ALBERT+BiLSTM+CRF实现序列标注
一、模型框架图

二、分层介绍
1)ALBERT层
albert是以单个汉字作为输入的(本次配置最大为128个,短句做padding),两边分别加上开始标识CLS和结束标识SEP,输出的是每个输入word的embedding。在该框架中其实主要就是利用了预训练模型albert的词嵌入功能,在此基础上fine-tuning其后面的连接参数,也就是albert内部的训练参数不参与训练。
2)BiLSTM层
该层的输入是albert的embedding输出,一般中间会加个project_layer,保证其输出是[batch_szie,num_steps, num_tags]。batch_size为模型当中batch的大小,num_steps为输入句子的长度,本次配置为最大128,num_tags为序列标注的个数,如图中的序列标注一共是5个,也就是会输出每个词在5个tag上的分数,由于没有做softmax归一化,所以不能称之为概率值。
3)CRF层
如果没有CRF层,直接按BiLSTM每个词在5个tag的最大分数作为输出的话,可能会出现【B-Person,O,I-Person,O,I-Location】这种序列,显然不符合实际情况。CRF层可以加入一些约束条件,从而保证最终预测结果是有效的。
例如:
句子的开头应该是“B-”或“O”,而不是“I-”。
“B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Location”则是错误的。
“O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
这些约束可以在训练数据时被CRF层自动学习得到,这种异常的序列出现概率就会大大降低。
三、如何训练?
在从BiLSTM层进入到CRF层时,会有多种路径选择,像上图中会有5x5x5x5x5种路径可能,假设s是我们要寻找的正确路径,其出现的概率如下:
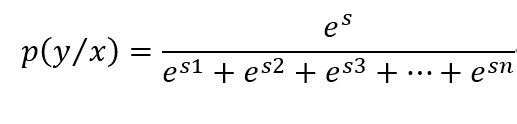
es是当前序列的分数,分母是所有序列分数的和,这也是我们的求解loss function。
传统CRF主要由特征函数组成,一个是状态特征函数,一个是转移特征函数,函数的值要么为1,要么为0,通过训练其权重λ来改变特征函数的贡献。而这里对路径s的训练没有权重,但也是由两部分组成:
1)EmissionScore(发射分数):由BiLSTM层训练输出的每个位置对各个tag的分数,就是上图中输出的红色字体分数。
2)TransitionScore (转移分数): 这部分主要由CRF层训练得到,如下图
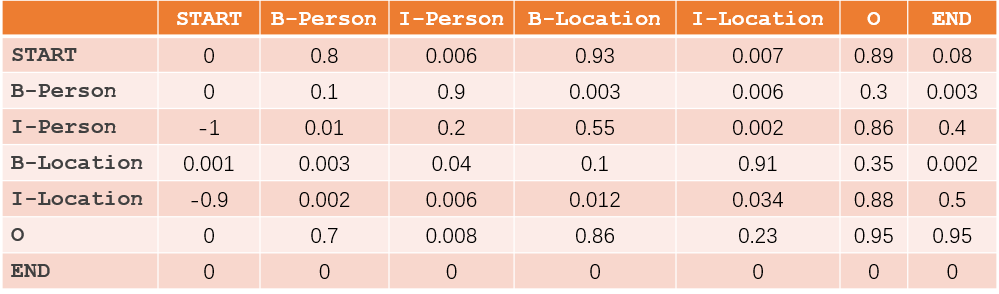
所以,S=EmissionScore+TransitionScore
举例:
对于序列来说,比如有一个序列是“START B-Person I-Person O B-Location O END”,则
EmissionScore=x0,START+x1,B-Person+x2,I-Person+x3,O+x4,B-Location+x5,O+x6,END
TransitionScore=tSTART−>B-Person+tB−Person−>I-Person+tI-Person−>O+t0−>B-Location+tB-Location−>O+tO−>END
es=eEmissionScore+TransitionScore
训练过程:
在训练的时候,BiLSTM层和CRF层的所有参数都会统一求导纳入到训练步骤中,BiLSTM层主要训练其神经网络的参数,而CRF层的参数就是上述转移矩阵,会首先初始化一个转移矩阵参数,然后通过求导不断改变其转移矩阵参数,其训练的目标就是使得正确的路径是所有路径中出现的概率最大,也就是上文的P(y|x)最大。
#初始化转移矩阵
trans = tf.get_variable("transitions",shape=[self.num_tags + 1, self.num_tags + 1],initializer=self.initializer) #CRF层的返回结果就是最新的转移矩阵参数,每一次更新后,再把新的参数传进去,继续更新
log_likelihood, trans = crf_log_likelihood(
inputs=logits,
tag_indices=targets,
transition_params=trans,
sequence_lengths=lengths+1)
损失函数通常会变为-log(p(y|x)),这样就转换成了求解最小值,利用梯度下降法求解即可。
总结:其实BiLSTM+CRF与传统CRF类似,都是有两部分组成,只不过BiLSTM层负责了发射分数的训练,而CRF层负责转移分数的训练。
ALBERT+BiLSTM+CRF实现序列标注的更多相关文章
- TensorFlow教程——Bi-LSTM+CRF进行序列标注(代码浅析)
https://blog.csdn.net/guolindonggld/article/details/79044574 Bi-LSTM 使用TensorFlow构建Bi-LSTM时经常是下面的代码: ...
