python网络编程-socket套接字通信循环-粘包问题-struct模块-02
前置知识
不同计算机程序之间数据的传输
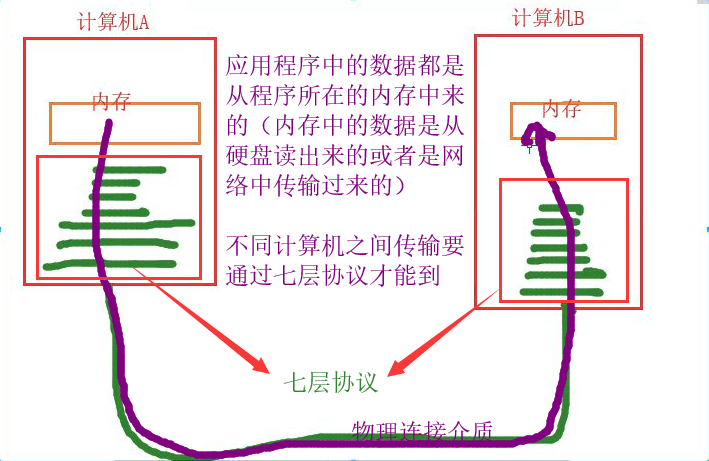
应用程序中的数据都是从程序所在计算机内存中读取的。
内存中的数据是从硬盘读取或者网络传输过来的
不同计算机程序数据传输需要经过七层协议物理连接介质才能到达目标程序
socket (套接字)
json.dump/dumps 只是把数据类型序列化成字符串
要想用来文件传输,还需要encode 给它编码成二进制数据才能传输
不用pickle是因为要和其他语言交互(你给页面就是js来处理,能不能支持是问题),而pickle只能是在python中用
程序员不需要七层一层一层地去操作硬件写网络传输程序,直接使用python解释器提供的socket 模块即可
大多数注意点都在代码后面的注释里,要仔细看哦~

初略版的双端(C/S)通信
程序运行时先启动服务端再启动客户端(代码设置一下可以一份代码跑好几个(客户端可能会启好几个))
server服务端
socket.scoket()不传参数默认就是TCP协议
import socket
server = socket.socket() # 有一个参数 type=SOCK_STREAM,即不传参数,默认就是TCP协议
# socket.socket() # socket模块中有个socket类,加() 实例化成一个对象(ctrl + 单击 可以看到)
# 不要形成固有思想, 模块.名字() 就以为是模块里的方法,点进去,可能还是类(看他这个类的名字还是全小写的...)
server.bind(('127.0.0.1', 8080)) # 127.0.0.1 本机回环地址只能本机访问,其他计算机访问不了(识别到了就不用走七层协议这些了)
# address: Union[tuple, str, bytes]) ---> address 参数是一个元组,绑定ip 和 端口
server.listen(5) # 半连接池
print("waitting....")
# waitting....
conn, addr = server.accept() # 阻塞,等待客户端连接,没有收到信息会停在这里
print("hi") # 在连通之前并没有反应
# hi
# --------------------------------------
# send 与 recv 要对应
# 不要两边都 recv,不然就都等着接收了
# --------------------------------------
data = conn.recv(1024) # 阻塞,等待客户端发送数据,接收1024个字节的数据
print(data)
# b'halo baby'
conn.send(b'ok') # 发送数据(必须是二进制数据)
conn.close() # 关闭连接
server.close() # 关闭服务
client客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080)) # 去连接服务器上的程序(服务器的IP + port)
client.send(b'halo baby')
data = client.recv(1024)
print(data)
client.close()
点进去发现socket这个类有实现 __enter_ 、 __exit__方法,__exit__方法中有关闭连接的方法,故可以用with上下文来操作(暂不举例了,面向对象这两个函数的知识点提一嘴)
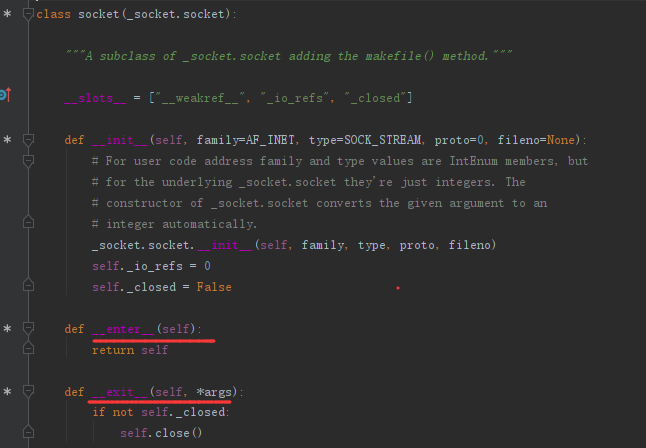
在重启服务器的时候可能会遇到的BUG(mac居多)

解决方法
# 加入一条socket配置,重用ip和端口
import socket
from socket import SOL_SOCKET, SO_REUSEADDR
server = socket.socket()
# -------------------------------------
# 加上他就可以防止重启报错了(注意位置)
# -------------------------------------
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080)) # 把地址绑定到套接字
server.listen(5) # 半连接池
conn, addr = server.accept() # 接受客户端链接
ret = conn.recv(1024) # 接收客户端信息
print(ret) # 打印客户端信息
conn.send(b'hi') # 向客户端发送信息
