MariaDB集群配置(主从和多主)
1.mariadb主从
主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是主从架构的数据库,读写分离必须基于主从架构来搭建。
主可以将数据同步到从上,但是从不能将数据同步到主上。
二进制日志这能一条一条的写入,因此数据的同步会有延迟。
异步优点:性能好,效率高
缺点:数据的安全性低
同步优点:数据的安全性高
缺点:效率低
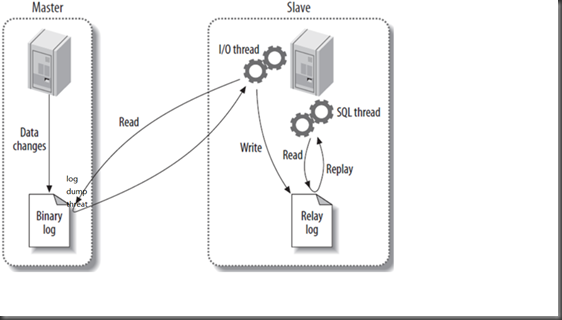
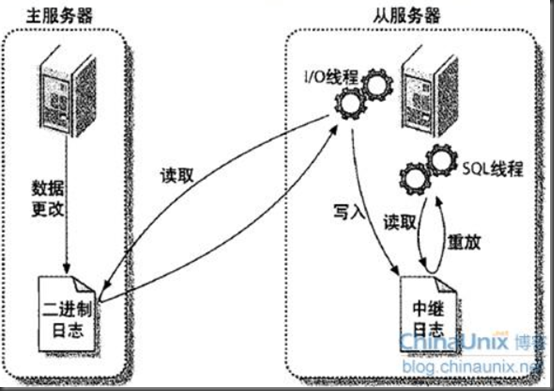
mariadb的复制过程:
1.master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
2.slave会生成I/O线程和SQL线程,I/O线程会读取master的二进制日志,master会生成一个dump线程将数据返回给slave端,存储到slave的中继日志(relay log)中。
3.slave端的SQL thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
面试会问到的
如果slave有多个,那么master端会生成许多的dump线程,这对于master端会造成很大的压力,为了解决这种问题我们可以这样解决:
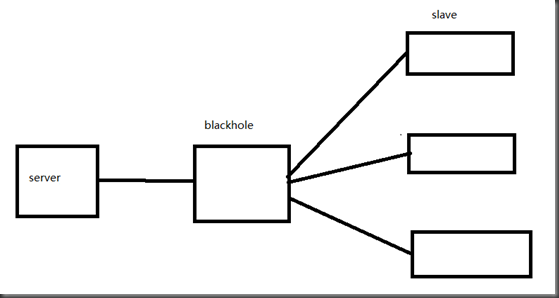
将中间的引擎设置为blackhole,让他只做接受转发线程的作用,不记录存储任何数据,只负责同步二进制文件的作用。这样就减轻了server端的压力。
在一个主从集群中,如果主故障,则会就会影响整个集群,解决这个单点故障的方法,有以下两个:
1.MHA
MHA(Master High Availability)一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。另外对于想快速搭建的可以参考:MHA快速搭建
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。
工作原理下图所示:
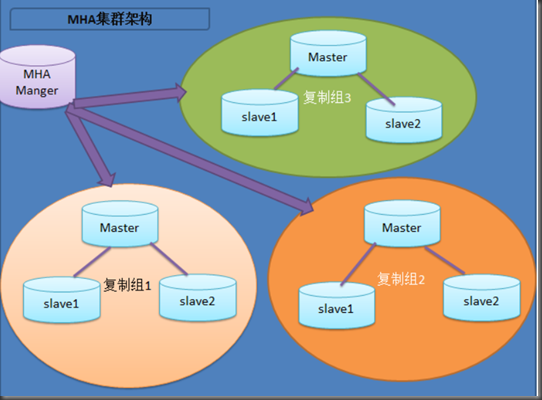
一个集群有一个MHA配置文件
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
2.主主集群,数据库互为主从
将数据库互相设置为主从。但是这样的设置,在两台数据库接受数据时,由于异步的机制,同步数据会出现错误,造成数据的不一致。
主主集群主要用于增删改少,读多的时候。
2.mysql主从集群配置
在做主从集群之前,需要保证主从数据库的一致性,即数据库里的内容一致
yum配置
[mariadb]
name=MariaDB
baseurl=http://mirrors.ustc.edu.cn/mariadb/yum/10.3/centos7-amd64/
gpgkey=http://mirrors.ustc.edu.cn/mariadb/yum/RPM-GPG-KEY-MariaDB
gpgcheck=1
服务器1: MariaDB01 192.168.88.5
服务器2: MariaDB02 192.168.88.10
操作系统: CentOS7.3
数据库版本:MariaDB-10.3.7
主从关系: MariaDB01为主,MariaDB02为从
MariaDB01端
1. 修改配置文件
[root@localhost ~]# vim /etc/my.cnf.d/server.cnf
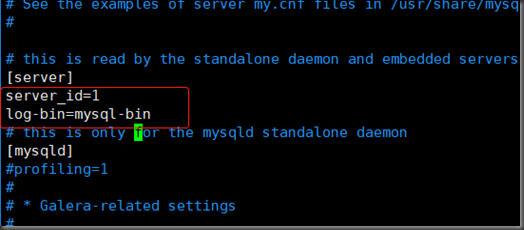
2. 重启mariadb服务
[root@localhost ~]# systemctl restart mariadb
3.创建主从连接帐号与授权
登陆数据库
grant replication slave on *.* to slave@'%' identified by 'slave';
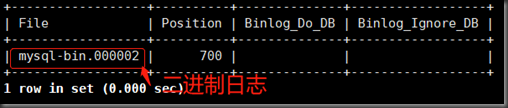
4查看设置好的主连接和授权
show master status;
MariaDB02端
1. 修改配置文件
