NameNode 和 SecondaryNameNode
1. NN 和 2NN 工作机制
- NameNode 会产生在磁盘中备份元数据的FsImage;
- 每当元数据有更新或者添加数据时,修改内存中的元数据并追加到Edits中;
- SecondaryNameNode 专门用于合并 FsImage 和 Edits;
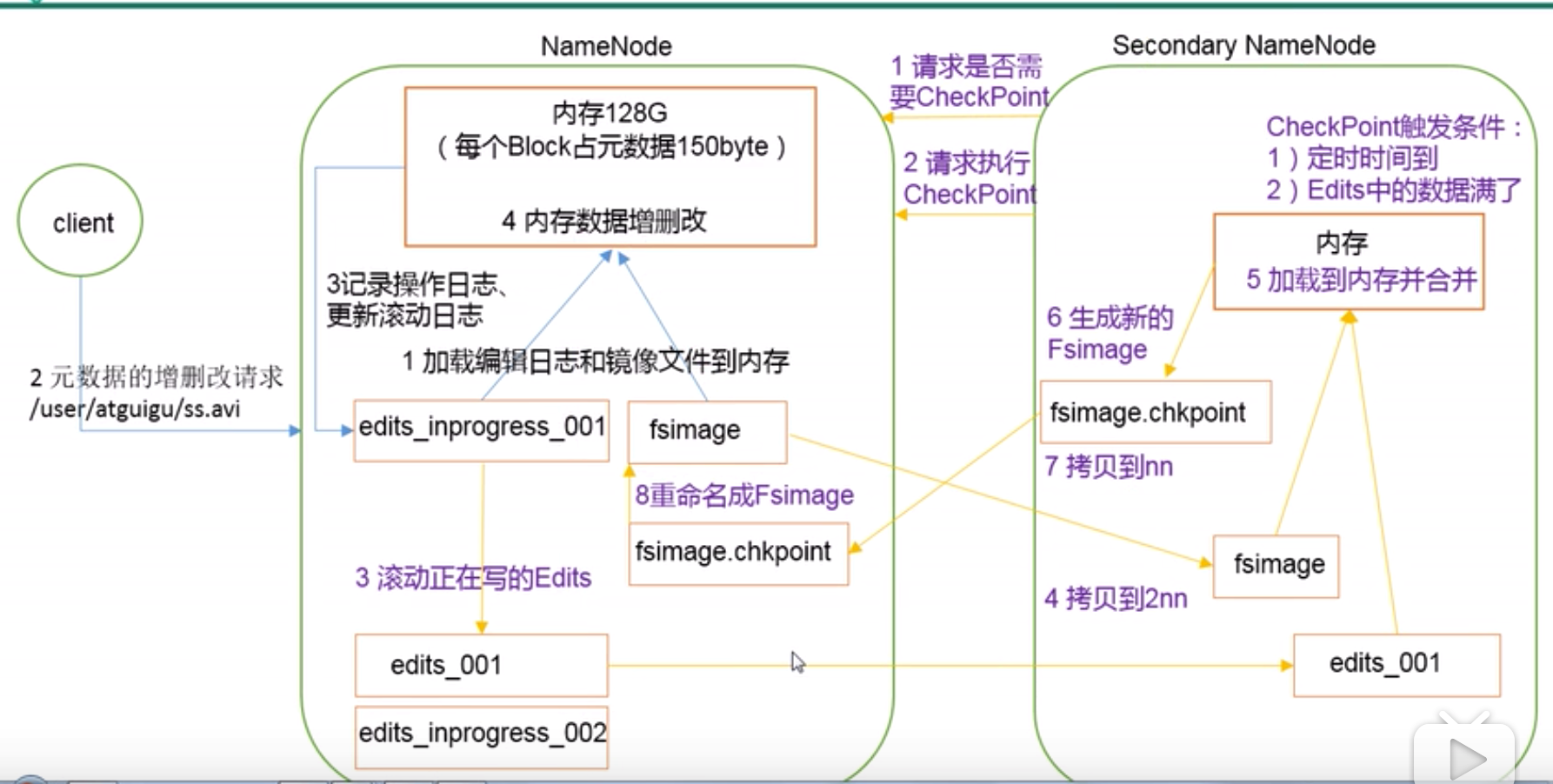
2. Fsimage 和 Edits 解析
- 查看Fsimage:
hdfs oiv -p XML -i fsimage_0000000000000000105 -o fsimage.xmlhdfs oiv -p 需要转换生成的文件类型 -i 镜像文件 -o 转换后文件输出路径
- 查看Edits:
hdfs oev -p XML -i edits_000000000000000104-000000000000000105 -o edits.xml
3. CheckPoint 时间设置
- 通常情况下, SecondaryNameNode 每隔一小时执行一次;
- 另一种情况:一分钟检查一次操作次数,当操作次数达到一百万时, SecondaryNameNode 执行一次;
// hdfs-default.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>一分钟检查一次操作次数</description>
</property>
4. NameNode 故障处理
- NameNode 发生故障后,可以采用两种方法恢复数据
- 将 SecondaryNameNode 中数据拷贝到 NameNode 存储数据的目录;
- 使用
-importCheckpoint选项启动 NameNode 守护进程, 从而将 SecondaryNameNode 中数据拷贝到 NameNode 目录中;- 如果 SecondaryNameNode 和 NameNode 不在一个主机节点上,需要将 SecondaryNameNode 存储数据的目录拷贝到 NameNode 存储数据的评级目录,并删除
in_user.lock文件; bin/hdfs namenode -importCheckpoint- 启动 NameNode:
sbin/hadoop-daemon.sh start namenode
- 如果 SecondaryNameNode 和 NameNode 不在一个主机节点上,需要将 SecondaryNameNode 存储数据的目录拷贝到 NameNode 存储数据的评级目录,并删除
// 第二种方式,需要修改 hdfs-site.xml 配置文件
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>NameNode中存放地址/tmp/dfs/name</value>
</property>
5. 集群的安全模式
5.1 NameNode 启动
- NameNode 启动时, 首先将镜像文件(Fsimage)载入内存,并执行编辑日志(Edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的 Fsimage 文件和一个空的编辑日志。此时,NameNode 开始监听 DataNode 请求。这个过程期间,NameNode 一直运行在安全模式,即 NameNode 的文件系统对于客户端来说是只读的。
5.2 DataNode 启动
- 系统中的数据块的位置并不是有 NameNode 维护的, 而是以块列表的形式存储在 DataNode 中。在系统的正常操作期间, NameNode 会在内存中保留所有块位置的映射信息。在安全模式下, 各个 DataNode 会向 NameNode 发送最新的块列表信息, NameNode 了解到足够多的块位置信息之后, 即可高效运行文件系统。
5.3 安全模式退出判断
- 如果满足"最小副本条件", NameNode 会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:
dfs.replication.min=1)。在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,所以 NameNode 不会进入安全模式。
5.4 安全模式基本语法
- 查看安全模式状态:
hdfs dfsadmin -safemode get - 进入安全模式状态:
hdfs dfsadmin -safemode enter - 离开安全模式状态:
hdfs dfsadmin -safemode leave - 等待安全模式离开:
hdfs dfsadmin -safemode wait
6. NameNode多目录