conn.close() # 关闭客户端套接字
server.close() # 关闭服务器套接字(可选)
服务端需要具备的条件
固定的ip和port
让客户端可以连接你(试想如果百度一天一个域名/ip?咋上百度))
要能24小时不间断提供服务
服务器不在线的话,客户端连啥?(双重循环 server.accpet() 来连接建立连接)
暂时不知道
半连接池,允许等待的最大个数
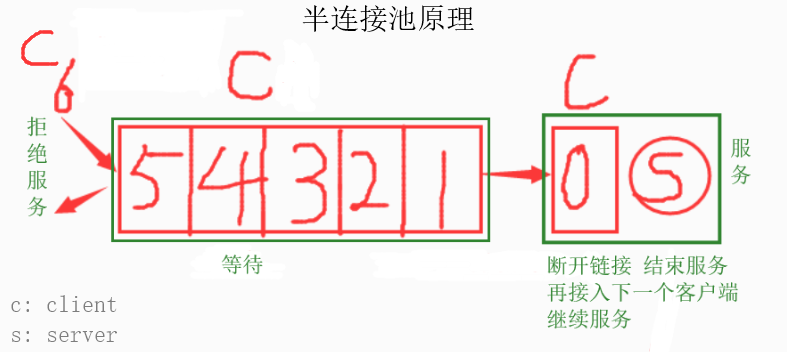
server.listen(5)指定5个等待席位
通信循环
双方都处于收的等待状态
直接回车没有发出数据,自身代码往下走进入了等待接收状态, 而另一端也没有收到消息,依然处于等待接收状态图,双方就都处于等待接收的状态了

linux、mac断开链接时不会报错,会一直返回空(b‘’)
穷,买不起mac...没图
解决方案
服务端
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080)) # 本地回环地址
server.listen(5)
conn, addr = server.accept() # 阻塞
for i in range(1, 5):
try:
data = conn.recv(1024) # 阻塞
print(data.decode('utf-8'))
msg = f"收到 {i} ga ga ga~"
# 发的时候要判断非空,空的自己send出去处于接收状态,对方依旧是接收状态,那就都等待了
conn.send(msg.encode('utf-8')) # ***** send 直接传回车会导致两遍都处于接收状态
except ConnectionResetError: # ***** 当服务端被强制关闭时汇报异常,这里捕获并做处理
# mac或者linux 会一直输空,不会自动结束
break
conn.close()
server.close()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
hi = input(">>>:").strip()
for i in range(1, 5):
msg = f'-{i} hi 咯~'
client.send(msg.encode('utf-8'))
data = client.recv(1024)
if len(data) == 0: # ***** mac或者linux 需要加,避免客户端突然断开,他不会报错,会一直打印空
break
print(f"收到 {i} {data.decode('utf-8')}")
client.close()
实现服务端可以接收多个客户端通讯(一个结束还可以接收下一个) --- 利用好server.listen(5) 半连接池以及conn, addr = server.accept()把接收的代码用循环包起来
粘包问题
多次发送被并为一次
根据最上面的前置知识可以知道,数据是从内存中读取过来的
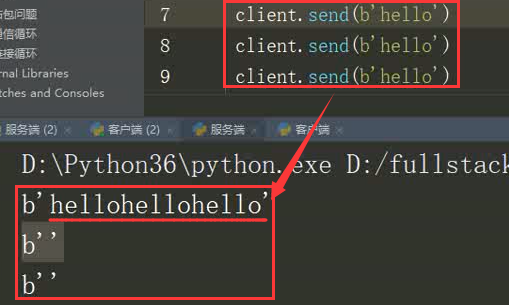
产生问题的原因
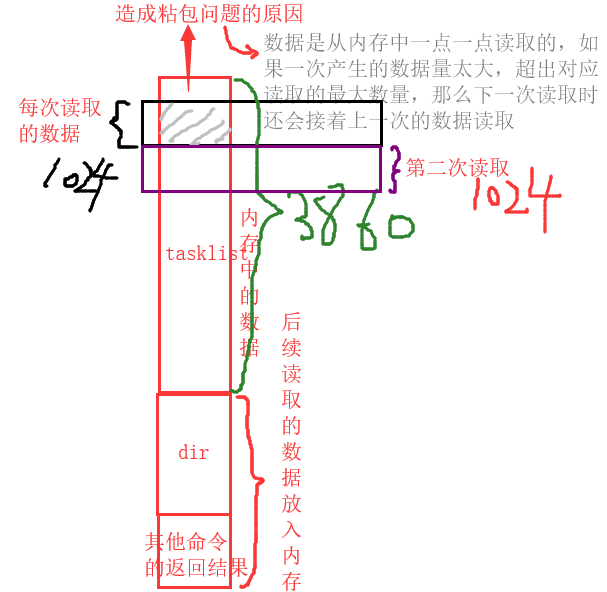
黏包现象只发生在tcp协议中
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
粘包是接收长度没对上导致的
控制recv接收的字节数与之对应(你发多少字节我收多少字节)
在很多情况下并不知道数据的长度,服务端不能写死
思路一如果在不知道数据有多长的情况下就会出现意外,那么我们可以先传一个固定长度的数据过去告诉他真实数据有多长,就可以对应着收了
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
这里利用struct模块模块的struct.pack() struct.unpack() 方法来实现打包(将真实数据长度变为固定长度的数字)解包(将该数字解压出打包前真实数据的长度)
pack unpack模式参数对照表(standard size 转换后的长度)
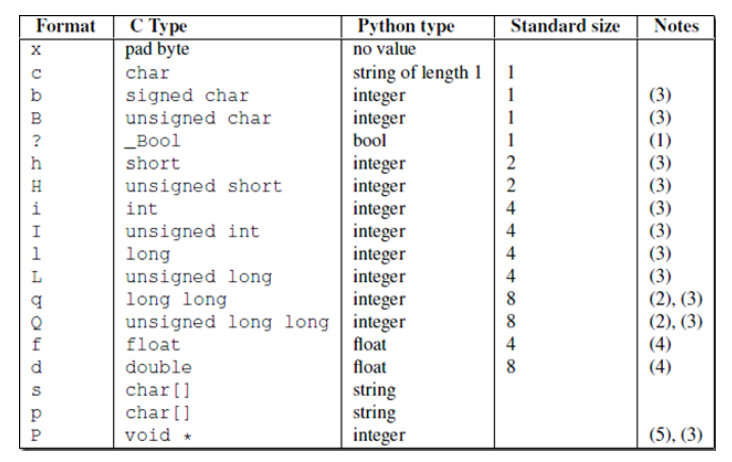
i 模式的范围:-2147483648 <= number <= 2147483647
在传真实数据之前还想要传一些描述性信息
如果在传输数据之前还想要传一些描述性信息,那么就得在中间再加一步了(传个电影,我告诉你电影名,大小,大致情节,演员等信息,你再选择要不要),前面的方法就不适用了
粘包问题解决思路
服务器端
- 先制作一个发送给客户端的字典
- 制作字典的报头
- 发送字典的报头
- 发送字典
- 再发真实数据
客户端
- 先接收字典的报头
- 解析拿到字典的数据长度