- NLP(二十五)实现ALBERT+Bi-LSTM+CRF模型
在文章NLP(二十四)利用ALBERT实现命名实体识别中,笔者介绍了ALBERT+Bi-LSTM模型在命名实体识别方面的应用. 在本文中,笔者将介绍如何实现ALBERT+Bi-LSTM+CRF ...
- LSTM+CRF进行序列标注
为什么使用LSTM+CRF进行序列标注 直接使用LSTM进行序列标注时只考虑了输入序列的信息,即单词信息,没有考虑输出信息,即标签信息,这样无法对标签信息进行建模,所以在LSTM的基础上引入一个标签转 ...
- TensorFlow (RNN)深度学习 双向LSTM(BiLSTM)+CRF 实现 sequence labeling 序列标注问题 源码下载
http://blog.csdn.net/scotfield_msn/article/details/60339415 在TensorFlow (RNN)深度学习下 双向LSTM(BiLSTM)+CR ...
- 基于CRF序列标注的中文依存句法分析器的Java实现
这是一个基于CRF的中文依存句法分析器,内部CRF模型的特征函数采用 双数组Trie树(DoubleArrayTrie)储存,解码采用特化的维特比后向算法.相较于<最大熵依存句法分析器的实现&g ...
- 用CRF++开源工具做文本序列标注教程
本文只介绍如何快速的使用CRF++做序列标注,对其中的原理和训练测试参数不做介绍. 官网地址:CRF++: Yet Another CRF toolkit 主要完成如下功能: 输入 -> &qu ...
- Bi-LSTM+CRF在文本序列标注中的应用
传统 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息.有了词嵌入方法之后,词向量形式的词表征一般效果比 one-hot 表示的特征 ...
- 序列标注(HMM/CRF)
目录 简介 隐马尔可夫模型(HMM) 条件随机场(CRF) 马尔可夫随机场 条件随机场 条件随机场的特征函数 CRF与HMM的对比 维特比算法(Viterbi) 简介 序列标注(Sequence Ta ...
- NLP之CRF应用篇(序列标注任务)
1.CRF++的详细解析 完成的是学习和解码的过程:训练即为学习的过程,预测即为解码的过程. 模板的解析: 具体参考hanlp提供的: http://www.hankcs.com/nlp/the-cr ...
随机推荐
- vue 开发系列(九) VUE 动态组件的应用
业务场景 我们在开发表单的过程中会遇到这样的问题,我们选择一个控件进行配置,控件有很多中类型,比如文本框,下来框等,这些配置都不同,因此需要不同的配置组件来实现. 较常规的方法是使用v-if 来实现, ...
- [小程序]微信小程序获取input并发送网络请求
1. 获取输入框数据wxml中的input上增加bindinput属性,和方法值在js部分定义与之对应的方法,只要在输入的时候,数据就会绑定调用到该方法,存入data属性变量中 2. 调用get请求发 ...
- Windows 下 pycharm 创建Django 项目【用虚拟环境的解释器】
1. 背景 我在 Windows 下的 pycharm 直接创建 全新 Django 项目 会 pip 和其他报错 ,暂时解决不了,另外后续的多个项目只需要一套python 环境, 所以可以 ...
- python cookie登录DVWA,phpstudy搭建DVWA参考https://www.jianshu.com/p/97d874548300
import requestsheader={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleW ...
- php、mysql查询当天,查询本周,查询本月的数据实例(字段是时间戳)
php.mysql查询当天,查询本周,查询本月的数据实例(字段是时间戳) //其中 video 是表名: //createtime 是字段: // //数据库time字段为时间戳 // //查询当天: ...
- 用eclipse开发Android,用Genymotion测试时报错adb发生错误
每当我要运行安卓程序时,控制台就会报出 The connection to adb is down, and a severe error has occured. You must restart ...
- JDOJ 3055: Nearest Common Ancestors
JDOJ 3055: Nearest Common Ancestors JDOJ传送门 Description 给定N个节点的一棵树,有K次查询,每次查询a和b的最近公共祖先. 样例中的16和7的公共 ...
- Matlab c2d()函数的用法
1.c2d()函数的用法 c2d()函数的作用是将s域的表达式转化成z域的表达式,s=0对应z=1. c2d()函数转化的方法有多种: ①zoh, 零阶保持器法,又称阶跃响应不变法: ②foh ,一阶 ...
- 微信小程序使用npm安装第三方库
微信小程序在 2.2.1 版本后增加了对 npm 包加载的支持,使得小程序支持使用 npm 安装第三方包. 之前在微信开发者工具选择“构建npm”会报错“没找到node_modules”目录”,这是因 ...
- 三层交换机RIP动态路由实验
一. 实验目的 1. 掌握三层交换机之间通过RIP协议实现网段互通的配置方法. 2. 理解动态实现方式与静态方式的不同 二. 应用环境 当两台三层交换机级联时,为了保证每台交换机上所连接的 ...