感知机算法及BP神经网络
简介:感知机在1957年就已经提出,可以说是最为古老的分类方法之一了。是很多算法的鼻祖,比如说BP神经网络。虽然在今天看来它的分类模型在很多数时候泛化能力不强,但是它的原理却值得好好研究。先学好感知机算法,对以后学习神经网络,深度学习等会有很大的帮助。
一,感知机模型
(1)、超平面的定义
令w1,w2,...wn,v都是实数(R) ,其中至少有一个wi不为零,由所有满足线性方程w1*x1+w2*x2+...+wn*xn=v
的点X=[x1,x2,...xn]组成的集合,称为空间R的超平面。
从定义可以看出:超平面就是点的集合。集合中的某一点X,与向量w=[w1,w2,...wn]的内积,等于v
特殊地,如果令v等于0,对于训练集中某个点X:
w*X=w1*x1+w2*x2+...+wn*xn>0,将X标记为一类
w*X=w1*x1+w2*x2+...+wn*xn<0,将X标记为另一类
(2)、数据集的线性可分
对于数据集T={(X1, y1),(X2, y2)...(XN, yN)},Xi belongs to Rn,yi belongs to {-1, 1},i=1,2,...N
若存在某个超平面S:w*X=0
将数据集中的所有样本点正确的分类,则称数据集T线性可分。
所谓正确地分类,就是:如果w*Xi>0,那么样本点(Xi, yi)中的 yi 等于1
如果w*Xi<0,那么样本点(Xi, yi)中的 yi 等于-1
因此,给定超平面 w*X=0,对于数据集 T中任何一个点(Xi, yi),都有yi(w*Xi)>0,这样T中所有的样本点都被正确地分类了。
如果有某个点(Xi, yi),使得yi(w*Xi)<0,则称超平面w*X对该点分类失败,这个点就是一个误分类的点。
(3)、感知机模型
f(X)=sign(w*X+b),其中sign是符号函数。
感知机模型,对应着一个超平面w*X+b=0,这个超平面的参数是(w,b),w是超平面的法向量,b是超平面的截距。
我们的目标是,找到一个(w,b),能够将线性可分的数据集T中的所有的样本点正确地分成两类。
二、感知机策略
策略的重点是定义损失函数,即构造出一种能都使得损失最小的函数结构
三、感知机算法
算法的输入为m个样本,每个样本对应于n维特征和一个二元类别输出1或者-1,如下: (x(0)1,x(0)2,...x(0)n,y0),(x(1)1,x(1)2,...x(1)n,y1),...(x(m)1,x(m)2,...x(m)n,ym)(x1(0),x2(0),...xn(0),y0),(x1(1),x2(1),...xn(1),y1),...(x1(m),x2(m),...xn(m),ym)
输出为分离超平面的模型系数θ向量
算法的执行步骤如下:
(1) 定义所有x0x0为1。选择θ向量的初值和 步长α的初值。可以将θ向量置为0向量,步长设置为1。要注意的是,由于感知机的解不唯一,使用的这两个初值会影响θ向量的最终迭代结果。