- 接收字典
- 从字典中获取真实数据的长度
- 循环获取真实数据
ps:为什么要多加一个字典
- pack打包的数据长度(的长度)有限,字典再打包会很小(长度值也会变很小)(120左右)
- 可以携带更多的描述信息
粘包问题解决最终版模板
服务器端
import socket
import subprocess
import struct
import json
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
cmd = conn.recv(1024)
if len(cmd) == 0:break
cmd = cmd.decode('utf-8')
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
res = obj.stdout.read() + obj.stderr.read()
d = {'name':'jason','file_size':len(res),'info':'asdhjkshasdad'}
json_d = json.dumps(d)
# 1.先制作一个字典的报头
header = struct.pack('i',len(json_d))
# 2.发送字典报头
conn.send(header)
# 3.发送字典
conn.send(json_d.encode('utf-8'))
# 4.再发真实数据
conn.send(res)
# conn.send(obj.stdout.read())
# conn.send(obj.stderr.read())
except ConnectionResetError:
break
conn.close()
客户端
import socket
import struct
import json
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
msg = input('>>>:').encode('utf-8')
if len(msg) == 0:continue
client.send(msg)
# 1.先接受字典报头
header_dict = client.recv(4)
# 2.解析报头 获取字典的长度
dict_size = struct.unpack('i',header_dict)[0] # 解包的时候一定要加上索引0
# 3.接收字典数据
dict_bytes = client.recv(dict_size)
dict_json = json.loads(dict_bytes.decode('utf-8'))
# 4.从字典中获取信息
print(dict_json)
recv_size = 0
real_data = b''
while recv_size < dict_json.get('file_size'): # real_size = 102400
data = client.recv(1024)
real_data += data
recv_size += len(data)
print(real_data.decode('gbk'))
案例-客户端向服务端传输文件
需求
# 写一个上传电影功能
1.循环打印某一个文件夹下面的所有文件
2.用户选取想要上传的文件
3.将用户选择的文件上传到服务端
4.服务端保存该文件
服务端(没有处理断开连接的报错以及空输入的报错,linux、mac的兼容)
import os
import sys
import socket
import struct
import json
server = socket.socket()
server.bind(('192.168.13.34', 8080))
server.listen(5)
conn, addr = server.accept()
'''
服务器端将文件都放在同一个目录
'''
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
dir_path = os.path.join(BASE_DIR, 'datas', 're_movies')
if not os.path.exists(dir_path):
os.makedirs(dir_path)
import time
from functools import wraps
# 统计运行时间装饰器
def count_time(func):
@wraps(func)
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
print(f"耗时{end_time - start_time}s")
return res
