Hadoop 学习总结之一:HDFS简介
一、HDFS的基本概念
1.1、数据块(block)
- HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。
- 和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。
- 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
1.2、元数据节点(Namenode)和数据节点(datanode)
- 元数据节点用来管理文件系统的命名空间
- 其将所有的文件和文件夹的元数据保存在一个文件系统树中。
- 这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)
- 其还保存了一个文件包括哪些数据块,分布在哪些数据节点上。然而这些信息并不存储在硬盘上,而是在系统启动的时候从数据节点收集而成的。
- 数据节点是文件系统中真正存储数据的地方。
- 客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。
- 其周期性的向元数据节点回报其存储的数据块信息。
- 从元数据节点(secondary namenode)
- 从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。
- 其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。这点在下面会相信叙述。
- 合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
1.2.1、元数据节点文件夹结构
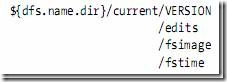
- VERSION文件是java properties文件,保存了HDFS的版本号。
- layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
- namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的。
- cTime此处为0
- storageType表示此文件夹中保存的是元数据节点的数据结构。
|
namespaceID=1232737062 cTime=0 storageType=NAME_NODE layoutVersion=-18 |
1.2.2、文件系统命名空间映像文件及修改日志
- 当文件系统客户端(client)进行写操作时,首先把它记录在修改日志中(edit log)
- 元数据节点在内存中保存了文件系统的元数据信息。在记录了修改日志后,元数据节点则修改内存中的数据结构。
- 每次的写操作成功之前,修改日志都会同步(sync)到文件系统。
- fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
- 同数据的机制相似,当元数据节点失败时,则最新checkpoint的元数据信息从fsimage加载到内存中,然后逐一重新执行修改日志中的操作。
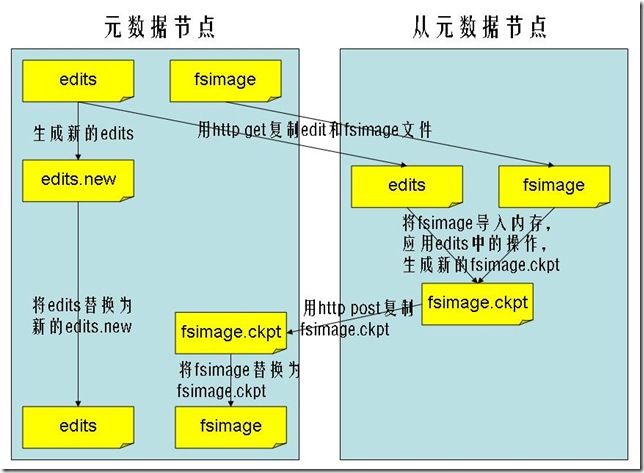
- 从元数据节点就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的
- checkpoint的过程如下:
- 从元数据节点通知元数据节点生成新的日志文件,以后的日志都写到新的日志文件中。
- 从元数据节点用http get从元数据节点获得fsimage文件及旧的日志文件。
- 从元数据节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
- 从元数据节点奖新的fsimage文件用http post传回元数据节点
- 元数据节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
- 这样元数据节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
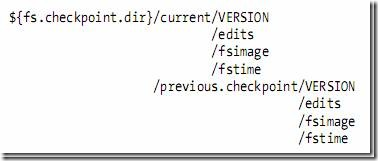
1.2.3、从元数据节点的目录结构
1.2.4、数据节点的目录结构
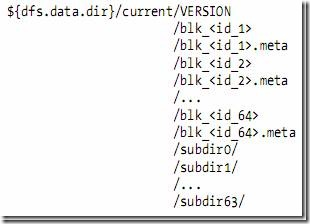
- 数据节点的VERSION文件格式如下:
|
namespaceID=1232737062 storageID=DS-1640411682-127.0.1.1-50010-1254997319480 cTime=0 storageType=DATA_NODE layoutVersion=-18 |
- blk_<id>保存的是HDFS的数据块,其中保存了具体的二进制数据。
- blk_<id>.meta保存的是数据块的属性信息:版本信息,类型信息,和checksum
- 当一个目录中的数据块到达一定数量的时候,则创建子文件夹来保存数据块及数据块属性信息。
二、数据流(data flow)
2.1、读文件的过程
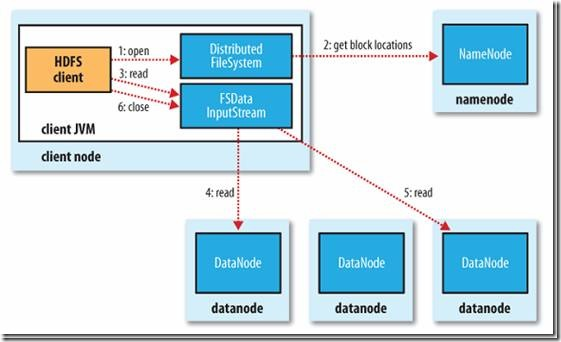
- 客户端(client)用FileSystem的open()函数打开文件
- DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
