python异步IO编程(二)
python异步IO编程(二)
目录
开门见山
Async IO设计模式
事件循环
asyncio 中的其他顶层函数
开门见山
下面我们用两个简单的例子来让你对异步IO有所了解
import asyncio async def count():
print("One")
await asyncio.sleep(1)
print("Two") async def main():
await asyncio.gather(count(),count(),count()) if __name__ =="__main__":
import time
start_time =time.time()
asyncio.run(main())
end_time = time.time()
print("执行时间:%s" %(end_time-start_time)+"秒")
运行结果:
One
One
One
Two
Two
Two
执行时间:1.0010051727294922秒
这个输出的顺序是异步IO的核心,由单一事件循环或协调器负责与每一个 count() 方法调用交流。当每一个任务执行到 await asyncio.sleep(1)) 时,函数会通知事件循环并交出控制权限,“我要睡眠一秒钟,在此期间,继续做其他有意义的事”(其他协程)。
与同步的版本对比:
def count():
print("One")
time.sleep(1)
print("Two") def main():
for _ in range(3):
count() if __name__ =="__main__":
import time
start_time =time.time()
main()
end_time = time.time()
print("执行时间:%s" %(end_time-start_time)+"秒")
运行结果:
One
Two
One
Two
One
Two
执行时间:3.001182794570923秒
使用 time.sleep() 和 asyncio.sleep() 看起来有点简陋,这里一般用来替代标准输入等耗时的操作。(最简单的等待就是使用 sleep(),基本上什么也不做。)也就是说 time.sleep() 可以表示任何耗时的阻塞函数的调用,而 asyncio.sleep() 用于表示非阻塞的函数调用(但是也是需要一定时间来完成)。
异步io的关键在于,await io操作,此时,当前协程就会被挂起,时间循环转而执行其他携程,但是要注意前面这句话,并不是说所有携程里的await都会导致当前携程的挂起,要看await后面跟的是什么,如果跟的是我们定义的携程,则会执行这个携程,如果是asyncio模块制作者定义的固有携程,比如模拟io操作的asyncio.sleep,以及io操作,比如网络io:asyncio.open_connection这些,才会挂起当前携程。