return inner
@count_time
def save_file(file_path, file_size):
with open(file_path, 'ab') as f:
# 一行一行地收文件,同时写入文件
recv_size = 0
while recv_size < file_size:
data = conn.recv(1024)
# 存文件
# json.dump(data.decode('utf-8'), f) # -------------可能报错,不传文件对象
f.write(data)
f.flush()
recv_size += len(data)
msg = f'已收到{file_name},{file_size/1024/1024}MB,over~'
print('\033[33m', msg, '\033[0m')
conn.send(msg.encode('utf-8'))
while True:
print("等待接收客户端的信息......")
# 1.接收报头大小
dict_header_recv = conn.recv(4)
# 2.接收字典
dict_header_size = struct.unpack('i', dict_header_recv)[0]
recv_dict_str = conn.recv(dict_header_size).decode('utf-8')
recv_dict = json.loads(recv_dict_str)
print(recv_dict)
# 3.获取字典中的数据长度以及文件名
file_name = recv_dict.get('file_name')
file_size = recv_dict.get('file_size')
# 4.循环获取真实数据,并存起来
file_path = os.path.join(dir_path, file_name)
# with open(file_path, 'ab') as f:
# # 一行一行地收文件,同时写入文件
# recv_size = 0
# while recv_size < file_size:
# data = conn.recv(1024)
# # 存文件
# # json.dump(data.decode('utf-8'), f) # -------------可能报错,不传文件对象
# f.write(data)
# f.flush()
# recv_size += len(data)
#
# msg = f'已收到{file_name},{file_size/1024/1024}MB,over~'
# print('\033[33m', msg, '\033[0m')
# conn.send(msg.encode('utf-8'))
save_file(file_path, file_size)
# conn.close()
# server.close()
客户端
import json
import os
import struct
import socket
# 连接服务端
client = socket.socket()
client.connect(('192.168.13.34', 8080))
while True:
'''后续想做成可以更换目录的,所以放到这里面了'''
# 操作目标文件夹
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
dir_path = os.path.join(BASE_DIR, 'movies')
# dir_path = r'一个绝对路径'
file_name_list = os.listdir(dir_path)
# 让用户选择
print("您的文件夹下现有如下文件:")
for index, file_name in enumerate(file_name_list, 1):
# 可以在前面给文件名做一个分割,把后缀名去掉
print(f"\t{index}. {file_name}")
choice = input("请选择您想要上传电影的编号>>>:").strip()
if choice in ['q', 'exit']:
print("感谢您的使用~")
break
elif choice.isdigit() and int(choice) - 1 in range(len(file_name_list)):
# 正确选好文件
file_name = file_name_list[int(choice) - 1]
file_path = os.path.join(dir_path, file_name)
else:
print("请输入正确的编号!")
