MySQL优化—工欲善其事,必先利其器之EXPLAIN(转)
最近慢慢接触MySQL,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器。最近我就打算了解下几个优化MySQL中经常用到的工具。今天就简单介绍下EXPLAIN。
内容导航
环境准备
MySQL版本:
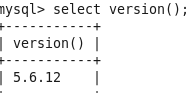
创建测试表
- CREATE TABLE people(
- id bigint auto_increment primary key,
- zipcode char(32) not null default '',
- address varchar(128) not null default '',
- lastname char(64) not null default '',
- firstname char(64) not null default '',
- birthdate char(10) not null default ''
- );
- CREATE TABLE people_car(
- people_id bigint,
- plate_number varchar(16) not null default '',
- engine_number varchar(16) not null default '',
- lasttime timestamp
- );
插入测试数据
- insert into people
- (zipcode,address,lastname,firstname,birthdate)
- values
- ('230031','anhui','zhan','jindong','1989-09-15'),
- ('100000','beijing','zhang','san','1987-03-11'),
- ('200000','shanghai','wang','wu','1988-08-25')
- insert into people_car
- (people_id,plate_number,engine_number,lasttime)
- values
- (1,'A121311','12121313','2013-11-23 :21:12:21'),
- (2,'B121311','1S121313','2011-11-23 :21:12:21'),
- (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
创建索引用来测试
- alter table people add key(zipcode,firstname,lastname);
EXPLAIN 介绍
先从一个最简单的查询开始:
- Query-1
- explain select zipcode,firstname,lastname from people;

EXPLAIN输出结果共有id,select_type,table,type,possible_keys,key,key_len,ref,rows和Extra几列。
id
- Query-2
- explain select zipcode from (select * from people a) b;

id是用来顺序标识整个查询中SELELCT 语句的,通过上面这个简单的嵌套查询可以看到id越大的语句越先执行。该值可能为NULL,如果这一行用来说明的是其他行的联合结果,比如UNION语句:
- Query-3
- explain select * from people where zipcode = 100000 union select * from people where zipcode = 200000;

select_type
SELECT语句的类型,可以有下面几种。
SIMPLE
最简单的SELECT查询,没有使用UNION或子查询。见Query-1。
PRIMARY
在嵌套的查询中是最外层的SELECT语句,在UNION查询中是最前面的SELECT语句。见Query-2和Query-3。
UNION
UNION中第二个以及后面的SELECT语句。 见Query-3。
DERIVED
派生表SELECT语句中FROM子句中的SELECT语句。见Query-2。
UNION RESULT
一个UNION查询的结果。见Query-3。
DEPENDENT UNION
顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。
- Query-4
- explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。
这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。
- SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
类似这样的语句会被重写成这样:
- SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
所以Query-4实际上被重写成这样:
- Query-5
- explain select * from people o where exists (select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。
SUBQUERY
子查询中第一个SELECT语句。
- Query-6
- explain select * from people where id = (select id from people where zipcode = 100000);

DEPENDENT SUBQUERY
和DEPENDENT UNION相对UNION一样。见Query-5。
除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。
table
显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。
- Query-7
- explain select * from (select * from (select * from people a) b ) c;

可以看到如果指定了别名就显示的别名。
<derivedN>N就是id值,指该id值对应的那一步操作的结果。
还有<unionM,N>这种类型,出现在UNION语句中,见Query-4。
注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。
type
type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。
const
当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是:
- Query-8
- explain select * from people where id=1;

- Query-9
- explain select * from people where zipcode = 100000;

注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。
- Query-10
- explain select * from people where id >2;

system
这是const连接类型的一种特例,表仅有一行满足条件。
- Query-11
- explain select * from (select * from people where id = 1 )b;

<derived2>已经是一个const table并且只有一条记录。
eq_ref
eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。
- Query-12
- explain select * from people a,people_car b where a.id = b.people_id;

我们创建两个MyISAM表people2和people_car2试试:
- CREATE TABLE people2(
- id bigint auto_increment primary key,
- zipcode char(32) not null default '',
- address varchar(128) not null default '',
- lastname char(64) not null default '',
- firstname char(64) not null default '',
- birthdate char(10) not null default ''
- )ENGINE = MyISAM;
- CREATE TABLE people_car2(
- people_id bigint,
- plate_number varchar(16) not null default '',
- engine_number varchar(16) not null default '',
- lasttime timestamp
- )ENGINE = MyISAM;
- Query-13
- explain select * from people2 a,people_car2 b where a.id = b.people_id;

