spark2.0新特性之DataSet
1.Spark SQL,DataFrame,DataSet的错误类型检测时机
spark SQL:其类型检测与语法检测是在运行时检测的
DataFrame:在spark2.0以前的版本中,DataFrame是类型不安全的,其类型检查是在运行时才检查的,语法检查倒是在编译时检查的
DataSet:类型检测和语法检测是在编译时检测
2. DataSet的性能比RDD的性能更好,实现代码更简洁,且内存利用率更高
通过统计单词的计数来举例:
RDDs的实现(words的获取各自已经实现好了的)
val counts = words
.groupBy(_.toLowerCase)
.map(w => (w._1, w._2.size))
Datasets
val counts = words
.groupBy(_.toLowerCase)
.count()
DataSet可以使用其内部的一些聚合函数,而RDD则需要自己去实现相应的逻辑,DataSet实现的运行速度远远超过原生的RDD实现。相比之下,使用RDD获得相同的性能将需要用户手动考虑如何以最佳并行化的方式来表达计算。
这个新的Dataset API的另一个好处是减少了内存使用。由于Spark知道Datasets中数据的结构,因此在缓存Datasets时可以在内存中创建更优化的结构。在下面的例子中,我们比较了使用Datasets而不是RDD来缓存内存中的数百万个字符串。在这两种情况下,缓存数据可以导致后续查询的性能显著的改进。然而,由于数据集编码器向Spark提供有关正在存储的数据的更多信息,因此可以优化缓存的表示以减少数倍(例子中可以减少4.5倍)的空间。
3. Lightning-fast Serialization with Encoders(带编码的快如闪电的序列化)
DataSet的编码器经过高度优化,并使用运行时代码生成来构建用于序列化和反序列化的自定义字节码。因此,它们可以比Java或Kryo序列化快得多。
每million object/second 量的数据DataSet的序列化与反序列化速度要比kryo快接近20倍的样子
除了速度之外,编码数据的序列化后的数据大小也明显的更小(达到小了2倍多),从而降低网络传输的成本。此外,序列化数据已经是Tungsten二进制格式,这意味着很多操作都可以立即完成,而不需要实现一个对象。Spark内置支持自动生成原始类型的编码器(例如String,Integer,Long),Scala样例类和Java Bean。我们计划开发此功能,并允许在将来的版本中对自定义类型进行高效的序列化。
4. Java和Scala的单一API
Dataset API的另一个目标是提供一个可用于Scala和Java的统一接口。这种统一对Java用户来说是好消息,因为这确保他们的API不会落后于Scala接口,代码示例可以轻松地从任何一种语言使用,库不再需要处理两种稍微不同的输入类型。对于Java用户来说唯一的区别是他们需要指定要使用的编码器,因为编译器不提供类型信息例如,如果要使用Java处理json数据,可以按如下方式执行:
// 用一个javaBean封装json串中有的字段
public class University implements Serializable {
private String name;
private long numStudents;
private long yearFounded;
public void setName(String name) {...}
public String getName() {...}
public void setNumStudents(long numStudents) {...}
public long getNumStudents() {...}
public void setYearFounded(long yearFounded) {...}
public long getYearFounded() {...}
}
class BuildString implements MapFunction {
public String call(University u) throws Exception {
return u.getName() + " is " + (2015 - u.getYearFounded()) + " years old.";
}
}
Dataset schools = context.read().json("/schools.json").as(Encoders.bean(University.class));
Dataset strings = schools.map(new BuildString(), Encoders.STRING());