[root@localhost ~]# vim /etc/my.cnf.d/server.cnf
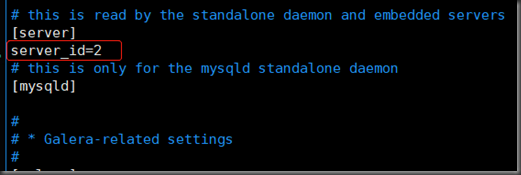
2. 重启mariadb服务
[root@localhost ~]# systemctl restart mariadb
3.登录数据库
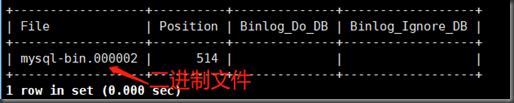
change master to master_host='192.168.88.5',master_user='slave',master_password='slave',master_log_file='mysql-bin.000002',master_log_pos=700;
master_log_file和主的二进制文件相同
master_log_pos和主的position相同
4.查看
show slave status\G; #G以竖排显示字列
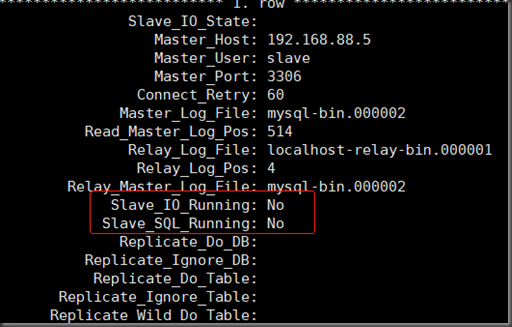
此时IO和SQL线程未开启
5.开启:start slave;
show slave status\G;
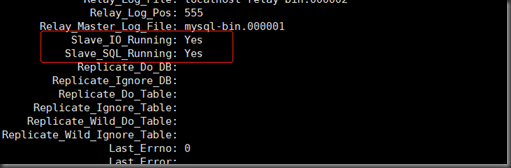
配置成功
6.验证
create database test01
use test01
create table students(id int(10), name char(20), age int(10))
之后查看从节点是否有test01数据库和students表
如果出现不同步可以执行以下步骤
stop slave
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
start slave
或者
stop slave;
mysql> change master to
master_host='192.168.254.28',
master_user='user',
master_password='pwd',
master_port=3306,
master_log_file='mysql-bin.000008',
master_log_pos=483;
start slave
3. mariadb galera集群(多主)
galera集群多用于关键性业务,因为galera集群为了数据的一致性,采用的是同步的机制,这就使galera牺牲了一部分性能来换取数据一致性。数据没有延迟,最少3个数据库。
galera集群各个主数据库之间通过wsrep协议实现高可用,wsrep的端口号为4567
wsrep通过galera来实现
脑裂
4.配置mariadb galera集群
实战Mariadb10.3(10以后自带galera软件,10一千必须再额外安装galera) galera Cluster集群架构
Mariadb galera Cluster安装:
操作系统:Centos7.3版本
集群数量:3个节点
主机信息:
192.168.88.5 node1 selinux=disabled firewalld关闭
192.168.88.10 node2 selinux=disabled firewalld关闭
192.168.88.12 node3 selinux=disabled firewalld关闭
1.三台主数据库都安装MariaDB10.3
2.mariadb初始化 (三个节点都需要执行)
3.配置galera
vi /etc/hosts
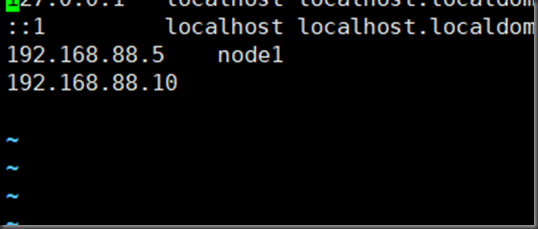
主节点配置文件server.cnf
vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_on=ON
wsrep_provider=/usr/lib64/galera/libgalera_smm.so #galera的库文件的地址
wsrep_cluster_address="gcomm://192.168.88.5,192.168.88.10,192.168.88.12" #各节点的ip
wsrep_node_name=node1 #节点主机名,各个数据库之间不能同名
wsrep_node_address=192.168.153.142 #节点ip