Async IO设计模式
链接协程
协程的一个关键特性是它们可以被链接到一起。(记住,一个协程是可等待的,所以另一个协程可以使用 await 来等待它。)这个特性允许你将程序划分成更小的,可管理可回收的协程:

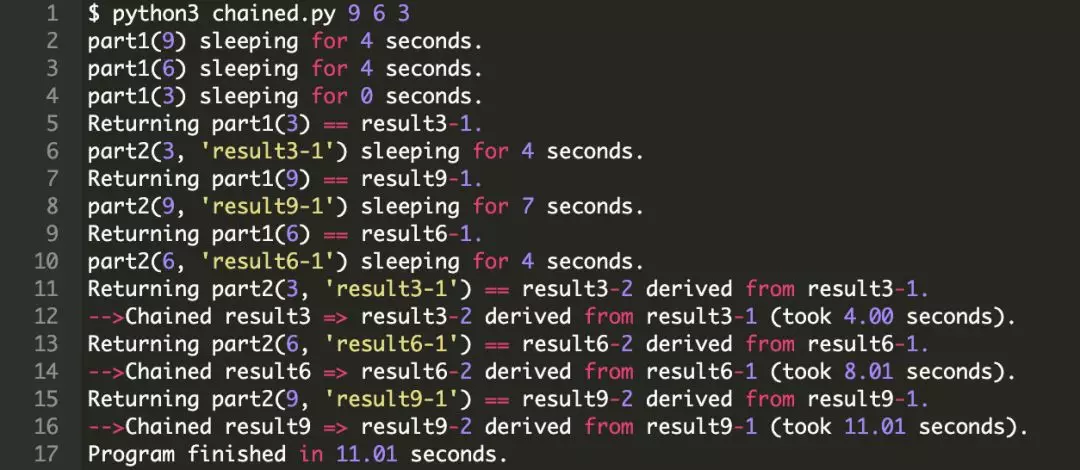
注意观察输出,part1() 的睡眠时间是可变的,而当它的返回结果可用的时候,part2() 开始执行并使用这些结果。
按照设定,main() 函数执行的时间应该与它聚集在一起的任务中最长的一个执行时间相同。
使用队列
在 asyncio 包中提供了与队列模块中相似的队列类。目前为止,我们的例子中还没有使用到队列结构。在 chained.py 中的每一个 task(feature) 都由一组协程组成,这些协程都有一个单一的输入链,并显式的等待其它协程。
还有一种结构同样可以配合异步IO使用:许多互不关联的生产者将元素加入到一个队列中,每一个生产者可能在不同的时间,随机且无序的加入多个元素到队列中。还有一组消费者不管任何信号,不停地从队列中拉取元素。
这种设计中,任何一个生产者和消费者都没有关联。消费者事先并不知道生产者的数量,甚至不知道将累计添加的队列中的元素数。
它需要一个单独的生产者或消费者在一个可指定的时间内,分别向队列中放入或从队列中提取元素。生产者与消费者通过队列的吞吐进行通信,而不是两者直接通信。
----------
注:由于 queue.Queue() 是线程安全的,所以它经常被用于开发基于线程的程序,而在异步IO编程中你不需要关心线程安全问题。(除非你将这两者合并在一起使用,但在本教程中并没有这么做。)
队列的一种用法(比如这里的情况)是充当生产者与消费者之间的通信通道,从而避免它们直接关联或联系。
----------
这个程序的同步版本看起来有些让人不忍直视:一组生产者连续且阻塞的向队列中添加元素,一次只有一个生产者在工作。只有当所有生产者都运行结束,消费者才会从队列中一个接一个的取出元素并处理。这会造成大量的延时。元素可能会在队列中被搁置,而不是被立刻取出并处理。
而异步版本的程序 asyncq.py 如下所示。运行过程中的难点是向消费者发送生产者已经完成的信号。否则,await q.get() 将会因为队列已满而被无限挂起,但是消费者却不知道生产者已经完成的信息。
这里是全部的脚本文件:

几个协程作为辅助函数返回随机字符串,几分之一秒的性能计数器以及随机整数。生产者将1-5的元素放入队列中,每一个元素都是一个 (i, t) 的元组,其中 i 是一个随机字符串,t 是生产者尝试将元组放入队列所需要的时间。
当消费者从队列取出元素时,它只使用元素放入队列时所使用的时间戳计算耗费时间。
牢记 asyncio.sleep() 用于模仿其他复杂的协程,如果这里是常规阻塞函数,则会耗尽时间并阻塞其他所有函数的运行。
