Confluence与Jira安装及后期迁移问题记录
Confluence与Jira
由于线上jira和confluence之前互相关联,confluence的登录用户全部关联自jira的用户,confluence安装时会提示是否关联jira,由于这个问题,我们必须先安装jira,后安装confluence.
confluence环境:
1. /Data/apps/atlassian-confluence-5.8.10 #程序文件
2. /Data/apps/atlassian-confluence-5.8.10/bin/start-confluence.sh #服务启动脚本
3. /Data/apps/atlassian-confluence-5.8.10/bin/start-confluence.sh #服务终止脚本
4. cd /Data/apps/conf-data/attachments/ #附件
5. /Data/apps/conf-data/index/ #索引
jira环境:
1. /Data/apps/atlassian-jira-6.3.15-standalone/ #程序文件
2. /Data/apps/atlassian-jira-6.3.15-standalone/bin/start-jira.sh #服务启动脚本
3. /Data/apps/atlassian-jira-6.3.15-standalone/bin/stop-jira.sh #服务终止脚本
4. /Data/apps/jira-data/caches #索引
5. /Data/apps/jira-data/data #附件
一. jira和confluence共同安装环境:
1. jira和confluence都依赖于Java环境,需要安装oracle JDK, 服务器默认环境已经安装1.8版本可以直接使用。
[root@hongfei2-sa ~]# java -version
java version "1.8.0_51"
Java(TM) SE Runtime Environment (build 1.8.0_51-b16)
Java HotSpot(TM) -Bit Server VM (build 25.51-b03, mixed mode)
2. 安装数据库:
可以从公司yum源直接安装也可以自己源码安装
[root@hongfei2-sa ~]# vim /etc/my.cnf #加入如下字段
character-set-server = utf8 #添加编码信息,如果不设置安装完成后会显示乱码
collation-server = utf8_bin
sql_mode = NO_AUTO_VALUE_ON_ZERO #必须添加,不然还原备份文件的时候会报错
default-storage-engine = INNODB #一般默认文件已经存在
max_allowed_packet = 256M #限制数据包大小
[root@hongfei2-sa ~]# service mysqld restart #重启生效 mysql> create database jira character set utf8 collate utf8_bin; #创建数据库
Query OK, row affected (0.00 sec)
mysql> grant all privileges on jira.* to 'jirauser'@'localhost' identified by 'abc123'; #授权用户
Query OK, rows affected (0.00 sec)
