ELK 日志收集系统
传统系统日志收集的问题
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下。
通常,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
查询命令:
tail -n 300 myes.log | grep 'node-1'
tail -100f myes.log
ELK分布式日志收集系统介绍
ElasticSearch 是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
ELK分布式日志收集原理
1、每台服务器集群节点安装Logstash日志收集系统插件
2、每台服务器节点将日志输入到Logstash中
3、Logstash将该日志格式化为json格式,根据每天创建不同的索引,输出到ElasticSearch中
4、浏览器使用安装Kibana查询日志信息
环境安装
1、安装ElasticSearch
2、安装Logstash
3、安装Kibana

Logstash介绍
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。 核心流程:Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
Logstash工作原理
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
logstash:输入(读取本地文件或者连接数据库)、输出Json 格式。
Input:输入数据到logstash,再由logstatsh输出(Json格式)数据到es服务器上。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tail -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。

Logstash环境安装
1、上传 logstash 安装包,我的目录为 /usr/local/es/
2、解压 tar –zxvf logstash-6.4.3.tar.gz
3、在config目录下放入test01.conf、test02.conf 读入并且读出日志信息

演示效果
1、启动./logstash -f ../config/test01.conf、./logstash -f ../config/test01.conf 分别指的是二个不同的配置文件,test01 是控制台输出 没有添加时间 输出,test02 是打印了时间。
2、启动./elasticsearch
3、启动./kibana Logstash 读取本地文件地址,实时存放在ES中,以每天格式创建不同的索引进行存放。
Kibana 平台查询
GET /es-2019.06.12/_search
test01.conf
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
}
test02.conf
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/usr/local/es/elasticsearch-6.4.3/logs/myes.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.200.135:9200"]
#### 创建索引 根据每天创建索引
index => "es-%{+YYYY.MM.dd}"
}
}
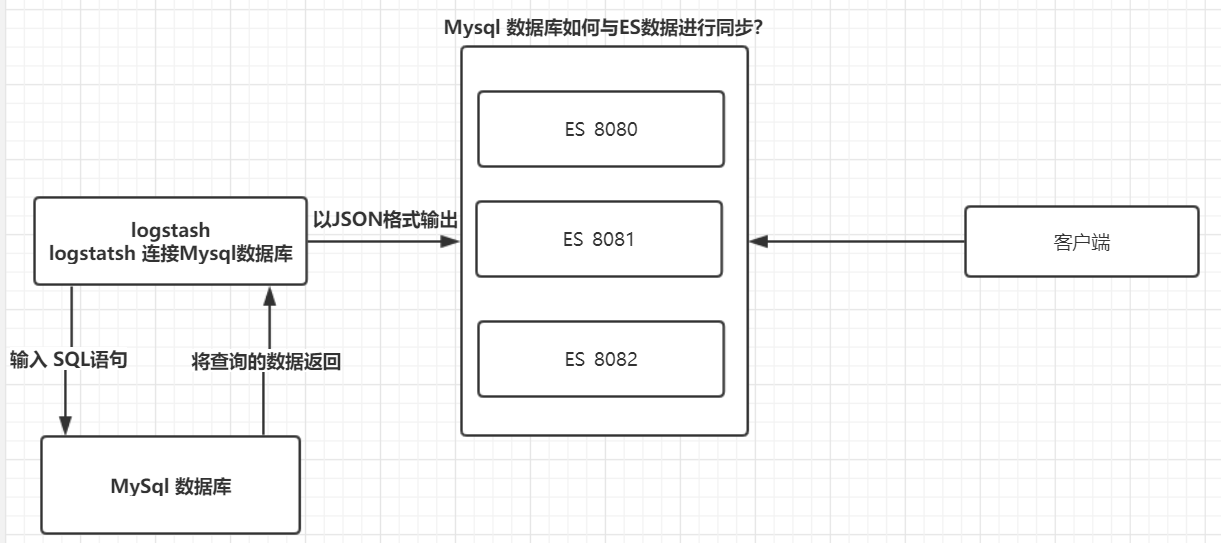
ES与Mysql保持数据一致性原理
logstash包含输入(读取本地文件或者连接数据库)与输出、过滤器。
如果数据新增或者修改了,ES 与 数据库如何保持一致性?