(2) 在训练集里面选择一个误分类的点(x(i)1,x(i)2,...x(i)n,yi)(x1(i),x2(i),...xn(i),yi), 用向量表示即(x(i),y(i))(x(i),y(i)),这个点应该满足:y(i)θ∙x(i)≤0y(i)θ∙x(i)≤0
(3) 对θ向量进行一次随机梯度下降的迭代:θ=θ+αy(i)x(i)θ=θ+αy(i)x(i)
(4)检查训练集里是否还有误分类的点,如果没有,算法结束,此时的θ向量即为最终结果。如果有,继续第2步。
四、感知机与感知机神经网络 代码实现
net=newp([ ],);
inputweights=net.inputweights{,};
biases=net.biases{}; net=newp([- ;- ],);
net.IW{,}=[- ];
net.IW{,}
net.b{}=;
net.b{}
p1=[;],a1=sim(net,p1)
p2=[;-],a2=sim(net,p2)
p3={[;] [ ;-]},a3=sim(net,p3)
p4=[ ; -],a4=sim(net,p4)
net.IW{,}=[,];
net.b{}=[];
a1=sim(net,p1) net=init(net);
wts=net.IW{,}
bias=net.b{}
net.inputweights{,}.initFcn='rands';
net.biases{}.initFcn='rands';
net=init(net);
bias=net.b{}
wts=net.IW{,}
a1=sim(net,p1) net=newp([- ;- ],);
net.b{}=[];
w=[ -0.8]
net.IW{,}=w;
p=[;];
t=[];
a=sim(net,p)
e=t-a
help learnp
dw=learnp(w,p,[],[],[],[],e,[],[],[],[],[])
w=w+dw
net.IW{,}=w;
a=sim(net,p) P=[-0.5 0.5 -0.1;-0.5 -0.5 ];
T=[ ]
net=newp([- ;- ],);
plotpv(P,T);
plotpc(net.IW{,},net.b{});
%hold on;
%plotpv(P,T);
net=adapt(net,P,T);
net.IW{,}
net.b{}
plotpv(P,T);
plotpc(net.IW{,},net.b{})
net.adaptParam.passes=;
net=adapt(net,P,T);
net.IW{,}
net.b{}
plotpc(net.IW{},net.b{})
net.adaptParam.passes=;
net=adapt(net,P,T)
net.IW{,}
net.b{}
