kettle mogodb output详解
以下主要来自官网文档,原文:https://wiki.pentaho.com/display/EAI/MongoDB+Output
Configure Connection Tab

1 Host name or IP address 输入本机或者服务器的ip地址
2 Port 端口号默认端口号27017
3 Username 和 Password 如果目标集合需要验证详细信息,可以使用用户名和密码字段提供验证细节
4 如果已经设置了有效的主机名和端口,那么可以使用Get DBs按钮和Get collection按钮分别检索选定数据库中现有数据库和集合的名称如下图:

5 如果多个主机,可以用逗号分隔,并且勾上Use all replicate set members/mongos

Create and Drop Indexes Tab

kettle 可以写入数据时候,在mongodb中创建索引
Output Options Tab
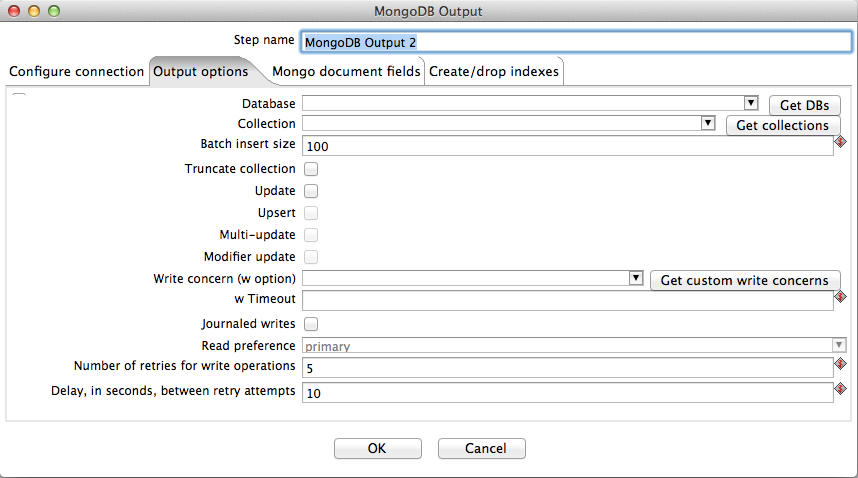
1 使用Get DBs按钮和Get collection按钮分别检索选定数据库中现有数据库和集合,如果输入一个集合名字,这个集合名字在数据库中不存在,那么会自动创建一个集合,并且将对应数据插入该集合中。
2 Truncate collection 如果勾上之后,在插入目标集合之前会把集合数据清空,然后再插入
3 除非使用唯一索引,否则mongodb允许插入重复数据
4 Mongo DB允许快速批量插入操作—可以使用批插入大小字段配置批大小。如果这里没有提供值,则使用默认的100行大小
5 选择Update,但不选择Upsert的时候,只更新,不插入。如果数据库中没数据,也不插入。有数据则更新。
