【零基础】神经网络优化之L1、L2
一、序言
前面的文章中,我们逐步从单神经元、浅层网络到深层网络,并且大概搞懂了“向前传播”和“反向传播”的原理,比较而言深层网络做“手写数字”识别已经游刃有余了,但神经网络还存在很多问题,比如最常见的两个问题:“过拟合”和“欠拟合”,下图中从左到右依次是“欠拟合”、“刚刚好”、“过拟合”。
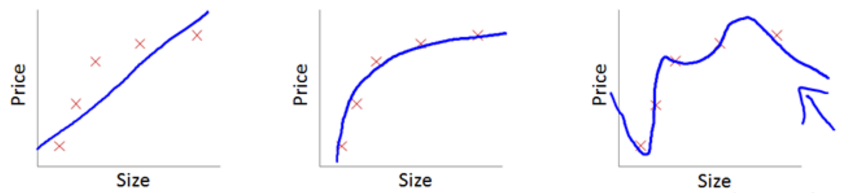
简单点说,欠拟合是我们学习到的w没能很好地“满足”训练数据的特征,一般是因为训练数据太少、训练次数不够、神经网络太简单等问题,优化地方法也比较容易,有针对性地增加训练数据、训练次数或使用更复杂的网络即可。过拟合则刚好相反,我们学习到的w与训练数据太契合了,以至于在实际场景中反而表现很差。本文就简单介绍下过拟合常见优化方法中的一种“L2”,之所以叫L2是因为它前面还有L0和L1。
二、正则化
无论是L0、L1、L2,本质上都是希望实现w的正则化,那何为正则化?严格定义如下:
就是给平面不可约代数曲线以某种形式的全纯参数表示。
用人话说就是:
对某一问题加以先验的限制或约束以达到某种特定目的的一种手段或操作。
还是不好理解的话,可以代入到当前应用场景里来理解:
所谓过拟合就是训练得到的w导致求解曲线过于契合训练数据,正则化就是将“过于契合”变为不那么契合,方法是让求解曲线变得更加“平滑”:
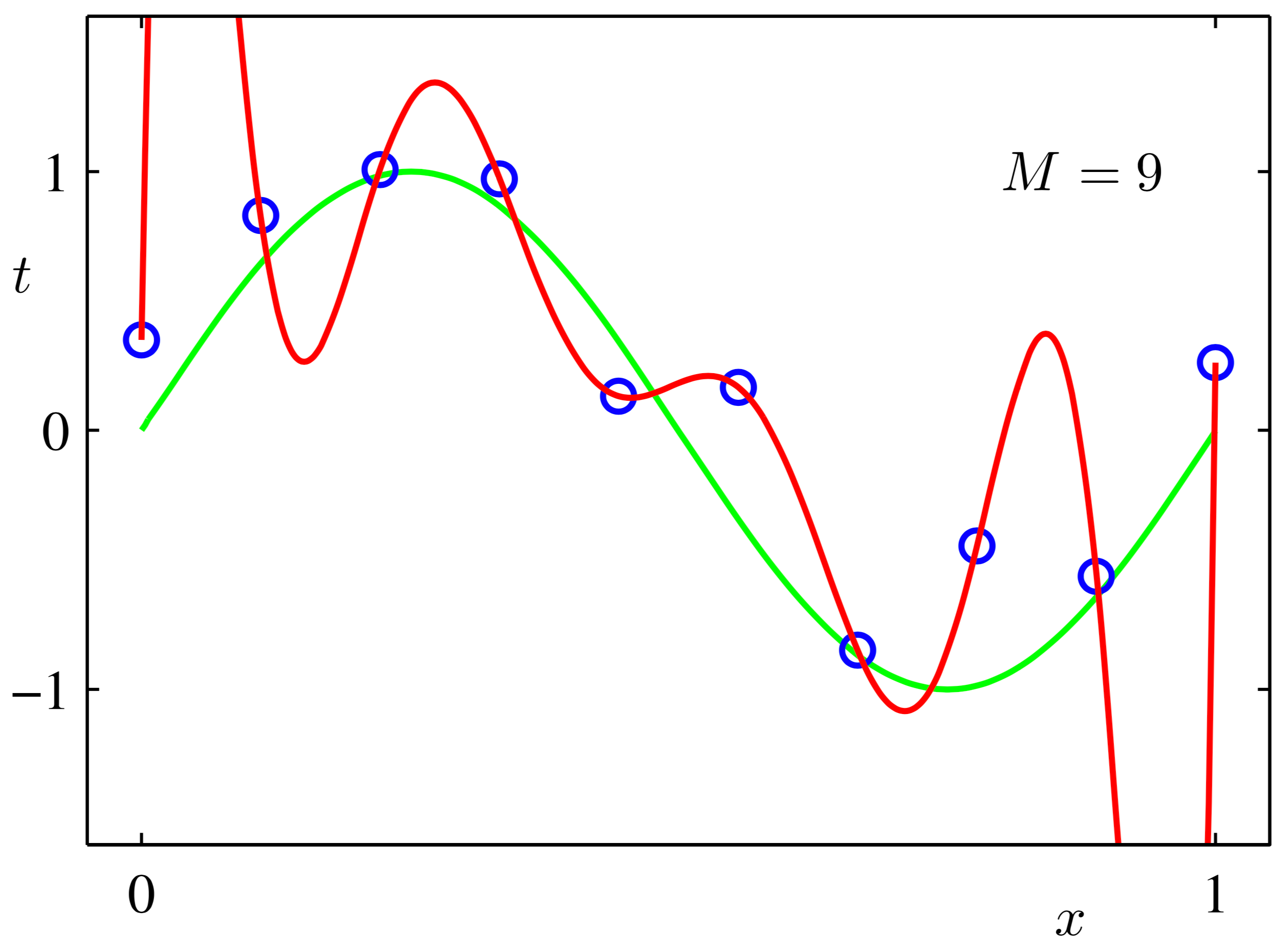
上图中,红色曲线就是过于契合训练数据(过拟合),而绿色曲线就是正则化后的结果(平滑)。
三、L0
L0是一种处理方法,简单来说:
L0 范数指向量中非 0 元素的个数。如果用 L0 范数来规则化一个参数矩阵 W 的话,就是希望 W 的大部分元素是 0,即让参数 W 是稀疏的。
不是很好理解,我们可以代入实际问题中。假设现在有如下的W
W = w1,w2,w3,w4,w5
对W进行L0正则化,就是在求dW时,先看看W中有那些元素是“非0”的,我们一般认为输入中非0的元素是相对“重要”的。现在假设w1、w2为非0数,w3、w4、w5为0,则W中非0数为2个。
W = w1, w2, 0, 0, 0
L0 = 2
进行相应dw计算时,先看一下dw有多少位是非0的,假设dw1、dw2、dw3为非0数,dw4、dw5为0。
dw = dw1, dw2, dw3, 0, 0
我们发现dw非0的数多于L0,那么我们就将dw中的某一个非0数置为0(比如dw3)。dw就变为:
dw = dw1, dw2, 0, 0, 0
