wMy_Python ~储存相关~
str,int,list,tuple,dict 是类型调用之后会产生一个 实例
>>> brand=["李宁",'耐克','阿迪达斯','鱼C']
>>> slogan=['一切皆有可能','Just do it','Impossible is nothing','让编程改变世界']
>>> print("鱼C的口号是:",slogan[brand.index('鱼C')])
鱼C的口号是: 让编程改变世界
>>> dict1={"李宁":"一切皆有可能",'耐克':"Just do it",'阿迪达斯':'Impossible is nothing'}
>>> print(dict1['李宁'])
一切皆有可能
>>> print(dict1["李宁"])
一切皆有可能
>>> # dict只能传入一个参数 .
>>> dict1=dict((('F',),['i',]))
>>> dict1
{'F': , 'i': }
>>> # dict只能传入一个参数 .
>>> dict1=dict((('F',),['i',]))
>>> dict1
{'F': , 'i': }
>>> dict1['F']=
>>> dict1
{'F': , 'i': }
>>> dict1["QQ"]="钱"
>>> dict1
{'F': , 'i': , 'QQ': '钱'}
在列表中如果你是用没有的函数 会出错 , 但是在字典中 , 如果没有的话会自动创建一个 . 如上.
>>> dict1.fromkeys((,,))
{: None, : None, : None}
>>> dict1.fromkeys((,,),'num')
{: 'num', : 'num', : 'num'}
如果直接使用fromkeys 会出错的.
>>> dict1=dict1.fromkeys(range(,),'赞')
Traceback (most recent call last):
File "<pyshell#0>", line , in <module>
dict1=dict1.fromkeys(range(,),'赞')
NameError: name 'dict1' is not defined
>>> dict1={}
>>> dict1=dict1.fromkeys(range(,),'赞')
>>> dict1
{: '赞', : '赞', : '赞', : '赞', : '赞', : '赞', : '赞', : '赞'}
>>> for i in dict1.items():
i (, '赞')
(, '赞')
(, '赞')
(, '赞')
(, '赞')
(, '赞')
(, '赞')
(, '赞')
>>> for i in dict1.values():
i '赞'
'赞'
'赞'
'赞'
'赞'
'赞'
'赞'
'赞'
>>> a={1:'one',2:'two'}
>>> b=a.copy()
>>> c=a
>>> id(a)
48682848
>>> id(b)
48854120
>>> id(c)
48682848
>>> # 由此可见 浅拷贝是 将内容放到另一块的储存区域中
在dict中批量添加元素.
>>> a={1:'one',2:'two'}
>>> b={3:'three',4:'four'}
>>> a=a+b
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
a=a+b
TypeError: unsupported operand type(s) for +: 'dict' and 'dict'
>>> a.update(b)
>>> a
{1: 'one', 2: 'two', 3: 'three', 4: 'four'}
>>> b.update(a)
>>> b
{1: 'one', 2: 'two', 3: 'three', 4: 'four'}
可见字典可有集合的特性 ~'唯一'
文件的读写.
--------- ---------------------------------------------------------------
'r' open for reading (default) 以只读方式打开(默认)
'w' open for writing, truncating the file first 已写入的方式打开文件 , 会覆盖已存在文件
'x' create a new file and open it for writing 创建一个新的文件,并且打开写入 . (文件已存在会引发异常)
'a' open for writing, appending to the end of the file if it exists 以读写模式打开 , 如果文件存在则将内容添加到文件末尾.
'b' binary mode 二进制模式打开
't' text mode (default) 文本模式打开
'+' open a disk file for updating (reading and writing) 打开一个(磁盘?)文件用于读写
'U' universal newline mode (deprecated)
========= ===============================================================
文件对象方法

写一个简单的小程序 . 给你一个txt文件内容如下
小客服:小甲鱼,今天有客户问你有没有女朋友?
小甲鱼:咦??
小客服:我跟她说你有女朋友了!
小甲鱼:。。。。。。
小客服:她让你分手后考虑下她!然后我说:"您要买个优盘,我就帮您留意下~"
小甲鱼:然后呢?