参考:
https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
5. 在spark2.x中使用RDD的场景
在以下情况下考虑使用RDD的这些方案或常见用例:
1、您需要对数据集进行低级的transformation和action操作;
2、您的数据是非结构化的,例如媒体流或文本流;
3、您希望使用功能编程构造来操纵您的数据而不是域特定表达式;
4、在通过名称或列来处理或访问数据属性时,您并不关心强加模式,例如柱状格式;
5、您可以放弃针对结构化和半结构化数据的DataFrames和Datasets提供的一些优化和性能优势。
5.1 Spark2.x中的RDD
spark2.0中RDD并没有被降为二等公民,被废弃,DataFrame和DataSet是构建在RDD基础之上的,可以通过简单的API方法调用在DataFrame或Dataset和RDD之间无缝移动
5.2 spark2.x中DataFrames
像RDD一样,DataFrame是一个不可变的分布式数据集合。与RDD不同,数据被组织成指定的列,比如关系数据库中的表。旨在使大数据集处理更加容易,DataFrame允许开发人员将结构强加于分布式数据集合,从而允许更高层次的抽象; 它提供了一个域专用语言API来操纵您的分布式数据;并使Spark能够接触到更多的受众,不止是专业的数据工程师。
5.3 spark2.x中Datasets
从Spark 2.0开始,Dataset具有两个不同的API特性:强类型 API和无类型的API,如下表所示,概念上,
将DataFrame视为一个通用对象DataSet[Row]的一个别名,其中一行是一个通用的无类型的JVM对象。相比之下,DataSet是强类型的JVM对象的集合,由您在Scala中定义的样例类或Java中的类决定。
Typed and Un-typed APIs
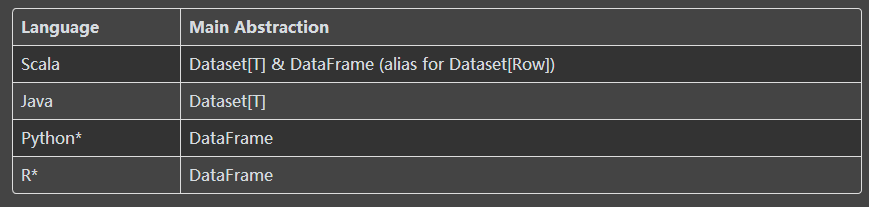
Note:
由于Python和R语言没有编译时类型安全检查,仅仅只有无类型化的API,即DataFrames
5.4 DataSets API的优点
作为Spark开发人员,您可以通过多种方式在Spark 2.0中受益于DataFrame和Dataset统一API。
5.4.1 静态类型和运行时类型安全
把静态类型和运行时安全性作为一个频谱,类型检查限制最少的是SQL最严格的是DataSet。例如,在您的Spark SQL字符串查询中,您将不会知道语法错误,直到运行时(这个代价可能是昂贵的),而在DataFrames和Datasets中,您可以在编译时捕获错误(这节省了开发人员的时间和成本)。也就是说,如果在DataFrame中调用不属于它自己的API的函数,编译器将会捕获它。但是,直到运行时才会检测到不存在的列名。
在谱的最远端是DataSet,最具限制性。由于Dataset API都被表示为lambda函数和JVM类型对象,因此 在编译时将检测到任何类型参数的不匹配。此外,在编译时也可以检测到语义解析错误,当使用Datasets时,可以节省开发人员的时间和成本。

5.4.2 将高级抽象和自定义视图转换为结构化和半结构化数据
DataFrames作为Datasets[Row]集合将结构化自定义视图呈现到半结构化数据中。例如,假设你有一个巨大的IoT(物联网)设备事件数据集,表示为JSON。由于JSON是一种半结构化格式,因此它很适合将自己作为DataSet指定为强类型的Dataset[DeviceIoTData]的集合。
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
可以使用Scala样例类将每个JSON条目表示为DeviceIoTData(一个自定义对象)。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
下一步可以从jsonfile中读取数据spark is the SparkSession
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
// 在该步骤前应该调用import spark implicits._
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
在上面的代码中,有三件事情发生在这里:
1.Spark读取JSON,推断类型结构,并创建一个DataFrames的集合。
2.这个时候,Spark将您的数据转换为DataFrame =Dataset[Row],这是一个通用Row对象的集合,因为它不知道确切的类型。