plotpv(P,T);
plotpc(net.IW{},net.b{}) plotpc(net.IW{},net.b{})
a=sim(net,p);
plotpv(p,a) p=[0.7;1.2]
a=sim(net,p);
plotpv(p,a);
hold on;
plotpv(P,T);
plotpc(net.IW{},net.b{}) P=[-0.5 -0.5 0.3 -0.1 -;-0.5 0.5 -0.5 1.0 ]
T=[ ];
net=newp([- ;- ],);
plotpv(P,T);
hold on;
linehandle=plotpc(net.IW{},net.b{});
E=;
net.adaptParam.passes=;
while (sse(E))
[net,Y,E]=adapt(net,P,T);
linehandle=plotpc(net.IW{},net.b{},linehandle);
drawnow;
end;
axis([- - ]);
net.IW{}
net.b{}
net=init(net);
net.adaptParam.passes=;
net=adapt(net,P,T);
plotpc(net.IW{},net.b{});
axis([- - ]);
net.IW{}
net.b{} net=newp([- ;- ],,'hardlim','learnpn');
plotpv(P,T);
linehandle=plotpc(net.IW{},net.b{});
e=;
net.adaptParam.passes=;
net=init(net);
linehandle=plotpc(net.IW{},net.b{});
while (sse(e))
[net,Y,e]=adapt(net,P,T);
linehandle=plotpc(net.IW{},net.b{},linehandle);
end;
axis([- - ]);
net.IW{}
net.b{} net=newp([- ;- ],);
net.trainParam.epochs=;
net=train(net,P,T);
pause;
linehandle=plotpc(net.IW{},net.b{});
hold on;
plotpv(P,T);
linehandle=plotpc(net.IW{},net.b{});
axis([- - ]); p=[1.0 1.2 2.0 -0.8; 2.0 0.9 -0.5 0.7]
t=[ ; ]
plotpv(p,t);
hold on;
net=newp([-0.8 1.2; -0.5 2.0],);
linehandle=plotpc(net.IW{},net.b{});
net=newp([-0.8 1.2; -0.5 2.0],);