小客服:她买了两个,说发一个货就好~
小甲鱼:呃。。。。。。你真牛!
小客服:那是,谁让我是鱼C最可爱小客服嘛~
小甲鱼:下次有人想调戏你我不阻止~
小客服:滚!!!
================================================================================
小客服:小甲鱼,有个好评很好笑哈。
小甲鱼:哦?
小客服:"有了小甲鱼,以后妈妈再也不用担心我的学习了~"
小甲鱼:哈哈哈,我看到丫,我还发微博了呢~
小客服:嗯嗯,我看了你的微博丫~
小甲鱼:哟西~
小客服:那个有条回复“左手拿著小甲魚,右手拿著打火機,哪裡不會點哪裡,so easy ^_^”
小甲鱼:T_T
================================================================================
小客服:小甲鱼,今天一个会员想找你
小甲鱼:哦?什么事?
小客服:他说你一个学生月薪已经超过12k了!!
小甲鱼:哪里的?
小客服:上海的
小甲鱼:那正常,哪家公司?
小客服:他没说呀。
小甲鱼:哦
小客服:老大,为什么我工资那么低啊??是时候涨涨工资了!!
小甲鱼:啊,你说什么?我在外边呢,这里好吵吖。。。。。。
小客服:滚!!!
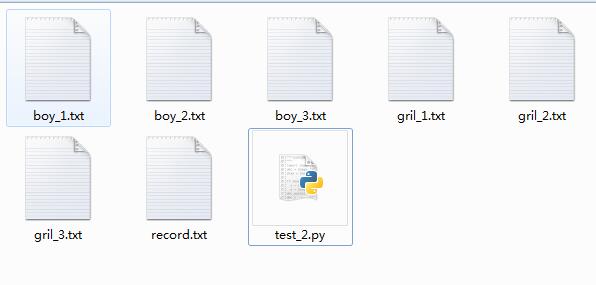
将该文件 分割为三部分 , 已经以"====~==="分割. 让你将每一段的每个人说的话自成一个文档 . 代码如下
def save_file(boy,gril,count):
file_name_boy='boy_'+str(count)+'.txt'
file_name_gril='gril_'+str(count)+'.txt'
boy_file=open(file_name_boy,'w')
gril_file=open(file_name_gril,'w')
boy_file.writelines(boy)
gril_file.writelines(gril)
boy_file.close()
gril_file.close()
def split_file(file_name):
boy=[]
gril=[]
count=
f=open(file_name) # 如果直接写文件名的话 那就默认 , 该文件和程序是在一个地方 .
for each_line in f: # for 读写文件 是一段一段的
if each_line[:]!="======": #如果 不是等号的话 .
(role,line_spoken)=each_line.split(":",) # 那么就开始收集 分割话语.
if role=='小甲鱼': # 上面函数调用的意思是 , ":"以其为分隔符 , 该字符传"一"分为二
boy.append(line_spoken)
if role=='小客服':
gril.append(line_spoken)
else:
save_file(boy,gril,count)
boy=[]
gril=[]
count+=
save_file(boy,gril,count)
f.close()
split_file("record.txt")
wMy_Python ~储存相关~的更多相关文章
- magento性能优化的教程(非常详细)
Magento是一套专业开源的电子商务系统,Magento设计得非常灵活,具有模块化架构体系和丰富的功能但有朋友会发现此模块用到了会发现非常的缓慢了,那么下面我们来看关于magento性能优化的例子. ...
- vbs的一些入门基础。。。
VBS(VBScript的进一步简写)是基于Visual Basic的脚本语言. Microsoft Visual Basic是微软公司出品的一套可视化编程工具, 语法基于Basic. 脚本语言, 就 ...
- qt之图像处理
毕业2年了,一直使用的qt做桌面程序,很少接触图像算法类的东西,最近由于项目的原因,不得不了解下图像处理,不过也是一些简单的图像处理,仅此作为记录,并希望能帮助初学qt图像处理的朋友. 首先我推荐一篇 ...