mysql> grant all privileges on jira.* to 'jirauser'@'127.0.0.1' identified by 'abc123';
Query OK, rows affected (0.00 sec)
mysql> flush privileges;
Query OK, rows affected (0.00 sec)
二. 安装jira:
1. 为了版本统一直接拷贝线上的安装包:
[root@hongfei2-sa apps]# tar -zxvf atlassian-jira-6.3..tar.gz
[root@hongfei2-sa conf]# pwd
/Data/apps/atlassian-jira-6.3.-standalone/conf
[root@hongfei2-sa conf]# ls
catalina.policy catalina.properties context.xml logging.properties server.xml tomcat-users.xml web.xml
[root@hongfei2-sa conf]# vim server.xml #修改8080为默认的80端口
[root@hongfei2-sa classes]# pwd
/Data/apps/atlassian-jira-6.3.-standalone/atlassian-jira/WEB-INF/classes
[root@hongfei2-sa classes]# vim jira-application.properties
jira.home = /Data/apps/jira-data #定义本地家目录
[root@hongfei2-sa lib]# mkdir /Data/apps/jira-data #创建家目录
[root@hongfei2-sa lib]# pwd
/Data/apps/atlassian-jira-6.3.-standalone/atlassian-jira/WEB-INF/lib #拷贝MySQL JDBC驱动到此目录下
[root@hongfei2-sa bin]# sh start-jira.sh #启动jira服务
[root@hongfei2-sa bin]# ss -tnl #可以看到80端口的和8005已经监听
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN *: *:*
LISTEN *: *:*
LISTEN ::ffff:127.0.0.1: :::*
LISTEN ::: :::*
LISTEN ::: :::*
LISTEN *: *:*
LISTEN ::: :::*
LISTEN ::: :::*
LISTEN *: *:*
LISTEN
驱动文件如下:
mysql-connector-java-5.1.35-bin.jar
注意: jdbc必须导入,不然安装完成为confluence自己默认的数据库,不会有mysql提示。
2. 浏览器访问进行web安装:
http://10.1.21.225 #这里暂时使用IP访问,后期可以指定域名解析。
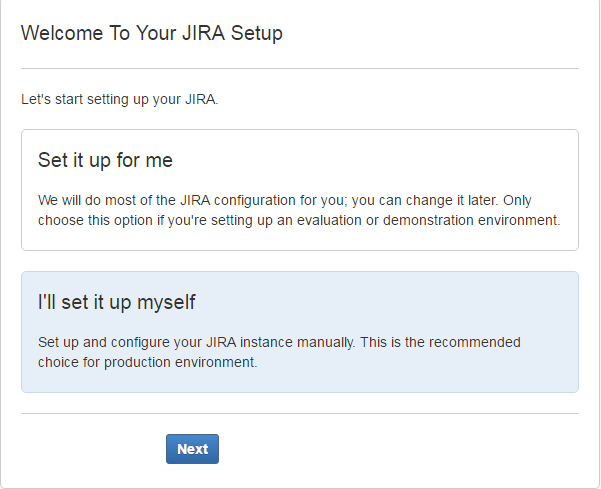
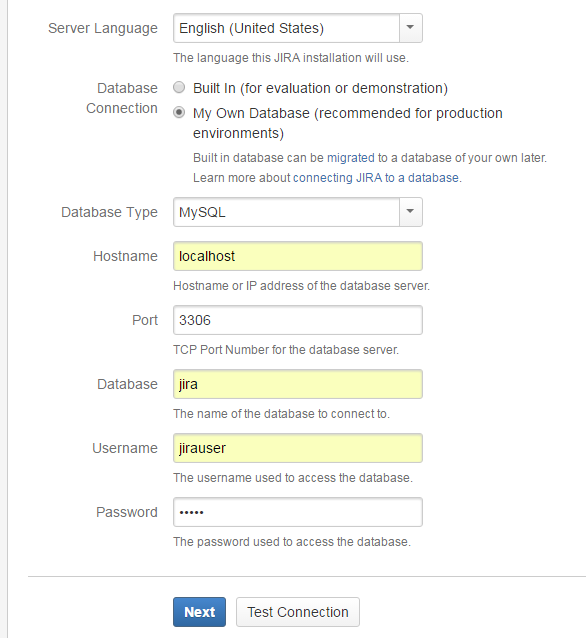


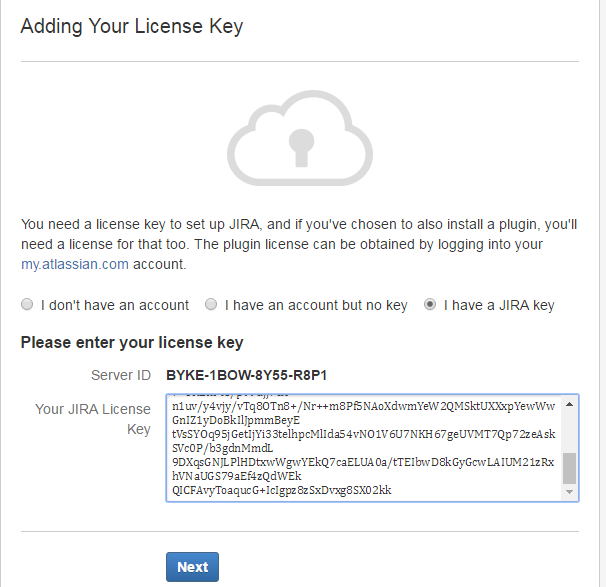
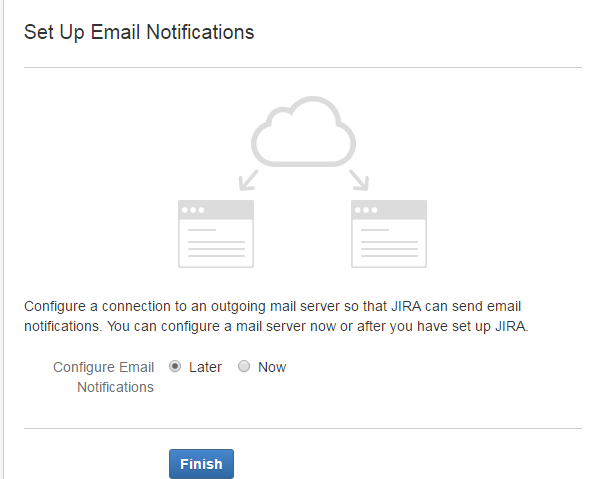
点击完成,大功告成,jira搭建完毕!