linehandle=plotpc(net.IW{},net.b{});
e=;
net=init(net);
while (sse(e))
[net,y,e]=adapt(net,p,t);
linehandle=plotpc(net.IW{},net.b{},linehandle);
drawnow;
end;
matlab运行结果:
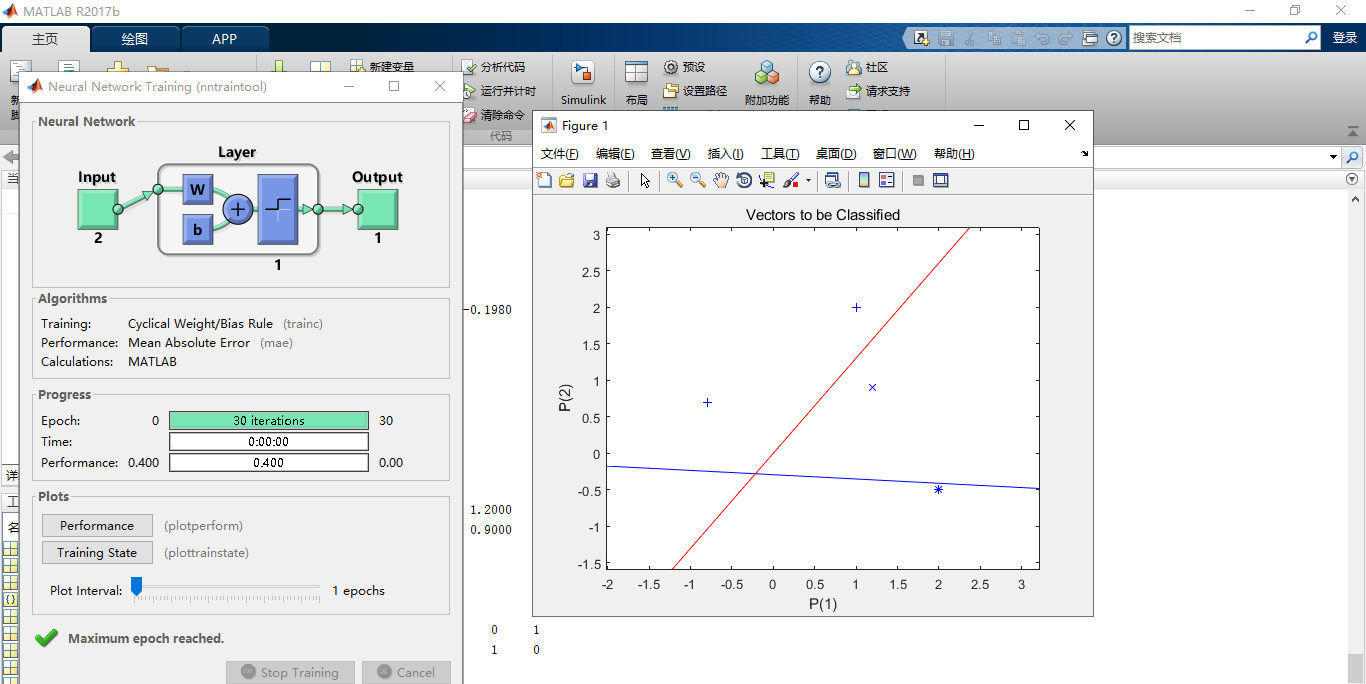
图:1
五、BP神经网络
(1)基本思想
BP神经网络也称为后向传播学习的前馈型神经网络,是一种典型的神经网络。后向传播是一种学习算法,体现为BP的训练过程,该过程是需要监督学习的;前馈型网络是一种结构,体现为BP的网络构架,如图2就是一个典型的前馈型神经网络.这种神经网络结构清晰,使用简单,而且效率也很高,因此得到了广泛的重视和应用。反向传播算法通过迭代处理的方式,不断的调整连接神经元的网络权重,使得最终输出结果和预期结果的误差最小。广泛应用于各种分类系统,他也包括了训练和使用两个阶段。
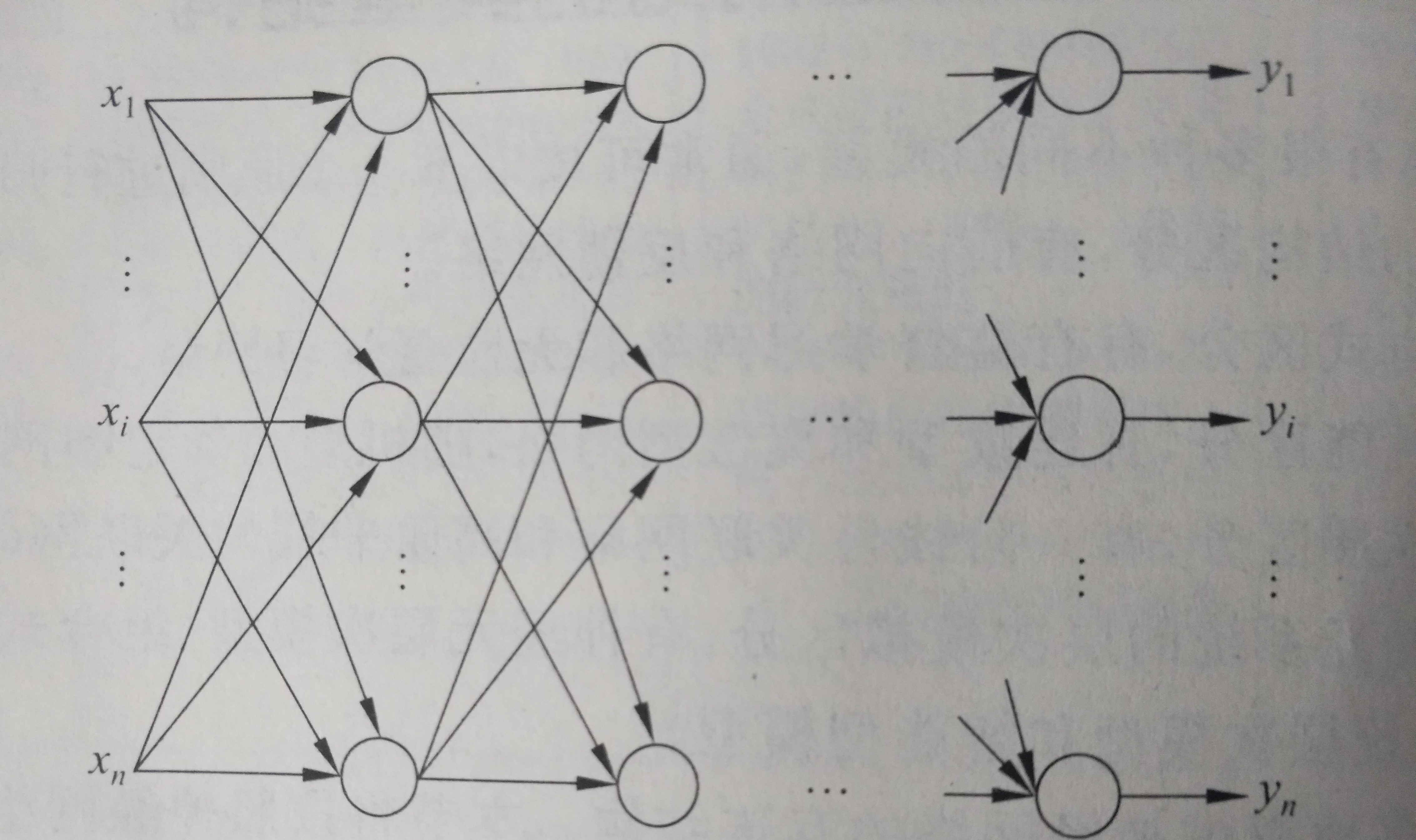
图:2
(2)算法过程
BP神经网络算法训练阶段的流程图和伪代码如下图所示:

图:3
步骤一、初始化网络权重
步骤二、向前传播输入(前馈型网络)
步骤三、反向误差传播
步骤四 、网络权重与神经元偏置调整
步骤五、判断结束
(3)BP神经网络 代码实现
% BP网络
net=newff([- ; ],[,],{'tansig','purelin'},'traingd')
net.IW{}
net.b{} p=[;];
a=sim(net,p)
net=init(net);
net.IW{}
net.b{}
a=sim(net,p)
%net.IW{}*p+net.b{}
p2=net.IW{}*p+net.b{}
a2=sign(p2)
a3=tansig(a2)
a4=purelin(a3)
net.b{}
net.b{} net.IW{}
net.IW{}
0.7616+net.b{}
a-net.b{}
(a-net.b{})/ 0.7616
help purelin p1=[;];
a5=sim(net,p1)
net.b{}
net=newff([- ; ],[,],{'tansig','purelin'},'traingd')
net.IW{}
net.b{}
%p=[;];
p=[;];
a=sim(net,p)
net=init(net);
net.IW{}
net.b{}
a=sim(net,p)
net.IW{}*p+net.b{}
p2=net.IW{}*p+net.b{}
a2=sign(p2)
a3=tansig(a2)
a4=purelin(a3)
net.b{}
net.b{} P=[1.2;;0.5;1.6]
W=[0.3 0.6 0.1 0.8]
