selenium自动化测试工具模拟登陆爬取当当网top500畅销书单
selenium自动化测试工具可谓是爬虫的利器,基本动态加载的网页都能抓取,当然随着大型网站的更新,也出现针对selenium的反爬,有些网站可以识别你是否用的是selenium访问,然后对你加以限制.
当当网目前还没有对这方面加以限制,所以今天就用这个练习熟悉一下selenium操作,我们可以试一下爬取一下当当网top500的畅销书单的相关信息,页面如下:
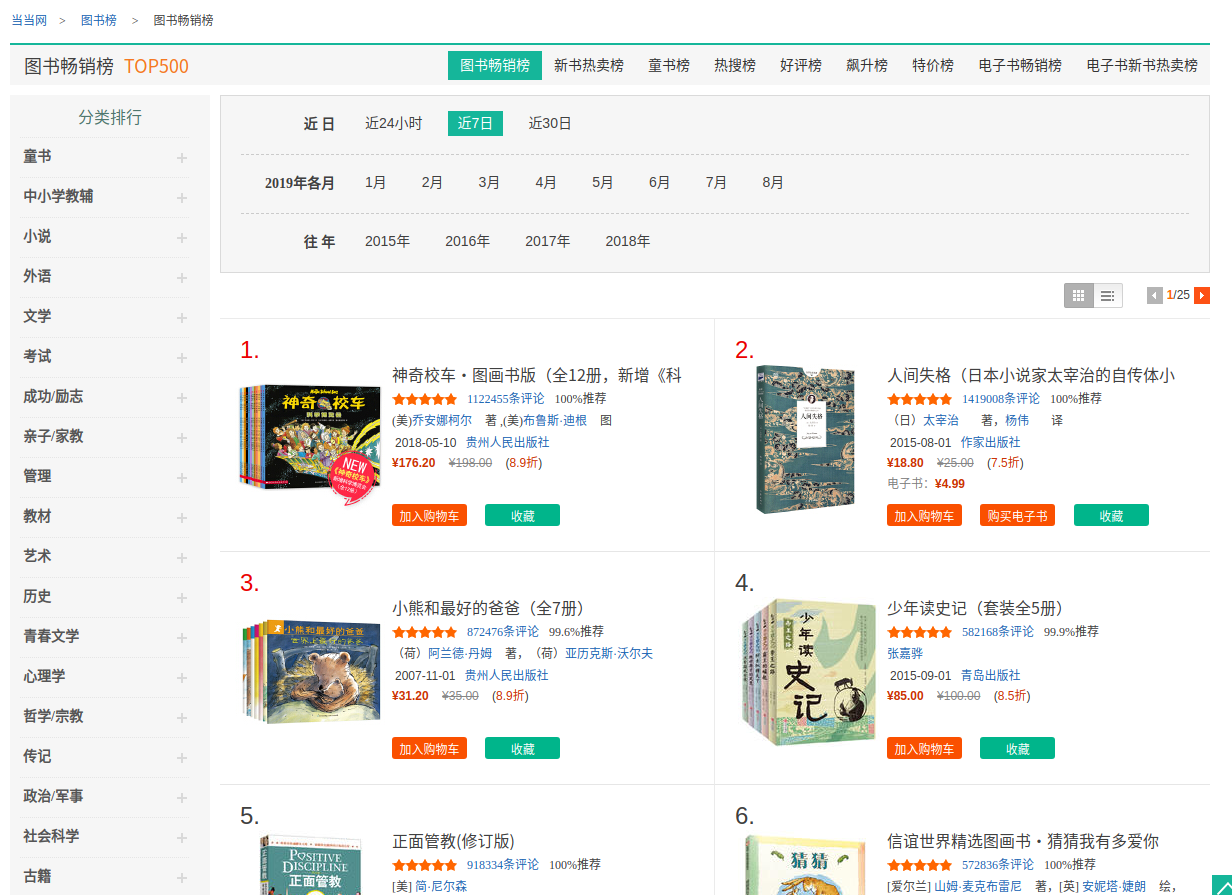
虽然这个页面不用登录就可以进来,但是我们可以随便试一下模拟登陆,直接在这个页面上面点击登录进入登录界面,然后会弹出一下窗口,
这是百分百会出现的,所以要先模拟点击把它点掉,然后才能传账号和密码进行登录
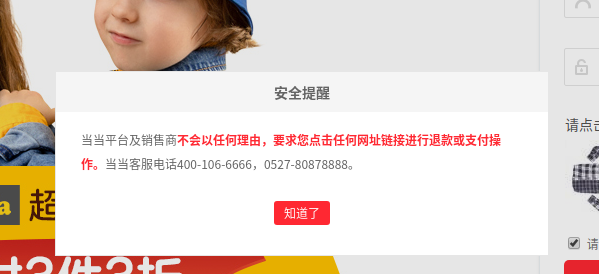
然后就是验证码的解决,说实话,现在当当这验证码基本很难实现用代码来破解,但是可以人工跳过,我在这里暂停了十秒,直接自己点击,然后等待程序运行,这样子就很容易就绕过了,反正只要过了验证这一关,下面的数据就不怕拿不到了.
