python数据分析5 数据转换
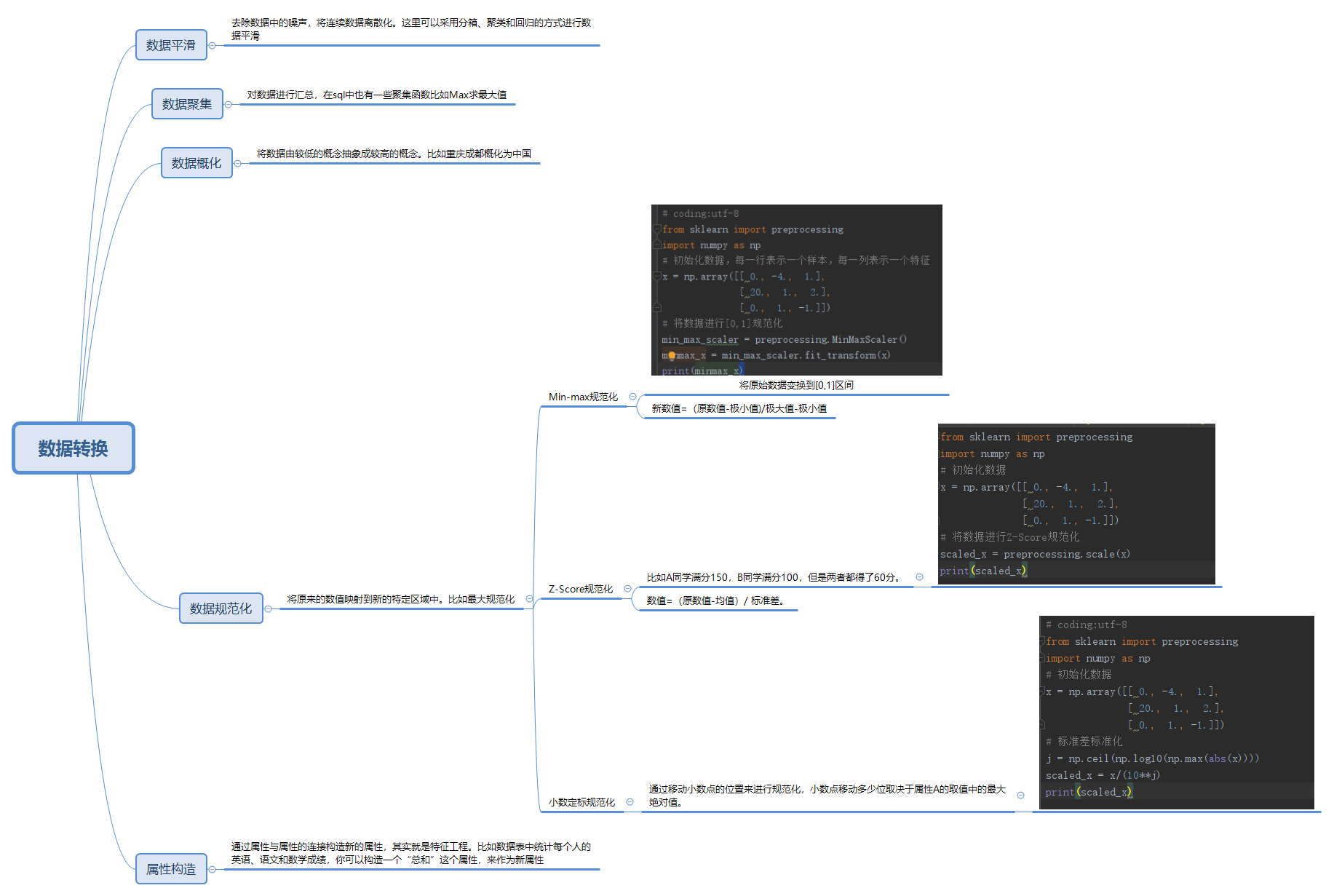
1数据转换
数据转换时数据准备的重要环节,它通过数据平滑,数据聚集,数据概化,规范化等凡是将数据转换成适用于数据挖掘的形式
1.1 数据平滑
去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑
1,2 数据聚集
对数据进行汇总,在sql中也有一些聚集函数比如Max求最大值
1.3 数据概化
将数据由较低的概念抽象成较高的概念。比如重庆成都概化为中国
1.4 数据规范化
将原来的数值映射到新的特定区域中。比如最大规范化
1.5 属性构造
通过属性与属性的连接构造新的属性,其实就是特征工程。比如数据表中统计每个人的英语、语文和数学成绩,你可以构造一个“总和”这个属性,来作为新属性
2 规范化方法
(1) Min-max规范化
将原始数据变换到[0,1]区间
新数值=(原数值-极小值)/极大值-极小值
(2)Z-Score规范化
比如A同学满分150,B同学满分100,但是两者都得了60分。
数值=(原数值-均值)/ 标准差。
(3)小数制定规范化
通过移动小数点的位置来进行规范化,小数点移动多少位取决于属性A的取值中的最大绝对值。
3 Scikit-Learn使用
(1)官网
(2)Min-max规范化使用
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据,每一行表示一个样本,每一列表示一个特征
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行[0,1]规范化
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)
print(minmax_x)
(3)Z_Score使用
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 将数据进行Z-Score规范化
scaled_x = preprocessing.scale(x)
print(scaled_x)
(4)小数点规范化
# coding:utf-8
from sklearn import preprocessing
import numpy as np
# 初始化数据
x = np.array([[ 0., -4., 1.],
[ 20., 1., 2.],
[ 0., 1., -1.]])