- 对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
- 客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
- Data从数据节点读到客户端(client)
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
2.2、写文件的过程
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
- 元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
- 如果数据节点在写入的过程中失败:
- 关闭pipeline,将ack queue中的数据块放入data queue的开始。
- 当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
- 失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
- 元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。

转:http://www.cnblogs.com/forfuture1978/archive/2010/03/14/1685351.html
Hadoop 学习总结之一:HDFS简介的更多相关文章
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- 【Hadoop】一、HDFS简介及基本概念
当需要存储的数据集的大小超过了一台独立的物理计算机的存储能力时,就需要对数据进行分区并存储到若干台计算机上去.管理网络中跨多台计算机存储的文件系统统称为分布式文件系统(distributed fi ...
- java大数据最全课程学习笔记(3)--HDFS 简介及操作
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 HDFS 简介及操作 HDFS概述 HDFS产出背景及定义 HDFS优缺点 HDFS组成架构 HDFS文件块大小 ...
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- hadoop学习笔记贰 --HDFS及YARN的启动
1.初始化HDFS :hadoop namenode -format 看到如下字样,说明初始化成功. 启动HDFS,start-dfs.sh 终于启动成功了,原来是core-site.xml 中配置 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
随机推荐
- java对象群体的组织:Enumeration及Iterator类
在一般情况下,遍历集合类会使用一下方式: for(int i=0;i<v.size();i++)< p=""> Customer c=(Custormer)v.g ...
- js判断一个对象是否包含属性的方式
判断一个对象是不是包含属性,我们这里提供三种方式 1,使用in 运算符 var obj = {name:'liwei'}; alert('name' in obj); // return true a ...
- java+内存分配及变量存储位置的区别[转]
原文来自:http://blog.csdn.net/rj042/article/details/6871030#comments Java内存分配与管理是Java的核心技术之一,之前我们曾介绍过Jav ...
- 如何开启Centos6.4系统的SSH服务
无论是Centos6.4系统的虚拟电脑还是服务器,始终感觉直接在命令行中操作不方便:比如全选.复制.粘贴.翻页等等.比如服务器就需要在机房给服务器接上显示器.键盘才操作感觉更麻烦.所以就可借助SSH( ...
- 李洪强iOS开发之OC面向对象—多态
OC面向对象—多态 一.基本概念 多态在代码中的体现,即为多种形态,必须要有继承,没有继承就没有多态. 在使用多态是,会进行动态检测,以调用真实的对象方法. 多态在代码中的体现即父类指针指向子类对象. ...
- Android核心分析 之十一Android GWES之消息系统
Android GWES之Android消息系统 ...
- iOS 库文件制作
一.静态库和动态库的介绍 一.什么是库? 库是共享程序代码的方式,一般分为静态库和动态库. 二.静态库与动态库的区别? 静态库:链接时完整地拷贝至可执行文件中,被多次使用就有多份冗余拷贝. 动态库:链 ...
- CentOS服务器的基本配置和查看
一.设置静态IP 1.修改网卡配置 编辑:vi /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 #描述网卡对应的设备别名,例如ifcfg-e ...
- MS WORD 表格自动调整列宽,自动变漂亮,根据内容自动调整 .
在MS WORD中,当有大量的表格出现时,调整每个表格的的高和宽和大小将是一件非常累的事情,拖来拖去,非常耗时间,而且当WORD文档达到300页以上时,调整反应非常的慢,每次拖拉线后,需要等待一段时间 ...
- (七)后台.apsx.cs获取前台客户端文本框的内容
<input ID='AllLocalData' name='AllLocalDataName' /> 其中最重要的一点是Request.Form[]中括号是放的name属性而非Id属性. ...