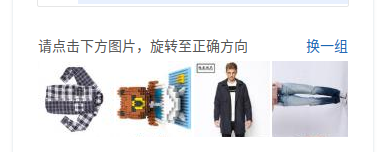
贴下代码:
from selenium import webdriver
import time
from lxml import etree
import csv browser = webdriver.Chrome()
browser.get("http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1")
# browser.get_cookies()
time.sleep(1)
button_login1 = browser.find_element_by_xpath("//span[@id='nickname']/a[@class='login_link']")
button_login1.click()
close_button = browser.find_element_by_id("J_loginMaskClose")
close_button.click()
input_phone_number = browser.find_element_by_id("txtUsername")
input_phone_number.send_keys('自己账号')
time.sleep(0.2)
input_password = browser.find_element_by_id("txtPassword")
input_password.send_keys('自己密码')
time.sleep(10)
button_login2 = browser.find_element_by_id("submitLoginBtn")
button_login2.click()
# button_book = browser.find_element_by_name("nav1")
# button_book.click()
# button_list = browser.find_element_by_xpath("//div[@class='book_top ']/a[@class='more_top']")
# button_list.click()
for i in range(25):
time.sleep(5)
text = browser.page_source
# print(text)
html = etree.HTML(text)
book_name = html.xpath("//div[@class='name']/a/text()")
price = html.xpath("//span[@class='price_n']/text()")
original_price = html.xpath("//span[@class='price_r']/text()")
publisher = html.xpath("//div[@class='publisher_info'][2]/a/text()")
# auther = html.xpath("//div[@class='publisher_info'][1]/text()")
time1 = html.xpath("//div[@class='publisher_info'][2]/span/text()")
result = zip(book_name, publisher, price, original_price, time1)
with open('book.csv', 'a', newline='') as csvfile:
writer = csv.writer(csvfile, dialect='excel')
writer.writerows(result)
for i in result:
print(i)
next_button = browser.find_element_by_xpath(
"//div[@class='bang_list_box']/div[@class='paginating']/ul[@class='paging']/li[@class='next']/a")
next_button.click()
selenium自动化测试工具模拟登陆爬取当当网top500畅销书单的更多相关文章
- 使用Post方法模拟登陆爬取网页
最近弄爬虫,遇到的一个问题就是如何使用post方法模拟登陆爬取网页.下面是极简版的代码: import java.io.BufferedReader; import java.io.InputStre ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- 使用Post方法模拟登陆爬取网页(转)
使用Post方法模拟登陆爬取网页 最近弄爬虫,遇到的一个问题就是如何使用post方法模拟登陆爬取网页.下面是极简版的代码: import java.io.BufferedReader; impor ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- Python爬虫之selenium爬虫,模拟浏览器爬取天猫信息
由于工作需要,需要提取到天猫400个指定商品页面中指定的信息,于是有了这个爬虫.这是一个使用 selenium 爬取天猫商品信息的爬虫,虽然功能单一,但是也算是 selenium 爬虫的基本用法了. ...
随机推荐
- tp5 get传参为中文时,需要解码 urldecode
php 接收 $data = urldecode($data);
- VLC和Qt结合编写流媒体rtsp播放器
VLC播放器是一款功能强大且小巧的播放器,它支持多种多样的音视频格式,比如MPEG1,2以及mp3等等.并且通过Qt和VLC的结合能让每个开发者写出自己的视频流媒体播放器. Q ...
- Nginx配置文件详细说明 (转)
Nginx配置文件详细说明 原文链接:http://www.cnblogs.com/Joans/p/4386556.html 在此记录下Nginx服务器nginx.conf的配置文件说明, 部分注释收 ...
- Class 源码解读
Class 获取包信息 /** * 获取此对象所在的包 * @revised 9 * @spec JPMS */ public Package getPackage() { // 原始类型和数组无 P ...
- pyqt5 工具栏文字图片同时显示
import sys from PyQt5.QtWidgets import QMainWindow, QTextEdit, QAction, QApplication from PyQt5.QtGu ...
- 【转】Java从hdfs上读取文件中的某一行
[From]https://blog.csdn.net/u010989078/article/details/51790166 package test; import java.io.Buffere ...
- vs2017 开发.NetCore部署docker
一.环境 操作系统:windows 10 64bit 开发环境:vs2017 部署环境:docker — windows 二.准备 安装docker: 见:https://www.cnblogs.c ...
- StringRedisTemplate与RedisTemplate区别
StringRedisTemplate与RedisTemplate两者的关系是StringRedisTemplate继承RedisTemplate. 两者的数据是不共通的:也就是说StringRedi ...
- 【AMAD】Stream-Framework -- 让你可以使用Cassandra和Redis构建新闻feed,活动流(activity stream)以及通知系统。
动机 简介 个人评分 动机 你曾经是否想为你自己的网站构建Facebook,Github那种feed流. 简介 通过Stream-Framework1你可以做到: Github那种活动流 Twitte ...
- Linux C/C++基础——文件(上)
1.文件指针 FILE* fp=NULL; fp指针,只调用了fopen(),在堆区分配空间,把地址返回给fp fp指针不是指向文件,fp指针和文件关联,fp内部成员保存在文件的状态 操作fp指针,不 ...