这里有一个实现了两个生产者和五个消费者的测试例子
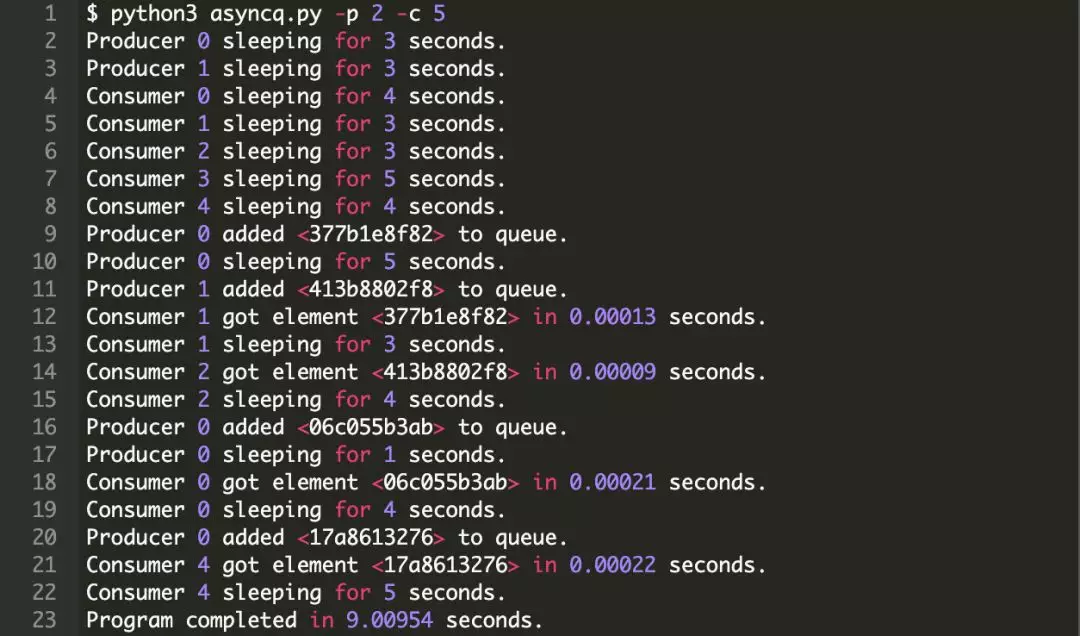
这个例子中,元素在几分之一秒内被处理好,产生延时可能有两个原因:
1. 很大程度上不可避免的标准开销
2. 元素出现在队列中,而所有消费者都在睡眠的情况
幸运的是,关于第二个原因,正常情况下,将消费者扩展到成百上个也是允许的。你不应该对 python3 asyncq.py -p 5 -c 100 有什么疑问。这里有一点比较关键,理论上你可以使用不同的操作系统和用户来管理和控制生产者和消费者,而队列作为中间消息吞吐的媒介。
目前,你已经进入到异步IO的学习中,并且看到了三个由 async 和 await 定义的协程以及 asyncio 调用的相关示例。如果你只是想深入了解Python新式协程的实现机制,而并不是想全盘关注,下一节将会有一个直观的介绍。
事件循环
可以把事件循环看作一个监控协程的 while True 循环,获取协程被闲置期间的反馈,以及可以在此期间执行的内容。它可以对处于等待态的协程可用时唤起闲置协程。
Python 3.7中引入的 asyncio.run() 负责获取事件循环,在任务被标记完成前运行任务,然后关闭事件循环。
事件循环的整个管理过程由一个函数调用隐式处理:
asyncio.run(main())
使用 get_event_loop() 管理 asyncio 事件循环还有一种更为繁复的方式,典型的示例如下所示:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(main())
finally:
loop.colse()
可能经常在旧的示例中看到 loop.get_event_loop(),但是除非你需要对事件循环进行精细的控制,使用 asyncio.run() 应该足以满足大多数程序的需要。
如果你需要在Python程序中与事件循环交互,那么旧式风格的 loop 是一个不错的选择,它支持使用 loop.is_running() 和 loop.is_closed() 进行自省。如果需要获得更精细的控制也可以进行操作,例如通过循环参数传递来 调度回调函数。
更重要的是理解事件循环的底层实现机制,这里有几点关于事件循环需要强调的:
#1:协程在与事件循环绑定之前不会自行处理。
你已经在关于生成器的解释中看到过这一点,但是这仍值得重申一遍。如果有一个需要等待其它协程的主协程,那么简单的单独调用它几乎没有效果:

记住,在调度 main() 协程(future对象)时使用 asyncio.run() 会真正强制执行事件循环。

(其它协程可以通过 await 执行,通常会在 asyncio.run() 中包装 main() 函数,然后在这里使用 await 调用链式协程。)