三. 安装confluence
1.同样下载线上的安装包并解压:
[root@confluence2.ops.prod.bj1 apps]# tar -zxvf atlassian-confluence-5.8..tar.gz
[root@confluence2.ops.prod.bj1 apps]# mkdir conf-data #创建家目录 [root@confluence2.ops.prod.bj1 classes]# pwd
/Data/apps/atlassian-confluence-5.8./confluence/WEB-INF/classes
[root@confluence2.ops.prod.bj1 classes]# vim confluence-init.properties #定义家目录
confluence.home=/Data/apps/conf-data
[root@confluence2.ops.prod.bj1 classes]# cd ../lib/
[root@confluence2.ops.prod.bj1 lib]# rz #上传MySQL JDBC 驱动 PS: 与jira相同 [root@confluence2.ops.prod.bj1 conf]# pwd
/Data/apps/atlassian-confluence-5.8./conf
[root@confluence2.ops.prod.bj1 conf]# vim server.xml #修改端口8090为80端口 [root@confluence2.ops.prod.bj1 bin]# sh start-confluence.sh #启动服务
[root@confluence2.ops.prod.bj1 bin]# ss -tnl #80和8000端口已经监听
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN ::ffff:127.0.0.1: :::*
LISTEN *: *:*
LISTEN ::: :::*
LISTEN ::: :::*
LISTEN *: *:*
LISTEN ::: :::*
LISTEN ::: :::*
LISTEN *: *:*
LISTEN ::: :::*
LISTEN 127.0.0.1: *:*
2. 浏览器访问:
http://10.1.20.178
