K-MEANS算法及sklearn实现
K-MEANS算法
聚类概念:
1.无监督问题:我们手里没有标签
2.聚类:相似的东西分到一组
3.难点:如何评估,如何调参
4.要得到簇的个数,需要指定K值
5.质心:均值,即向量各维取平均即可
6.距离的度量:常用欧几里得距离和余弦相似度
7.优化目标:min$$ min \sum_{i=0}^k \sum_{C_j=0} dist(c_i,x)^2$$
工作流程:
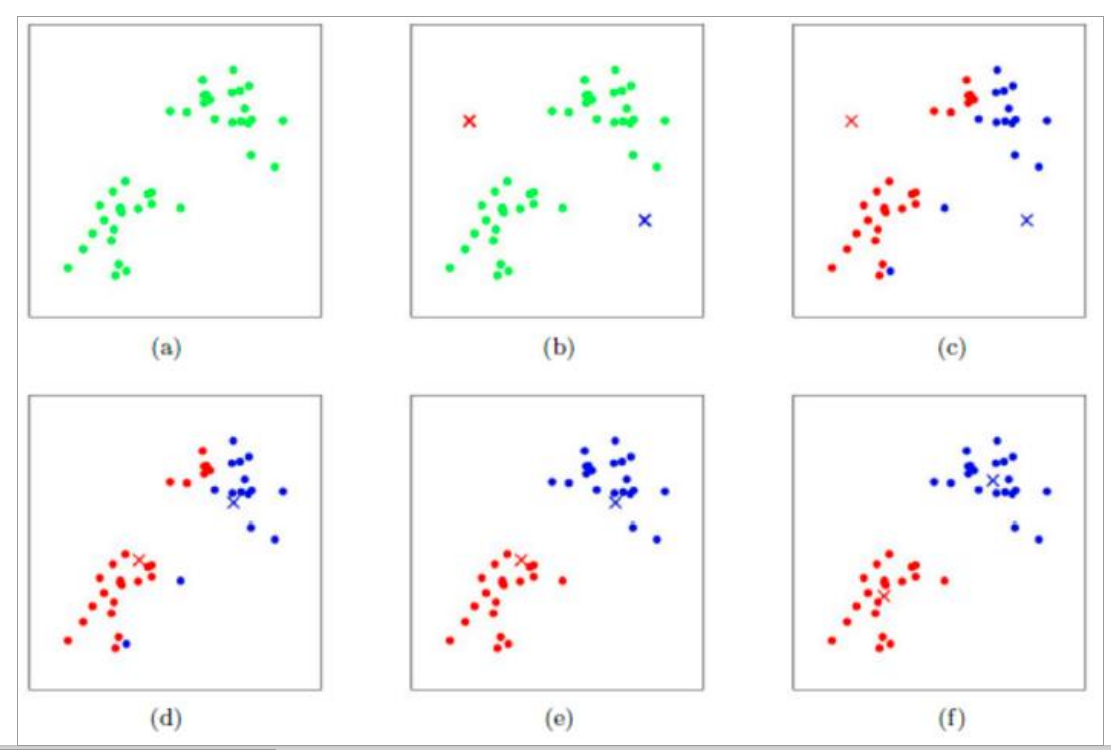
(a)读入数据
(b)随机初始化两个点
(c)计算每个点到质心的距离,离那个质心距离近,就暂时归为那类
(d)重新计算评估指标,更新质心,执行c动作
(e)重新更新质心
(f)重新计算质心的距离,进行分类,直到质心不在发生变化
优势:
简单、快速、适合常规数据集
劣势:
K值难确定
复杂度与样本呈线性关系
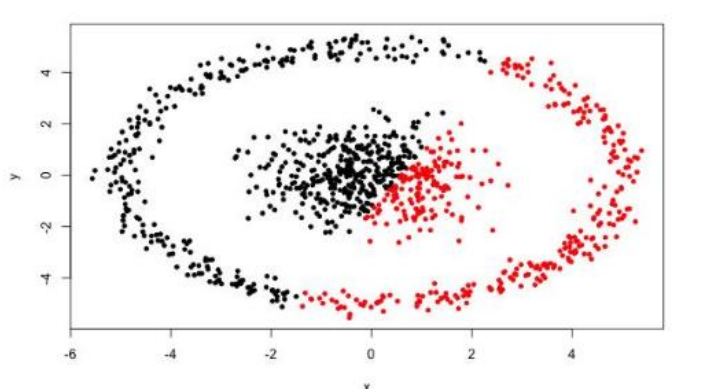
很难发现任意形状的簇,如下图:
sklearn实现
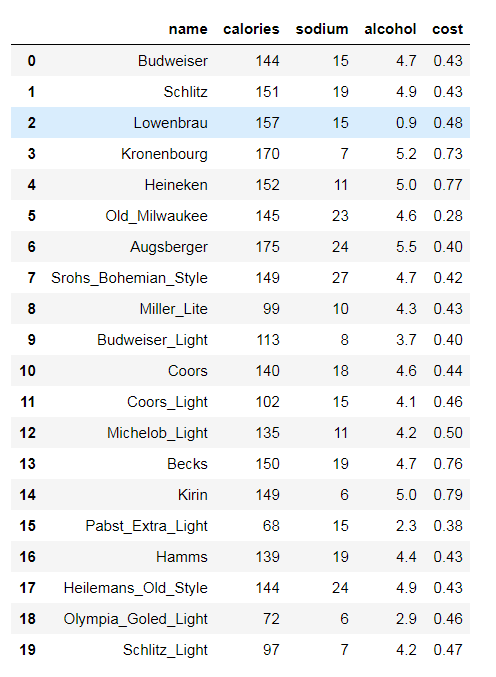
#数据读入
# beer dataset
import pandas as pd
beer = pd.read_csv('data.txt',sep=' ')
beer
X = beer[["calories","sodium","alcohol","cost"]]
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3).fit(X)
km2 = KMeans(n_clusters = 2).fit(X)
print(km.labels_)
array([0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 1, 0, 0, 1, 2])
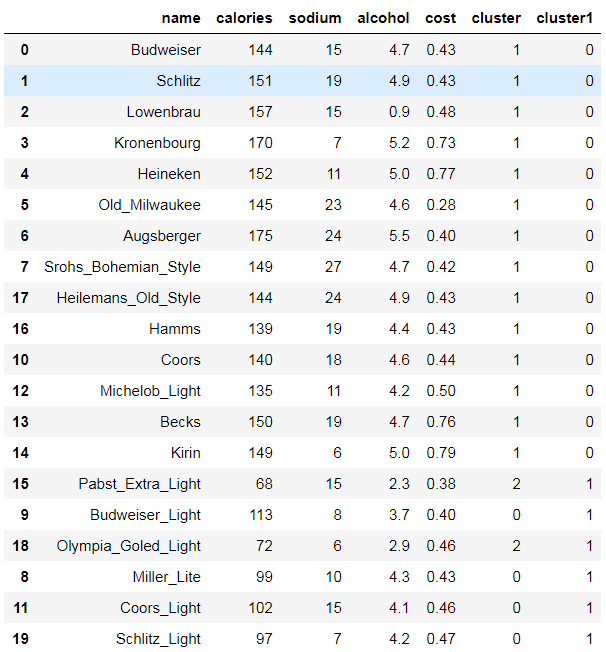
beer['cluster'] = km.labels_
beer['cluster1'] = km2.labels_
beer.sort_values('cluster')
beer.sort_values('cluster1')
K-MEANS算法及sklearn实现的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
代码详解: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split fr ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- 机器学习实战 - python3 学习笔记(一) - k近邻算法
一. 使用k近邻算法改进约会网站的配对效果 k-近邻算法的一般流程: 收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据.一般来讲,数据放在txt文本文件中,按照一定的格式进 ...
随机推荐