net1=newp([ ; ; ; ],,'purelin');
net2=newp([ ; ; ; ],,'logsig');
net3=newp([ ; ; ; ],,'tansig');
net4=newp([ ; ; ; ],,'hardlim'); net1.IW{}
net2.IW{}
net3.IW{}
net4.IW{}
net1.b{}
net2.b{}
net3.b{}
net4.b{}
net1.IW{}=W;
net2.IW{}=W;
net3.IW{}=W;
net4.IW{}=W;
a1=sim(net1,P)
a2=sim(net2,P)
a3=sim(net3,P)
a4=sim(net4,P)
init(net1);
net1.b{}
help tansig
p=[-0.1 0.5]
t=[-0.3 0.4]
w_range=-:0.4:;
b_range=-:0.4:; ES=errsurf(p,t,w_range,b_range,'logsig');
pause(0.5);
hold off;
net=newp([-,],,'logsig');
net.trainparam.epochs=;
net.trainparam.goal=0.001;
figure();
[net,tr]=train(net,p,t);
title('动态逼近')
wight=net.iw{}
bias=net.b
pause;
close;
p=[-0.2 0.2 0.3 0.4]
t=[-0.9 -0.2 1.2 2.0]
h1=figure();
net=newff([-,],[,],{'tansig','purelin'},'trainlm');
net.trainparam.epochs=;
net.trainparam.goal=0.0001;
net=train(net,p,t);
a1=sim(net,p)
pause;
h2=figure();
plot(p,t,'*');
title('样本')
title('样本');
xlabel('Input');
ylabel('Output');
pause;
hold on;
ptest1=[0.2 0.1]
ptest2=[0.2 0.1 0.9]
a1=sim(net,ptest1);
a2=sim(net,ptest2); net.iw{}
net.iw{}
net.b{}
net.b{}
matlab运行结果:
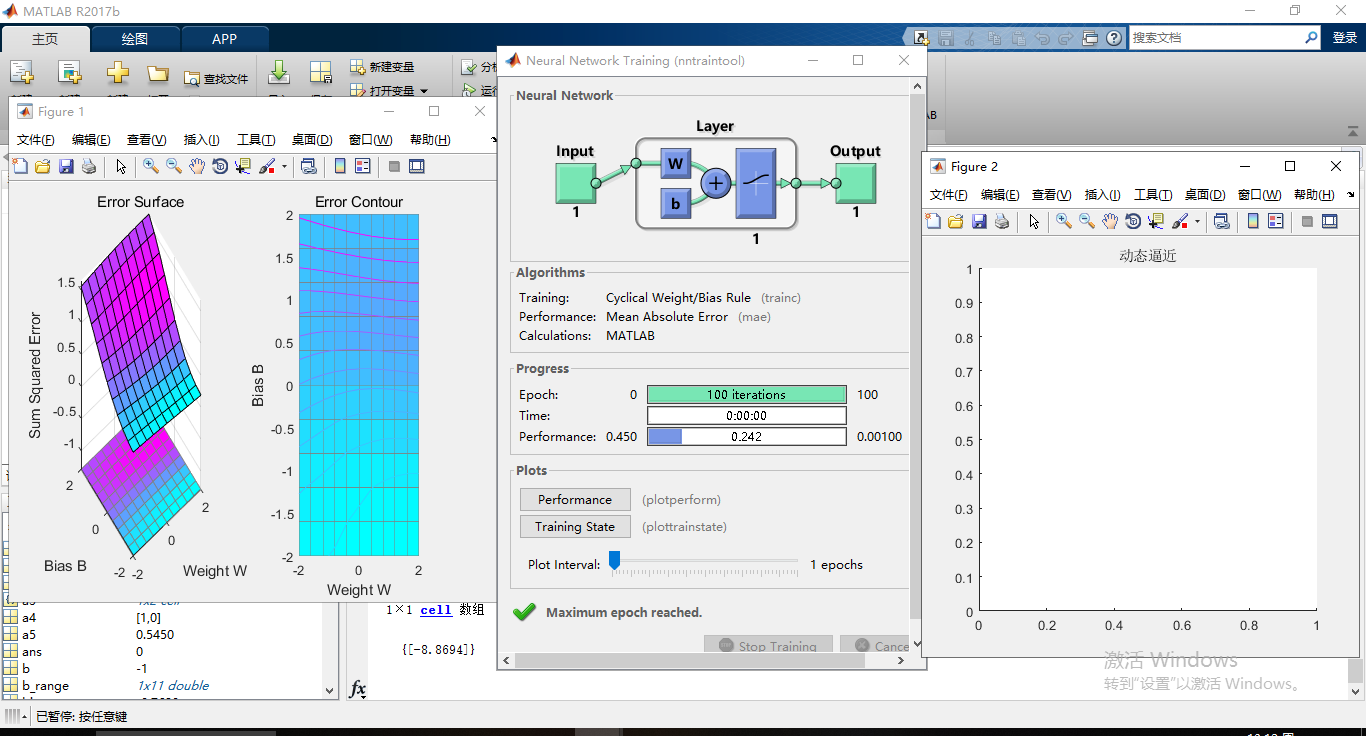
图:4
感知机算法及BP神经网络的更多相关文章
- bp神经网络及matlab实现
本文主要内容包含: (1) 介绍神经网络基本原理,(2) AForge.NET实现前向神经网络的方法,(3) Matlab实现前向神经网络的方法 . 第0节.引例 本文以Fisher的Iris数据集 ...
