以接受,使用包含列是否可以完成任务。如果不行则确定现有的包含大部分覆盖索引所需要的列的非聚集索引。如果有可能,适当重新安排现有非聚集索引的列顺序,使优化器能够考虑两个非聚集索引之间的的一个索引交叉。
有时候,可能必须为一下原因创建一个单独的非聚集索引:
- 重新排列现有索引中的列不被允许;
- 覆盖索引所需要的一些列不能被包含在现有的非聚集索引中;
- 两个现有非聚集索引中的总列数可能多于覆盖索引所需要的列数;
在这些情况下,可以在剩下的列上创建非聚集索引。如果新索引符合和现有索引符合覆盖索引的要求,优化器将能够使用索引交叉。在为新确定列及其顺序时,也要注意其他查询,以尝试使其最大化。
四、非聚集索引的连接
索引连接是索引交叉的特例,它将覆盖索引技术应用到索引交叉。如果没有单个覆盖查询的索引而存在多个索引一起可以覆盖该查询,SQL Server可以使用索引连接来完全满足查询而不需要转到基本表。
非聚集索引的连接实际上是非聚集索引的交叉的一种特例。使得多个非聚集索引交叉后可以覆盖所要查询的数据,从而使得从减少查询基本表变成了完全不用查询基本表。
--建立两个非聚集索引,一个在Name列,一个在INSiteId列
CREATE NONCLUSTERED INDEX INDEX_Name ON Person(Name) INCLUDE(Age) --索引还是刚才的索引,但是包含多一列
CREATE NONCLUSTERED INDEX INDEX_INSiteId ON Person(INSiteId) INCLUDE(Height) --同上 SELECT Name,Age,Height,INSiteId FROM Person WHERE INSiteId > 5155400 AND Name = '简单' --注意条件,索引连接刚好能覆盖所需数据,从而避免查找基本表
查看结果:
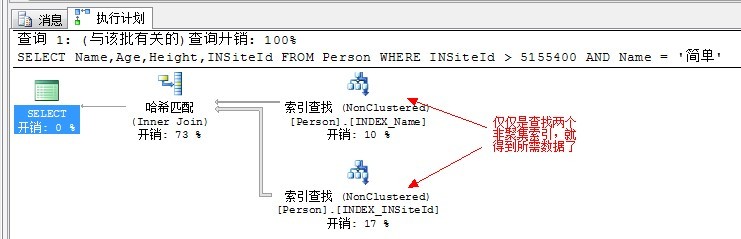
索引交叉和索引连接有什么区别呢?前面说到果,索引连接是索引交叉的特例。索引连接在交叉了之后,不用再转到基本表,少了一步书签查找。而索引交叉之后,还有一步书签查找转到基本表获得数据,因为索引交叉的返回列并不能完全符合SELECT的列。
五、非聚集索引的过滤
过滤索引是使用过滤器的非聚集索引,这个过滤器基本上是一个WHERE子句,用来在可能没有很好选择性的一个或多个列上创建一个高选择性的关键字组。
例如,一个具有大量NULL值的列可能被存储为稀疏列来降低这些null值的开销。在这个列添加一个过滤索引将使你拥有在不是null的数据上的索引。
在下面的所使用的Person表中,Name列有超过50%是NULL值,执行查询:
SELECT Name,Age FROM Person WHERE Name IS NOT NULL

这是一个聚集表扫描,并没有有效地使用索引。
当我们建立非聚集索引,且加上过滤后:INCLUDE()是为了形成覆盖索引。
CREATE NONCLUSTERED INDEX INDEX_Name ON Person(Name) INCLUDE(Age) WHERE Name IS NOT NULL --过滤的索引上过滤掉NULL值的行

在我的数据库当中,建立索引,加不加过滤没太大区别(因为很遗憾,Name列基本上没有NULL的),但是当过滤条件IS NOT NULL能够过滤很多条数据的时候,这时过滤的作用才能够展示出来。如果过滤条件,能够筛选掉很多条数据,那么性能无疑会大有提升。
过滤索引再许多方面带来回报:
- 减少索引尺寸从而增进查询效率;
- 建立更小的索引降低存储开销;
- 因为尺寸减小,降低了索引维护的成本;
SQL Server 非聚集索引的覆盖,连接,交叉和过滤 <第二篇>的更多相关文章
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- SQL SERVER中非聚集索引的覆盖,连接,交叉,过滤
1.覆盖索引:select和where中包含的结果集中应存在“非聚集索引列”,这样就不用查找基表了,索引表即可搞定: 2.索引交叉:索引的交叉可以理解成建立多个非聚集索引之间的join,如表实体一 ...