我想这是InnoDB对性能权衡的一个结果。
eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了:
- Query-14
- explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

ref
这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。
为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。
- reate index people_id on people2(id);
- create index people_id on people_car2(people_id);
然后再执行下面的查询:
- Query-15
- explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

- Query-16
- explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

- Query-17
- explain select * from people2 a,people_car2 b where a.id = b.people_id;

- Query-18
- explain select * from people2 where id = 1;

看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。
对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。
fulltext
链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。
ref_or_null
该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。
- Query-19
- mysql> explain select * from people2 where id = 2 or id is null;

- Query-20
- explain select * from people2 where id = 2 or id is not null;

注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。
index_merger
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。
unique_subquery
该类型替换了下面形式的IN子查询的ref:
- value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery
该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:
- value IN (SELECT key_column FROM single_table WHERE some_expr)
range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range:
- Query-21
- explain select * from people where id = 1 or id = 2;

注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。
这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。
- explain select * from people where id >1;

- explain select * from people where id in (1,2);

但事实上这两种情况下MySQL如何使用索引是有很大差别的:
我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。
——出自《高性能MySQL第三版》
index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。
- Query-22
- explain select * from people order by id;

至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。
ALL
最慢的一种方式,即全表扫描。
总的来说:上面几种连接类型的性能是依次递减的(system>const),不同的MySQL版本、不同的存储引擎甚至不同的数据量表现都可能不一样。
possible_keys
possible_keys列指出MySQL能使用哪个索引在该表中找到行。
key
key列显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
key_len
key_len列显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好 。
ref
ref列显示使用哪个列或常数与key一起从表中选择行。
rows
rows列显示MySQL认为它执行查询时必须检查的行数。注意这是一个预估值。
Extra
Extra是EXPLAIN输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息,包含的信息很多,只选择几个重点的介绍下。
Using filesort
MySQL有两种方式可以生成有序的结果,通过排序操作或者使用索引,当Extra中出现了Using filesort 说明MySQL使用了后者,但注意虽然叫filesort但并不是说明就是用了文件来进行排序,只要可能排序都是在内存里完成的。大部分情况下利用索引排序更快,所以一般这时也要考虑优化查询了。
Using temporary
说明使用了临时表,一般看到它说明查询需要优化了,就算避免不了临时表的使用也要尽量避免硬盘临时表的使用。
Not exists
MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行, 就不再搜索了。
Using index
说明查询是覆盖了索引的,这是好事情。MySQL直接从索引中过滤不需要的记录并返回命中的结果。这是MySQL服务层完成的,但无需再回表查询记录。
Using index condition
这是MySQL 5.6出来的新特性,叫做“索引条件推送”。简单说一点就是MySQL原来在索引上是不能执行如like这样的操作的,但是现在可以了,这样减少了不必要的IO操作,但是只能用在二级索引上,详情点这里。