continue
# 准备开始上传文件
file_size = os.path.getsize(file_path)
# 1.制作报头字典
file_dict = {
'file_name': file_name,
'file_size': file_size
}
# 2.打包报头字典
file_dict_str = json.dumps(file_dict)
file_dict_header_size = struct.pack('i', len(file_dict_str))
# 3.发送报头大小
client.send(file_dict_header_size)
# 4.发送报头字典
# file_dict_str = json.dumps(file_dict)
client.send(file_dict_str.encode('utf-8'))
# 5.一行一行地把文件发过去
with open(file_path, 'rb') as f:
# 一行一行地传过去,避免大文件(一行还是不顶用,压缩过的数据基本都在一行)
# 转为每次发 1024 Bytes 数据
_file_size = file_size
while _file_size > 0:
if file_size > 1024:
data = f.read(1024)
_file_size -= 1024
else:
data = f.read(_file_size)
_file_size -= _file_size
client.send(data)
print(f"发送了 {len(data)} Bytes 数据~~~")
print('\033[33m', f"文件{file_name},{file_size/1024/1024}MB已发送完毕~", '\033[0m')
msg = client.recv(1024)
if msg:
print(f"服务器端回复:", msg.decode('utf-8'))
client.close()
小提示:
上面的连接地址
('192.168.13.34', 8080)可以换成你小伙伴的地址哦~客户端和服务端的要记得一致
在命令行中(windows + r , 输入 cmd 回车)输入ipconfig可以查看本机的ip地址

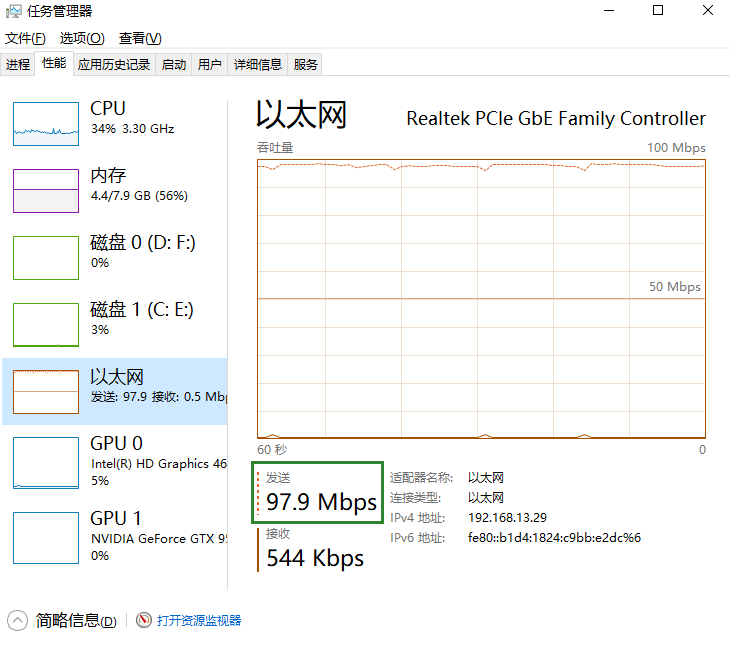
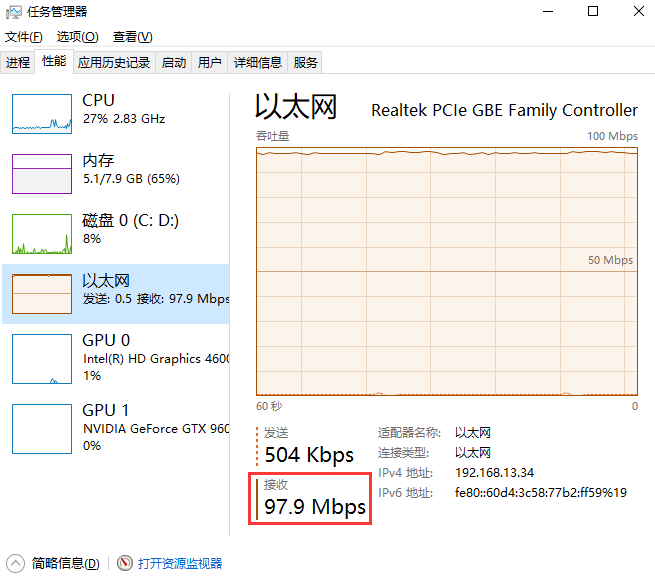
服务器端运行截图(本地局域网速度主要受限于硬盘读写速度)

客户端资源占用截图

服务器端资源占用截图
另一份案例参考
服务端
import socket
import json
import struct
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
header_len = conn.recv(4)
# 解析字典报头
header_len = struct.unpack('i', header_len)[0]
# 再接收字典数据
header_dic = conn.recv(header_len)
real_dic = json.loads(header_dic.decode('utf-8'))
# 获取数据长度
total_size = real_dic.get('file_size')
# 循环接收并写入文件
recv_size = 0
with open(real_dic.get('file_name'), 'wb') as f:
while recv_size < total_size:
data = conn.recv(1024)
f.write(data)
recv_size += len(data)