如此一来,在做W更新时,部分元素是不更新的(减去的是0),仅更新最多L0个元素。考虑一种理想情况,比如通过L0我们刚好将曲线中一些不重要信息排除掉,那是不是就实现了曲线的“平滑”?其次实践中我们会发现,优化W时其内部元素总是有冲动趋向于极大或极小(即重要的信号越来越重要,不重要的信号越来越不重要),通过L0我们可以延缓这一趋势。
但问题是那些信号是不重要的,那些才是重要的?L0很难去判定,所以L0在实际使用时会有一点作用,但效果好坏全凭运气。
四、L1
L1相对就比较直接了,它直接在损失函数后加上一个小尾巴:
L1 = λ*|W|
其中λ是一个超参(也就是可以人为设置的),用来调节L1影响的幅度。
先回忆一下损失函数的样子

其中Label是训练数据中标注的正确答案,Y是传播函数预测的结果,Y = WX+b
加上L1的损失函数

为了求Δw,我们用新的损失函数对w求导

上式中前半截(Label-Y)^2对w求导在之前“看懂神经网络中的反向传播”已经写过就直接拿来用了,后半截这个w绝对值对w的求导很多地方写的不清不楚让人痛苦,翻了翻高中课本方恍然大悟:
对绝对值求导的结果就是将|W|分为了三段,大于0、等于0、小于0,大于0的部分求导后为1、小于0的部分求导后为-1、等于0的部分不能求导就让结果直接为0吧。所以:
Δw = 2*(Label - Y)*x + λ*f(w)
其中f(w)在w大于0时为1,小于0时为-1,等于0时为0.
由于Δw的结果与W相关,所以L1最后实现的效果就是将W中“正值减小”(多减了一部分正的λ)、“负值增大”(多减了一部分负的λ),也即是使W更加“平滑”。
五、L2
L1让人看起来已经感觉很棒棒了,但实际使用时还是感觉不够劲爆所以又有了L2。L2较L1就只做了一点微小的改变:
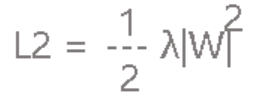
是的,就只是将w变为w的平方而已,乘以1/2只是为了后面计算方便。
我们一样将L2作为小尾巴放到损失函数的屁股后面:
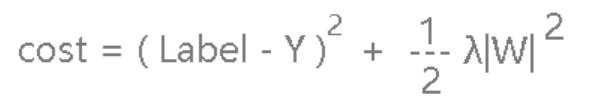
这里求导就很简单了
Δw = 2*(Label - Y)*x + λ*W
L2很简洁,意义与L1差不多都是在更新w时进行一定程度的衰减(w中的负值和正值都更趋向于0)。较L1不同的是L2是按W的一定比例进行衰减,而L1只是简单地减去λ。具体啥好处说不上来,反正大家都用L2
六、总结
公式推导这里花了不少时间,真的推导出来后我发现,当年发明L1、L2的人肯定是先找到了Δw减去这么个值效果很棒,然后再回头去推导cost的计算公式,要不然咋这么巧呢?
