Kafka文件的存储机制
Kafka文件的存储机制
同一个topic下有多个不同的partition,每个partition为一个目录,partition命名的规则是topic的名称加上一个序号,序号从0开始。

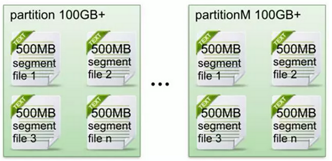
每一个partition目录下的文件被平均切割成大小相等(默认一个文件是500兆,可以手动去设置)的数据文件,
每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。
默认保留7天的数据。
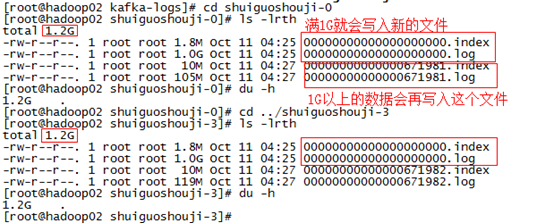
每个partition下都会有这些每500兆一个每500兆一个(当然在上面的测试中我们将它设置为了1G一个)的segment段。
另外每个partition只需要支持顺序读写就可以了,partition中的每一个segment端的生命周期是由我们在配置文件中指定的一个参数觉得的。
比如它在默认情况下,每满500兆就会创建新的segment段(segment file),每满7天就会清理之前的数据。
它的一个特点就是支持顺序写。如下图所示:
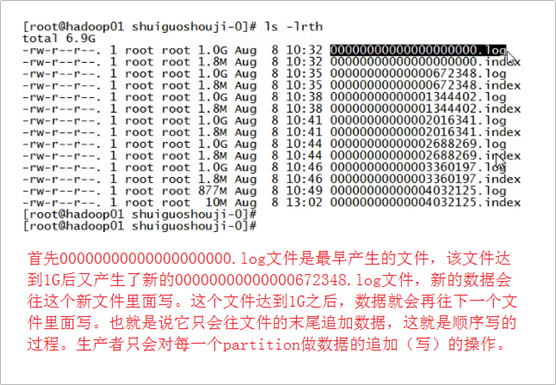
首先00000000000000000000.log文件是最早产生的文件,该文件达到1G(因为我们在配置文件里面指定的1G大小,默认情况下是500兆)
之后又产生了新的0000000000000672348.log文件,新的数据会往这个新的文件里面写,这个文件达到1G之后,数据就会再往下一个文件里面写,
也就是说它只会往文件的末尾追加数据,这就是顺序写的过程,生产者只会对每一个partition做数据的追加(写)的操作。
问题:如何保证消息消费的有序性呢?比如说生产者生产了0到100个商品,那么消费者在消费的时候安装0到100这个从小到大的顺序消费,
那么kafka如何保证这种有序性呢?难度就在于,生产者生产出0到100这100条数据之后,通过一定的分组策略存储到broker的partition中的时候,
比如0到10这10条消息被存到了这个partition中,10到20这10条消息被存到了那个partition中,这样的话,消息在分组存到partition中的时候就已经被分组策略搞得无序了。
那么能否做到消费者在消费消息的时候全局有序呢?遇到这个问题,我们可以回答,在大多数情况下是做不到全局有序的。但在某些情况下是可以做到的。 比如我的partition只有一个,这种情况下是可以全局有序的。那么可能有人又要问了,只有一个partition的话,哪里来的分布式呢?哪里来的负载均衡呢?
所以说,全局有序是一个伪命题!全局有序根本没有办法在kafka要实现的大数据的场景来做到。但是我们只能保证当前这个partition内部消息消费的有序性。 结论:一个partition中的数据是有序的吗?回答:间隔有序,不连续。 针对一个topic里面的数据,只能做到partition内部有序,不能做到全局有序。特别是加入消费者的场景后,如何保证消费者的消费的消息的全局有序性,
这是一个伪命题,只有在一种情况下才能保证消费的消息的全局有序性,那就是只有一个partition!。
Segment file是什么? 生产者生产的消息按照一定的分组策略被发送到broker中partition中的时候,这些消息如果在内存中放不下了,就会放在文件中,
partition在磁盘上就是一个目录,该目录名是topic的名称加上一个序号,在这个partition目录下,有两类文件,一类是以log为后缀的文件,
一类是以index为后缀的文件,每一个log文件和一个index文件相对应,这一对文件就是一个segment file,也就是一个段。
其中的log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,索引文件记录了元数据信息。
说到segment file的索引文件和数据文件的一一对应,我们应该能想到storm中的Ack File机制,在spout发出去的时候要发一个Ack Tuple,
在下游的bolt处理完之后,它也要发一个Ack Tuple,这两个Ack Tuple里面包含了同样一份数据,这个数据叫做MessageId,它是一个对象,
这个对象里面包含两个比较重要的字段,一个是RootId,另一个是TupleId(也叫锚点Id),这个锚点Id会在我们发送数据的时候进行异或一下,
异或的结果才会发送给Ack那个Bolt。

Segment文件命名的规则:partition全局的第一个segment从0(20个0)开始,后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。 那么这样命令有什么好处呢?假如我们有一个消费者已经消费到了368776(offset值为368776),那么现在我们要继续消费的话,怎么做呢?