binlog_format=row #二进制日志设置为行模式,行模式数据比较安全,但是耗费资源
default_storage_engine=InnoDB #使用的默认引擎
innodb_autoinc_lock_mode=2 #性能最好
wsrep_slave_threads=1 #并行复制线程数
innodb_flush_log_at_trx_commit=0 #0.log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下在事务提交的时候,不会主动触发写入磁盘的操作。
#1:每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去,该模式为系统默认。
#2:每次事务提交时MySQL都会把log buffer的数据写入log file,但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作
innodb_buffer_pool_size=120M #设置缓存池大小,按照情况设定
wsrep_sst_method=rsync #远程同步,保证数据一致性
wsrep_causal_reads=ON #避免各个节点的数据不一致,这种情况需要等待全同步复制,保证数据一致性
将此文件复制到mariadb-2、mariadb-3,注意要把 wsrep_node_name 和 wsrep_node_address 改成相应节点的 hostname 和 ip。
4.启动集群服务:
启动 MariaDB Galera Cluster 服务:
(第一次启动要用初始化:mysqld_safe --wsrep_cluster_address=gcomm://192.168.88.5,192.168.88.10,192.168.88.12 >/dev/null &)
[root@node1 ~]#systemctl stop mariadb
[root@node1 ~]# vim /var/lib/mysql/grastate.dat
[root@node1 ~]# /bin/galera_new_cluster #重启
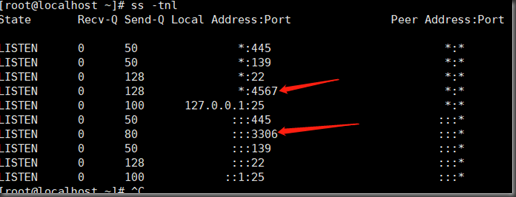
[root@node1 ~]# cat /var/lib/mysql/grastate.dat
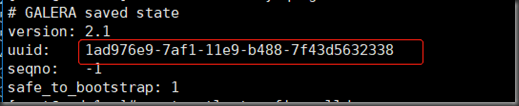
三台数据库的uuid必须相同
剩余两节点启动方式为:
systemctl restart mariadb
5.验证集群状态
在node1上执行:
[root@node1 ~]# mysql -uroot -p12346 #进入数据库
查看是否启用galera插件
连接mariadb,查看是否启用galera插件
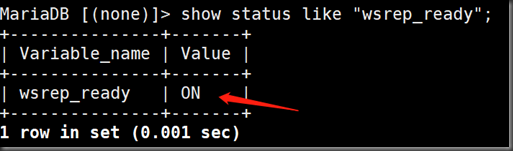
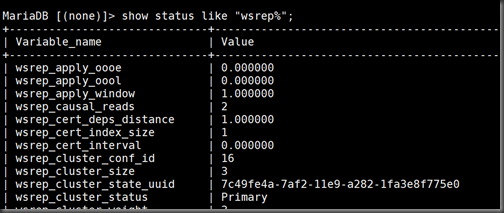
MariaDB [(none)]> show status like "wsrep_ready";
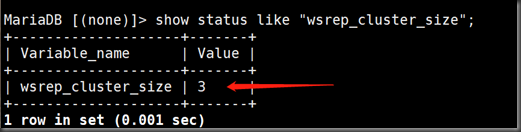
value里的数字时表明集群里的数据库个数
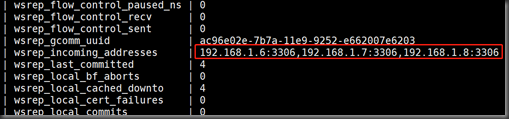
在该集群的数据库ip
6.测试集群mariad数据是否同步
注意:
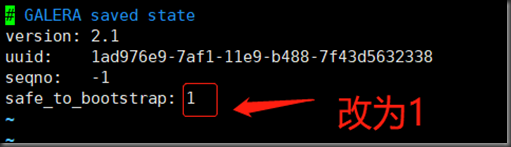
如果galera_new_cluster 报错
vim /var/lib/mysql/grastate.dat
把safe_to_bootstrap更改为1
# GALERA saved state
version: 2.1
uuid: a393feef-f639-11e8-9b89-4e75f9b8fb0f
seqno: -1
safe_to_bootstrap: 1
MariaDB集群配置(主从和多主)的更多相关文章
- mariadb集群配置(主从和多主)
mariadb主从 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是主从架构的数据库,读写分离必须基于主从架构 ...