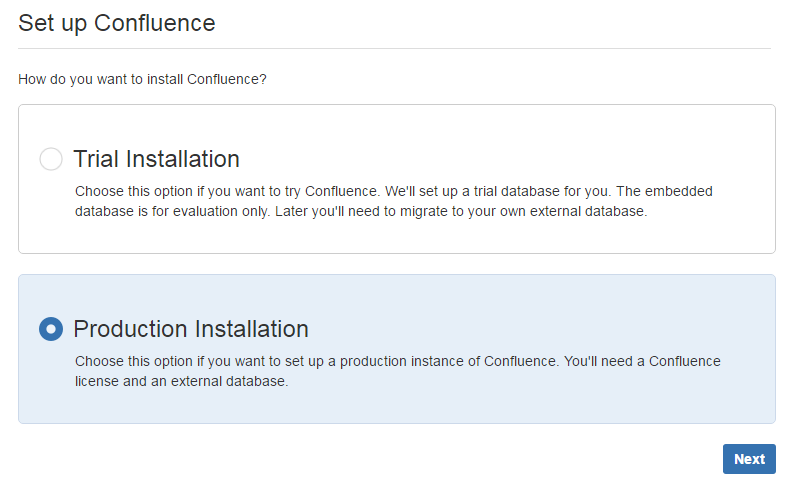

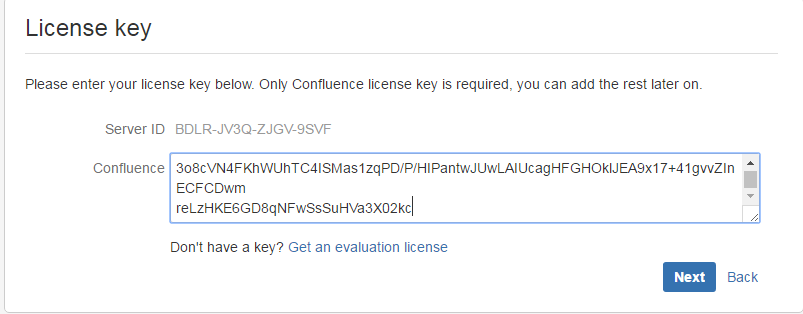
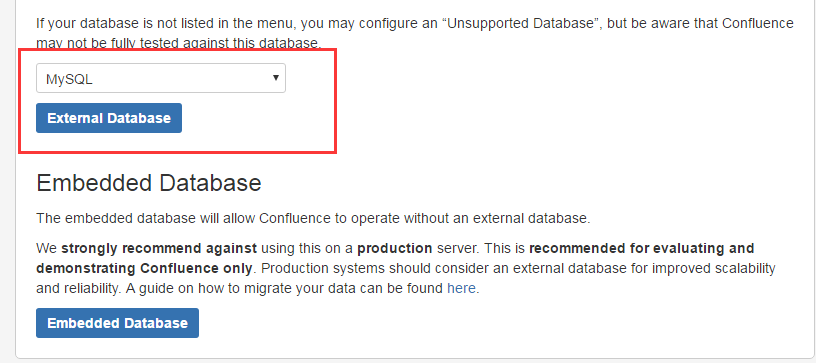
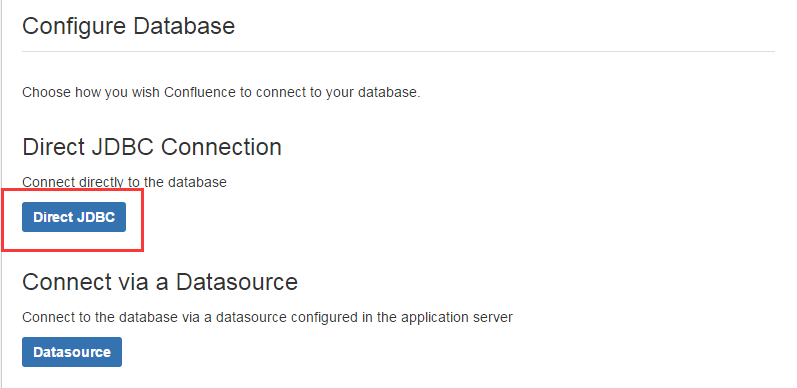

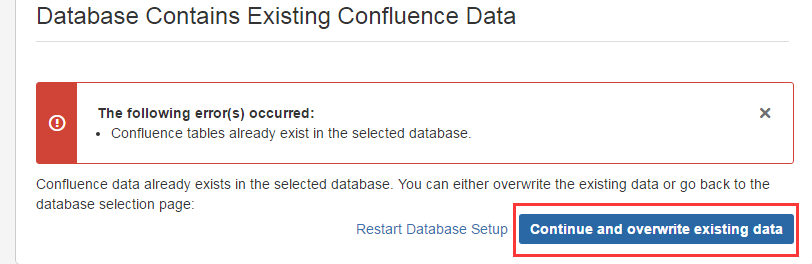
注意: 这里的问题是因为之前已经存在confluence的数据,直接选择清除重写即可。
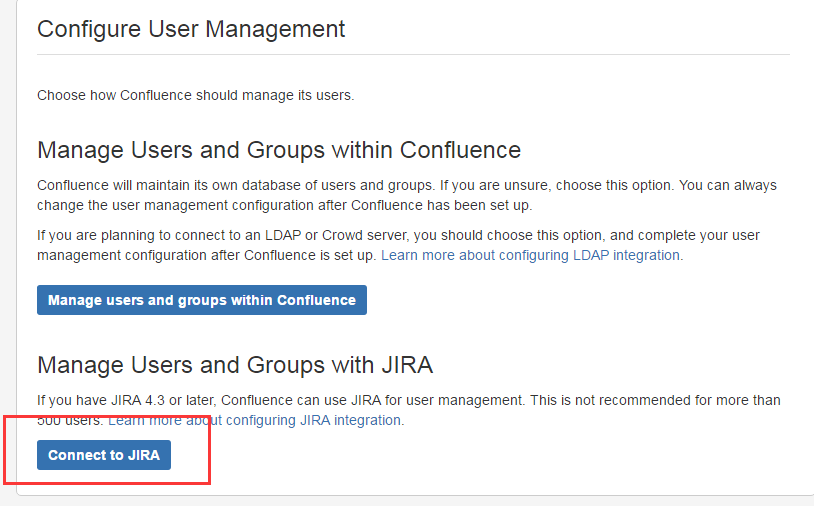
注意: 这里为管理jira用户和用户组,confluence只有自身管理员账户,其他账户都同步字jira里的用户,这里可以设置关联,也可以选择第一项安装完成后关联。

注意: 这里截图有点问题,jira的server地址必须要加http://,正常为http://10.1.20.228

confluence安装完成
注意:
如果遇到输入任何字符都创建空间失败问题,如下:

解决:
这个问题为数据库配置文件有问题,请重新核实是否与文档开始数据库配置的几个参数有差异,没问题,重启mysql即可解决。
四. Jira和Confluence迁移:
1. jira迁移:
jira默认程序每天会备份数据库,默认在/Data/apps/jira-data/export/目录下,也可以手动备份。
jira附件目录: /Data/apps/jira-data/data


注意: 还原的时候授权码必须填写,如果不填写会报sql表错误。
2. confluence迁移:
线上confluence迁移由于其数据量太多,数据库文件太大,所以这里不能使用如jira还原的方法直接还原备份文件
这里使用innobackupex 热备份备份数据到备机还原
首先,正常安装完成,然后用备份数据库替换即可,重启数据库和confluence服务。
注意: 这时候登录的时候会提示登录失败,这是由于此时的confluence是备份线上的数据,线上数据关联的为线上的jira用户,由于设置关联的IP地址和线上是不同的,所以导致授权失败,解决方法如下:
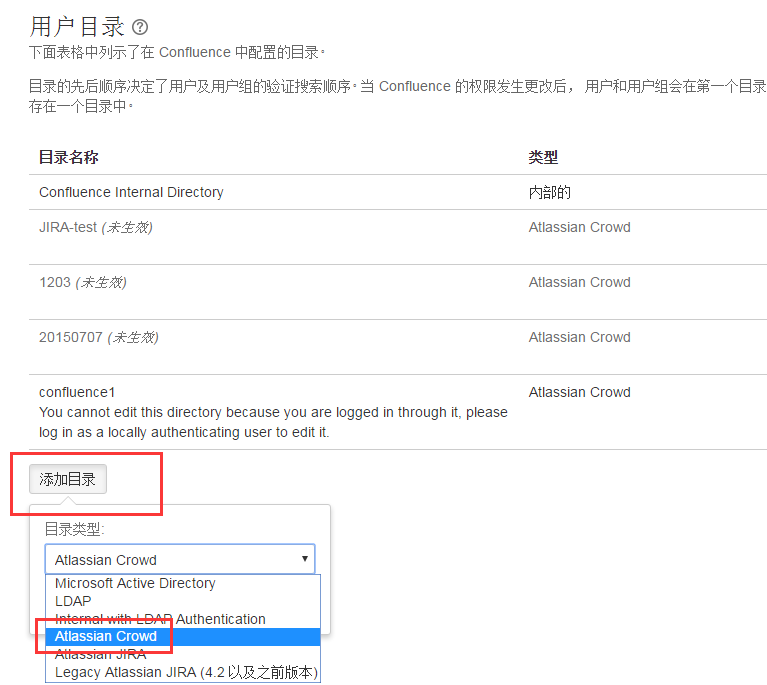
(1)首先登陆线上jira,进入用户目录配置

