java的HashMap与ConcurrentHashMap
好像今天没有什么源码读,那么就来看看java的这两种HashMap有啥不一样的地方吧,在这之前先普及一下HashMap的一些基本知识:
(1)放入HashMap的元素是key-value对。
(2)底层说白了就是以前数据结构课程讲过的散列结构。
(3)要将元素放入到hashmap中,那么key的类型必须要实现实现hashcode方法,默认这个方法是根据对象的地址来计算的,具体我也记不太清楚了,接着还必须覆盖对象的equal方法。
用一张图来表示一下散列结构吧:
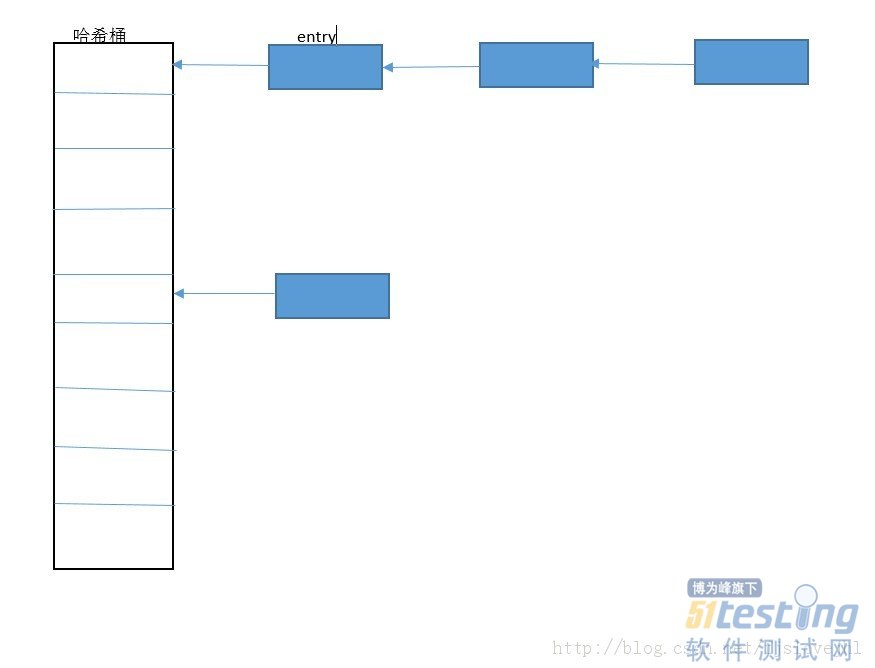
在这里hashCode函数就是用于确定当前key应该放在hash桶里面的位置,这里hash桶可以看成是一个数组,最简单的通过一些取余的方法就能用来确认key应该摆放的位置,而equal函数则是为了与后面的元素之间判断重复。
好了,这里我们接下来来看看java的这两种类库的用法吧:
由于他们都实现了Map接口,将元素放进去的方法就是put(a,b),这里我们先来分析比较简单的HashMap吧:
|
public V put(K key, V value) { modCount++; |
这个函数其实本身还是很简单的,首先通过hash函数获取当前key的hash值,不过这里需要注意的是,对hashCode方法返回的值HashMap本身还会进行一些处理,具体什么样子的就不细说了,然后再调用indexFor方法用于确定当前key应该属于当前Hash桶的位置,接着就是遍历当前桶后面的链表了,这里equal方法就派上用场了,这里看到如果equal是相等的话,那么就直接用新的value来替换原来的value就好了。。。
当然最多的情况还是,桶后面的链表没有与当前的key相同的,那么这个时候就需要调用addEntry方法,将要加入的key-value放入到当前的结构中了,那么接下来来看看这个方法的定义吧:
|
void addEntry(int hash, K key, V value, int bucketIndex) { createEntry(hash, key, value, bucketIndex); //创建新的entry,并将它加入到当前的桶后面的链表中 |
其实这个方法很简单,首先来判断当前的桶的大小,如果觉得太小的话,那么需要扩充当前桶的大小,这样可以让添加元素存放的更离散化一些,优化擦入和寻找的效率。
然后就是创建一个新的entry,用于保存要擦入的key和value,然后再将其链到应该放的桶的链表上就好了。。
好了,到这里位置,整个HashMap的擦入元素的过程就已经看的很清楚了,在整个这个过程中没有看到有加锁的过程,因此可以说明HashMap是不支持并发的,不是线程安全的,在并发的环境下使用会产生一些不一致的问题。。。
因此java新的concurrent类库中就有了ConcurrentHashMap用于在并发环境中使用。。
那么我们再来看看ConcurrentHashMap的put操作是怎么搞的吧:
| public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key); //获取hash值 int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment //用于获取相应的片段 s = ensureSegment(j); //这里表示没有这个片段,那么需要创建这个片段 return s.put(key, hash, value, false); //这里就有分段加锁的策略 } |
这里刚开始跟HashMap都差不太多吧,无非是先获取当前key的hash值,但是接下来进行的工作就不太一样了,这里就有了一个分段的概念:
ConcurrentHashMap将整个Hash桶进行了分段,也就是将这个大的数组分成了几个小的片段,而且每个小的片段上面都有锁存在,那么在擦入元素的时候就需要先找到应该插入到哪一个片段,然后再在这个片段上面进行擦入,而且这里还需要获取锁。。。。
那我们来看看这个segment的put方法吧:
| final V put(K key, int hash, V value, boolean onlyIfAbsent) { //这里的锁是计数锁,同一个锁可以被同一个线程获取多次,但是不能被不同的线程获取 HashEntry<K,V> node = tryLock() ? null : //如果获取了当前的segment的锁,那么node为null,待会自己分配就好了 scanAndLockForPut(key, hash, value); //如果没有加上锁,那么等吧,有可能的话还要分配entry,反正有时间干嘛不多做一些事情 V oldValue; try { //这里表示已经获取了锁,那么将在相应的位置放入entry HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); //找到存放entry的桶,然后获取第一个entry for (HashEntry<K,V> e = first;;) { //从当前的第一个元素开始 if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { //如果key相等,那么直接替换元素 oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) //如果元素太多了,那么需要重新调整当前的hash结构,让桶变多一些,这样元素放的更离散一些 rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); //这里必须要在finally里面释放已经获取的锁,这样才能保证锁一定会被释放 } return oldValue; } |
其实在这里ConcurrentHashMap和HashMap的区别就已经很明显了:
(1)ConcurrentHashMap对整个桶数组进行了分段,而HashMap则没有
(2)ConcurrentHashMap在每一个分段上都用锁进行保护,从而让锁的粒度更精细一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。。。
最后用一张图来表来说明一下ConcurrentHashMap吧:
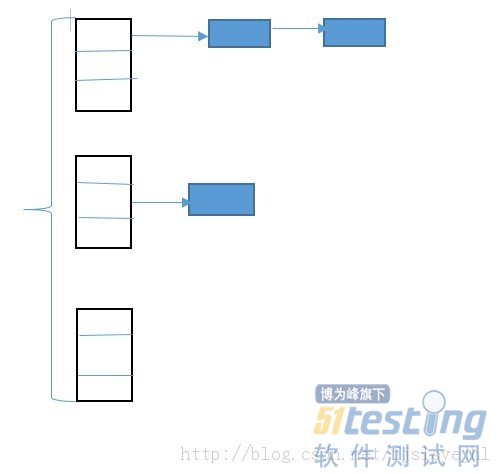
最后,在并发的情况下,要么使用concurrent类库中提供的容器,要么就需要自己来管理数据的同步问题了。。。
摘自:http://www.blogjava.net/qileilove/archive/2013/09/23/404308.html
java的HashMap与ConcurrentHashMap的更多相关文章
- Java集合——HashMap,HashTable,ConcurrentHashMap区别
Map:“键值”对映射的抽象接口.该映射不包括重复的键,一个键对应一个值. SortedMap:有序的键值对接口,继承Map接口. NavigableMap:继承SortedMap,具有了针对给定搜索 ...
- Java中HashMap与ConcurrentHashMap的区别
从JDK1.2起,就有了HashMap,正如前一篇文章所说,HashMap不是线程安全的,因此多线程操作时需要格外小心. 在JDK1.5中,伟大的Doug Lea给我们带来了concurrent包,从 ...