Using where
使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。
注意:Extra列出现Using where表示MySQL服务器将存储引擎返回服务层以后再应用WHERE条件过滤。
EXPLAIN的输出内容基本介绍完了,它还有一个扩展的命令叫做EXPLAIN EXTENDED,主要是结合SHOW WARNINGS命令可以看到一些更多的信息。一个比较有用的是可以看到MySQL优化器重构后的SQL。
Ok,EXPLAIN了解就到这里,其实这些内容网上都有,只是自己实际操练下会印象更深刻。下一节会介绍SHOW PROFILE、慢查询日志以及一些第三方工具。
原文地址:http://www.cnblogs.com/zhanjindong/p/3439042.html
MySQL优化—工欲善其事,必先利其器之EXPLAIN(转)的更多相关文章
- mysql优化(三)–explain分析sql语句执行效率
mysql优化(三)–explain分析sql语句执行效率 mushu 发布于 11个月前 (06-04) 分类:Mysql 阅读(651) 评论(0) Explain命令在解决数据库性能上是第一推荐 ...
- MySQL优化—工欲善其事,必先利其器之EXPLAIN
最近慢慢接触MySQL,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器.最近我就打算了解下几个优化MySQL中经常用到的工具.今天就简单介绍下EXPLAIN. 内容导航 id select_t ...
- MySQL优化—工欲善其事,必先利其器(2)
上一篇文章简单介绍了下EXPLAIN的用法,今天主要介绍以下几点内容: 慢查询日志 打开慢查询日志 保存慢查询日志到表中 慢查询日志分析 Percona Toolkit介绍 安装 pt-query-d ...
- 【MySQL】优化—工欲善其事,必先利其器之EXPLAIN
接触MySQL已经有一段时间了,了解如何优化它也迫在眉睫了,话说工欲善其事,必先利其器.最近我就打算了解下几个优化MySQL中经常用到的工具.今天就简单介绍下EXPLAIN. 环境准备 Explain ...
- Mysql优化要点
优化MySQL Mysql优化要点 慢查询 Explain mysql慢查询 注意事项 SELECT语句务必指明字段名称 SELECT *增加很多不必要的消耗(cpu.io.内存.网络带宽):增加了使 ...
- 一次浴火重生的MySQL优化(EXPLAIN命令详解)
一直对SQL优化的技能心存无限的向往,之前面试的时候有很多面试官都会来一句,你会优化吗?我说我不太会,这时可能很多人就会有点儿说法了,比如会说不要使用通配符*去检索表.给常常使用的列建立索引.还有创建 ...
- mysql优化:explain分析sql语句执行效率
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优 ...
- MYSQL优化浅谈,工具及优化点介绍,mysqldumpslow,pt-query-digest,explain等
MYSQL优化浅谈 msyql是开发常用的关系型数据库,快速.稳定.开源等优点就不说了. 个人认为,项目上线,标志着一个项目真正的开始.从运维,到反馈,到再分析,再版本迭代,再优化… 这是一个漫长且考 ...
- MySQL优化之Explain命令解读,optimizer_trace
简述: explain为mysql提供语句的执行计划信息.可以应用在select.delete.insert.update和place语句上.explain的执行计划,只是作为语句执行过程的一个参考, ...
随机推荐
- AFNetworking框架使用
本文是由 iOS Tutorial 小组成员 Scott Sherwood撰写,他是一个基于位置动态加载(Dynamically Loaded)的软件公司(专业的混合定位)的共同创办人. 网络 — 你 ...
- TCP协议基础
IP协议是Internet上使用的一个关键协议,它的全称是Internet Protocol,即Internet协议,通常简称IP协议.通过使用IP协议,使Internet·成为一个允许连接不同类型 ...
- [开发笔记]-DataGridView控件中自定义控件的使用
最近工作之余在做一个百度歌曲搜索播放的小程序,需要显示歌曲列表的功能.在winform中采用DataGirdView来实现. 很久不写winform程序了,有些控件的用法也有些显得生疏了,特记录一下. ...
- struts2的 result 通配符 OGNL
result: 1). result 是 action 节点的子节点 2). result 代表 action 方法执行后, 可能去的一个目的地 3). 一个 action 节点可以配置多个 resu ...
- asp.net mvc 2.o 中使用JQuery.uploadify
From:http://www.cnblogs.com/strugglesMen/archive/2011/07/01/2095916.html 官方网站http://www.uploadify.co ...
- ASP.Net Chart Control -----Bar and Column Charts
StackedBar StackedColumn StackedArea <asp:CHART id="Chart1" runat="server" H ...
- 支持.NET和移动设备的XLS读写控件XLSReadWriteII下载地址及介绍
原文来自龙博方案网http://www.fanganwang.com/product/3085转载请注明出处 读写任何单元值 数字型.字符型.布尔型以及错误型.但是你了解日期和时间型单元吗?在Exce ...
- C/C++中函数参数传递详解(二)
昨天看了内存管理的有关内容,有一点了解,但不是很深入,发现之前写代码时有很多细节问题没有注意到,只知道这样做可以实现功能,却不知道为什么可以这样,对于采用自己的方法造成的隐患也未知,更不晓得还有其他方 ...
- Javascript 的类型转换之减号
专职写JS已经有一个月了(对,没错就是一个月),从2014年11月24实习开始到今的2月份,我做的工作一直都是切图,另外跟着老板学产品,现在我一听到切图两字,我就想吐...所以我找了一份专职写JS的工 ...
- [Python陷阱]os.system调用shell脚本获取返回值
当前有shell个脚本/tmp/test.sh,内容如下: #!/bin/bashexit 11 使用Python的os.system调用,获取返回值是: >>> ret=os.sy ...