confluence1即为confluence授权jira用户时的账户名,可以看到后边ip地址池里为线上的confluence地址,所以线上confluence无法正常授权,我们把线下confluence地址加入iP地址列表即可。保存再次访问即可。
(2) 登录confluence,这时候confluence认证是从线上机器认证用户,非线下搭建jira,所以需要添加线下机器的confluence2账户认证:

3. 这里备份的只是数据库的文档,confluence里记录的附件,图片,索引,都在/Data/apps/conf-data/目录下,此目录也需要同步。
总结:
1. 安装时必须导入jdbc,切记为oracle jdk Linux系统自带的open jdk无法识别,安装是不会提示mysql数据库,默认安装为confluence自带的数据库里。
2. confluence安装完成后最后一步让提示输入一个空间名称,这个时候不管输入什么字符都无法通过,因为为无法和数据库交互,数据库配置文件有问题,参考开头数据库配置文件设置。
3. jira和confluence登录后会看到页面混乱,这是因为索引文件和文档匹配不同导致,重新更新索引即可。
4. 迁移时,由于线上confluence数据很大,只能通过备份数据库实现,jira可以通过每天备份文件选择恢复即可,恢复时候确保要输入激活码,不然恢复到最后时会提示错误。
5. confluence还原线上环境后无法登录问题,首先在线上jira环境在confluence1(线上认证账户)添加线下confluenceIP地址,通过线上认证登录账号,添加线下认证账号(confluence2),登录confluence2,添加crowd认证同步即可。
6. 从机器在跑u 一段时间的时候进入主页时会出现页面混乱的现象,这是由于实时同步导致数据不一致。解决方法为:设置–> 外观–> Refresh Client Resources点击链接即可修复。
Confluence与Jira安装及后期迁移问题记录的更多相关文章
- Redis Cluster 4.0高可用集群安装、在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Jira/Confluence的备份、恢复和迁移
之前的文章已经分别详细介绍了Jira.Confluence的安装及二者账号对接的操作方法,下面简单说下二者的备份.恢复和迁移: 一.Jira.Confluence的备份.恢复1)Confluence的 ...