#2:默认情况下,一个异步IO事件循环会运行在单核CPU的单线程中,通常,单核CPU运行一个单线程的事件循环是绰绰有余的。跨多核运行事件循环也是可行的。更多信息可以参考 John Reese 的演讲,同时要关注你的笔记本可能会超负荷运载转。
#3:事件循环是可插拔的。就是说,如果你想,你可以实现自己的事件循环并执行相同的任务。CPython实现的 uvloop 包就很好的说明了这一点。
”可插拔式事件循环“可以可以理解为:你可以使用任何可用的事件循环的实现,这与协程本身的结构无关。asyncio 包自带了两个不同的事件循环实现,默认实现基于 selectors 模块。(第二种实现仅适用于Windows系统。)
asyncio 中的其他顶层函数
除了 asyncio.run(),你还看到过其它诸如 asyncio.create_task() 和 asyncio.gather() 的包级函数。
你可以在 asyncio.run() 之后使用 create_task() 来调度协程对象的执行。
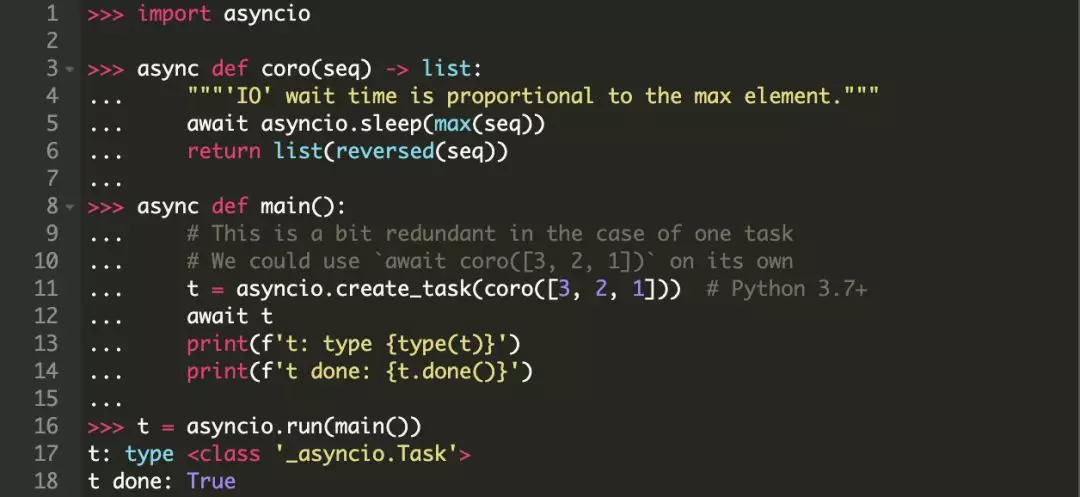
这种模式有一个巧妙之处:如果你不在 main() 中使用 await t,那么它可能在执行完成之前收到 main() 的信号并结束。因为 asyncio.run(main()) 调用了 loop.run_until_complete(main()) 方法,事件循环只会关注(没有显式使用await t的情况下)main() 方法是否完成,而不会关注 main() 中创建的任务是否完成。没有 await t,循环中的其他任务在它们运行完成之前可能会被取消。如果有需要,你可以使用 asyncio.Task.all_tasks()获取当前挂起的任务列表。
注:asyncio.create_task() 是在Python 3.7被引入的。在Python 3.6以及更早的版本中,使用 asyncio.ensure_future() 代替 create_task()。
另外,还有 asyncio.gather()。虽然 gather() 并没有做什么特殊的事情,只是将一组协程(futures)放到一个 future 中。它会返回一个 future 对象作为结果,并且,如果你使用了 await asyncio.gather() 并指定了多个任务或协程,那么它会等待所有的任务或协程运行结束。(这与我们之前示例中queue.join() 有些相似。)在 gather() 的返回中包含所有输入后的结果列表。
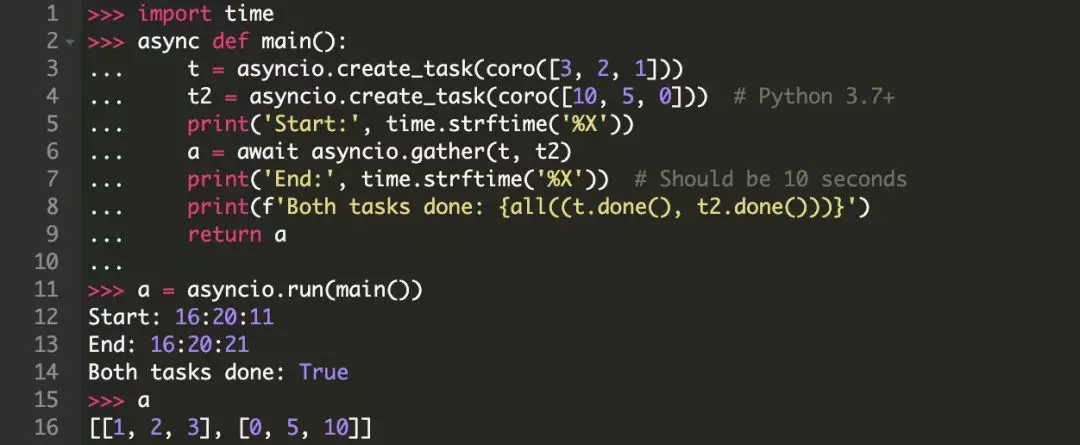
你可能已经注意到 gather() 会等待你传给它的 Futures 或协程的结果集。或者你可以顺序遍历 asyncio.as_completed() 来完成任务,该方法会返回一个迭代器,在完成任务时返回结果。像下面这样,在 coro([10, 5, 0]) 完成之前,coro([3, 2, 1]) 的结果已经可用了,而使用 gather() 则与之不同:
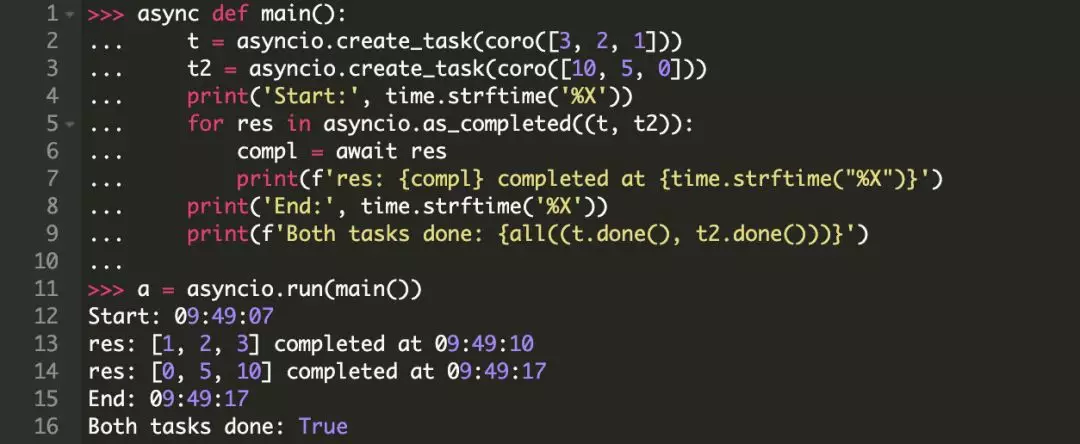
最后,你还应该知道 asyncio.ensure_future()。你可能很少会用到它,因为它是一个比较低级别的管道API,并且很大程度上被后来引入的 create_task() 所替代。
await 的优先级
虽然关键字 await 与 yield 的行为有些相似,但是 await 的优先级明高于后者。这意味着更严格的编码约束,在很多实例中需要在 yield 语句中时使用括号,而相同功能时使用 await 则不需要加括号。有关更多信息,请参阅PEP 492中await表达式示例。
资源附录
Python的几个特殊版本
Python中的异步IO发展之迅速,已经难以追踪其更新历程。这里列出了几个与 asyncio 有关的Python的小版本变更以及介绍:
3.3:在生成器中开始允许 yield from 表达式。
3.4:asyncio 作为临时性功能被引入Python的标准库。
3.5:async 和 await 加入Python语法,用于标识和等待协程运行。此时它们还没有成为保留关键字。(你仍然可以使用async 和await 定义函数名或变量名。)
3.6:引入了异步生成器与异步推导式。宣布 asyncio 为稳定版,而不再是临时版。
3.7:async 和 await 成为保留关键字。(它们不能再用作标识符。)它们主要用在替换 asyncio.coroutine() 生成器。在 asyncio 包中引入了 asyncio.run() 以及其他许多功能。
如果你想要保证安全(并且能够使用 asyncio.run()),那么你可以使用Python 3.7或更高的版本来获取完整的功能集。
转载:
https://mp.weixin.qq.com/s/fJaXmfHfYEk6XL2y8NmKmQ
https://mp.weixin.qq.com/s/RjDh7AITty92jxC8jIOiPA
https://mp.weixin.qq.com/s/vlH_2S2JIJpf3N0WRNcIJQ
python异步IO编程(二)的更多相关文章
- python异步IO编程(一)
python异步IO编程(一) 基础概念 协程:python generator与coroutine 异步IO (async IO):一种由多种语言实现的与语言无关的范例(或模型). asyncio ...
- Python异步IO --- 轻松管理10k+并发连接
前言 异步操作在计算机软硬件体系中是一个普遍概念,根源在于参与协作的各实体处理速度上有明显差异.软件开发中遇到的多数情况是CPU与IO的速度不匹配,所以异步IO存在于各种编程框架中,客户端比如浏览 ...