3.现在,Spark转换Dataset[Row] -> Dataset[DeviceIoTData]类型的特定的Scala JVM对象,如
DeviceIoTData类所示。
我们大多数人使用结构化数据习惯于以柱状方式查看和处理数据或访问对象内的特定属性。使用Dataset作为Dataset[ElementType]类型对象的集合,您无缝地获得强类型JVM对象的编译时安全性和自定义视图。并且您从上述代码获得的强类型DataSet[T]可以用高级方法轻松显示或处理。
5.4.3 易于使用的API结构
虽然结构可能会限制您的Spark程序对数据的控制,但它引入了丰富的语义和一组容易的域特定操作,可以表示为高级结构。然而,大多数计算可以使用Dataset的高级API来实现。例如,它能更简单的通过访问DataSet类型对象的DeviceIoTData执行agg,select,sum,avg,map,filter,或groupBy而不是使用RDD rows的数据字段
在域特定的API中表达您的计算比使用关系代数类型表达式(在RDD中)更简单和更容易。例如,下面的代码将filter() and map() 创建另一个不可变数据集。
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
5.4.4 性能与优化
除了上述所有优点,您不能忽视使用DataFrames和Dataset API的空间效率和性能提升,原因有两个。
首先,因为DataFrame和Dataset API构建在Spark SQL引擎之上,所以它使用Catalyst来生成优化的逻辑和物理查询计划。通过R,Java,Scala或Python DataFrame / Dataset API,所有关系类型查询都经历相同的代码优化器,提供空间和速度效率。而DataSet[T]y有类型的API针对数据工程任务进行了优化,无类型的DataSet[Row](DataFrame的别名)甚至更快,适合交互式分析。
其次,由于Spark作为编译器了解您的Dataset类型的JVM对象,因此使用编码器将指定类型的JVM对象映射到Tungsten的内部存储器中表示。因此,Tungsten编码器可以有效地对JVM对象进行序列化/反序列化,并生成可以以优异速度执行的紧凑字节码。
6. 什么时候应该使用DataFrames或Datasets?
1.如果您需要丰富的语义,高级抽象和域特定的API,请使用DataFrame或Dataset。
2.如果您的处理需要高层次表达式,filters, maps, aggregation, averages, sum,SQL查询,柱状访问以及对半结构化数据使用lambda函数,请使用DataFrame或Dataset。
3.如果要在编译时要求更高级别的类型安全性,则需要类型化的JVM对象,利用Catalyst优化器,并从Tungsten的高效代码生成中受益,使用Dataset。
4.如果要在Spark Libraries之间统一并简化API,请使用DataFrame或Dataset。
5.如果您是R用户,请使用DataFrames。
6.如果您是Python用户,请使用DataFrames,如果需要更多控制,请返回RDD。
参考:
https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
spark2.0新特性之DataSet的更多相关文章
- 浅谈Tuple之C#4.0新特性那些事儿你还记得多少?
来源:微信公众号CodeL 今天给大家分享的内容基于前几天收到的一条留言信息,留言内容是这样的: 看了这位网友的留言相信有不少刚接触开发的童鞋们也会有同样的困惑,除了用新建类作为桥梁之外还有什么好的办 ...
- Java基础和JDK5.0新特性
Java基础 JDK5.0新特性 PS: JDK:Java Development KitsJRE: Java Runtime EvironmentJRE = JVM + ClassLibary JV ...
- Visual Studio 2015速递(1)——C#6.0新特性怎么用
系列文章 Visual Studio 2015速递(1)——C#6.0新特性怎么用 Visual Studio 2015速递(2)——提升效率和质量(VS2015核心竞争力) Visual Studi ...
- atitit.Servlet2.5 Servlet 3.0 新特性 jsp2.0 jsp2.1 jsp2.2新特性
atitit.Servlet2.5 Servlet 3.0 新特性 jsp2.0 jsp2.1 jsp2.2新特性 1.1. Servlet和JSP规范版本对应关系:1 1.2. Servlet2 ...