- 使用Crowd集成Confluence与JIRA
一. 独立安装Crowd,步骤1-步骤13的内容二. 设置Confluence使用Crowd进行认证.步骤14-18的内容三. 设置JIRA使用Crowd进行认证,并使用Confluence的组织机构 ...
- confluence与jira账号对接、查看到期时间及问题总结
前面介绍了对于confluence和jira的破解版安装记录,下面简单记录下confluence和jira结合配置:安装顺序:先安装Jira,然后安装Confluence,在Confluence安装过 ...
- Jira安装过程
一.下载jira jira下载路径:https://www.atlassian.com/software/jira/download 二.安装 jira安装一直下一步下一步即可 三.破解 E:\JIR ...
- Ubuntu 下 Mariadb 数据库的安装和目录迁移
Ubuntu 下 Mariadb 数据库的安装和目录迁移 1.简介 本文主要是 Ubuntu 下 Mariadb 数据库的安装和目录迁移,同样适用于 Debian 系统:Ubuntu 20.0.4 M ...
- Centos下安装破解Jira7的操作记录
Jira是一个集项目计划.任务分配.需求管理.错误跟踪于一体的工具,可以作为一个bug管理系统,可以将在测试过程中所发现的bug录入.分配给开发人员.前面介绍了Confluence在Centos下的安 ...
- Redis Cluster高可用集群在线迁移操作记录【转】
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
随机推荐
- 如何从word中直接复制图片到编辑器中
Chrome+IE默认支持粘贴剪切板中的图片,但是我要发布的文章存在word里面,图片多达数十张,我总不能一张一张复制吧?Chrome高版本提供了可以将单张图片转换在BASE64字符串的功能.但是无法 ...
- 乱搞 - LCT求LCA
神犇学弟说LCA要用LCT求,于是我就听他的话写了一个LCT~ Code: #include <bits/stdc++.h> #define N 500005 #define lson t ...
- DP基础(线性DP)总结
DP基础(线性DP)总结 前言:虽然确实有点基础......但凡事得脚踏实地地做,基础不牢,地动山摇,,,嗯! LIS(最长上升子序列) dp方程:dp[i]=max{dp[j]+1,a[j]< ...
- neo4j 一些常用的CQL
创建节点.关系 创建节点(小明):create (n:people{name:’小明’,age:’18’,sex:’男’}) return n; 创建节点(小红): create (n:people{ ...
- Linux+CLion+树莓派远程编译时,Cmake编译出现undefined reference to `vtable for MainWindow'的解决办法
在win+CLion上进行远程qt开发时碰到以下错误: 错误提示: undefined reference to `vtable for MainWindow' 原因:源文件的目录结构有问题?? 解决 ...
- Linux设备驱动程序 之 获取当前时间
墙上时间 内核一般通过jiffies来获取当前时间,该数值表示的是最近一次系统启动到当前的时间间隔,它和设备驱动程序无关,因为它的声明期只限于系统的运行期:但是驱动程序可以用jiffies来计算不同事 ...
- LeetCode 最长公共前缀(探索字节跳动)
题目描述 编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow ...
- centos7 开启80端口
关闭与开启防火墙 systemctl stop firewalld.servicesystemctl start firewalld.service 先查看防火墙是否开启的状态,以及开放端口的情况:s ...
- C++ STL——模板
目录 一 函数模板的特性 二 模板的实现机制 三 类模板 四 类模板如何派生子类 五 普通类的.h和.cpp文件分离 六 类模板在类内类外的实现 七 模板的应用实例 注:原创不易,转载请务必注明原作者 ...
- jQuery常用Method-API
目的:对web页面(HTML/JSP/XML)中的任何标签,属性,内容进行增删改查 (1)DOM简述与分类 (A)DOM是一种W3C官方标准规则,可访问任何标签语言的页面(HTML/JSP/XML) ...