- Python之IO编程——文件读写、StringIO/BytesIO、操作文件和目录、序列化
IO编程 IO在计算机中指Input/Output,也就是输入和输出.由于程序和运行时数据是在内存中驻留,由CPU这个超快的计算核心来执行,涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.从 ...
- Python之IO编程
前言:由于程序和运行数据是在内存中驻留的,由CPU这个超快的计算核心来执行.当涉及到数据交换的地方,通常是磁盘.网络等,就需要IO接口.由于CPU和内存的速度远远高于外设的速度,那么在IO编程中就存在 ...
- Python异步IO之协程(一):从yield from到async的使用
引言:协程(coroutine)是Python中一直较为难理解的知识,但其在多任务协作中体现的效率又极为的突出.众所周知,Python中执行多任务还可以通过多进程或一个进程中的多线程来执行,但两者之中 ...
- Python - 异步IO\数据库\队列\缓存
协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程,协程一定是在单线程运行的. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和 ...
- Java IO编程全解(三)——伪异步IO编程
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/7723174.html 前面讲到:Java IO编程全解(二)--传统的BIO编程 为了解决同步阻塞I/O面临 ...
- Python笔记-IO编程
IO在计算机中是指input和output(数据输入与输出),涉及到数据交换(磁盘.网络)的地方就需要IO接口. 输入流input stream是指数据从外面(磁盘.网络服务器)流入内存:输出流out ...
- Python异步IO
在IO操作的过程中,当前线程被挂起,而其他需要CPU执行的代码就无法被当前线程执行了. 我们可以使用多线程或者多进程来并发执行代码,为多个用户服务. 但是,一旦线程数量过多,CPU的时间就花在线程切换 ...
随机推荐
- 图片加载框架之Glide和Picasso
Glide介绍 Glide是一个加载图片的库,作者是bumptech,它是在泰国举行的google 开发者论坛上google为我们介绍的,这个库被广泛的运用在google的开源项目中. Glide是一 ...
- java初级之数组详解
一,数组的概念: 数组是为了存储同一种数据多个元素的集合,也可以看成是一个容器,数组既可以存储基本数据类型,也可以存储引用数据类型,数组是为了存储同种数据类型的多个值. 1.1.1,一维数组重点: 数 ...
- Selenium 2自动化测试实战31(跳过预期和预期失败)
跳过预期和预期失败 在运行测试时,有时需要直接跳过某些测试用例,或者当用例符合某个条件时跳过测试,又或者直接将测试用例设置为失败.unittest提供了实现这些需求的装饰器. --unittest.s ...
- Linux的ifconfig看到的信息详解
Linux的ifconfig看到的信息详解 [root@localhost ~]# ifconfig eth0 Link encap:Ethernet HWaddr :::BF:: inet addr ...
- 简单场景的类继承、复杂场景的类继承(钻石继承)、super、类的方法
1.python子类调用父类成员有2种方法,分别是普通方法和super方法 class Base(object): #基类的表示方法可以多种,Base(),Base,Base(object),即新式类 ...
- webdriervAPI(XPath元素定位)
from selenium import webdriver driver = webdriver.Chorme() driver.get("http://www.baidu.co ...
- C# 重写WndProc
重写WndProc方法来处理 Windows 消息 处理 Windows 消息. 在开发winForm时,常常要处理Windows消息,可以重写WndProc来实现.常见代码如下: using Sys ...
- 谷歌云SSH开启root密码登陆
废话不多说,开始教程 1.先选择从浏览器打开ssh连接服务器连接登录成功后,输入以下命令 sudo -i #切换到root passwd #修改密码 然后会要求输入新密码,然后再重复一次密码,输入密码 ...
- sql sever 两数据表差异比较EXCEPT、INTERSECT
1.概念: EXCEPT主要是用来获取两个结果集的差:两个结果用EXCEPT链接,返回第一个结果集不在第二个结果集中的数据. INTERSECT主要是用来获取两个结果集的交集:两个结果用INTERSE ...
- JAVAEE 7 api.chm
JAVAEE 7 api.chm 链接:https://pan.baidu.com/s/1LUD3oam5B-Hp8tdpfQYk2w 提取码:x1kc