- 关于lombok插件的使用,强大的简化代码工具
关于下载和安装lombok插件,过程特别简单,可以参考: https://blog.csdn.net/longloveqing/article/details/81539749 安装好后,下面介绍下l ...
- A New 3-bit Programming Algorithm using SLC-to-TLC Migration for 8MBs High Performance TLC NAND Flash Memory
背景 1.2012年左右的数据SLC.MLC.TLC闪存芯片的区别:SLC = Single-Level Cell ,即1bit/cell,速度快寿命长,价格超贵(约MLC 3倍以上的价格),约10万 ...
- Linux安装git (git-2.11.0)
本文旨在讲述如何在linux上安装最新版的git. 1.查看当前git版本:git --version 查看最新版git:访问https://www.kernel.org/pub/softwa ...
- Stream系列(十三) GroupingBy方法使用
分组 视频讲解 https://www.bilibili.com/video/av78225682/ EmployeeTestCase.java package com.example.demo; i ...
- pmap 命令
NAME pmap - report memory map of a process SYNOPSIS pmap [ -x | -d ] [ -q ] pids... pmap -V 常用参数: -x ...
- CrawlerRunner没有Log输出
官网log说明:https://docs.scrapy.org/en/latest/topics/logging.html#scrapy.utils.log.configure_logging 这里记 ...
- SQL Server解惑——为什么你的查询结果超出了查询时间范围
原文:SQL Server解惑--为什么你的查询结果超出了查询时间范围 废话少说,直接上SQL代码(有兴趣的测试验证一下),下面这个查询语句为什么将2008-11-27的记录查询出来了呢?这个是同事遇 ...
- Boot-crm管理系统开发教程(三)
(ps:前两章我们已经把管理员登录和查看用户的功能实现了,那么今天我们将要实现:添加用户,删除用户,和修改用户功能) 由于Cusomer的POJO类型已经写好了,所以这次我们之前从CustomerCo ...
- Boot-crm管理系统开发教程(二)
ps:昨天将管理员登录的功能完成了,并完美的解决跳过登录从而进入管理界面的bug,今天我们将实现"查询用户"功能. ①在po包中创建Customer类,并编写相关变量和添加set/ ...
- id和class的区别
id和class是定义css样式用到的,不同的是定义样式时的写法不一样,使用id选择样式时,定义的格式为 #main{width:20px;} ,使用class时用到的是 .main{width:20 ...