- 神经网络中的BP神经网络和贝叶斯
1 贝叶斯网络在地学中的应用 1 1.1基本原理及发展过程 1 1.2 具体的研究与应用 4 2 BP神经网络在地学中的应用 6 2.1BP神经网络简介 6 2.2基本原理 7 2.3 在地学中的具体 ...
- BP神经网络与Python实现
人工神经网络是一种经典的机器学习模型,随着深度学习的发展神经网络模型日益完善. 联想大家熟悉的回归问题, 神经网络模型实际上是根据训练样本创造出一个多维输入多维输出的函数, 并使用该函数进行预测, 网 ...
- Python语言编写BP神经网络
Python语言编写BP神经网络 2016年10月31日 16:42:44 ldy944758217 阅读数 3135 人工神经网络是一种经典的机器学习模型,随着深度学习的发展神经网络模型日益完善 ...
- 粒子群优化算法对BP神经网络优化 Matlab实现
1.粒子群优化算法 粒子群算法(particle swarm optimization,PSO)由Kennedy和Eberhart在1995年提出,该算法模拟鸟集群飞行觅食的行为,鸟之间通过集体的协作 ...
- 神经网络和误差逆传播算法(BP)
本人弱学校的CS 渣硕一枚,在找工作的时候,发现好多公司都对深度学习有要求,尤其是CNN和RNN,好吧,啥也不说了,拿过来好好看看.以前看习西瓜书的时候神经网络这块就是一个看的很模糊的块,包括台大的视 ...
- 感知机和BP神经网络
一.感知机 1.感知机的概念 感知机是用于二分类的线性分类模型,其输入是实例的特征向量,输出是实例的类别,类别取+1和-1二个值,+1代表正类,-1代表负类.感知机对应于输入空间(特征空间)中将实例分 ...
- JAVA实现BP神经网络算法
工作中需要预测一个过程的时间,就想到了使用BP神经网络来进行预测. 简介 BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法 ...
- 数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了.神经网络有很多种:前向传输网络.反向传输网络.递归神经网络.卷积神经网络等.本文介绍基本的反向传输神经网络(Backpropaga ...
随机推荐
- was控制台无法停止应用
问题描述: was控制台无法停止应用,只能通过停止server的方式停止: 代码实现: import org.slf4j.Logger; import org.slf4j.LoggerFactory; ...
- EventBus使用教程
如图准备工作: 父子(子父)组件触发 EventBus.$emit('sub') EventBus.$on('sub',()=>{ console.log(1111222232211122) } ...
- Rocketmq 集群部署
10.1.0.178 配置文件 broker-a-m.properties brokerClusterName=PaymentClusterbrokerName=broker-anamesrvAddr ...
- [Mac][Python][Jupyter Notebook]安装配置和使用
Jupyter 项目(以前称为 IPython 项目),提供了一套使用功能强大的交互式 shell 进行科学计算的工具,实现了将代码执行与创建实时计算文档相结合. 这些 Notebook 文件可以包含 ...
- [Python] Codecombat 攻略 Sarven 沙漠 (1-43关)截止至36关
首页:https://cn.codecombat.com/play语言:Python 第二界面:Sarven沙漠(43关)时间:4-11小时内容:算术运算,计数器,while循环,break(跳出循环 ...
- CSRF(cross-site request forgery )跨站请求攻击
CSRF(cross-site request forgery )跨站请求伪造,攻击者盗用了你的身份,以你的名义发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,通过 ...
- FormCollection使用
FormCollection用来在controller中获取页面表单元素的数据.它是表单元素的集合,包括<input type="submit" />元素. 用法举例: ...
- Struts2入门2
五.Struts2的工作原理及文件结构 Struts2过滤与自己相关的请求,比如.action后缀的请求,Struts2会进行过滤和处理,但如果是.html或者.jsp,Struts2不会对其进行处理 ...
- js中当call或者apply传入的第一个参数是null/undefined时,js函数内执行的上下文环境是什么?
在js中我们都知道call/apply,还有比较少用的bind;传入的第一个参数都是改变函数当前上下文对象; call/apply区别在于传的参数不同,一个是已逗号分隔字符串,一个以数组形式.而bin ...
- C# Stopwatch 使用
static IEnumerable<int> SampleData() { ; var r = new Random(); , arraySize).Select(x => r.N ...