- 背水一战 Windows 10 (1) - C# 6.0 新特性
[源码下载] 背水一战 Windows 10 (1) - C# 6.0 新特性 作者:webabcd 介绍背水一战 Windows 10 之 C# 6.0 新特性 介绍 C# 6.0 的新特性 示例1 ...
- C# 7.0 新特性2: 本地方法
本文参考Roslyn项目中的Issue:#259. 1. C# 7.0 新特性1: 基于Tuple的“多”返回值方法 2. C# 7.0 新特性2: 本地方法 3. C# 7.0 新特性3: 模式匹配 ...
- C# 7.0 新特性1: 基于Tuple的“多”返回值方法
本文基于Roslyn项目中的Issue:#347 展开讨论. 1. C# 7.0 新特性1: 基于Tuple的“多”返回值方法 2. C# 7.0 新特性2: 本地方法 3. C# 7.0 新特性3: ...
- C# 7.0 新特性3: 模式匹配
本文参考Roslyn项目Issue:#206,及Docs:#patterns. 1. C# 7.0 新特性1: 基于Tuple的“多”返回值方法 2. C# 7.0 新特性2: 本地方法 3. C# ...
- C# 7.0 新特性4: 返回引用
本文参考Roslyn项目中的Issue:#118. 1. C# 7.0 新特性1: 基于Tuple的“多”返回值方法 2. C# 7.0 新特性2: 本地方法 3. C# 7.0 新特性3: 模式匹配 ...
随机推荐
- Job for keepalived.service failed because the control process exited with error code. See "systemctl status keepalived.service" and "journalctl -xe" for details.
解决方案 https://blog.csdn.net/zt15732625878/article/details/86493096
- otter安装、使用
一.otter简介 otter是阿里开源的一个分布式数据库同步系统,尤其是在跨机房数据库同步方面,有很强大的功能.它是基于数据库增量日志解析,实时将数据同步到本机房或跨机房的mysql/oracle数 ...
- produceTestDate
set serveroutput on --使用基本变量类型 declare --定义基本变量:类型 --基本数据类型 pnumber , ); pname ); pdate date; begin ...
- 阶段5 3.微服务项目【学成在线】_day04 页面静态化_06-freemarker基础-遍历map数据
大的map里面有一些小的map 遍历数据模型里面的stuMap <br/> 遍历数据模型中的stuMap(map)数据 <br/> 姓名:${stuMap['stu1'].na ...
- HAProxy+Keepalived 高可用负载均衡
转自 https://www.jianshu.com/p/95cc6e875456 Keepalived+haproxy实现高可用负载均衡 Master backup vip(虚拟IP) 192.16 ...
- 初识MyBatis之HelloWorld
1.先下载MyBatis相关Jar包. 2. 创建数据库和表 CREATE TABLE tbl_employee( id ) PRIMARY KEY AUTO_INCREMENT, last_name ...
- 详解Linux开源安全审计和渗透测试工具Lynis
转载自FreeBuf.COM Lynis是一款Unix系统的安全审计以及加固工具,能够进行深层次的安全扫描,其目的是检测潜在的时间并对未来的系统加固提供建议.这款软件会扫描一般系统信息,脆弱软件包以及 ...
- Linear regression with one variable - Model representation
摘要: 本文是吴恩达 (Andrew Ng)老师<机器学习>课程,第二章<单变量线性回归>中第6课时<模型概述>的视频原文字幕.为本人在视频学习过程中逐字逐句记录下 ...
- OpenGL.资料积累
1.又一种Qt + OpenGL 的离屏渲染方法 - liji_digital的博客 - CSDN博客.html(https://blog.csdn.net/liji_digital/article/ ...
- Hadoop之HDFS介绍
1. 概述 HDFS是一种分布式文件管理系统. HDFS的使用场景: 适合一次写入,多次读出的场景,且不支持文件的修改: 适合用来做数据分析,并不适合用来做网盘应用: 1.2 优缺点 优点: 高容错性 ...