- NameNode 在本地目录可以配置成多个, 且每个目录存放内容相同,增加了可靠性;
// hdfs-site.xml 配置
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1, file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
参考资料:
NameNode 和 SecondaryNameNode的更多相关文章
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- NameNode和SecondaryNameNode(面试开发重点)
NameNode和SecondaryNameNode(面试开发重点) 1 NN和2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁 ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
- HDFS05 NameNode和SecondaryNameNode
NameNode和SecondaryNameNode(了解) 目录 NameNode和SecondaryNameNode(了解) NN 和 2NN 工作机制 NameNode工作机制 Secondar ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- 浅谈HDFS(二)之NameNode与SecondaryNameNode
NN与2NN工作机制 思考:NameNode中的元数据是存储在哪里的? 假设存储在NameNode节点的硬盘中,因为经常需要随机访问和响应客户请求,必然效率太低,所以是存储在内存中的 但是,如果存储在 ...
随机推荐
- 003_STM32程序移植之_W25Q64
1. 测试环境:STM32C8T6 2. 测试模块:W25Q64FLASH模块 3. 测试接口: 1. W25Q64FLASH模块接口: VCC3.3--------------------VCC3. ...
- java常用函数
if(null == list || list.size() ==0 ){ } list.isEmpty()和list.size()==0 没有区别 isEmpty()判断有没有元素而size()返回 ...
- svn 外部引用别的项目文件
建立了一个文件目录E:\My\myproject 想在该目录下有一个文件夹引用别的工程的文件. 1.在E:\My\myproject 空白处右键属性. 2.点击Properties,弹出 3.点击ne ...
- JIRA恢复备份后无法上传附件
1.在恢复JIRA 备份数据和附件后,上传附件失败,这一般是恢复附件时没有修改附件的拥有者和组 创建JIRA平台,会自动创建一个服务器的账户,如果是服务器第一次部署JIRA那么账户肯定是jira,如果 ...
- vfork与fork的区别
vfork()用法与fork()相似,但是也有区别,具体区别归结为以下3点: 1. fork():子进程拷贝父进程的数据段,代码段.vfork():子进程与父进程共享数据段. 2. fork():父子 ...
- MyEclipse环境的项目改为在Eclipse中运行爬坑记【我】
新检出一个web项目,同事都是运行在MyEclipse中的,我用Eclipse启动, 1.首先是许多jar包报错: 处理方法为 remove掉,然后 选 WEB-INF 下的所有 jar 重新添加 ...
- Vue报错 Duplicate keys detected: '1'. This may cause an update error. vue报错
情况一.错误信息展示为关键字‘keys‘,此时应该检查for循环中的key,循环的key值不为唯一性 (很普通) 情况二.有两个相同的for循环,而这两个for循环的key值是一样的,此时将一个的ke ...
- java引用如果是成员变量则引用本身不保存在栈上的汇编级调试证明
很久很久没有更新博客了,因为发生太多太多猝不及防的事情,再加上自己本身也特别忙,这里补上一直想发的自己觉得很有意义的一次探索过程. 就是很多java开发人员都曾被误导的一个点——“如果一个变量是引用, ...
- Apache损坏无法使用怎么办
已经 find / -name httpd | xargs rm -rf删光了httpd相关文件,但是使用yum install httpd 无法正常安装. 查看Httpd的状态是 解决办法: yum ...
- 编译bitcoin比特币客户端
我遇到了两个不太容易解决的问题. 问题一: checking for Berkeley DB C++ headers... default configure: error: Found Berkel ...