GAN 原理及公式推导
Generative Adversarial Network,就是大家耳熟能详的 GAN,由 Ian Goodfellow 首先提出,在这两年更是深度学习中最热门的东西,仿佛什么东西都能由 GAN 做出来。我最近刚入门 GAN,看了些资料,做一些笔记。
可以参考另一篇,GAN原理
https://www.cnblogs.com/jins-note/p/9550561.html
1.Generation
什么是生成(generation)?就是模型通过学习一些数据,然后生成类似的数据。让机器看一些动物图片,然后自己来产生动物的图片,这就是生成。
以前就有很多可以用来生成的技术了,比如 auto-encoder(自编码器),结构如下图:
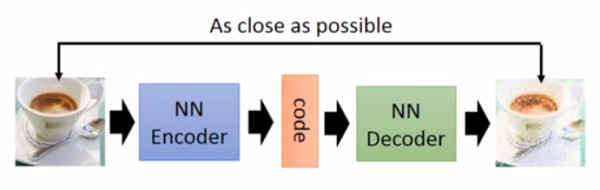
你训练一个 encoder,把 input 转换成 code,然后训练一个 decoder,把 code 转换成一个 image,然后计算得到的 image 和 input 之间的 MSE(mean square error),训练完这个 model 之后,取出后半部分 NN Decoder,输入一个随机的 code,就能 generate 一个 image。
但是 auto-encoder 生成 image 的效果,当然看着很别扭啦,一眼就能看出真假。所以后来还提出了比如VAE这样的生成模型,我对此也不是很了解,在这就不细说。
上述的这些生成模型,其实有一个非常严重的弊端。比如 VAE,它生成的 image 是希望和 input 越相似越好,但是 model 是如何来衡量这个相似呢?model 会计算一个 loss,采用的大多是 MSE,即每一个像素上的均方差。loss 小真的表示相似嘛?

比如这两张图,第一张,我们认为是好的生成图片,第二张是差的生成图片,但是对于上述的 model 来说,这两张图片计算出来的 loss 是一样大的,所以会认为是一样好的图片。
这就是上述生成模型的弊端,用来衡量生成图片好坏的标准并不能很好的完成想要实现的目的。于是就有了下面要讲的 GAN。
2.GAN
大名鼎鼎的 GAN 是如何生成图片的呢?首先大家都知道 GAN 有两个网络,一个是 generator,一个是 discriminator,从二人零和博弈中受启发,通过两个网络互相对抗来达到最好的生成效果。流程如下:
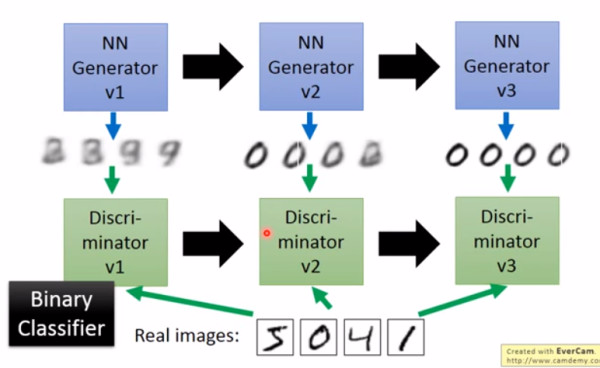
主要流程类似上面这个图。首先,有一个一代的 generator,它能生成一些很差的图片,然后有一个一代的 discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个 discriminator 就是一个二分类器,对生成的图片输出 0,对真实的图片输出 1。
接着,开始训练出二代的 generator,它能生成稍好一点的图片,能够让一代的 discriminator 认为这些生成的图片是真实的图片。然后会训练出一个二代的 discriminator,它能准确的识别出真实的图片,和二代 generator 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。
这就是 GAN,运行过程就是这么的简单。这就结束了嘛?显然没有,下面还要介绍一下 GAN 的原理。
3.原理
首先我们知道真实图片集的分布 Pdata(x),x 是一个真实图片,可以想象成一个向量,这个向量集合的分布就是 Pdata。我们需要生成一些也在这个分布内的图片,如果直接就是这个分布的话,怕是做不到的。
我们现在有的 generator 生成的分布可以假设为 PG(x;θ),这是一个由 θ 控制的分布,θ 是这个分布的参数(如果是高斯混合模型,那么 θ 就是每个高斯分布的平均值和方差)
假设我们在真实分布中取出一些数据,{x1, x2, ... , xm},我们想要计算一个似然 PG(xi; θ)。
对于这些数据,在生成模型中的似然就是
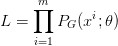
我们想要最大化这个似然,等价于让 generator 生成那些真实图片的概率最大。这就变成了一个最大似然估计的问题了,我们需要找到一个 θ* 来最大化这个似然。
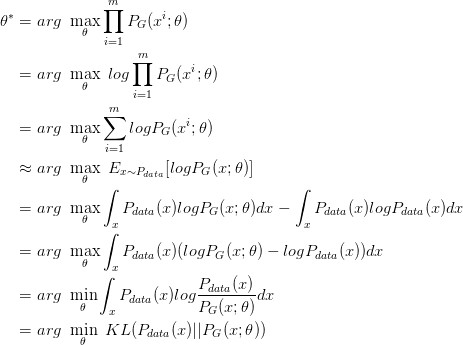
寻找一个 θ* 来最大化这个似然,等价于最大化 log 似然。因为此时这 m 个数据,是从真实分布中取的,所以也就约等于,真实分布中的所有 x 在 PG 分布中的 log 似然的期望。
真实分布中的所有 x 的期望,等价于求概率积分,所以可以转化成积分运算,因为减号后面的项和 θ 无关,所以添上之后还是等价的。然后提出共有的项,括号内的反转,max 变 min,就可以转化为 KL divergence 的形式了,KL divergence 描述的是两个概率分布之间的差异。
所以最大化似然,让 generator 最大概率的生成真实图片,也就是要找一个 θ 让 PG 更接近于 Pdata。
那如何来找这个最合理的 θ 呢?我们可以假设 PG(x; θ) 是一个神经网络。
首先随机一个向量 z,通过 G(z)=x 这个网络,生成图片 x,那么我们如何比较两个分布是否相似呢?只要我们取一组 sample z,这组 z 符合一个分布,那么通过网络就可以生成另一个分布 PG,然后来比较与真实分布 Pdata。
大家都知道,神经网络只要有非线性激活函数,就可以去拟合任意的函数,那么分布也是一样,所以可以用一直正态分布,或者高斯分布,取样去训练一个神经网络,学习到一个很复杂的分布。
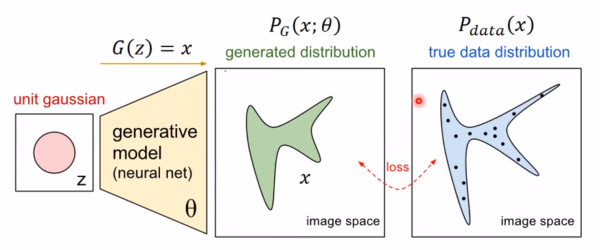
如何来找到更接近的分布,这就是 GAN 的贡献了。先给出 GAN 的公式:

这个式子的好处在于,固定 G,max V(G,D) 就表示 PG 和 Pdata 之间的差异,然后要找一个最好的 G,让这个最大值最小,也就是两个分布之间的差异最小。
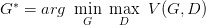
表面上看这个的意思是,D 要让这个式子尽可能的大,也就是对于 x 是真实分布中,D(x) 要接近与 1,对于 x 来自于生成的分布,D(x) 要接近于 0,然后 G 要让式子尽可能的小,让来自于生成分布中的 x,D(x) 尽可能的接近 1。
现在我们先固定 G,来求解最优的 D:


对于一个给定的 x,得到最优的 D 如上图,范围在 (0,1) 内,把最优的 D 带入
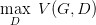
可以得到:

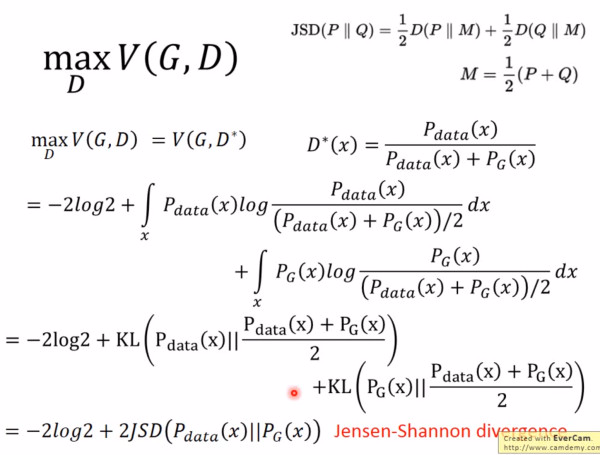
JS divergence 是 KL divergence 的对称平滑版本,表示了两个分布之间的差异,这个推导就表明了上面所说的,固定 G。
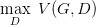
表示两个分布之间的差异,最小值是 -2log2,最大值为 0。
现在我们需要找个 G,来最小化