这里只做了公式的推导,具体代码就不放出来了(因为求解的问题太简单,以至于加上L1、L2后没啥优化效果),以后把所有优化整全了再发个完整的代码包。
请关注公众号“零基础爱学习”一起AI学习。

【零基础】神经网络优化之L1、L2的更多相关文章
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- 【零基础】神经网络优化之mini-batch
一.前言 回顾一下前面讲过的两种解决过拟合的方法: 1)L0.L1.L2:在向前传播.反向传播后面加个小尾巴 2)dropout:训练时随机“删除”一部分神经元 本篇要介绍的优化方法叫mini-bat ...
- 【零基础】神经网络优化之dropout和梯度校验
一.序言 dropout和L1.L2一样是一种解决过拟合的方法,梯度检验则是一种检验“反向传播”计算是否准确的方法,这里合并简单讲述,并在文末提供完整示例代码,代码中还包含了之前L2的示例,全都是在“ ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(2)
前文链接:狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(1) 小甲鱼在很多情况下是跟着谭浩强鹦鹉学舌,所以谭浩强书中的很多错误他又重复了一次.这样,加上他自己的错误,错谬之处难以胜数. 由于拙 ...
- IM开发者的零基础通信技术入门(二):通信交换技术的百年发展史(下)
1.系列文章引言 1.1 适合谁来阅读? 本系列文章尽量使用最浅显易懂的文字.图片来组织内容,力求通信技术零基础的人群也能看懂.但个人建议,至少稍微了解过网络通信方面的知识后再看,会更有收获.如果您大 ...
- IM开发者的零基础通信技术入门(一):通信交换技术的百年发展史(上)
[来源申明]本文原文来自:微信公众号“鲜枣课堂”,官方网站:xzclass.com,原题为:<通信交换的百年沧桑(上)>,本文引用时已征得原作者同意.为了更好的内容呈现,即时通讯网在收录时 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- 零基础学习openstack【完整中级篇】及openstack资源汇总
1.你是如何学习openstack的?2.你对openstack的组件了解多少?3.你认为openstack该如何学习? 一直想写关于openstack的方面的内容,今天终于整理完成.算是完成一桩心事 ...
随机推荐
- Extjs 兼容IE8常见问题及解决方法
1. 在IE8中整个页面都打不开,一般情况是: 页面组件中最后一个属性出现了逗号 没有多余的逗号,就很有可能是组件中没有设置renderTo:Ext.getBody(); 2. 页面按钮颜色失效 自定 ...
- C# 求余 int a = 371 / 100 % 10,求a的结果为多少?//nt 和int类型计算得到的结果还是int类型
//int 和int类型计算得到的结果还是int类型 eg:int a = 371 / 100 % 10,求a的结果为多少? 首先371除以100,再让此结果除以10求余数. 一 371除以100得到 ...
- vue滚动分页加载以及监听事件处理
<template> <div class="bodyContainer"> <div class="allContent" id ...
- python火爆背后
Python是一种非常好的编程语言,也是目前非常有前途的一门学科.有很多工作要做,而且薪水也很高,这已经成为每个人进入IT行业的首选.那么Python能做什么呢?为什么这么热? 那么Python能做什 ...
- Java调用Python相关问题:指定python环境、传入参数、返回结果
本篇文章涉及到的操作均在Windows系统下进行,Java调用python在原理上不难,但是可能在实际应用中会有各种各样的需求,网上其他的资料很不全,所以又总结了这篇文章,以供参考. 一.指定pyth ...
- Django 启动报错 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc7
pycharm 报错 cmd 报错 解决办法 首先 是计算机 编码问题 是 django 读取你的 用户host名 但是 windos 用户名 如果是中文 就会报这个错 要改成 英文
- TCP/IP三次挥手,四次断开(精简)
很多协议都是基于TCP/IP协议的基础之上进行工作的,可能我们了解这些原理近期看来并无实际作用,因为它不像如一些web服务器配置一样,配置了我就可以使用,就可以提供服务. 但是从我们长远发展角度来看, ...
- Shodan全世界在线设备搜索引擎
reproduction from https://danielmiessler.com/study/shodan/ What is Shodan? Shodan is a search engine ...
- CSS之简介及引入方式
一.css的来源 1994年哈坤·利提出了CSS的最初建议.而当时伯特·波斯(Bert Bos)正在设计一个名为Argo的浏览器,于是他们决定一起设计CSS.其实当时在互联网界已经有过一些统一样式表语 ...
- 越狱后cydia无法联网
0x:卸载 cydia installer 1x:卸载后重启手机 2x:再次h3lix