该博客内容来自蚂蚁课堂:http://www.mayikt.com/
ELK 日志收集系统的更多相关文章
- ELK日志收集系统搭建
架构图 ELK 架构图:其中es 是集群,logstash 是单节点(猜想除非使用nginx对log4j的网络输出分发),kibana是单机(用不着做成集群). 1.拓扑图 2.logstash ...
- Linux 搭建ELK日志收集系统
在搭建ELK之前,首先要安装Redis和JDK,安装Redis请参考上一篇文章. 首先安装JDK及配置环境变量 1.解压安装包到/usr/local/java目录下[root@VM_0_9_cento ...
- Go语言学习之11 日志收集系统kafka库实战
本节主要内容: 1. 日志收集系统设计2. 日志客户端开发 1. 项目背景 a. 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 b. 当系统机器比较少时,登陆到服务器上查看即可 ...
- springboot 集成 elk 日志收集功能
Lilishop 技术栈 官方公众号 & 开源不易,如有帮助请点Star 介绍 官网:https://pickmall.cn Lilishop 是一款Java开发,基于SpringBoot研发 ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- 日志收集系统ELK搭建
一.ELK简介 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下.因此我们需要集中化的管理 ...
- ELK日志分析系统的应用
收集和分析日志是应用开发中至关重要的一环,互联网大规模.分布式的特性决定了日志的源头越来越分散, 产生的速度越来越快,传统的手段和工具显得日益力不从心.在规模化场景下,grep.awk 无法快速发挥作 ...
- 快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana)
快速搭建应用服务日志收集系统(Filebeat + ElasticSearch + kibana) 概要说明 需求场景,系统环境是CentOS,多个应用部署在多台服务器上,平时查看应用日志及排查问题十 ...
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
随机推荐
- 2018-2019-2 20165209 《网络对抗技术》Exp8: Web基础
2018-2019-2 20165209 <网络对抗技术>Exp8: Web基础 1 基础问题回答和实验内容 1.1基础问题回答 (1)什么是表单 表单在网页中主要负责数据采集功能.一个表 ...
- 2018-2019-2 20165312《网络攻防技术》Exp7 网络欺诈防范
2018-2019-2 20165312<网络攻防技术>Exp7 网络欺诈防范 目录 一.相关知识点总结 二.实验内容 三.实验步骤 四.实验总结及问题回答 五.实验中遇到的问题及解决方法 ...
- Web安全测试 — 手工安全测试方法&修改建议
常见问题 1.XSS(CrossSite Script)跨站脚本攻击 XSS(CrossSite Script)跨站脚本攻击.它指的是恶意攻击者往Web 页面里插入恶意 html代码,当用户浏览该页之 ...
- 使用RESTful风格开发
什么是RESTful风格? REST是REpresentational State Transfer的缩写(一般中文翻译为表述性状态转移),REST 是一种体系结构,而 HTTP 是一种包含了 RES ...
- JMeter_控制器执行效果_给自己挖过的坑
线程及循环设置: 数据文件中放在“循环控制器”中的执行效果:每条数据执行5次,取够50条数据时停止 简单逻辑控制器按下面的目录创建后,执行结果效果同上面循环控制器的执行效果 本来想规整下目录结构,结果 ...
- 转换为CString
CString a, b, c;c = a + b; 使用Format方法方便的实现int.float和double等数字类型转换为CString字符串. %c 单个字符 %d 十进制整数(int) ...
- HTTP和WSGI协议
HTTP协议简介 超文本传输协议(HyperText Transfer Protocol)是一种应用层协议.HTTP是万维网的数据通信的基础.设计HTTP最初的目的是为了提供一种发布和接收HTML页面 ...
- 使用弹窗批量修改数据POPUP_GET_VALUES
转自:https://blog.csdn.net/huanglin6/article/details/81231215 业务场景:在SAP内,有时候需要用户批量维护某些数据,这时候可以使用标准函数PO ...
- videojs调整音频播放语速
参考来源: https://stackoverflow.com/questions/19112255/change-the-video-playback-speed-using-video-js 以下 ...
- Flask框架(2)--编写简单的用户注册--登录场景
为了更好的理解web前后端的工作业务逻辑:本笔记记录用flask框架编写的一个最初级的代码实现简单的用户注册,登录场景: 初次进入首页,提示--游客,欢迎参观,有登录和注册选项, 登录成功后的用户,会 ...