print('上传成功')
except ConnectionResetError as e:
print(e)
break
conn.close()
# server.close()
客户端
import socket
import json
import os
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8080))
while True:
# 获取电影列表 循环展示
MOVIE_DIR = r'D:\python视频\day25\视频'
movie_list = os.listdir(MOVIE_DIR)
# print(movie_list)
for i, movie in enumerate(movie_list, 1):
print(i, movie)
# 用户选择
choice = input('please choice movie to upload>>>:')
# 判断是否是数字
if choice.isdigit():
# 将字符串数字转为int
choice = int(choice) - 1
# 判断用户选择在不在列表范围内
if choice in range(0, len(movie_list)):
# 获取到用户想上传的文件路径
path = movie_list[choice]
# 拼接文件的绝对路径
file_path = os.path.join(MOVIE_DIR, path)
# 获取文件大小
file_size = os.path.getsize(file_path)
# 定义一个字典
res_d = {
'file_name': '性感荷官在线发牌.mp4',
'file_size': file_size,
'msg': '注意身体,多喝营养快线'
}
# 序列化字典
json_d = json.dumps(res_d)
json_bytes = json_d.encode('utf-8')
# 1.先制作字典格式的报头
header = struct.pack('i', len(json_bytes))
# 2.发送字典的报头
client.send(header)
# 3.再发字典
client.send(json_bytes)
# 4.再发文件数据(打开文件循环发送)
with open(file_path, 'rb') as f:
for line in f:
client.send(line)
else:
print('not in range')
else:
print('must be a number')
# client.close()
python网络编程-socket套接字通信循环-粘包问题-struct模块-02的更多相关文章
- 8.7 day28 网络编程 socket套接字 半连接池 通信循环 粘包问题 struct模块
前置知识:不同计算机程序之间的数据传输 应用程序中的数据都是从程序所在计算机内存中读取的. 内存中的数据是从硬盘读取或者网络传输过来的 不同计算机程序数据传输需要经过七层协议物理连接介质才能到达目标程 ...
- Python之路(第三十一篇) 网络编程:简单的tcp套接字通信、粘包现象
一.简单的tcp套接字通信 套接字通信的一般流程 服务端 server = socket() #创建服务器套接字 server.bind() #把地址绑定到套接字,网络地址加端口 server.lis ...
- 19 网络编程--Socket 套接字方法
1.Socket(也称套接字)介绍 socket这个东东干的事情,就是帮你把tcp/ip协议层的各种数据封装啦.数据发送.接收等通过代码已经给你封装好了 ,你只需要调用几行代码,就可以给别的机器发消息 ...