- [Java集合] 彻底搞懂HashMap,HashTable,ConcurrentHashMap之关联.
注: 今天看到的一篇讲hashMap,hashTable,concurrentHashMap很透彻的一篇文章, 感谢原作者的分享. 原文地址: http://blog.csdn.net/zhanger ...
- 轻松理解 Java HashMap 和 ConcurrentHashMap
前言 Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据. 本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 ...
- Java中关于Map的使用(HashMap、ConcurrentHashMap)
在日常开发中Map可能是Java集合框架中最常用的一个类了,当我们常规使用HashMap时可能会经常看到以下这种代码: Map<Integer, String> hashMap = new ...
- Java集合——HashMap、HashTable以及ConCurrentHashMap异同比较
0. 前言 HashMap和HashTable的区别一种比较简单的回答是: (1)HashMap是非线程安全的,HashTable是线程安全的. (2)HashMap的键和值都允许有null存在,而H ...
- 沉淀再出发:java中的HashMap、ConcurrentHashMap和Hashtable的认识
沉淀再出发:java中的HashMap.ConcurrentHashMap和Hashtable的认识 一.前言 很多知识在学习或者使用了之后总是会忘记的,但是如果把这些只是背后的原理理解了,并且记忆下 ...
- JAVA HashMap与ConcurrentHashMap
HashMap Fast-Fail(遍历时写入操作异常) 在使用迭代器的过程中如果HashMap被修改,那么ConcurrentModificationException将被抛出,也即Fast-fai ...
- Java并发指南13:Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析
Java7/8 中的 HashMap 和 ConcurrentHashMap 全解析 转自https://www.javadoop.com/post/hashmap#toc7 部分内容转自 http: ...
随机推荐
- 【leetcode❤python】 Maximum Depth of Binary Tree
#-*- coding: UTF-8 -*- # Definition for a binary tree node.# class TreeNode(object):# def __init ...
- 【转】JSP总结
day1 JSP 定义: 1)Java Server Page, Java EE 组件,本质上是 Servlet. 2)运行在 Web Container.接收 Http Reques ...
- 关于header('location:url')的一些说明,php缓冲区
网上搜索header('location:url')的用法,得到如下三个结论: 1. location和“:”号间不能有空格,否则会出错. 2. 在用header前不能有任何的输出. 3. heade ...
- 03_Spring工厂接口
Spring工厂接口 1.BeanFactory 接口 和 ApplicationContext 接口区别 ? * ApplicationContext 接口继承BeanFactory接口, ...
- JS学习笔记(四) 正则表达式(RegExp对象)
参考资料: 1. http://www.w3school.com.cn/js/js_obj_regexp.asp ☂ 知识点: ☞ RegExp是正则表达式的缩写. ☞ RegExp是一种模式,用于在 ...
- iOS - OC NSArray 数组
前言 @interface NSArray<__covariant ObjectType> : NSObject <NSCopying, NSMutableCopying, NSSe ...
- [转载] Tmux 速成教程:技巧和调整
原文: http://blog.jobbole.com/87584/ 决定从 screen 转向 tmux 了, 非常喜欢 tmux 的窗格功能. 简介 有些开发者经常要使用终端控制台工作,导致最终打 ...
- poj2194Stacking Cylinders
链接 可以根据反余弦和反正切算出角a和b的值, 然后向量旋转就可以了,图中的状态旋转rotate((2,0),a+b) 反状态把角度反过来,点取(-2,0)即可. 不知道是不是理解错了,题意写着两圆 ...
- hostapd源代码分析(一):网络接口和BSS的初始化
[转]hostapd源代码分析(一):网络接口和BSS的初始化 原文链接:http://blog.csdn.net/qq_21949217/article/details/46004349 最近在做一 ...
- Android保存图像到相册
在应用的图集中,通常会给用户提供保存图片的功能,让用户可以将自己喜欢的图片保存到系统相册中. 这个功能其实很好做,系统提供了现成的API: 简单的来说就这一行代码: [java] MediaStor ...