选择Update的时候,Mongo Document Fields 里面的 Match field for update 必须有一个选择Y才可以,然后Modifier policy 选择Insert&Update时候,如果有数据就更新。
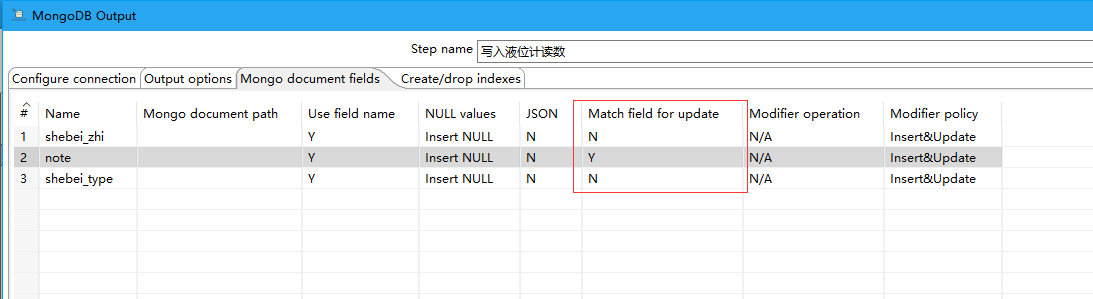
同时选择Update,Upsert时候,在数据库中找到则更新,找不到则插入。
(在mongodb使用update功能的时候upsert本身就是一个可选择的功能,true是库里没有则插入,false是库里没有不做操作。默认false。因此kettle在选择update功能时候下面还有一个upsert)
最终生效则必须在Mongo document fields 选项卡中选择Match field for update,必须有一个是Y,如下图:
Match field for update选择为Y,则是用这个自动去匹配。比如途中选择note为Y,note作为更新参照字段。
相当于sql语句:update 表 set shebei_zhi = value1,shebei_type = value2 where note = value3
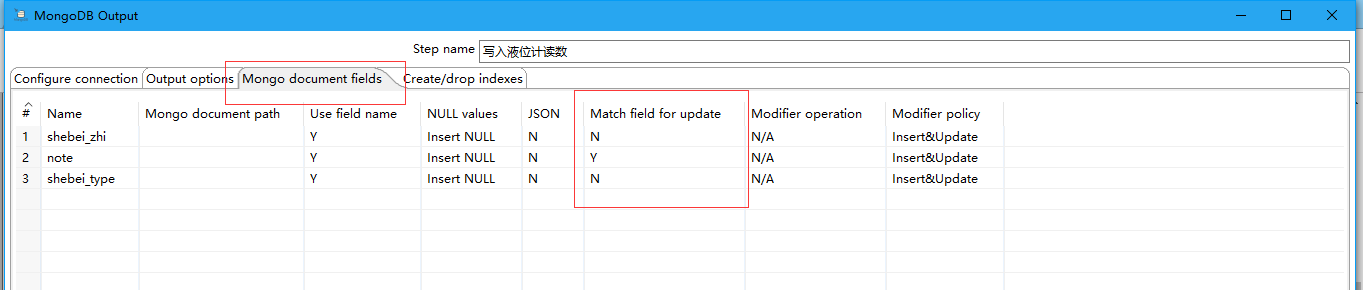
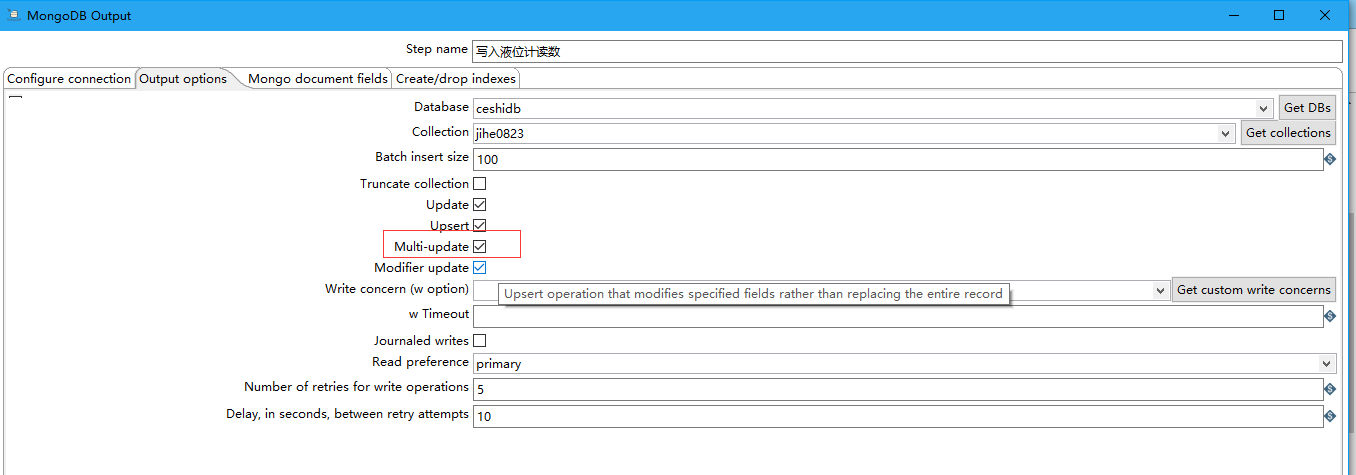
6 勾选Modifier update,可以对update操作进一步设置如可以增加操作符设置:$set,$inc和$push。勾选之后, Mongo document fields 选项卡中Modifier operation 和Modifier policy才起作用。
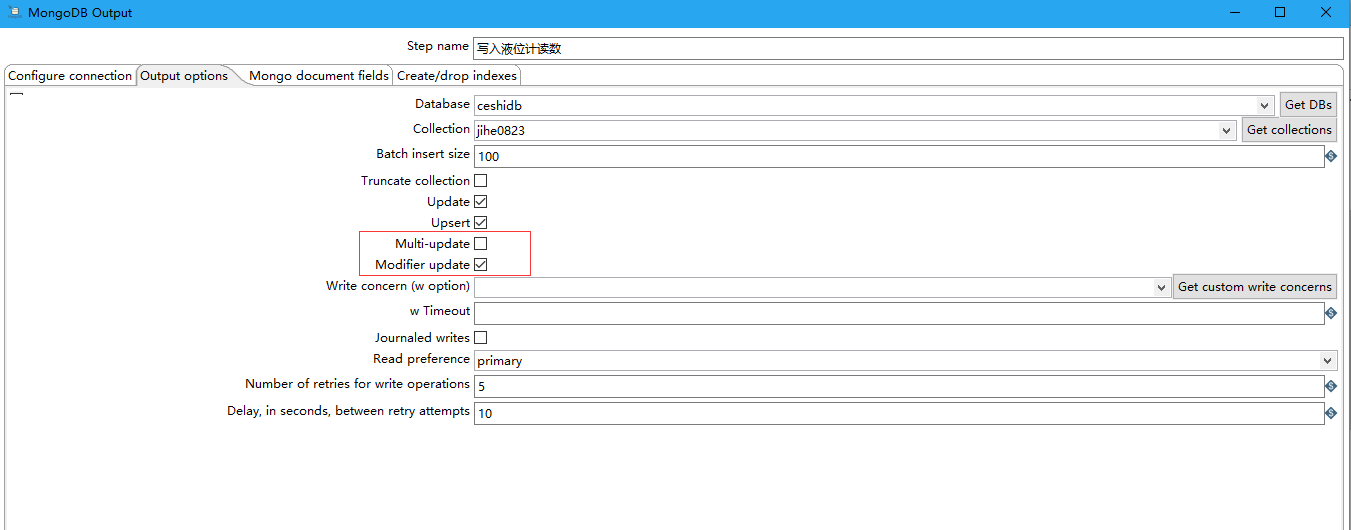