- 网络编程--Socket(套接字)
网络编程 网络编程的目的就是指直接或间接地通过网络协议与其他计算机进行通讯.网络编程中 有两个主要的问题,一个是如何准确的定位网络上一台或多台主机,另一个就是找到主机后 如何可靠高效的进行数据传输.在 ...
- Python网络编程——处理套接字错误
在网络应用中,经常会遇到这种情况:一方尝试连接,但另一方由于网络媒介失效或者其他原因无法响应. Python的Socket库提供了一个方法,能通过socket.error异常优雅地处理套接字错误. 1 ...
- 19、网络编程 (Socket套接字编程)
网络模型 *A:网络模型 TCP/IP协议中的四层分别是应用层.传输层.网络层和链路层,每层分别负责不同的通信功能,接下来针对这四层进行详细地讲解. 链路层:链路层是用于定义物理传输通道,通常是对某些 ...
- Python网络编程——修改套接字发送和接收的缓冲区大小
很多情况下,默认的套接字缓冲区大小可能不够用.此时,可以将默认的套接字缓冲区大小改成一个更合适的值. 1. 代码 # ! /usr/bin/env python # -*- coding: utf-8 ...
- 网络编程 TCP协议:三次握手,四次回收,反馈机制 socket套接字通信 粘包问题与解决方法
TCP协议:传输协议,基于端口工作 三次握手,四次挥手 TCP协议建立双向通道. 三次握手, 建连接: 1:客户端向服务端发送建立连接的请求 2:服务端返回收到请求的信息给客户端,并且发送往客户端建立 ...
- TCP/IP网络编程之套接字类型与协议设置
套接字与协议 如果相隔很远的两人要进行通话,必须先决定对话方式.如果一方使用电话,另一方也必须使用电话,而不是书信.可以说,电话就是两人对话的协议.协议是对话中使用的通信规则,扩展到计算机领域可整理为 ...
随机推荐
- spiderkeeper使用教程
安装包 pip install scrapy pip install scrapyd pip install scrapyd-client pip install spiderkeeper 进入到sc ...
- @Transient的应用
我今天分配的任务是为一个页面Debug,遇到了一个问题查询的实体类在数据库没有对应的表,这时最常用的是建立视图或者表,但是应用@Transient注释可以让你更简单,免除建立表还有视图需要找多表关联关 ...
- DP&图论 DAY 5 下午
DP&图论 DAY 5 下午 树链剖分 每一条边要么属于重链要么轻边 证明: https://www.cnblogs.com/sagitta/p/5660749.html 轻边重链都是交 ...
- js设计模式-代理模式
1.什么是设计模式? 设计模式:在软件设计过程中常用的代码规范,针对特定的场景 2.应用场景: 麦当劳点餐 观察者模式 规定的代码格式 花店送花 :代理模式 真实对象(男同学)-----代理对 ...
- 码云上webide怎么提交
修改后想提交,它会提示:“暂存文件后才能提交”, 我拿放大镜找遍了整个界面也没找到“暂存”按钮, 原来,文件旁边那个+号就是暂存,好歹鼠标方式去之后给个tip,服了. 点一下这个加号,提交按钮就可用了 ...
- AMBARI部署HADOOP集群(3)
1. 安装ambari-server yum -y install ambari-server 2. ambari server 需要一个数据库存储元数据,默认使用的 Postgres 数据库.默认的 ...
- js的window.onscroll事件兼容各大浏览器
为窗口添加滚动条事件其实非常的简单, window.onscroll=function(){}; 注意在获取滚动条距离的时候 谷歌不识别document.documentElement.scrollT ...
- shell案例(6):1、创建用户 2、创建目录 3、创建文件 4、退出
脚本基本要求 1.创建用户2.创建目录3.创建文件4.退出 #!/bin/bash #author:zhiping.wang Check_error() { ] then echo "$1 ...
- wpf prism IRegionManager 和IRegionViewRegistry
引入了一个新的问题,IRegionViewRegistry和IRegionManager都具有RegisterViewWithRegion方法,二者有区别么? 答案是——没有.我们已经分析过,在Uni ...
- layui 数据表格复选框实现单选功能
//点击选中(单选)//单击行勾选checkbox事件 $(document).on("click",".layui-table-body table.layui-tab ...