# 标准差标准化
j = np.ceil(np.log10(np.max(abs(x))))
scaled_x = x/(10**j)
print(scaled_x)
4 思维导图
5 总结
为了寻找数据的规律,需要将其规范化。那么目前知道有三种方法,分别为Min-max规范化,Z-Score规范化,小数制定规定化等。
python数据分析5 数据转换的更多相关文章
- (python数据分析)第03章 Python的数据结构、函数和文件
本章讨论Python的内置功能,这些功能本书会用到很多.虽然扩展库,比如pandas和Numpy,使处理大数据集很方便,但它们是和Python的内置数据处理工具一同使用的. 我们会从Python最基础 ...
- 《谁说菜鸟不会数据分析》高清PDF全彩版|百度网盘免费下载|Python数据分析
<谁说菜鸟不会数据分析>高清PDF全彩版|百度网盘免费下载|Python数据分析 提取码:p7uo 内容简介 <谁说菜鸟不会数据分析(全彩)>内容简介:很多人看到数据分析就望而 ...
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析(二): Numpy技巧 (1/4)
In [1]: import numpy numpy.__version__ Out[1]: '1.13.1' In [2]: import numpy as np
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
随机推荐
- 我是如何一步步编码完成万仓网ERP系统的(十)产品库设计 6.属性项和类别关联
https://www.cnblogs.com/smh188/p/11533668.html(我是如何一步步编码完成万仓网ERP系统的(一)系统架构) https://www.cnblogs.com/ ...
- XSS漏洞初窥(通过dvwa平台进测试)
xss的全称是:Cross Site Script,中文名叫“跨站脚本攻击”,因为和CSS重名,所以改名XSS.作为一个网站是肯定要和用户有交互的,那么肯定就伴随着信息的输入输出,而利用xss就是通过 ...
- MyDAL - .OpenDebug() 与 Visual Studio 输出窗口 使用
索引: 目录索引 SQL Debug 信息说明 一. 对 XConnection 对象 未开启 OpenDebug, 在 VS 状态下,将默认在 VS 窗口 打印出 参数化的 SQL 执行语句: 新 ...
- Java枚举的用法和原理深入
转载请注明原文地址:https://www.cnblogs.com/ygj0930/p/10843644.html 一:枚举的用法 1.定义和组织常量 在JDK1.5之前,我们定义常量都是:publi ...
- 工作必备之正则匹配、grep、sed、awk
常用正则:匹配空行:^\s*\n 匹配www开头:^www 添加行号:awk '$0=""NR". "$0' /etc/yum.conf 1.所有域名前加www ...
- NBU磁带库报错代码
Linux驱动报错"Sense Key"和"ASC and ASCQ"含义 1.Sense Keys Definitions 0x0 No sense 0x1 ...
- HLOJ1366 Candy Box 动态规划(0-1背包改)
题目描述: 给出N个盒子(N<=100),每个盒子有一定数量的糖果(每个盒子的糖果数<=100),现在有q次查询,每次查询给出两个数k,m,问的是,如果从N个盒子中最多打开k个盒子(意思是 ...
- detectron2安装出现Kernel not compiled with GPU support 报错信息
在安装使用detectron2的时候碰到Kernel not compiled with GPU support 问题,前后拖了好久都没解决,现总结一下以备以后查阅. 不想看心路历程的可以直接跳到最后 ...
- 高斯混合模型GMM与EM算法的Python实现
GMM与EM算法的Python实现 高斯混合模型(GMM)是一种常用的聚类模型,通常我们利用最大期望算法(EM)对高斯混合模型中的参数进行估计. 1. 高斯混合模型(Gaussian Mixture ...
- (转)pgbouncer常用配置项详解
https://pgbouncer.github.io/config.html 参考 <PostgreSQL修炼之道>之pgbouncer 配置文件分为[databases] 和 [pgb ...