7 勾选Modifier update之后,可以再勾选Multi-update。mongodb默认只更新找到的第一条记录,如果勾选,就把按条件查出来多条记录全部更新,即更新找到的多条记录。
参考:https://blog.csdn.net/qq_26645205/article/details/78341196
kettle mogodb output详解的更多相关文章
- Webpack探索【4】--- entry和output详解
本文主要讲entry和output相关内容.
- PHP输出缓冲控制- Output Control 函数应用详解
说到输出缓冲,首先要说的是一个叫做缓冲器(buffer)的东西.举个简单的例子说明他的作用:我们在编辑一篇文档时,在我们没有保存之前,系统是不会向磁盘写入的,而是写到buffer中,当buffer写满 ...
- PHP输出缓冲控制 - Output Control 函 应用详解
简介 说到输出缓冲,首先要说的是一个叫做缓冲器(buffer)的东西.举个简单的例子说明他的作用:我们在编辑一篇文档时,在我们没有保存之前,系统是不会向磁盘写入的,而是写到buffer中,当buffe ...
- kettle的下载、安装和初步使用(Ubuntu 16.04平台下)(图文详解)
不多说,直接上干货! 能够看我这篇博客的博友们,想必是已经具备一定基础了. 扩展博客 kettle的下载.安装和初步使用(windows平台下)(图文详解) kettle的下载 Kettle可以在h ...
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
前期博客 Filebeat的下载(图文讲解) 前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticse ...
- Logstash组件详解(input、codec、filter、output)
logstash组件详解 logstash的概念及特点. 概念:logstash是一个数据采集.加工处理以及传输(输出)的工具. 特点: - 所有类型的数据集中处理 - 不同模式和格式数据的正常化 - ...
- 58、Spark Streaming: DStream的output操作以及foreachRDD详解
一.output操作 1.output操作 DStream中的所有计算,都是由output操作触发的,比如print().如果没有任何output操作,那么,压根儿就不会执行定义的计算逻辑. 此外,即 ...
- html5中output元素详解
html5中output元素详解 一.总结 一句话总结: output元素是HTML5新增的元素,用来设置不同数据的输出,没什么大用,了解即可 <form action="L3_01. ...
- kettle的下载、安装和初步使用(windows平台下)(图文详解)
kettle的下载 Kettle可以在http://kettle.pentaho.org/网站下载 http://sourceforge.net/projects ...
随机推荐
- bat 获取当前文件夹的文件名
bat 获取当前文件夹的文件名 @echo off pushd %1 & for %%i in (.) do set curr=%%~ni echo %curr% pause
- Mariadb多实例启动脚本
#!/bin/bash port=3306 mysql_user="root" mysql_pwd="centos" cmd_path="/app/m ...
- MySQL基准测试和sysbench工具
参考https://www.cnblogs.com/kismetv/archive/2017/09/30/7615738.html 一.基准测试的作用 sysbench是一个开源的.模块化的.跨平台的 ...
- awk的妙用
终端形式 有人说awk的优势在于可以个性化输出命令,这么说来太抽象了,假如我们查看占用6379端口的进程信息. lsof -i: 输出结果: COMMAND PID USER FD TYPE DEVI ...
- django-cookies设置与使用
原文地址:http://www.cnblogs.com/wupeiqi/articles/5246483.html 感谢说话声音像评书表演艺术家刘兰芳老师的武沛齐老师的倾力奉献! 1.获取Cookie ...
- [Cypress] Find Unstubbed Cypress Requests with Force 404
Requests that aren't stubbed will hit our real backend. To ensure we've stubbed all our routes, we c ...
- 51 Nod 1191消灭兔子
1191 消灭兔子 1 秒 131,072 KB 40 分 4 级题 有N只兔子,每只有一个血量B[i],需要用箭杀死免子.有M种不同类型的箭可以选择,每种箭对兔子的伤害值分别为D[i],价格为P[i ...
- noi 2011
描述 已知长度最大为200位的正整数n,请求出2011^n的后四位. 输入 第一行为一个正整数k,代表有k组数据,k<=200接下来的k行, 每行都有一个正整数n,n的位数<=200 输出 ...
- 漫谈计算机编码:从ASCII码到UTF-8
第一阶段 盘古开天辟地——ASCII码 计算机大家都知道,本质是二进制运算和存储.在计算机中人类的几乎所有文字和字符都没法直接表示,所以美国人在发明计算机的时候为了让计算机可以用于保存和传输文字,就发 ...
- ubuntu16.0.4 设置静态ip地址
由于Ubuntu重启之后,ip很容易改变,可以用以下方式固定ip地址 1.设置ip地址 vi /etc/network/interface # The loopback network interfa ...