- Java—集合框架详解
一.描述Java集合框架 集合,在Java语言中,将一系类的对象看成一个整体. 首先查看jdk中的Collection类的源码后会发现Collection是一个接口类,其继承了java迭代接口Iter ...
- [转]magento性能优化的教程(非常详细)
本文转自:https://www.sypopo.com/post/kMQE8dERoV/ 前面优化 mod_deflate模块,将text. css 和 javascript 先进行压缩再发送到浏览器 ...
- vsphere 5.1 改进和SSO理解
虚拟交换器 以5.1版的vSphere而言,VMware在VDS上提供一些新功能.例如,现在可以用快照的方式,来备份还原VDS组态及网络端口群组(port group)的组态,以因应vCenter S ...
- [SHOI2012]回家的路 最短路
---题面--- 题解: 吐槽:找了好久的错,换了n种方法,重构一次代码,,,, 最后发现,,, 数组开小了,其实一开始尝试开大了数组,但唯独没有尝试开大手写队列的数组.... 思路: 有两种方法,这 ...
- 我的自动化测试历程(Selenium+TestNG+Java+ReportNG+Jenkins)
原地址:http://blog.csdn.net/shilinjie_8952/article/details/53380373?locationNum=11&fps=1 测试环境:Java+ ...
- 简单VBS教程.RP
Mimick同菜鸟==.文转豆瓣~:https://www.douban.com/note/88562379/ 讲一下VBScript.主要面向菜鸟,懂得编程的朋友就不要浪费时间了,如果你想接触以下V ...
随机推荐
- 在VBA中调用工作表函数
虽然VBA几乎可以完成所有工作表函数的功能,但是有时候在无法打开思路的时候,适当调用一些工作表函数也未尝不可,在VBA中调用工作表函数需要用到 WorksheetFunction对象,例如: Work ...
- XML中的非法字符转化成实体
问题 如果XML有非法字符比如 "·",或者HTML标签<br/>.XML在解析的过程中就会出错.就无法正常解析,或者把xml反射成实体. 有些字符,像(<)这类 ...
- eclipse 中提示tomcat 的端口被占用了 后的最快捷解决方法
很多时候运行tomcat 的时候总是会提示tomcat 的端口被占用 但是任务管理器里面还找不到是哪个端口被占用了 因此很多人就重新配置tomcat 或者去修改tomcat的端口号 ,其实这么做太麻 ...
- Wilcoxon test
clear load NPSVOR name={'SCV1V1','SVC1VA','SVR','CSSVC','SVMOP','NNOP','ELMOP','POM',... 'NNPOM', 'S ...
- 继承多态绕点 C#篇
最近在看博客的时候看到一块很绕的地方,有点类似于以前学习C语言是的i++,++i组合到一起使用的情况,很坑b的,绝对会比i++,++i这种情况更有用,虽然实际代码里面确实很少出现. 面对象像三大特点不 ...
- struts2视频学习笔记 07-08(为Action的属性注入值,指定需要Struts 2处理的请求后缀,常用常量)
课时7 为Action的属性注入值(增加灵活性,适用于经常更改的参数) Struts2为Action中的属性提供了依赖注入功能,在struts2的配置文件中,我们可以很方便地为Action中的属性注入 ...
- LSM树——放弃读能力换取写能力,将多次修改放在内存中形成有序树再统一写入磁盘
LSM树(Log-Structured Merge Tree)存储引擎 代表数据库:nessDB.leveldb.hbase等 核心思想的核心就是放弃部分读能力,换取写入的最大化能力.LSM Tree ...
- Caffe 深度学习框架介绍
转自:http://suanfazu.com/t/caffe/281 Caffe是一个清晰而高效的深度学习框架,其作者是博士毕业于UC Berkeley的贾扬清,目前在Google工作. Caffe是 ...
- netty4 Handler的执行顺序
转载:https://my.oschina.net/jamaly/blog/272385 Handler在netty中,无疑占据着非常重要的地位.Handler与Servlet中的filter很像,通 ...
- Eclipse如何设置代码提示功能
Windows→Preference→XML→XML Files→Editor→Content Assist→Auto Activation→Prompt when these characters ...