- InnoDB 聚集索引和非聚集索引、覆盖索引、回表、索引下推简述
关于InnoDB 存储引擎的有聚集索引和非聚集索引,覆盖索引,回表,索引下推等概念,这些知识点比较多,也比较零碎,但是概念都是基于索引建立的,本文从索引查找数据讲述上述概念. 聚集索引和非聚集索引 在 ...
- SQL Server性能优化(11)非聚集索引的覆盖索引存储结构
一,非聚集索引的include 非聚集索引的Include属性可以让非聚集索引包含其他列.如 CREATE NONCLUSTERED INDEX [NonIxUser] ON [dbo].[Users ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- 但从谈论性能点SQL Server选择聚集索引键
简单介绍 在SQL Server中,数据是按页进行存放的.而为表加上聚集索引后,SQL Server对于数据的查找就是依照聚集索引的列作为keyword进行了. 因此对于聚集索引的选择对性能的影响就变 ...
- 探究SQL添加非聚集索引,性能提高几十倍之谜
上周,技术支持反映:客户的一个查询操作需要耗时6.1min左右,在跟进代码后,简化了数据库的查询后仍然收效甚微.后来,技术总监分析了sql后,给其中的一个表添加的一个非聚集索引(三个字段)后,同样的查 ...
- mysql 聚集索引,非聚集索引,覆盖索引区别。
把原站信息经过筛选贴过来,用于自己备忘.原站:https://www.cnblogs.com/aspwebchh/p/6652855.html ---------------------------- ...
随机推荐
- spring mvc 自定义转换器
<!-- 注册转化器 --> <mvc:annotation-driven conversion-service="conversionService" /> ...
- 51nod1158 全是1的最大子矩阵
跟最大子矩阵差不多O(n3)扫一下.有更优写法?挖坑! #include<cstdio> #include<cstring> #include<cctype> #i ...
- I.MX6 Linux、Jni ioctl 差异
/*********************************************************************** * I.MX6 Linux.Jni ioctl 差异 ...
- Activiti 多个并发子流程的应用
多个部门发起资金计划,最后统一到财务部审批,每个部门发起资金计划是一个子流程,财务部审批是多个部门的计划同时审批,审批完成后,再提交上级领导审批. 流程如下: 要解决以上问题,需要实现多个子流程并行处 ...
- activiti 源码笔记之startProcess
rumtimeService.startProcessInstanceByXX方法将启动流程的任务委派给StartProcessInstanceCmd,此时会根据rumtimeService.star ...
- 【阅读】提问的智慧+有效的报告BUG
这两项可谓是我们测试人员的基本要求了,不过实话说的是,我自己这两方面很薄弱.哎!!! 这两篇文章都看过了,不过我在这也记个笔记吧.督促自己!!! <提问的智慧> <如何有效地报告Bu ...
- mysql 数据库自增id 的总结
有一个表StuInfo,里面只有两列 StuID,StuName其中StuID是int型,主键,自增列.现在我要插入数据,让他自动的向上增长,insert into StuInfo(StuID,Stu ...
- yeoman的学习
官网地址:http://yeoman.io/ 什么是yeoman? 在上一篇博客已粗劣地提到yeoman的安装和验证.说白了,其实yeoman是生成代码和搭建框架的前端自动化工具.为了做到这些,yeo ...
- 嵌入式 H264—MP4格式及在MP4文件中提取H264的SPS、PPS及码流
一.MP4格式基本概念 MP4格式对应标准MPEG-4标准(ISO/IEC14496) 二.MP4封装格式核心概念 1 MP4封装格式对应标准为 ISO/IEC 14496-12(信息技术 视听对象 ...
- 嵌入式 hi3518平台获取网关
</pre><pre code_snippet_id="495447" snippet_file_name="blog_20141024_1_70650 ...