- redis sentinel 集群配置-主从切换
1.配置redis master,redis slave(配置具体操作见上文http://www.cnblogs.com/wangchaozhi/p/5140469.html). redis mast ...
- mongodb集群配置主从模式
测试环境 操作系统:CentOS 7.2 最小化安装 主服务器IP地址:192.168.197.21 master-node 从服务器IP地址:192.168.197.22 slave-node 关闭 ...
- mariadb 数据库集群配置
mariadb集群配置(主从和多主) mariadb主从 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是 ...
- mariadb集群与nginx负载均衡配置--centos7版本
这里配置得是单nginx主机..先准备4台主机,三台mariadb集群,一台nginx. ------------------------------------------------------- ...
- Docker:docker搭建redis一主多从集群(配置哨兵模式)
角色 实例IP 实例端口 宿主机IP 宿主机端口 master 172.19.0.2 6382 192.168.1.200 6382 slave01 172.19.0.3 6383 192.168.1 ...
- redis学习五 集群配置
redis集群配置 0,整体概述 整体来说就是: 1,安装redis 2,配置多个redis实例 3,安装 ruby和rubygems 4,启动red ...
- mongoDB Replica集群配置(1主+1从+1仲裁)
1.mongoDB节点介绍 主节点(Primary) 在复制集中,主节点是唯一能够接收写请求的节点.MongoDB在主节点进行写操作,并将这些操作记录到主节点的oplog中.而从节点将会从oplog复 ...
- redis主从同步故障切换及集群配置
一.redis是一中高性能的缓存数据库, 原理:1. 从服务器向主服务器发送 SYNC 命令.2. 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下 ...
随机推荐
- collection,random,os,sys,序列化模块
一.collection 模块 python拥有一些内置的数据类型,比如 str,list.tuple.dict.set等 collection模块在这些内置的数据类型的基础上,提供了额外的数据类型: ...
- idea创建springmvc项目创部署成功,但访问controller层报错404
这个问题网上有很多解决问题,检查配置文件是否正确?controller注解是否扫描?项目启动是否成功等等. 访问报错404,而且后台也没错误,归根结底还是访问路径错了. 1.如图,idea配置tomc ...
- java调出cmd窗口长ping某个ip
package lct.conference.test; import java.io.IOException; public class Test { public static void main ...
- YARN构建--解决cypress下载慢问题
背景 注意: 此方案仅适合已经自行搭建私有仓库的用户使用 如非必要,尽可能使用软件开发云或其他服务提供的镜像站,避免此类特殊处理(会导致仓库维护成本增加) 场景描述 YARN构 ...
- yii2.0场景的简单使用
一.规则中使用场景规则场景的使用模型层public function rules(){ return [ [['name','product_id'],'required','on'=>'add ...
- manjaro xfce4 使用super+D快捷键显示桌面(以及使用super+方向键调整窗口)设置无效
xfce4 有两个地方设置快捷键:Keyboard -> application shortcuts 和 window manager -> keyboard. window manage ...
- Python -三目运算(三元运算)
if 1==1: name = "jacky" else: name = "zhuyuanlu" name = 值1 if 条件 else 值2 #如果这个条件 ...
- 深入理解JVM虚拟机6:深入理解JVM类加载机制
深入理解JVM类加载机制 简述:虚拟机把描述类的数据从class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制. 下面我们具体 ...
- QQ 为什么以 UDP 协议为主,以 TCP 协议为辅?
QQ既有UDP也有TCP!不管UDP还是TCP,最终登陆成功之后,QQ都会有一个TCP连接来保持在线状态.这个TCP连接的远程端口一般是80,采用UDP方式登陆的时候,端口是8000. UDP协议是无 ...
- Interacted Action-Driven Visual Tracking Algorithm
文章来源:Attentional Action-Driven Deep Network for Visual Object Tracking 博士论文(2017年8月份完稿) http://s-s ...