看上图,分2个步骤,第1步是从所有文件log文件的的文件名中找到对应的log文件,第368776条数据位于上图中的“00000000000000368769.log”这个文件中,
这一步涉及到一个常用的算法叫做“二分查找法”(假如我现在给你一个offset值让你去找,你首先是将所有的log的文件名进行排序,然后通过二分查找法进行查找,
很快就能定位到某一个文件,紧接着拿着这个offset值到其索引文件中找这条数据究竟存在哪里);第2步是到index文件中去找第368776条数据所在的位置。 索引文件(index文件)中存储这大量的元数据,而数据文件(log文件)中存储这大量的消息。 索引文件(index文件)中的元数据指向对应的数据文件(log文件)中消息的物理偏移地址。
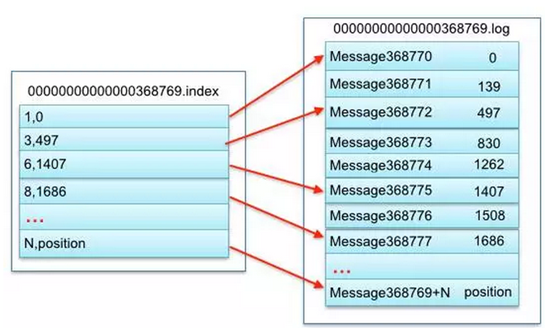
上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,
分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。 其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息),
其中497表示该消息的物理偏移地址(位置)为497。
Kafka文件的存储机制的更多相关文章
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
随机推荐
- Binary Tree 分类: POJ 2015-06-12 20:34 17人阅读 评论(0) 收藏
Binary Tree Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 6355 Accepted: 2922 Descr ...
- Socket状态变迁图
在一些防火墙或端口管理工具中经常会看到连接状态为CLOSED CLOSE_WITE LAST_ACK等的进程, 虽然状态就那么很少的几个, 而且看字面意思也能猜个大概, 但没做过Socket编程的朋友 ...
- 准确率(Precision)、召回率(Recall)以及F值(F-Measure)
转载自:http://blog.csdn.net/yechaodechuntian/article/details/37394967 https://www.zhihu.com/question/19 ...
- Python_cmd的各种实现方法及优劣(subprocess.Popen, os.system和commands.getstatusoutput)
http://blog.csdn.net/menglei8625/article/details/7494094
- SQL锁行 解决多台服务器发送统一请求并发问题
锁行信息SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED 存储过程:SET Transaction Isolation Level Read语法的四种情 ...
- bzoj 2818: Gcd GCD(a,b) = 素数
2818: Gcd Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 1566 Solved: 691[Submit][Status] Descript ...
- 【Web】简谈如何监听浏览器的关闭
> 参考的优秀文章 beforeunload实现关闭离开的提示 想起以前做的一个小系统,一个企业内部小型的测试系统,让考生在给定时间内完成考试,如果考生中退出,那么下次进来可以利用剩余的考试时间 ...
- Python3基础 双星号 求一个数的几次幂
镇场诗:---大梦谁觉,水月中建博客.百千磨难,才知世事无常.---今持佛语,技术无量愿学.愿尽所学,铸一良心博客.------------------------------------------ ...
- C#实现随机抽奖和冒泡排序
随机抽奖程序 string[] s = new string[] { "A", "B", "C", "D", " ...
- C#获取百度新歌TOP50
先上软件效果图 代码如下1.根据Url地址得到网页的html源码 public static string GetWebContent(string Url) { string strResult = ...