观察上式,当 PG(x)=Pdata(x) 时,G 是最优的。
4.训练
有了上面推导的基础之后,我们就可以开始训练 GAN 了。结合我们开头说的,两个网络交替训练,我们可以在起初有一个 G0 和 D0,先训练 D0 找到 :
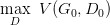
然后固定 D0 开始训练 G0, 训练的过程都可以使用 gradient descent,以此类推,训练 D1,G1,D2,G2,...
但是这里有个问题就是,你可能在 D0* 的位置取到了:
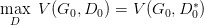
然后更新 G0 为 G1,可能
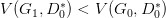
了,但是并不保证会出现一个新的点 D1* 使得
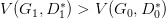
这样更新 G 就没达到它原来应该要的效果,如下图所示:
避免上述情况的方法就是更新 G 的时候,不要更新 G 太多。
知道了网络的训练顺序,我们还需要设定两个 loss function,一个是 D 的 loss,一个是 G 的 loss。下面是整个 GAN 的训练具体步骤:

上述步骤在机器学习和深度学习中也是非常常见,易于理解。
5.存在的问题
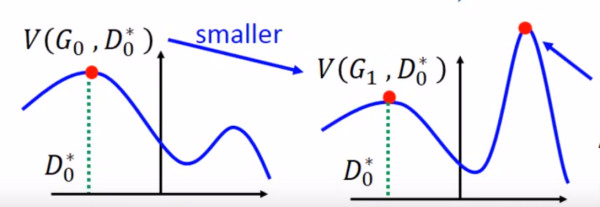
但是上面 G 的 loss function 还是有一点小问题,下图是两个函数的图像:
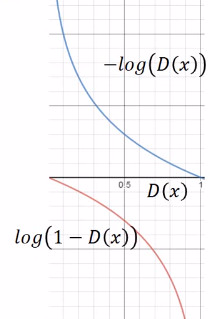
log(1-D(x)) 是我们计算时 G 的 loss function,但是我们发现,在 D(x) 接近于 0 的时候,这个函数十分平滑,梯度非常的小。这就会导致,在训练的初期,G 想要骗过 D,变化十分的缓慢,而上面的函数,趋势和下面的是一样的,都是递减的。但是它的优势是在 D(x) 接近 0 的时候,梯度很大,有利于训练,在 D(x) 越来越大之后,梯度减小,这也很符合实际,在初期应该训练速度更快,到后期速度减慢。
所以我们把 G 的 loss function 修改为
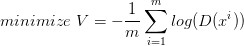
这样可以提高训练的速度。
还有一个问题,在其他 paper 中提出,就是经过实验发现,经过许多次训练,loss 一直都是平的,也就是
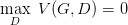
JS divergence 一直都是 log2,PG 和 Pdata 完全没有交集,但是实际上两个分布是有交集的,造成这个的原因是因为,我们无法真正计算期望和积分,只能使用 sample 的方法,如果训练的过拟合了,D 还是能够完全把两部分的点分开,如下图:

对于这个问题,我们是否应该让 D 变得弱一点,减弱它的分类能力,但是从理论上讲,为了让它能够有效的区分真假图片,我们又希望它能够 powerful,所以这里就产生了矛盾。
还有可能的原因是,虽然两个分布都是高维的,但是两个分布都十分的窄,可能交集相当小,这样也会导致 JS divergence 算出来 =log2,约等于没有交集。
解决的一些方法,有添加噪声,让两个分布变得更宽,可能可以增大它们的交集,这样 JS divergence 就可以计算,但是随着时间变化,噪声需要逐渐变小。
还有一个问题叫 Mode Collapse,如下图:

这个图的意思是,data 的分布是一个双峰的,但是学习到的生成分布却只有单峰,我们可以看到模型学到的数据,但是却不知道它没有学到的分布。
造成这个情况的原因是,KL divergence 里的两个分布写反了
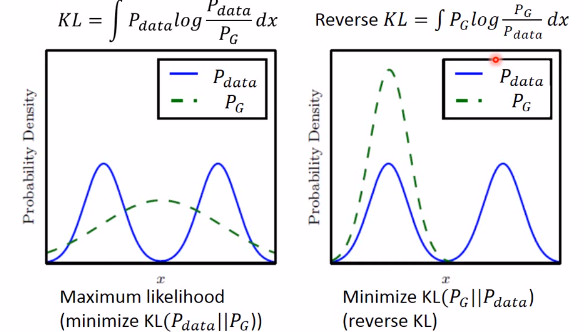
这个图很清楚的显示了,如果是第一个 KL divergence 的写法,为了防止出现无穷大,所以有 Pdata 出现的地方都必须要有 PG 覆盖,就不会出现 Mode Collapse。
6.参考
这是对 GAN 入门学习做的一些笔记和理解,后来太懒了,不想打公式了,主要是参考了李宏毅老师的视频:
GAN 原理及公式推导的更多相关文章
- GAN网络从入门教程(二)之GAN原理
在一篇博客GAN网络从入门教程(一)之GAN网络介绍中,简单的对GAN网络进行了一些介绍,介绍了其是什么,然后大概的流程是什么. 在这篇博客中,主要是介绍其数学公式,以及其算法流程.当然数学公式只是简 ...
- XGBoost原理和公式推导
本篇文章主要介绍下Xgboost算法的原理和公式推导.关于XGB的一些应用场景在此就不赘述了,感兴趣的同学可以自行google.下面开始: 1.模型构建 构建最优模型的方法一般是最小化训练数据的损失 ...
- 深度学习----现今主流GAN原理总结及对比
原文地址:https://blog.csdn.net/Sakura55/article/details/81514828 1.GAN 先来看看公式: GAN网络主要由两个网络构 ...
- NDT(Normal Distributions Transform)算法原理与公式推导
正态分布变换(NDT)算法是一个配准算法,它应用于三维点的统计模型,使用标准最优化技术来确定两个点云间的最优的匹配,因为其在配准过程中不利用对应点的特征计算和匹配,所以时间比其他方法快.下面的公式推导 ...
- FFM原理及公式推导
原文来自:博客园(华夏35度)http://www.cnblogs.com/zhangchaoyang 作者:Orisun 上一篇讲了FM(Factorization Machines),说一说FFM ...
- 线性模型之逻辑回归(LR)(原理、公式推导、模型对比、常见面试点)
参考资料(要是对于本文的理解不够透彻,必须将以下博客认知阅读,方可全面了解LR): (1).https://zhuanlan.zhihu.com/p/74874291 (2).逻辑回归与交叉熵 (3) ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- 深度学习中常见的 Normlization 及权重初始化相关知识(原理及公式推导)
Batch Normlization(BN) 为什么要进行 BN 防止深度神经网络,每一层得参数更新会导致上层的输入数据发生变化,通过层层叠加,高层的输入分布变化会十分剧烈,这就使得高层需要不断去重新 ...
- Logistic回归原理及公式推导[转]
原文见 http://blog.csdn.net/acdreamers/article/details/27365941 Logistic回归为概率型非线性回归模型,是研究二分类观察结果与一些影响因素 ...
随机推荐
- Eclipse - servlet显示无法导入javax.servlet包问题的解决方案
项目名-->右键 Property-->选择 Java Build Path-->选择 Add External JARs-->选择 把servlet-api.jar的路径输入 ...
- Androidx初尝及其新旧包对照表
x的最低实验条件 AndroidStudio 3.2.0+ gradle:gradle-4.6以上 本次实验条件: AndroidStudio 3.3 (强制要求最低gradle版本为gradle-4 ...
- c#使用正则表达式处理字符串
正则表达式可以灵活而高效的处理文本,可以通过匹配快速分析大量的文本找到特定的字符串. 可以验证字符串是否符合某种预定义的格式,可以提取,编辑,替换或删除文本子字符串. 现在如下特定的字符串: stri ...
- python 版本号比较 重载运算符
# -*- coding: utf-8 -*- class VersionNum(object): """ 版本号比较 默认版本以“.”分割,各位版本位数不超过3 例一: ...
- C++Primer第五版 练习8.6答案详解
重写7.1.1节书店程序(第299页),从文件中读取一个交易记录.将文件名作为一个参数传递给main. 本题所需源文件如下: Sales_data.h文件: #pragma once #include ...
- 2013.6.21 - OpenNER第一天
下午去实验室继续写实验报告,跟伟杰要了一个实验报告,然后大师兄叫我,我们在走廊唠了一会儿. 大 师兄想做Open NE,他说这个会比较难,目前没有人做,因为还没有发现相关的文章,大家研究的都是指定了哪 ...
- Codeforces D. Powerful array(莫队)
题目描述: Problem Description An array of positive integers a1, a2, ..., an is given. Let us consider it ...
- 微信小程序~生命周期方法详解
生命周期是指一个小程序从创建到销毁的一系列过程 在小程序中 ,通过App()来注册一个小程序 ,通过Page()来注册一个页面 先来看一张小程序项目结构 从上图可以看出,根目录下面有包含了app.js ...
- 0029redis单机版环境搭建
linux环境下安装单机版redis,主要分为如下几步: 1. 安装gcc 2.下载安装包 3.解压安装包 4.进入解压目录并执行make和make install命令 5.查看默认安装目录 6.更改 ...
- 十六.maven自动化构建protobuf代码依赖
protobuf在序列化和反序列化中的优势: 1):序列化后体积相比Json和XML很小,适合网络传输2):支持跨平台多语言3):消息格式升级和兼容性还不错4):序列化反序列化速度很快,快于Json的 ...